Grok Celestia DA Namespaces
 Luke Cassady-Dorion
Luke Cassady-Dorion
One of the challenges Web2 developers encounter when building Web3 systems is grokking the difference between trust assumptions in the two environments.
In a Web2 environment, developers own their backend. Your data is stored in databases you administer, and your application logic runs on servers you control. You trust the system because you own it.
In a Web3 environment, your "data" is stored on nodes distributed around the world, run by everything from professional operators to hobbyists. Much like the X-Files, you "trust no one"—instead, systems are designed so you can verify everything.

Data Availability in blockchain networks ensures that everyone can access the data needed to verify the validity of state transitions. It’s about providing proof so that others can verify the work, creating a system where you don’t need to trust anyone blindly.
Celestia is a Data Availability layer used by hundreds of applications globally. One of its key innovations is segmenting data into namespaces. This way, when verifying data, each application can focus on its own data and ignore other applications' data.
This post combines video and code examples to help you better understand Data Availability and namespaces.
Videos are great for grasping concepts, but not always ideal for diving into code. I recommend watching the video first, paying attention to the concepts. When the video gets to the code section, you can get an overview, then return here to explore the code in detail.
Code Time
Now that you understand what a namespace is, let’s use the Celenium API to query data about Celestia namespaces. Specifically, we will use two API routes from Celenium to:
Get count of namespaces in the network
Get namespaces
You’ll fetch the total number of namespaces and then retrieve detailed information about each. Finally, you’ll analyze this data to find the top 10 namespaces by blob count and size.
Setting the API Base URL
In this code, the base URL for the Celenium API is set to:
const celeniumApiBase = "https://api-mainnet.celenium.io/v1";
This pulls data from the Celestia mainnet. All API requests in the code use this base URL and append different endpoints.
You can also use:
Mocha Testnet:
https://api-mocha.celenium.io/v1/Arabica Devnet:
https://api-arabica.celenium.io/v1/
Celenium API Routes
We’ll use the following two endpoints:
GET /namespace/count: Returns the total number of namespaces.GET /namespace: Returns namespace data.
Main Functions
getNamespaceCount
Makes a request to the namespace/count endpoint to retrieve the total number of namespaces. It handles potential rate-limiting by using a retry mechanism with a sleep function, which delays the next request for one second if the API responds with a 429 (Too Many Requests) status.
const getNamespaceCount = async (): Promise<number> => {
console.log("Fetching count of namespaces...");
while (true) {
try {
const response = await axios.get<number>(
`${celeniumApiBase}/namespace/count`
);
console.log(`Total namespaces in network: ${response.data}`);
return response.data;
} catch (error) {
if (axios.isAxiosError(error) && error.response?.status === 429) {
console.warn("Rate limited, sleeping for 1 second...");
await sleep(1000);
} else {
throw error;
}
}
}
};
getNamespaces
Retrieves namespaces from the namespace endpoint. It uses pagination by accepting a limit and an offset to fetch data in batches. Just like the previous function, it retries the request if the rate limit is reached.
const getNamespaces = async (
limit: number,
offset: number
): Promise<Namespace[]> => {
console.log(
`Fetching namespaces with limit ${limit} and offset ${offset}...`
);
while (true) {
try {
const response = await axios.get<Namespace[]>(
`${celeniumApiBase}/namespace`,
{
params: { limit, offset },
}
);
console.log(`Fetched ${response.data.length} namespaces`);
return response.data;
} catch (error) {
if (axios.isAxiosError(error) && error.response?.status === 429) {
console.warn("Rate limited, sleeping for 1 second...");
await sleep(1000);
} else {
throw error;
}
}
}
};
Handling Rate Limits
The sleep function is used to delay retries when a rate limit is hit.
const sleep = (ms: number) => new Promise((resolve) => setTimeout(resolve, ms));
analyzeNamespaceUsage
In the main function, we first call getNamespaceCount to determine how many namespaces exist. Then, we use getNamespaces to fetch all namespaces in batches of 100. After collecting all the data, we sort the namespaces by two criteria:
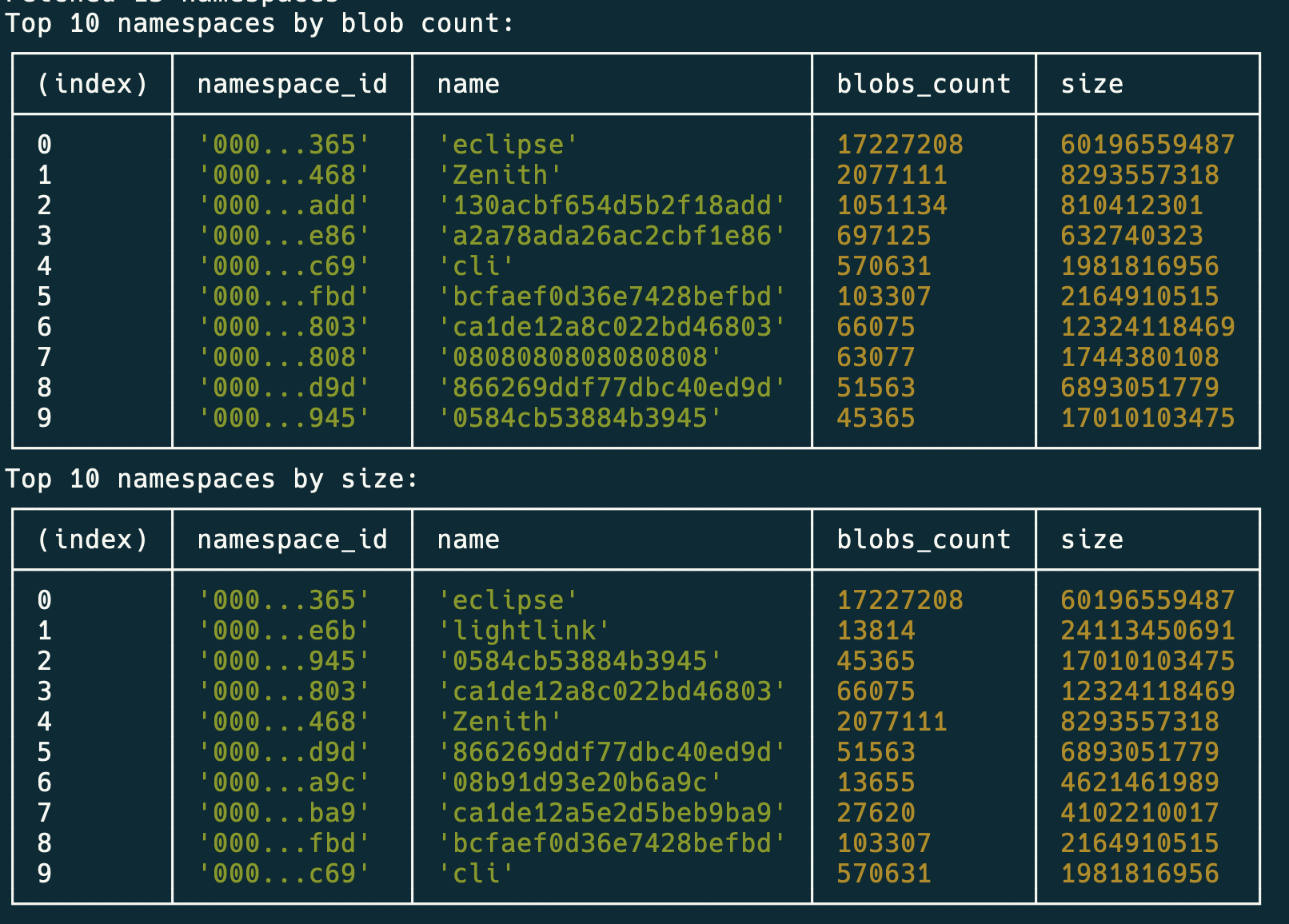
Blob count: The top 10 namespaces by the number of blobs.
Size: The top 10 namespaces by size of data posted.
Both sorted results are displayed using console.table for easy reading in the console.
const analyzeNamespaceUsage = async (): Promise<void> => {
try {
// Step 1: Get the count of namespaces
const namespaceCount = await getNamespaceCount();
const limit = 100;
const namespaceData: Namespace[] = [];
// Step 2: Get all namespaces with pagination
for (let offset = 0; offset < namespaceCount; offset += limit) {
const namespaces = await getNamespaces(limit, offset);
namespaceData.push(...namespaces);
}
// Step 3: Sort namespaces by blobs_count and size, and display top 10 using console.table
const sortedByBlobsCount = [...namespaceData]
.sort((a, b) => b.blobs_count - a.blobs_count)
.slice(0, 10);
console.log("Top 10 namespaces by blob count:");
console.table(
sortedByBlobsCount.map(({ namespace_id, name, blobs_count, size }) => ({
namespace_id: `${namespace_id.slice(0, 3)}...${namespace_id.slice(-3)}`,
name,
blobs_count,
size,
}))
);
const sortedBySize = [...namespaceData]
.sort((a, b) => b.size - a.size)
.slice(0, 10);
console.log("Top 10 namespaces by size:");
console.table(
sortedBySize.map(({ namespace_id, name, blobs_count, size }) => ({
namespace_id: `${namespace_id.slice(0, 3)}...${namespace_id.slice(-3)}`,
name,
blobs_count,
size,
}))
);
} catch (error) {
console.error("Error analyzing namespace usage:", error);
}
};
Running the Code
Finally, we call analyzeNamespaceUsage() to run the code.
codeanalyzeNamespaceUsage();
At the time I wrote this blog post, the code produces the following.
Questions? Comments? Let me know below and I’ll get back to you.
Subscribe to my newsletter
Read articles from Luke Cassady-Dorion directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Luke Cassady-Dorion
Luke Cassady-Dorion
I've always had fun doing lots of different things. Currently, I work in Developer Relations at Irys. I've worked as a software engineer, I've been a CTO, a TV producer, a documentary director, a YouTuber. I've written and contributed to multiple books on software development. I've taught yoga and I've taught Pilates. I have half a BS in Computer Science and a BA in Thai Language Studies.