Understanding Encapsulation in Object-Oriented Programming
 Francesco Tusa
Francesco Tusa
Encapsulation is a fundamental principle in object-oriented programming (OOP) that helps manage program complexity by bundling the attributes (data) and the methods (behaviours) that operate on the data into a single unit called a class. This principle not only enhances the security and integrity of the data but also promotes code modularity and reusability.
Designing Object Interfaces
Encapsulation is closely linked with the concept of object interface and abstraction. Whilst attributes are encapsulated within an object along with the methods, an object will still need to expose the functionalities it provides to other objects. The object interface defines in a structured way what functionalities an object exposes and how other objects can use them.
When we consider this concept in a real-world context, it becomes clear that we experience it daily when interacting with various objects and systems. For instance, many of us use a microwave oven with an interface that allows us to set the power level and timer. However, the intricate details of how microwaves are generated and the timer functions within the electronic circuits are abstracted and do not need to be disclosed.
Specifically, in the concept of OOP, the interface specifies which methods are available for other objects to call, thereby controlling access and changes to the object’s internal state. This interaction is typically done through public methods, while the structure utilised to represent the internal object’s state is kept private:
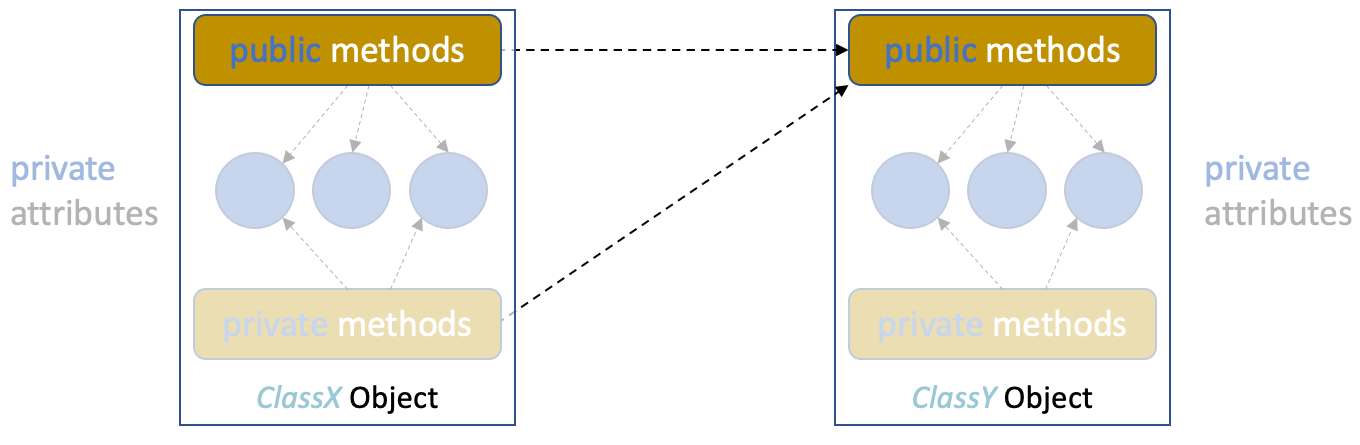
In the image above, objects of different classes interact by invoking public methods—they “send messages” to each other. The rest of the object is hidden and not exposed to other objects directly (or available). Method invocation is how objects communicate and collaborate in an OOP system.
Data Hiding and Integrity
One of the core aspects of encapsulation is data hiding. By restricting direct access to the object’s attributes, encapsulation ensures that the internal representation of the object's status is hidden from the outside. This is typically achieved by declaring the attributes of a class as private and providing public methods to access and modify these attributes.
For example, consider a BankAccount class:
public class BankAccount {
private String accountNumber;
private double balance;
public BankAccount(String num, double bal) {
accountNumber = num;
balance = bal;
}
public double getBalance() {
return balance;
}
public void deposit(double amount) {
if (amount > 0) {
balance += amount;
}
}
public boolean withdraw(double amount) {
if (amount > 0 && amount <= balance) {
balance -= amount;
return true;
}
return false;
}
}
In this class, the balance (and accountNumber) attribute is private, meaning it cannot be accessed directly from outside the class. Instead, the getBalance, deposit, and withdraw methods represent the object interface and provide controlled access to the balance. This ensures that any changes to the balance attribute are validated, maintaining the integrity of the associated data:
public class Program {
public static void main(String[] args) {
BankAccount account1 = new BankAccount("A0123", 1000);
account1.withdraw(2000); // false: cannot withdraw more than 1000
System.out.println("Balance: " + account1.balance);
}
}
In the above Program class, any changes to the balance are performed via the withdraw method. Because the balance available on the account “A0123” is 1000, attempting to withdraw 2000 will not be allowed by the logic implemented within the withdraw method, preventing any anomalies in the program execution.
Now, let’s imagine that the balance attribute in the previous BankAccount class is public. As a result, it can be modified directly from the Program class:
public class Program {
public static void main(String[] args) {
BankAccount account1 = new BankAccount("A0123", 1000);
double amount = 1500;
account1.balance = account1.balance - amount; // balance is negative: -500
System.out.println("Balance: " + account1.balance);
}
}
In this scenario, the code in the Program class can directly update the balance attribute of the BankAccount class, bypassing any checks implemented in the withdraw method designed to prevent the balance from going negative. This could lead to data integrity issues, resulting in errors and anomalies within the program.
Accessor Methods: Getters and Setters
Accessor methods, commonly known as getters and setters, are crucial to encapsulation. Getters are methods that retrieve the value of an attribute, while setters are methods that set or update the value of an attribute. These methods provide controlled access to the attributes, allowing for validation, enforcing of rules, and other logic to be applied when getting or setting values.
For instance, consider the yearOfBirth attribute in a Person class:
public class Person {
private String name;
private String surname;
private int yearOfBirth;
private String address;
public Person(String n, String s) {
name = n;
surname = s;
}
public int getYearOfBirth() {
return yearOfBirth;
}
public void setYearOfBirth(int yearOfBirth) {
int currentYear = // contains the current year
if (yearOfBirth > 0 && yearOfBirth <= currentYear) {
this.yearOfBirth = yearOfBirth;
} else {
System.out.println("Error! Invalid year of birth.");
}
}
public String getAddress() {
return address;
}
public void setAddress(String addr) {
address = addr;
}
public String getName() {
return name;
}
public String getSurname() {
return surname;
}
}
In this example, the setYearOfBirth method includes a check to ensure that the yearOfBirth is a valid year. The logic for the check is implemented in a single place within the same class, and other classes are forced to perform any updates on that attribute via the provided setter. This prevents invalid data from being assigned to the attribute, thereby maintaining data integrity during the program execution.
Implementation Hiding
With encapsulation, the internal representation of the attributes of a class is hidden and abstracted from the outside world, allowing for implementation hiding.
In the real-world example of using a microwave oven, if a new disruptive technology for generating microwaves is developed and integrated into a new device we buy, we do not need to be aware of these changes as long as the way we operate the microwave—the interface—remains the same.
In object-oriented programming, this means that it is possible to change the internal implementation of a class, such as an attribute type or representation, without affecting the external code that uses the class. For instance, we can decide to change the way the address information is stored in the previous Person class from a single string to an Address object, as we want to take advantage of the address parsing and validation functionalities already available in that class. A simplified example of such Address class might be:
public class Address {
private int number;
private String street;
private String city;
private String postcode;
public Address(String address) {
// split the address in tokens based on the ','
String[] tokens = address.split(",");
number = Integer.parseInt(tokens[0]);
street = tokens[1];
city = tokens[2];
postcode = tokens[3];
// checks isValid and prints an error in case
if (checkIsValid() == false) {
System.out.println("Invalid address");
}
}
// should check whether it is a valid address
// always returns true for now
private boolean checkIsValid() {
// for example, validates the postcode against
// street name, number, etc.
return true;
}
// format the output indicating number, street, city and postcode
public String toString() {
return "Number: " + number +
", Street: " + street +
", City: " + city +
", Postcode: " + postcode + "\n";
}
}
An updated version of the code of the Person class that uses the Address class for the address attribute is shown below:
public class Person {
private String name;
private String surname;
private int yearOfBirth;
private Address address;
public Person(String n, String s) {
name = n;
surname = s;
}
// getter/setter methods yearOfBirth attribute as above
// ...
public String getAddress() {
return address.toString();
}
public void setAddress(String addr) {
this.address = new Address(address);
}
// getter methods for name and surname attributes ass above
// ...
}
Whilst the internal representation of the address attribute changed, the class (and object) interface did not. It can be noted that all the public methods still have the same signature (i.e., the combination of name, return type and parameters) as in the first Person class example where the address attribute was String. Notably, also the signature of the getter and setter methods for the address attribute has not been changed, as both methods still return and accept data as a String.
With this modification, the Address class might now handle parsing and validating the address string, but the Person class interface remains the same. This change is hidden from the users of the Person class, demonstrating implementation hiding. As a result, any code that uses the Person class does not need to change.
For example, the following Program class remains unaffected, as the getAddress and setAddress method can still be invoked as before because they still return and accept a String object:
public class Program {
public static void main(String[] args) {
Person p1 = new Person("Tom", "Green");
p1.setAddress("30, Hampstead Ln, London, N6 4NX");
System.out.println(p1.getName() + " lives at " + p1.getAddress());
}
}
This demonstrates how encapsulation greatly improves code flexibility and maintainability. By hiding the internal object’s state and requiring all interactions to go through its public methods, changes to a class's internal implementation can be performed without affecting other parts of the program. As a result, a program code becomes more modular and easier to maintain.
Conclusions
Encapsulation is a strong principle in OOP that supports data hiding and integrity, implementation hiding, and boosts code flexibility and maintainability. It helps create robust, modular, and maintainable software systems where the likelihood of anomalies due to erroneous data is prevented by bundling data and methods and controlling access to the internal state.
Subscribe to my newsletter
Read articles from Francesco Tusa directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by