Week 20: Real-Time Data Processing with Databricks Autoloader ⏳
 Mehul Kansal
Mehul Kansal
Hey data enthusiasts! 👋
Spark Structured Streaming provides an efficient framework for processing streaming data in real time, while Databricks Autoloader simplifies the process of ingesting streaming data from external sources. In this blog, we will explore how these two powerful tools can be utilized for continuous data ingestion and processing. Let’s get started!
Spark structured streaming
Consider a scenario where we have to find out the trending hashtags on a producer that generates data continuously. The consumer is a Spark structured streaming application that consumes data for processing.
We create a dummy producer that can generate a continuous stream of data, with the help of ‘netcat‘ command that creates a simple TCP socket.

- We start a consumer - Spark structured streaming application, simultaneously.
- For reading the data through socket, we use the following code.

- For processing the data, we use the following code for counting the number of words (hashtags).

- For writing the data to the sink in real-time, we use the following code.

- Now, we enter a line into the TCP socket producer.

- The Spark structured streaming consumer reads the line, processes the data and writes the data in the form of count of each word.
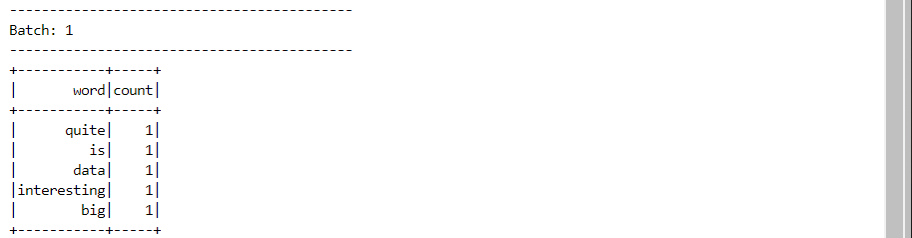
- We enter another line on the producer application.

- The new data gets processed and appended into the previous result, as the data arrives continuously.

Databricks Autoloader
Autoloader acts as a wrapper leveraging Spark structured streaming while also providing additional benefits.
Let’s first consider a scenario where we use ‘copy into‘ command to move data manually.
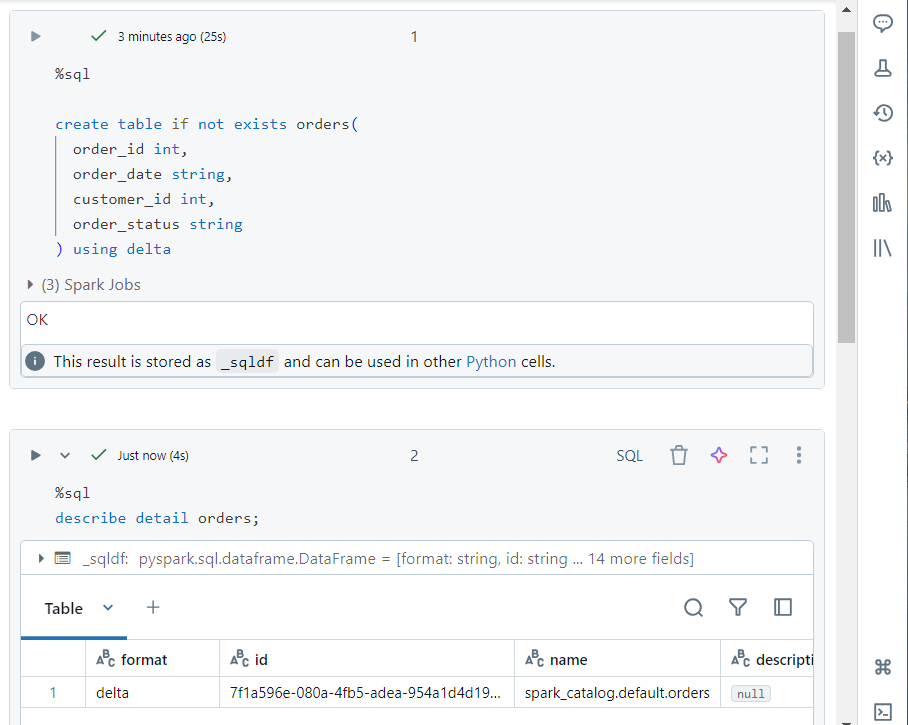
We create a table ‘orders‘ into which data will be copied.
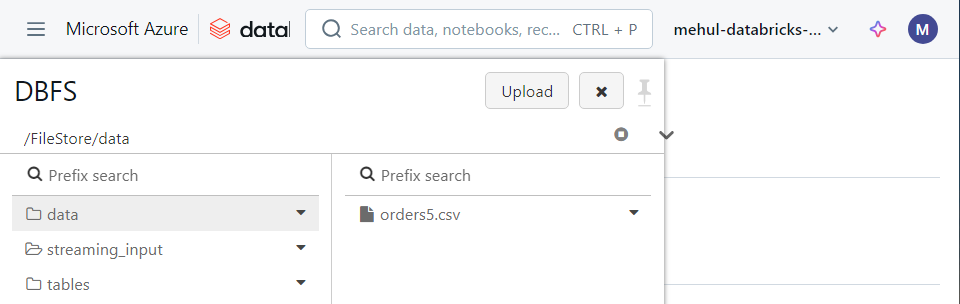
- In DBFS, we upload a file ‘orders.csv‘ where the data resides.
- We can list the files in DBFS as follows.
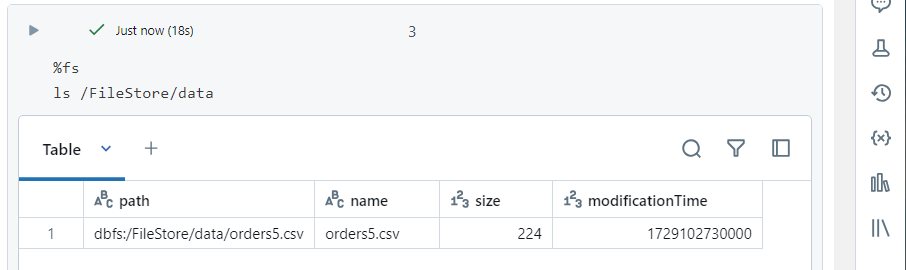
Copy into command
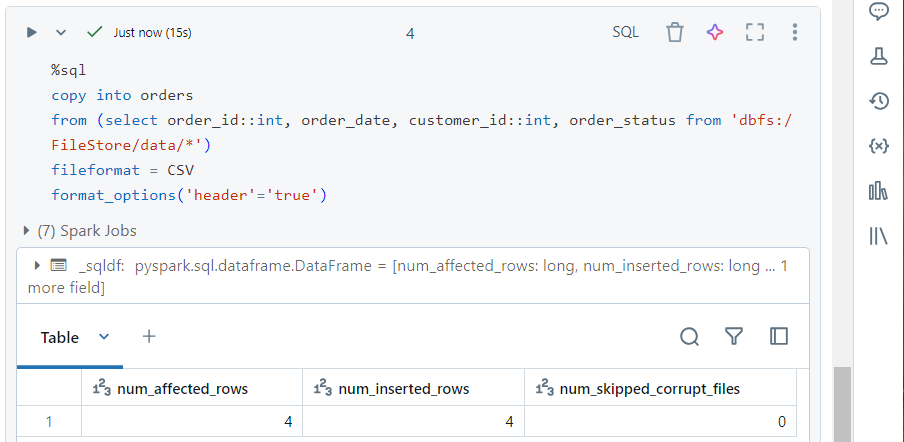
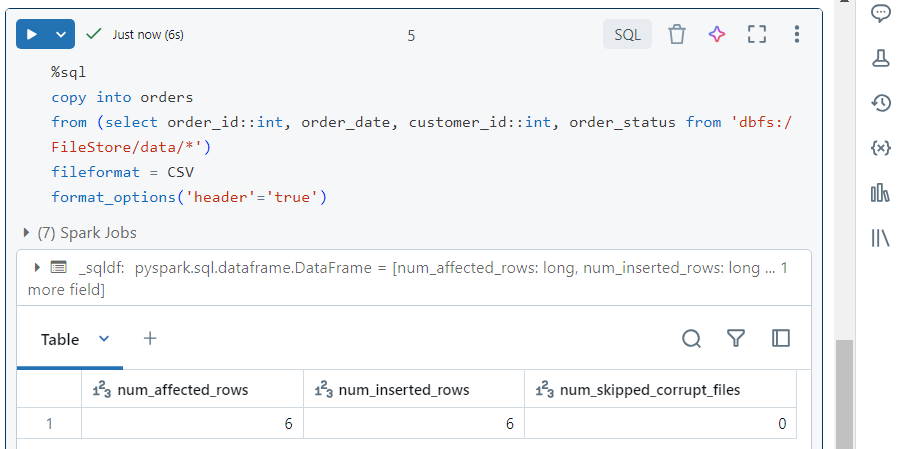
- Now, we use the ‘copy into‘ command to move the data into our ‘orders‘ table, using batch processing.
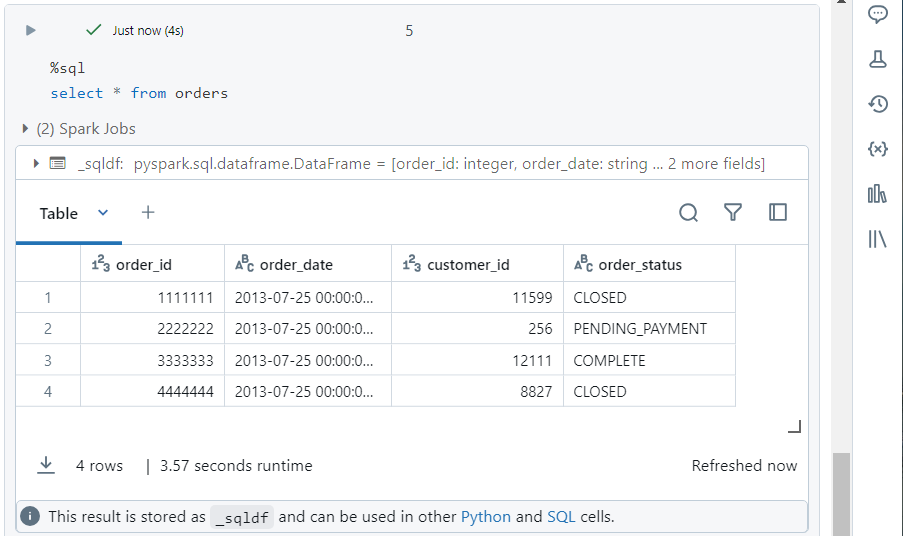
- We can use the typical SQL syntax to verify that the data was indeed copied.
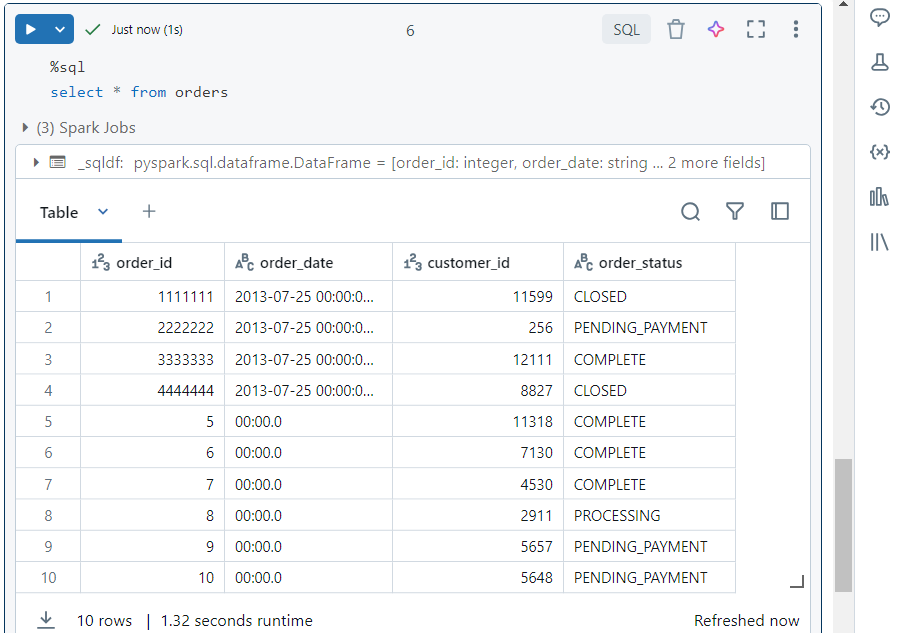
- Now, we need to load more data into the table from the file ‘orders7.csv‘.
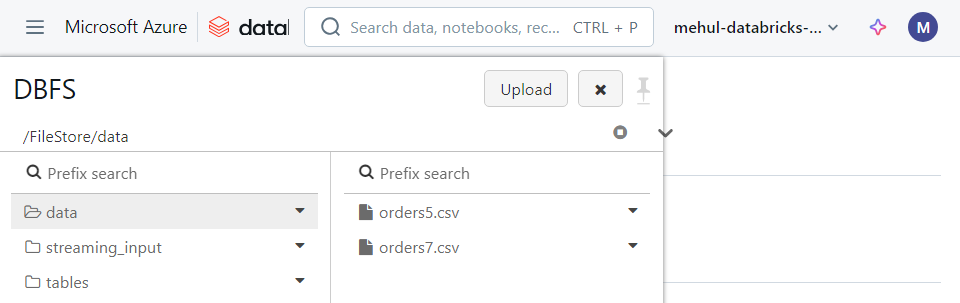
- In order to achieve this, we need to follow the manual process again and run the ‘copy into‘ command.
- We can verify that the new data was also copied.
- Note that ‘copy into‘ works well when the schema is static but it does not support schema evolution.
Copy into vs Autoloader
Unlike ‘copy into‘, Autoloader is used to handle streaming data files.
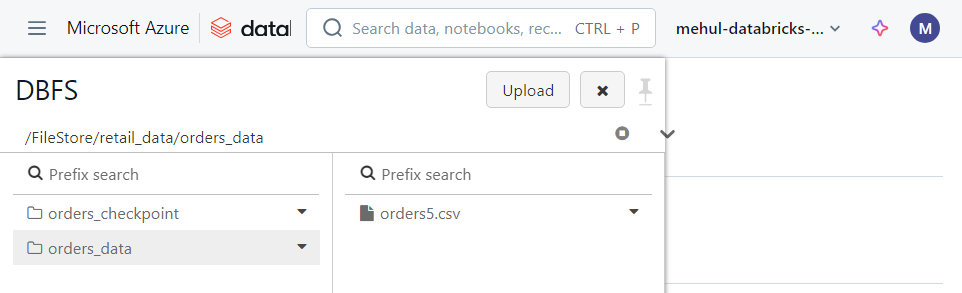
Let’s say we have one file ‘orders5.csv‘ inside DBFS.
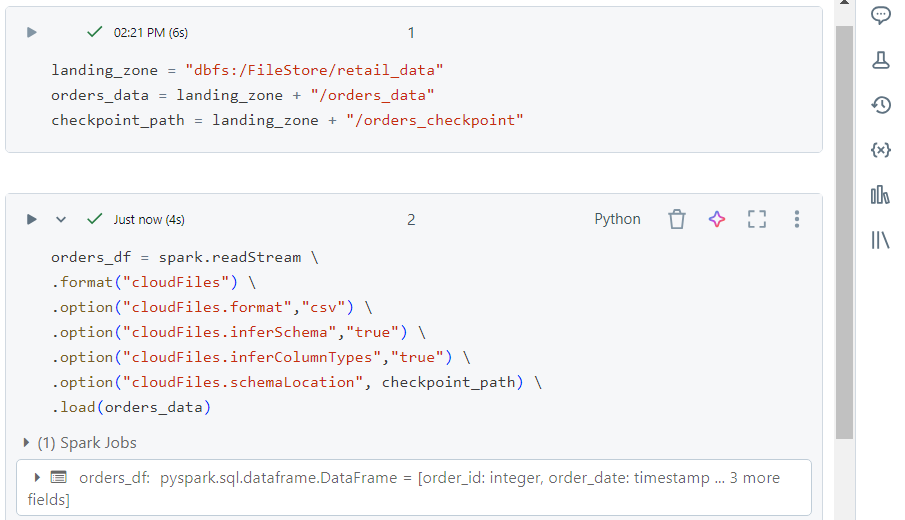
We declare variables specifying the locations at which the files get uploaded and the checkpoint gets created.
Afterwards, we start reading files using ‘readStream‘.
- We can list the data in our dataframe. Note that the display command keeps running, waiting for more files to arrive.
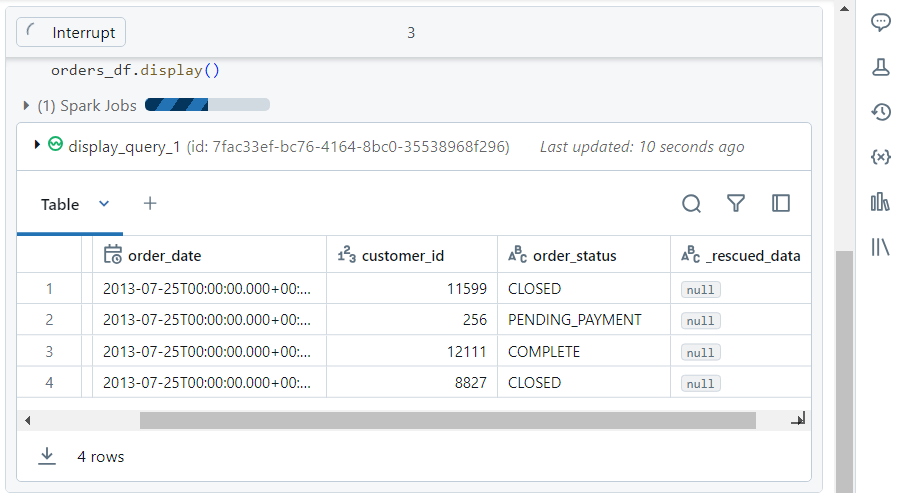
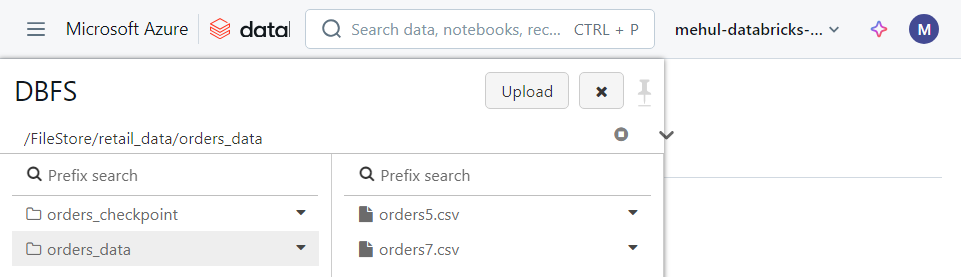
- Now, we upload one more file ‘orders7.csv‘ inside DBFS.
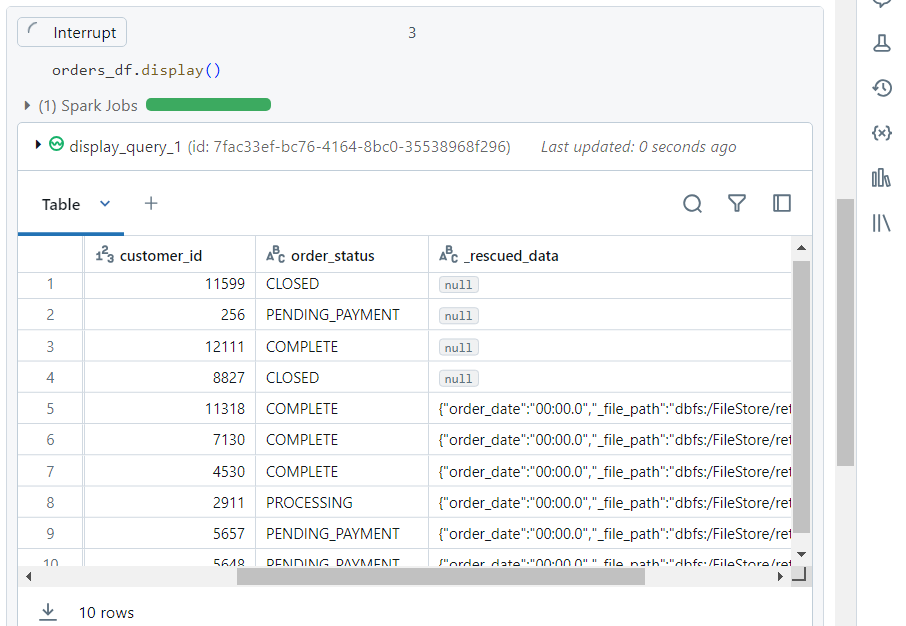
- Due to the ‘readStream‘ command, the display function will automatically load the new data into our dataframe.
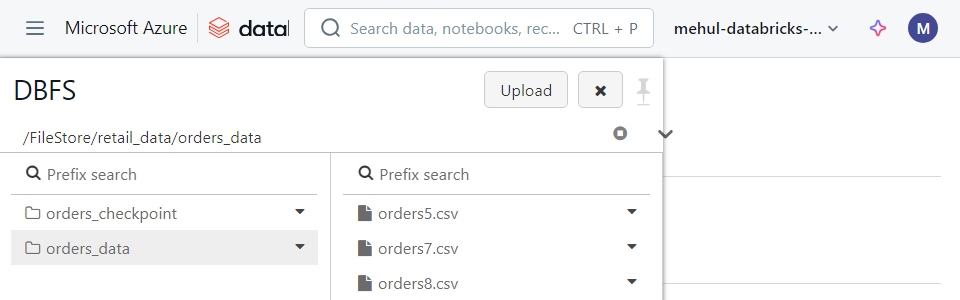
- We can try uploading a file ‘orders8.csv‘ with a different schema - with one new column.
- The job now fails with ‘UnknownFieldException‘.
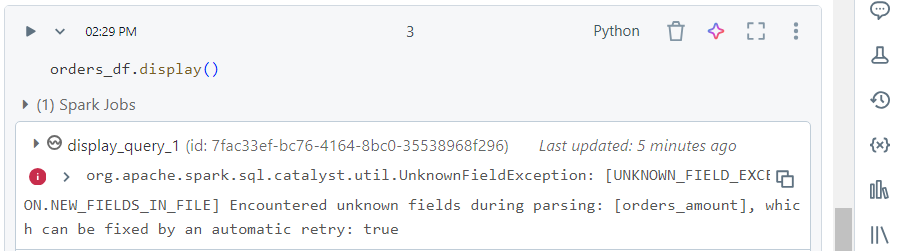
- If we re-run the command, the schema evolves successfully. Note that ‘orders_amount‘ is the new column but with no values.
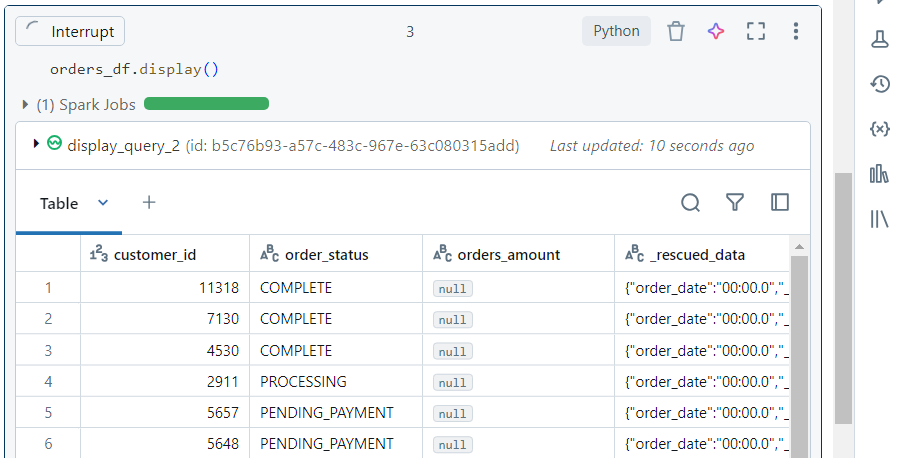
- Consider the scenario where the ‘customer_id‘ column has a mismatched value with respect to the datatype.
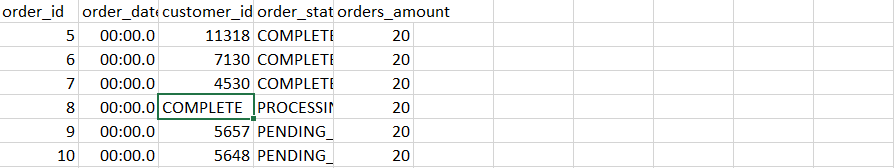
- We upload the file containing this data ‘orders9.csv‘ into DBFS.
- The mismatched data gets captured inside ‘_rescued_data‘ column for future reference.
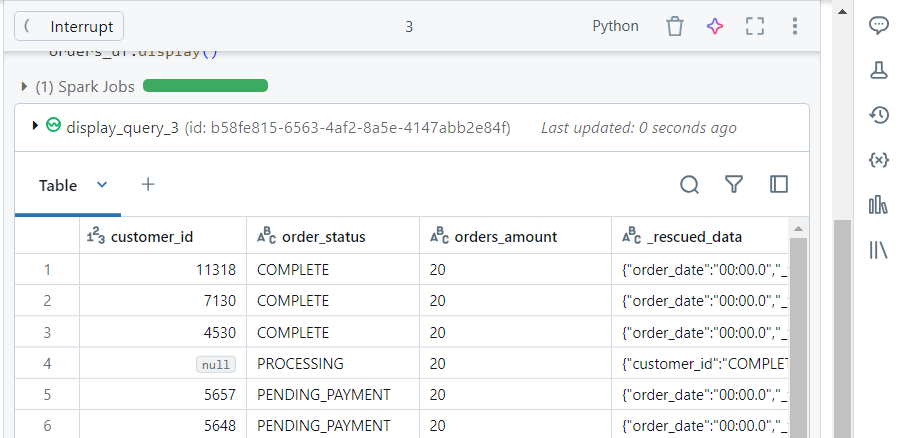
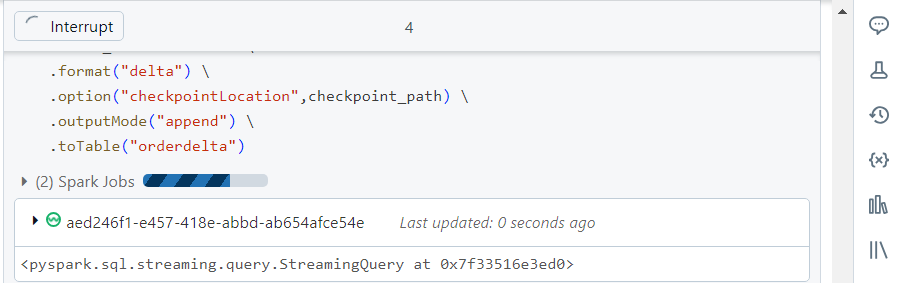
- For writing the above data into the sink table, we use the following syntax:
orders_df.writeStream \
.format(“delta”) \
.option(“checkpointLocation”,checkpoint_path) \
.outputMode(“append”) \
.toTable(“orderdelta”)
- Note that the ‘writeStream‘ operation also keeps running waiting for the new data.
- We can list the data written into ‘orderdelta‘ sink table.
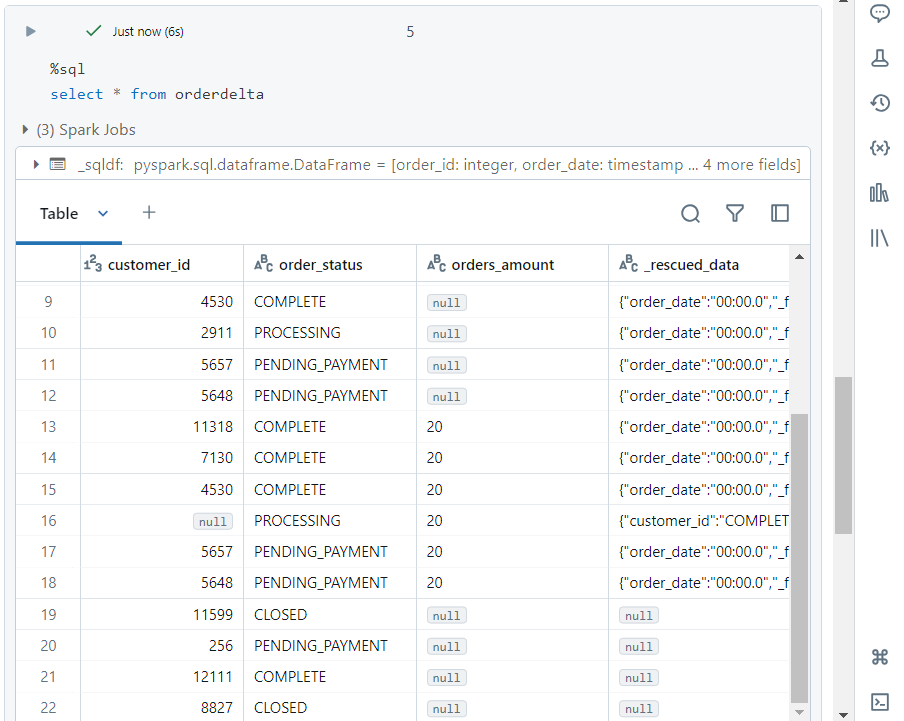
- If we keep uploading new files, the data keeps getting written into the sink.
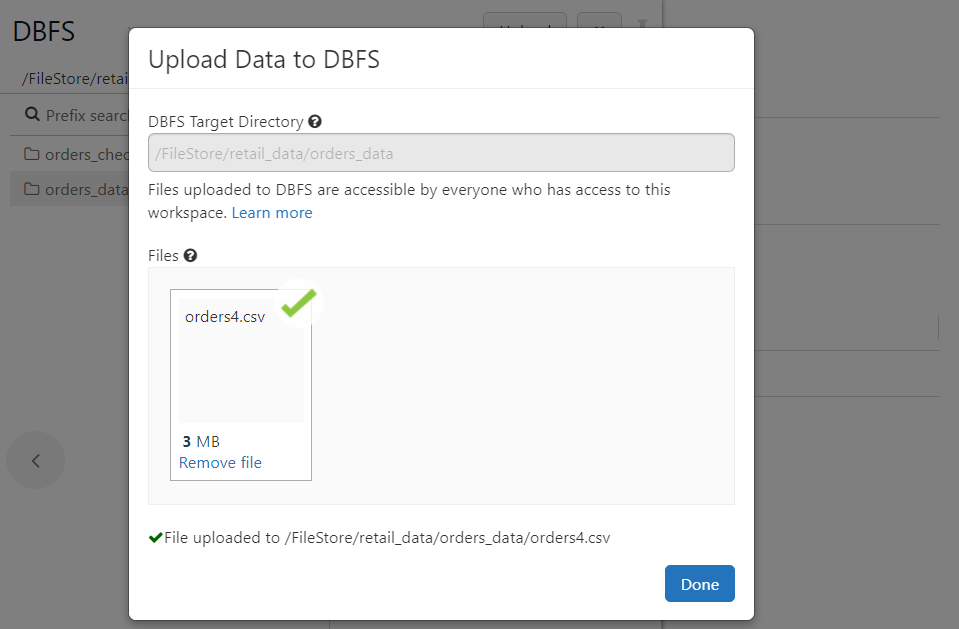
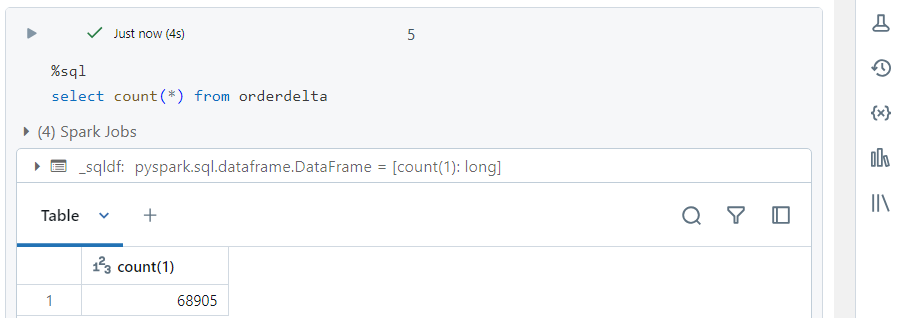
- The latest file ‘orders4.csv‘ contains over 68000 records, all of which get written into sink in real-time.
Accessing ADLS Gen2 using Autoloader
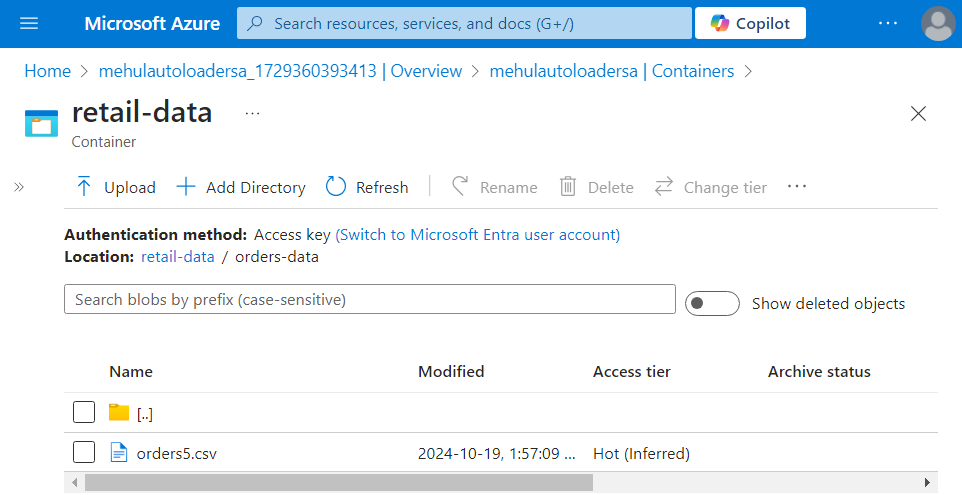
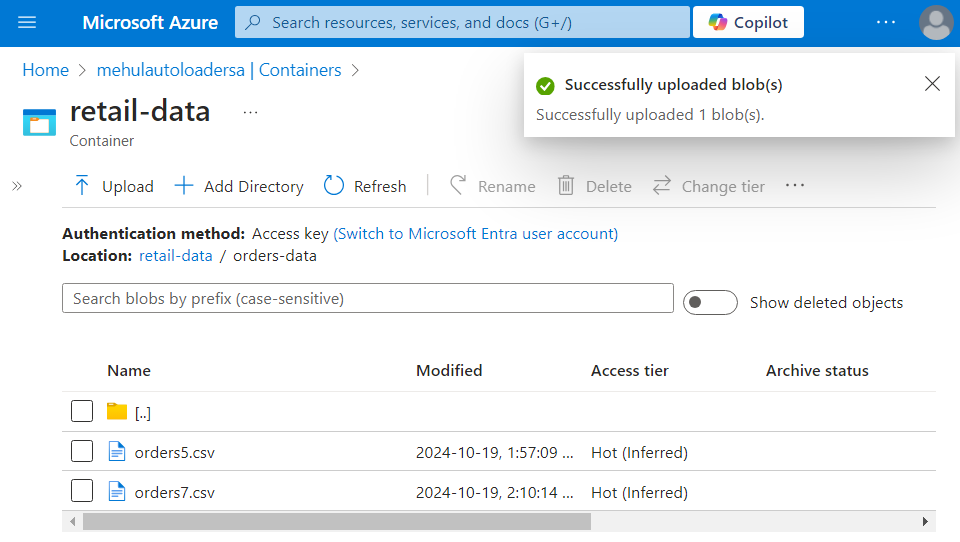
- We have a file ‘orders5.csv‘ inside ‘orders-data‘ directory of ‘retail-data‘ container.
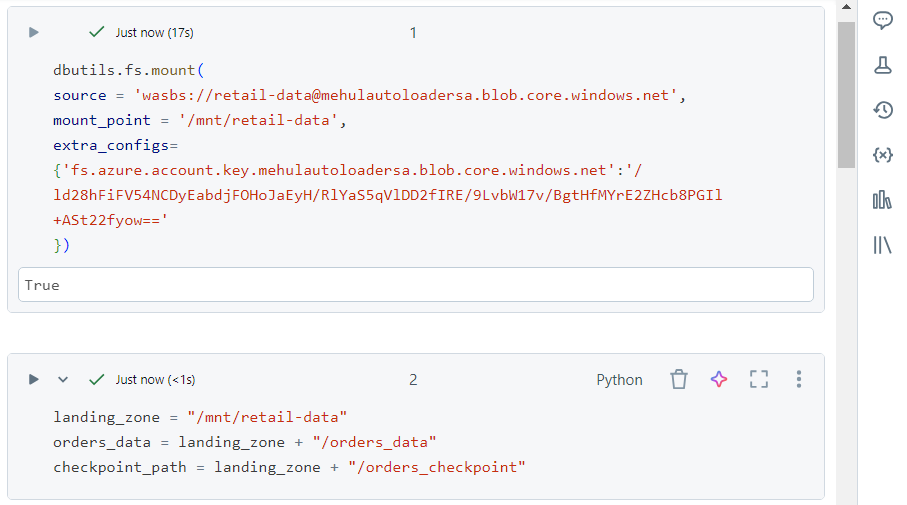
- In order to access the file, we mount the container into Databricks, using the storage account’s access key. We define the variables accordingly.
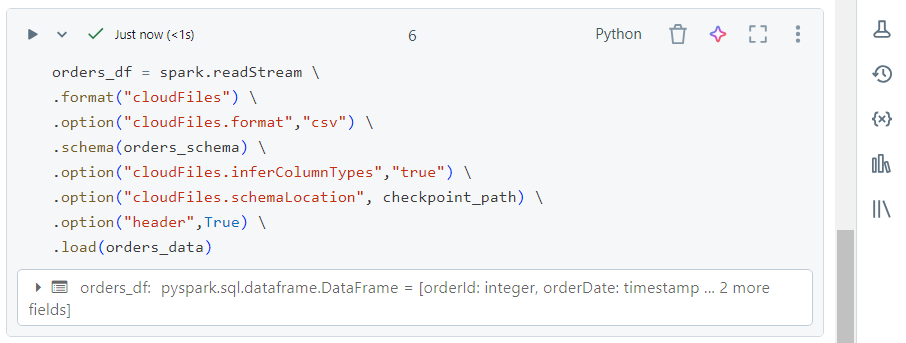
- Now, we can use the typical syntax of Autoloader for reading the streaming data.
- The display function confirms that the data gets read successfully.
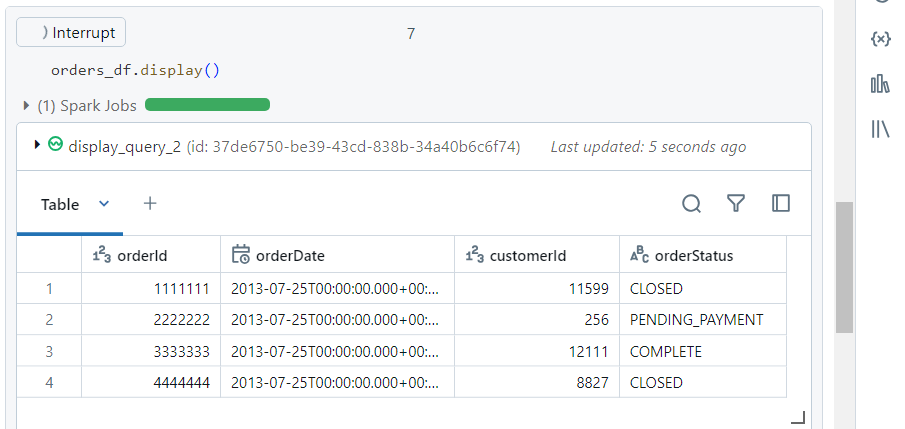
- We upload a new file ‘orders7.csv‘ into the landing folder.
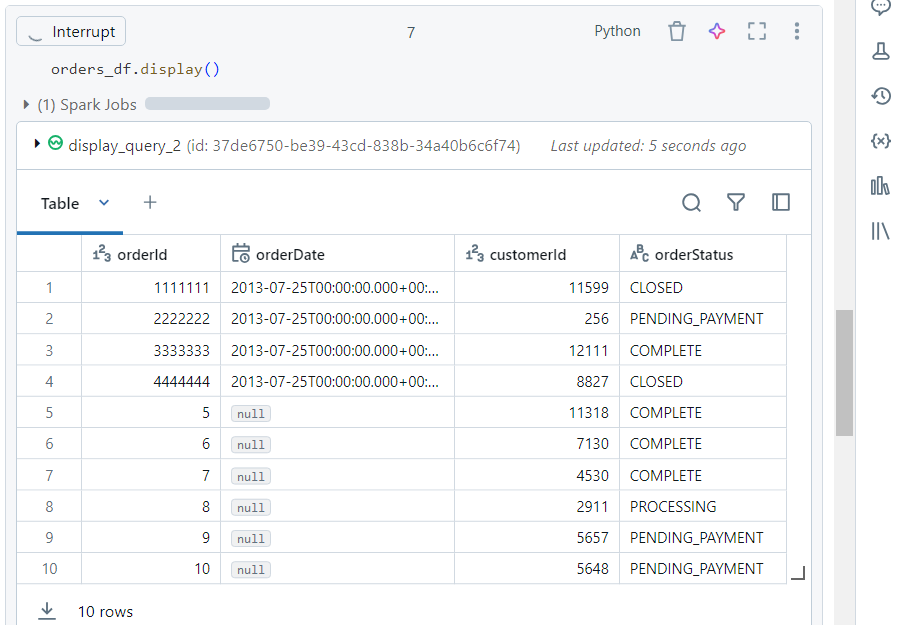
- The data inside new file uploaded into the cloud storage gets read in real-time.
Conclusion
By leveraging Spark Structured Streaming and Databricks Autoloader, you can build a robust and scalable real-time data processing pipeline. Whether it's processing trending hashtags or ingesting retail data into cloud storage, these tools help you process large datasets in real time, allowing you to react to new information as it arrives.
This blog marks the end of my ‘20 Weeks of Data Engineering‘ series. Thank you for following along; I hope it has been insightful, and I appreciate your time and support! 🎯
Subscribe to my newsletter
Read articles from Mehul Kansal directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by