Building your own basic RAG Pipeline with Langchain and Llama3 - Part 1
 Tarannum
TarannumIn simple words, a RAG pipeline, retrieves texts from a retriever, asks a text generation model to augment it’s response.
Describing more, it retrieves relevant documents or data chunks from a large corpus using a retriever, then feeds this information into a language model to generate a response, getting a contextually accurate response.
We could split the whole RAG pipeline into 2 flows: Ingestion of data and Querying
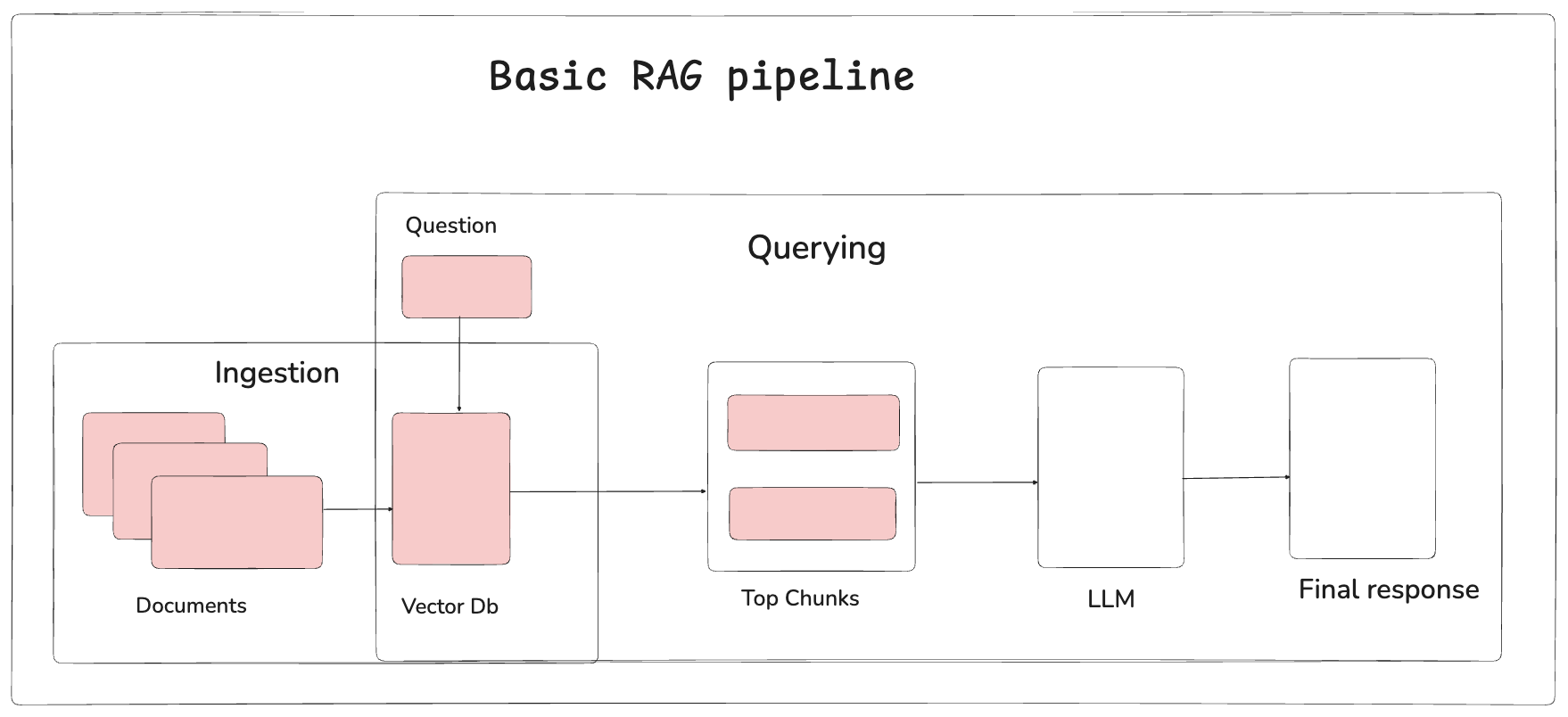
How do I tell my LLM that it needs to search for answers from the data I have provided? You can ingest data into a vector store and get answers using an LLM by invoking it with a query and retrieved context.
WHY LLAMA?
While building a Retrieval-Augmented Generation (RAG) pipeline using OpenAI's GPT offers a simple solution, it involves sending your data to OpenAI's servers, which raises security concerns. For sensitive or confidential information that must remain within your own environment, hosting your own Large Language Model (LLM) is the best solution to ensure data privacy and security.
How to build one?
If we split the RAG flow, ingestion could be split into these parts:
Load any document and extract text from it
Chunk the Text into size of your choice
Create embeddings for the Text
Store it in a vector store of your choice
If we could split the retriever part of RAG flow,
Pass in a query
Use the query to search for context in our vector store
Take the query and the context and ask LLM to provide an answer
Voila, you’ve built yourself a RAG chain.
How does Langchain make this better?
Langchain is a framework to get to these steps easier. It simplifies your process.
What does embedding text even mean?
Basically you convert your data into vectors as shown in the image below for machines to understand. The text is converted into vectors to capture it’s meaning. Similar ideas end up with similar vectors, making it easier to allow system to measure and compare the semantic similarity of different pieces of text. This mathematical representation enables efficient retrieval and reasoning over text data based on the meaning it encodes.
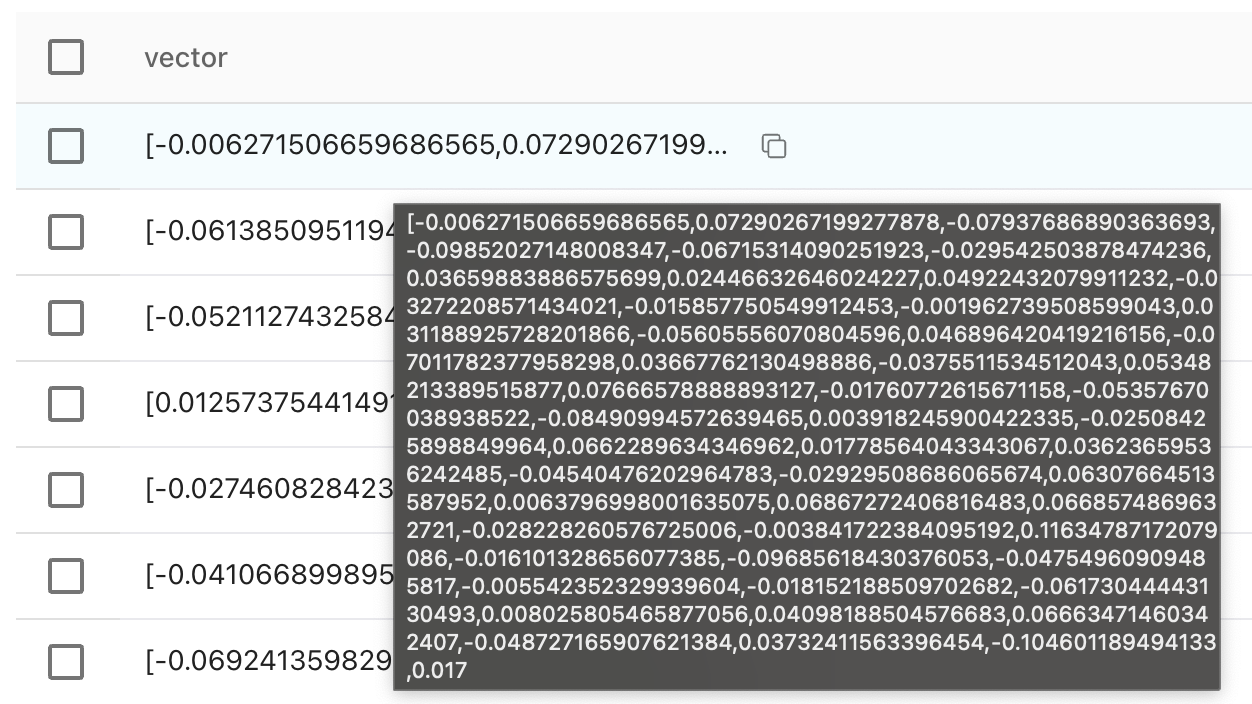
Enough talking should we look at some code?
How do I bring up my Llama3?
If you want to host your LLM locally, you can use Ollama to get LLM of your choice up.
Install Ollama
Run the command
ollama run llama3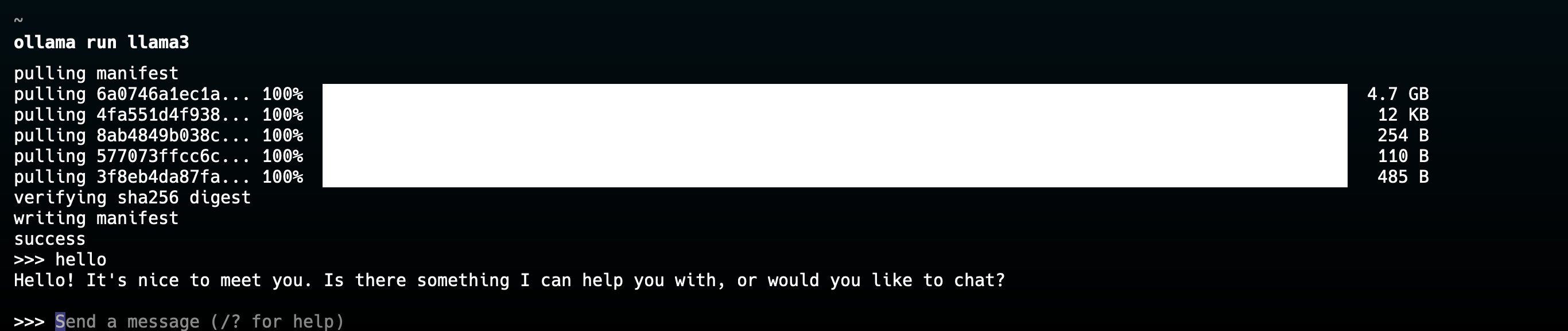
Code
Let’s do some initial setup
We will be using ChromaDB as our vector store. Let’s set it up.
Set up Ollama in your machine and use the model needed (Llama3 in our case)
Declare your ChromaDB client, embedding model and give a collection name.
llm = Ollama("llama3")
client = chromadb.HttpClient(host="localhost", port=8083)
embedding_function = HuggingFaceBgeEmbeddings()
collection_name = "test-collection"
langchain_chroma = Chroma(
client=client,
collection_name=collection_name,
embedding_function=embedding_function,
)
The populate_data method will store the data for a folder path passed as argument.
TextLoader, a document loader provided by langchain will load only .txt filesRecursiveCharacterTextSplitteris a text splitter which splits text based on chunk size and overlap size you have provided.It will create a list of Documents with filename as metadata and store them in ChromaDB. Langchain will take care of creation of collection, indexing and storing.
def populate_data(filenames):
all_docs = []
for file_name in filenames:
loader = TextLoader(file_name)
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=2000, chunk_overlap=200)
docs: list[Document] = text_splitter.split_documents(documents)
for doc in docs:
doc.metadata = {
"file_name": file_name
}
all_docs += docs
langchain_chroma.add_documents(documents=all_docs)
The retrieve_answers method will take in a question and return a response. We have pulled the basic prompt from langchain hub, but you can pass in customisable prompts.
context | format_docspasses the question through the retriever(Chroma), extracting Document objects, and then toformat_docsto generate stringsRunnablePassthrough()passes through the input question unchanged.The input to
promptis expected to be a dict with keys"context"and"question"The last step is where
StrOutputParser()extracts the string content from the LLM's output response.You invoke the
rag_chainto retrieve answers
def retrieve_answers(question):
context = langchain_chroma.as_retriever()
def format_docs(docs: list[Document]) -> str:
"""Convert document page content to string by replacing new line character."""
return "\n\n".join(doc.page_content for doc in docs)
rag_prompt = hub.pull("rlm/rag-prompt")
rag_chain = (
{"context": context | format_docs, "question": RunnablePassthrough()}
| rag_prompt
| llm
| StrOutputParser()
)
result = rag_chain.invoke(question)
return result
Entire code:
import chromadb
from langchain import hub
from langchain_chroma import Chroma
from langchain_community.document_loaders import TextLoader
from langchain_community.embeddings import HuggingFaceBgeEmbeddings
from langchain_community.llms.ollama import Ollama
from langchain_core.documents import Document
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_core.vectorstores import VectorStoreRetriever
from langchain_text_splitters import RecursiveCharacterTextSplitter
llm = Ollama("llama3")
client = chromadb.HttpClient(host="localhost", port=8083)
embedding_function = HuggingFaceBgeEmbeddings()
collection_name = "test-collection"
langchain_chroma = Chroma(
client=client,
collection_name=collection_name,
embedding_function=embedding_function,
)
def populate_data(filenames):
all_docs = []
for file_name in filenames:
loader = TextLoader(file_name)
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=2000, chunk_overlap=200)
docs: list[Document] = text_splitter.split_documents(documents)
for doc in docs:
doc.metadata = {
"file_name": file_name
}
all_docs += docs
langchain_chroma.add_documents(documents=all_docs)
def retrieve_answers(question):
retriever: VectorStoreRetriever = langchain_chroma.as_retriever()
def format_docs(docs: list[Document]) -> str:
"""Convert document page content to string by replacing new line character."""
return "\n\n".join(doc.page_content for doc in docs)
rag_prompt = hub.pull("rlm/rag-prompt")
rag_chain = (
RunnablePassthrough.assign(context=(lambda x: format_docs(x["context"])))
| rag_prompt
| llm
| StrOutputParser()
)
result = rag_chain.invoke(question)
return result
Subscribe to my newsletter
Read articles from Tarannum directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by