Kubernetes Learning Week Series 2
 Nan Song
Nan Song
Kubernetes Learning Week Series 1
How to inspect Kubernetes network
https://medium.com/@helpme.zhang/how-to-inspect-kubernetes-networking-0d89dfefee95
This article outlines how to inspect the network in a Kubernetes cluster. It includes finding the cluster IP addresses of Pods and Services, entering a Pod’s network namespace, checking a Pod’s virtual Ethernet interface, and exploring connection tracking and iptables rules. The article also discusses querying cluster DNS and viewing IPVS details in Kubernetes 1.11 and later versions.
Key Points:
Use 'kubectl get pod -o wide' to find the cluster IP of a Pod.
Use 'kubectl get service --all-namespaces' to find the IP of a Service.
Use “nsenter” and the container’s process ID to enter the Pod’s network namespace.
Use the 'ip addr' command to associate the Pod’s virtual Ethernet interface (eth0) with the node’s interface (veth).
Use the “conntrack” command to inspect connection tracking and adjust the maximum number of tracked connections.
Use “iptables-save” to dump the iptables rules and view Kubernetes Service NAT rules.
Use “dig” and the kube-dns Service IP to query cluster DNS.
Use “ipvsadm” to explore IPVS details in Kubernetes 1.11 and later versions.
How Adidas is managing a container platform
https://medium.com/adidoescode/adidas-how-we-are-managing-a-container-platform-1-3-6ce24e756490
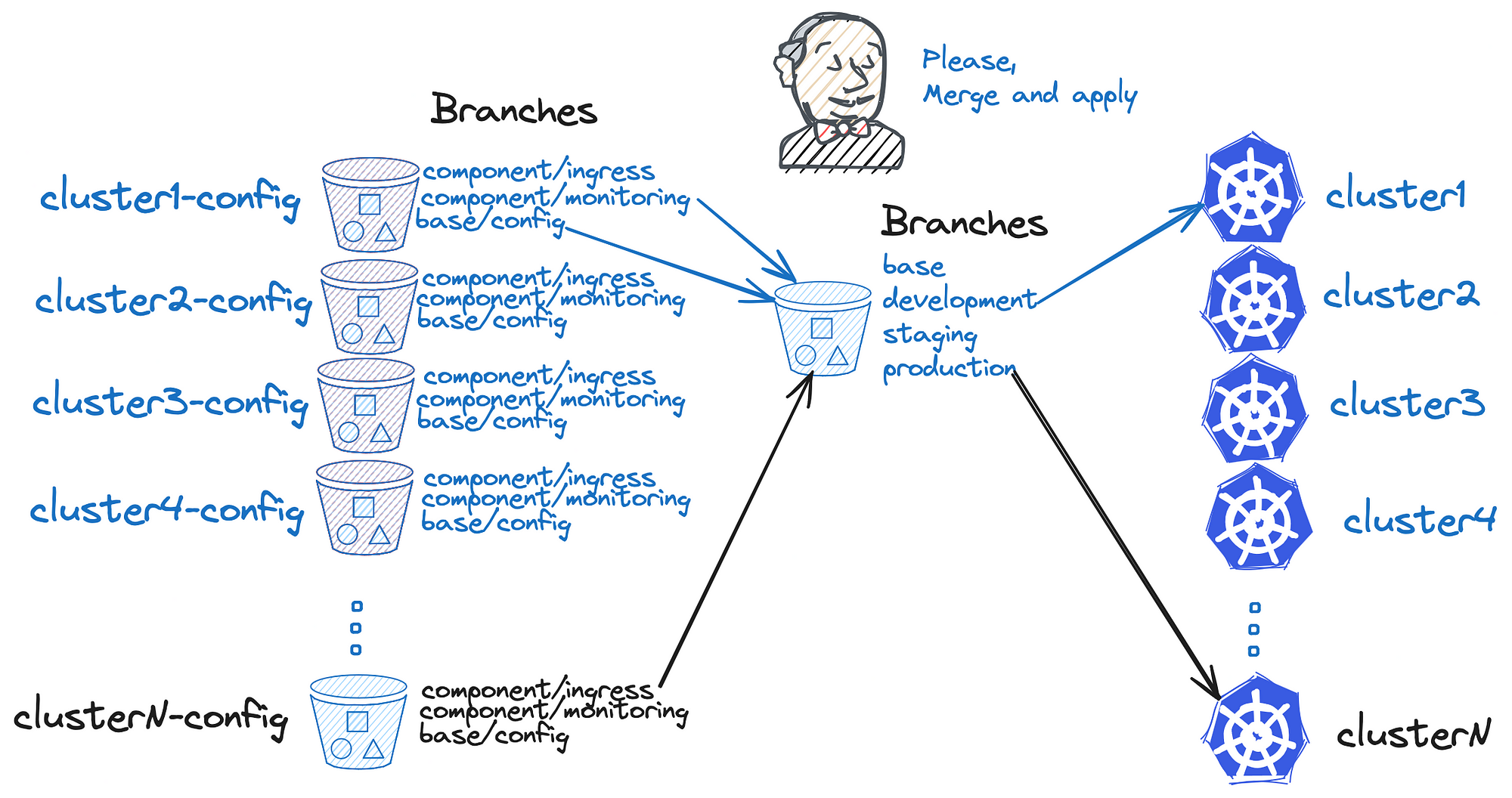
This article discusses how the fashion company Adidas managed the transition of its container platform to a GitOps-based setup, which was a significant strategic move for its technological advancement.
Key Points:
For over five years, Adidas has been enhancing its container platform to enable teams to work more efficiently.
Before the GitOps transition, Adidas had a complex configuration management system with multiple repositories, branches, and pipelines, which was both time-consuming and error-prone.
The main goals of the GitOps transition were to reduce operational time, manage platform clusters more effectively, improve process resilience, and enhance visibility into both global and local configuration states.
Leaky Vessels deep dive
https://dev.to/snyk/leaky-vessels-deep-dive-escaping-from-docker-one-syscall-at-a-time-4479
This article delves into the research conducted by the Snyk Security Labs team on Docker Engine, where they discovered four high-severity vulnerabilities that allow malicious attackers to breach the container environment. The article explores the techniques used to identify these vulnerabilities, including the use of the strace tool to analyze Docker Engine’s internal workings and discover race conditions.
Key Points:
The research team used the powerful Linux tool strace to investigate Docker Engine and identify vulnerabilities.
They discovered a vulnerability (CVE-2024-21626) that allows attackers to exploit a confused deputy situation caused by a race condition to breach the container environment.
Another vulnerability (CVE-2024-23652) allows attackers to delete arbitrary files on the host filesystem by swapping directory trees during container teardown.
A third vulnerability (CVE-2024-23651) is a race condition that allows attackers to perform arbitrary bind mounts, effectively accessing the host filesystem.
The article also discusses best practices for mitigating such vulnerabilities, such as performing checks and operations on the same file descriptor to avoid race conditions.
How to allocate resources other than cpu or memory inside K8s
https://itnext.io/using-k8s-requests-for-allocating-resources-other-than-cpu-or-memory-75471a390fbb
This article discusses a lesser-known feature in Kubernetes called “Extended Resources,” which allows users to manage and allocate resources on Kubernetes nodes beyond CPU or memory.
Key Points:
The Kubernetes scheduler is unaware of certain node-level resources (like IP addresses), which can lead to scheduling issues.
Extended Resources allow users to advertise and manage these additional node-level resources, making the scheduler aware of them.
Pods can request and use Extended Resources just like they consume CPU and memory, and the scheduler ensures that the requested extended resources are available before scheduling the Pod.
Extended Resources cannot be overcommitted, and if both requests and limits are specified in the Pod spec, the requests and limits must be equal.
Remove specific image from all K8s nodes
https://medium.com/@nmaguiar/removing-specific-images-from-all-kubernetes-nodes-afd248feea60
This article provides a solution to the issue of removing or pulling a specific image from all Kubernetes nodes, even when the image has the same name and tag across different versions.
Key Points:
The root cause of this issue is that each Kubernetes node has its own container image cache, and these nodes may have different versions of the same image.
The solution involves using the crictl CLI tool to list, pull, or remove images on each node, rather than relying on changing the node cache TTL or other workarounds.
The article provides example commands for performing the necessary actions on each node, along with variations for different Kubernetes distributions (K3S, OpenShift/CRI-O, ECR/GKE/AKS).
Additional tips and considerations are provided, such as using shell scripts to automate the process and potential security/storage implications.
7 considerations for multi-cluster kubernetes
https://dev.to/rayedwards/7-considerations-for-multi-cluster-kubernetes-44gb
This article discusses the challenges and considerations organizations face when adopting a multi-cluster Kubernetes or hybrid cloud approach. It highlights key areas that organizations need to address, including cloud orchestration, interoperability, data portability, security and governance, resource optimization, talent shortages, and the complexity of resilience.
Key Points:
Cloud orchestration complexity: Navigating different Kubernetes distributions across cloud providers is a major challenge.
Interoperability: Achieving application interoperability across different cloud environments can be difficult due to vendor-specific customizations.
Data portability: Cloud providers may charge high “data egress” fees for moving data out of their platforms, leading to a “Hotel California” effect.
Security and governance: Ensuring comprehensive security and governance across hybrid and multi-cloud deployments is critical.
Resource optimization: Optimizing resource utilization and cost in multi-cloud environments requires specialized tools and techniques.
Talent shortage: Finding and retaining skilled architects to manage hybrid and multi-cloud environments can be challenging.
Resilience: Implementing strong cloud-native disaster recovery strategies is essential to ensure application availability.
Kubernetes Resiliency(RTO/RPO) in multi-cluster deployments
https://dev.to/rayedwards/kubernetes-resiliency-rtorpo-in-multi-cluster-deployments-32be
Key Points:
Kubernetes provides resilience within a single cluster through volume replication, achieving a zero Recovery Time Objective (RTO) and potentially a zero Recovery Point Objective (RPO).
In multi-cluster deployments across platforms and cloud providers, asynchronous communication between clusters and “north-south” network traffic presents challenges for data resilience and recovery.
Tools like KubeSlice can help address these challenges by establishing low-latency data plane interconnections between clusters, enabling synchronous data replication and faster recovery, achieving near-zero RTO.
When deploying Kubernetes in multi-cluster environments, carefully considering application and data resilience needs is crucial, as it significantly impacts productivity and revenue.
Subscribe to my newsletter
Read articles from Nan Song directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by