Experiments with gpt-4o vision and architecture diagrams
 Dhaval Singh
Dhaval Singh
I was playing around with 4o’s vision capability, especially for extracting complex technical architecture diagrams and here is how i did it. It’s a bit too early for conclusion on what works and what doesn’t. More on that in later posts.
What do we want out of this?
I am basically trying to find an optimal setting for LLMs to be able to read technical architecture diagrams correctly and consistently.
Setting up eval
There is almost no point in experimenting with LLMs if you dont have any kind of eval setup. Even the most rudimentry, basic stuff will work. But you need something.
I have always been meaning to try out Promptfoo’s eval library, as it has been made with a very similar thought process as to how we have built our internal eval at Seezo. Run via yaml files, keeping everything in config, showing HTML reports, etc.
Anyway, the setup is pretty straigtforward. You can get up and running in less than an hour if you have your API keys ready :)
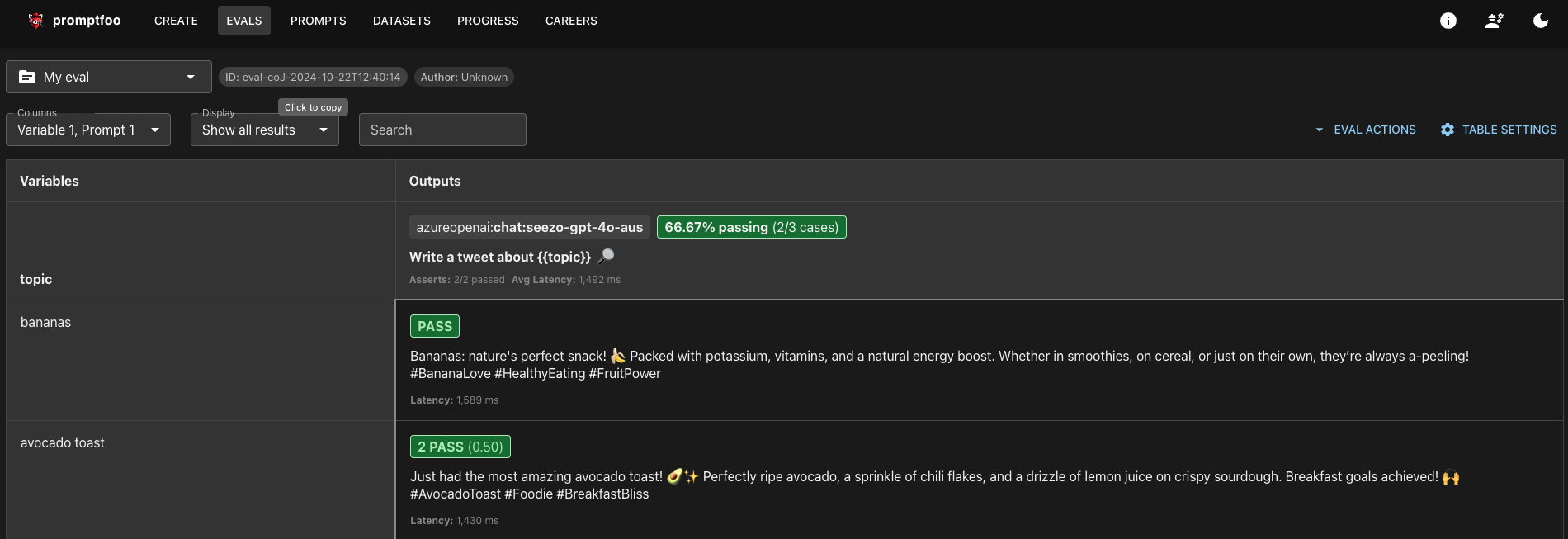
Once i had the sample eval up and running, it’s time to figure out what exactly we want to evaluate.
Dataset and Ground truth
I went with this diagram(found randomly on the web, just search for “AWS Architecture diagram“). We have done some experiments interally on this and noticed 4o is inconsistent with extracting components, especially the “OpenID Connect” entity.

So, we have out basic dataset(the img) and we know what we are looking for, ie: “OpenID Connect“. This is our ground truth.
The idea is to tell the LLM to extract all entities from the img and check if it is able to get “OpenID Connect“. This is our “Pass” metric.
Setting up eval assertions
Doing these kinds of eval is pretty easy with promptfoo. This is how my config file looks like:
description: "AWS Vision eval: OpenID Connect"
prompts:
- file://vision_prompt.json
providers:
- id: azureopenai:chat:<enter your deployment name>
label: openai-gpt-4o-hightemp
config:
apiHost: <enter your endpoint here>
temperature: 0.7
max_tokens: 4096
defaultTest:
options:
provider:
id: azureopenai:chat:<enter your deployment name>
config:
apiHost: <enter your endpoint here>
tests:
- vars:
question: file://vision_prompt.txt
url: 'https://i.imgur.com/xhaLcKB.png'
options:
transformVars: |
return { ...vars, image_markdown: `` }
assert:
- type: icontains-all
value:
- 'OpenID Connect'
- 'Amazon S3'
I spent some time experimenting with different types of asserts and llm-based rubriks. But for now, this is more than enough for our current usecase.
assert:
- type: icontains-all
value:
- 'OpenID Connect'
- 'Amazon S3'
What this test means is, we will check if the LLM response contains 'OpenID Connect' and 'Amazon S3'(added this to see if it is missing one thing in particular) and it is done in a case-insensitive manner.
I have linked the image via URL(couldn’t figure out a direct way add images without copypasting the base64 format in the config itself).
The vision prompt format is very simple
[
{
"role": "user",
"content": [
{
"type": "text",
"text": "{{question}}"
},
{
"type": "image_url",
"image_url": {
"url": "{{url}}"
}
}
]
}
]
This is the prompt we are starting with:
Analyze the architecture diagram carefully and perform the following step:
Text Extraction and Labeling: Identify and transcribe all visible text in the diagram, keeping the original formatting, capitalization, and technical terms intact. For any text that is partially visible or unclear, mark it with [unclear].
Running our eval!
Our first run is with temp 0.7
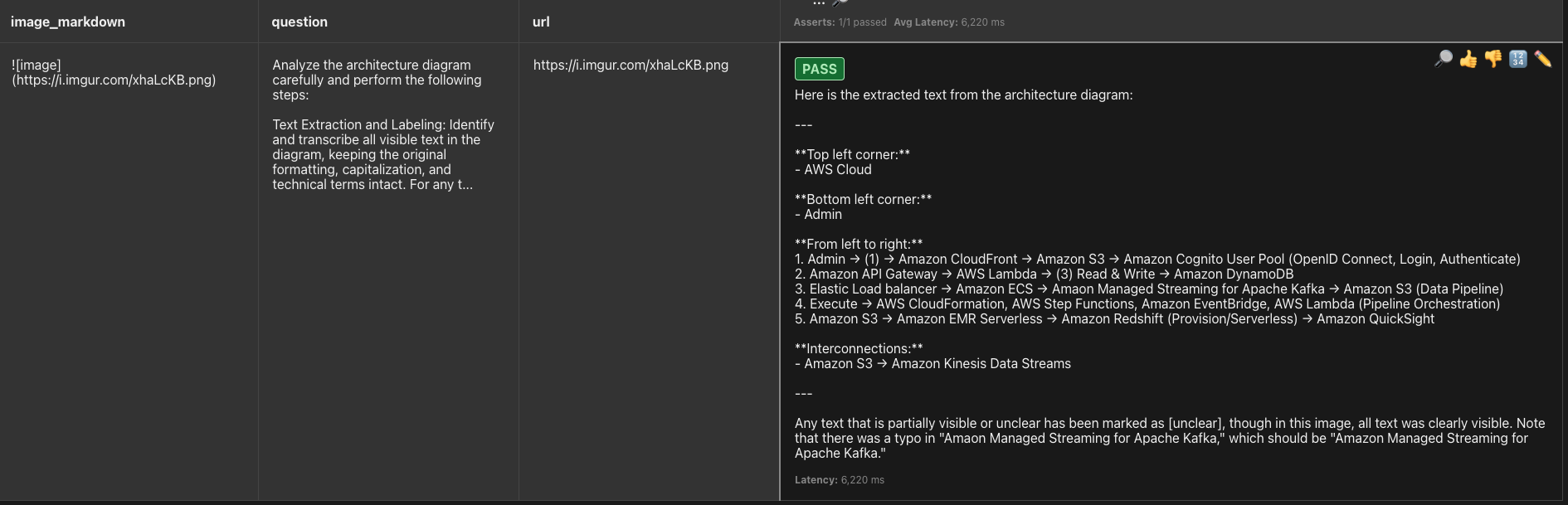
Great! It passes in the first try. The output seems to be pretty decent.
So, is the experiment over?
NOT EVEN CLOSE.
Let’s run it 10 times and see what happens :)
promptfoo eval --repeat 10
It is able to find both entities 9/10 times! Not bad at all.
It fails once, exactly where we thought it would.
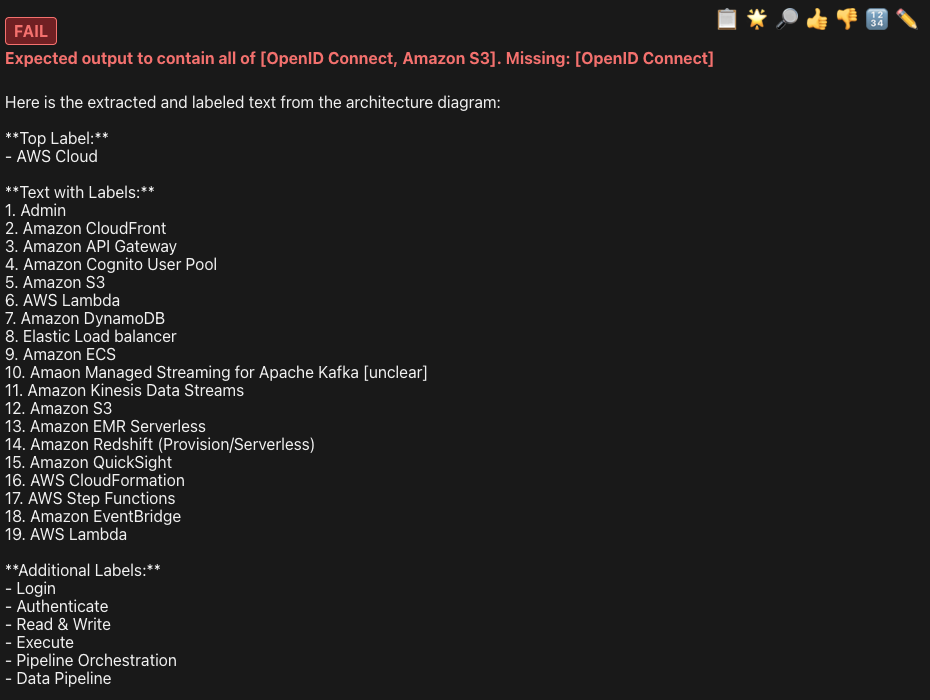
Lets try with few different temperatures and see what happens. Let’s run 10 times each for 0.0, 0.5 and 0.7

It only fails in 0.7, twice this time.
What’s next?
Now we have our basic eval setup, we will do more experiments on this by tweaking the hyperparams like top_p, presence_penalty, frequency_penalty, etc.
We will also try for different images and see what happens!
Subscribe to my newsletter
Read articles from Dhaval Singh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by