The Transformer Revolution: Breaking Down the Encoder and Decoder
 Himanshu Singh Shekhawat
Himanshu Singh ShekhawatTransformers have taken the AI world by storm, reshaping how we approach problems like language translation, text generation, and even image recognition. But at the heart of these advanced AI models lies a relatively simple yet powerful architecture made up of two essential building blocks: the encoder and the decoder.
In this blog, we’ll explore the fundamentals of the transformer model, focusing on the encoder and decoder components. I’ll take you from the basics all the way to advanced concepts, illustrating key ideas with easy-to-understand images. By the end of this post, you’ll have a solid grasp of how transformers work and why they’re so revolutionary.
What Exactly is a Transformer?
First off, let's talk about what a transformer is in the world of AI. If you’re familiar with older models like RNNs (Recurrent Neural Networks) or LSTMs (Long Short-Term Memory networks), transformers are kind of like their smarter, faster cousins. Instead of processing data step by step, transformers process all the information at once, allowing for better understanding of complex relationships—especially in text.
Transformers are used in AI for tasks like machine translation (think Google Translate) and text generation. And all of this is powered by the encoder and decoder inside the transformer architecture.
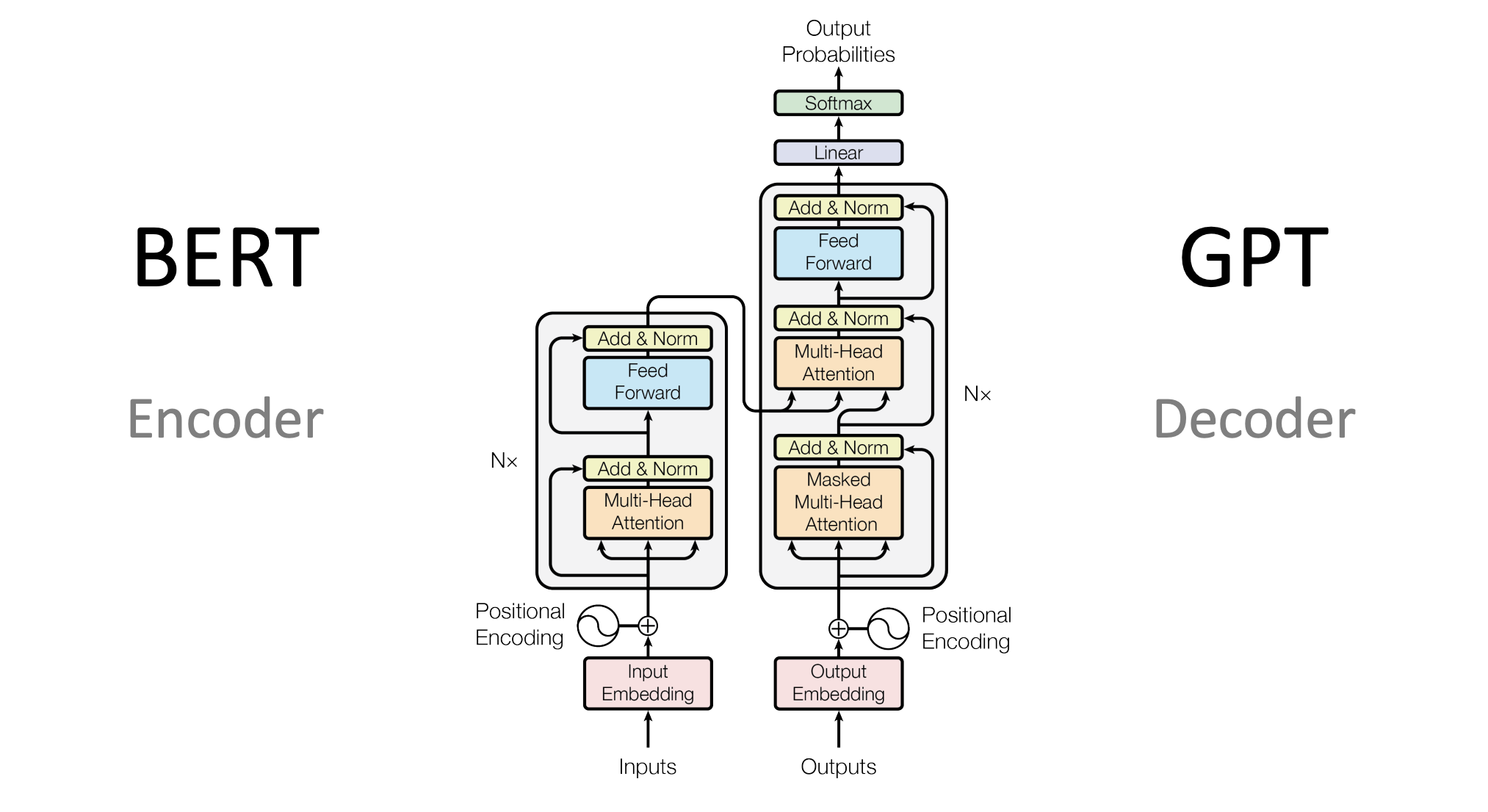
Part 1: The Encoder – Understanding the Input
The encoder is like the brain that processes the input. If you're translating a sentence, the encoder reads and understands the sentence in its entirety. In a transformer, the encoder doesn’t just take the sentence word by word—it looks at the whole sentence at once, weighing which parts are most important in understanding the overall meaning.
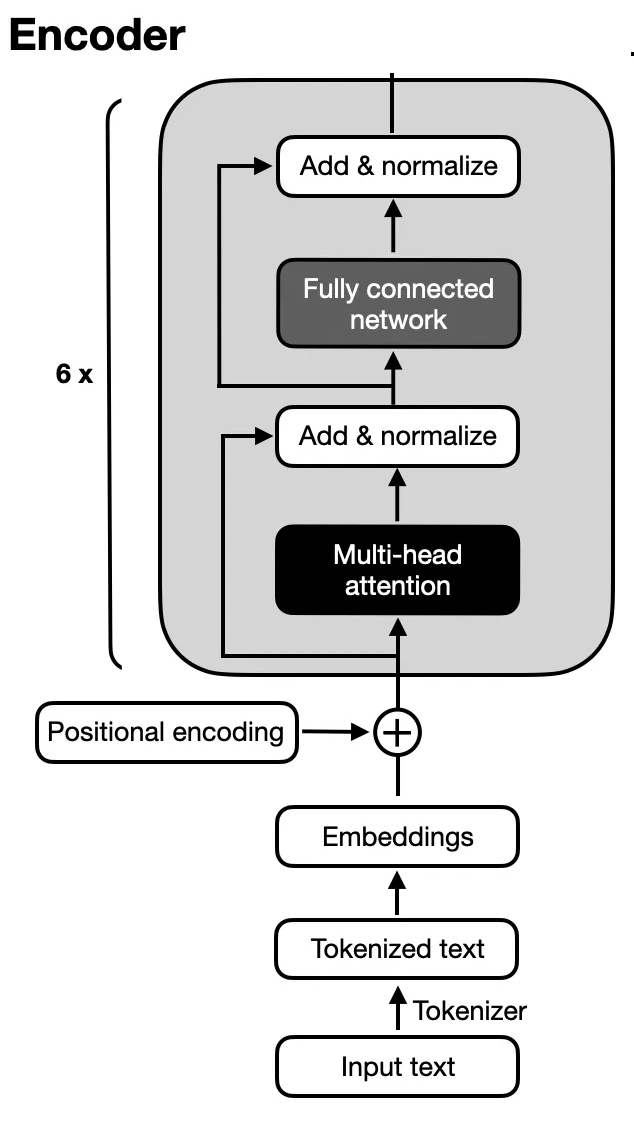
how the encoder works, step by step:
1. Self-Attention: The Heart of the Transformer
Self-attention is like a spotlight that shines on each word in the input sequence, but with a twist—it shines brighter on the more important words. So, instead of treating every word equally, self-attention lets the model focus on certain words that are more relevant to the context.
Imagine the sentence: "The dog chased the cat." When the model is processing "chased," it’s important to know that "dog" is doing the chasing and "cat" is being chased. Self-attention helps the model figure that out by comparing every word to every other word.
how it works:
Query (Q): What are we looking at?
Key (K): What’s the meaning of each word?
Value (V): How important is each word in this context?
These three vectors are what help the model understand relationships between words.
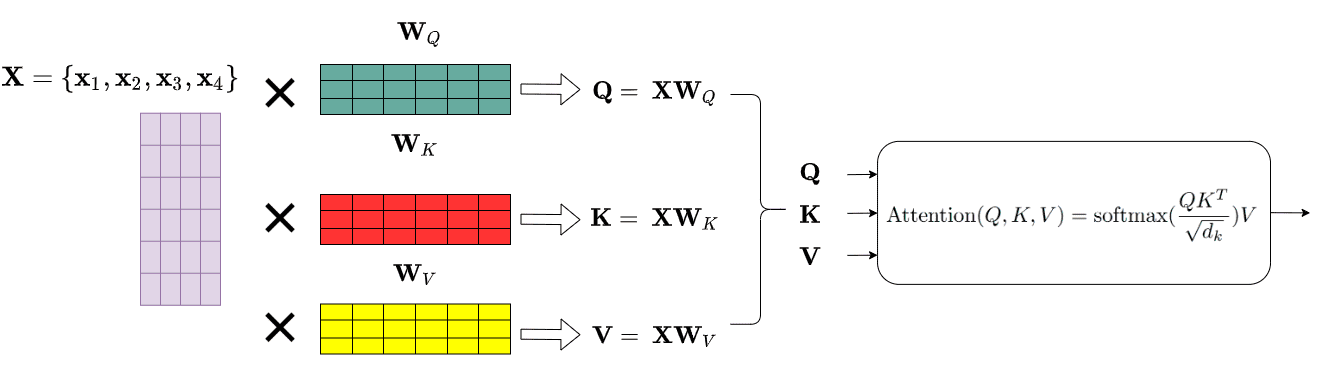
1.2 Positional Encoding: Teaching the Model Word Order
The transformer doesn't naturally understand the order of words (because it processes everything at once). To help it figure out that "The dog chased the cat" is different from "The cat chased the dog," we use positional encoding. This is like adding a little extra information to each word so the model knows where each one fits in the sentence.
1.3 Feedforward Networks: Adding Some Brainpower
After the self-attention mechanism has done its magic, the model applies a feedforward neural network to each word. Think of this as another layer of processing that helps the model fully understand what it's looking at. This step is done for every word, independently.
Part 2: The Decoder – Crafting the Output
Now that the encoder has processed the input, the decoder steps in to generate the output. For example, if the encoder understands "The dog chased the cat," the decoder would be responsible for translating it into another language or generating the next word in a sentence.
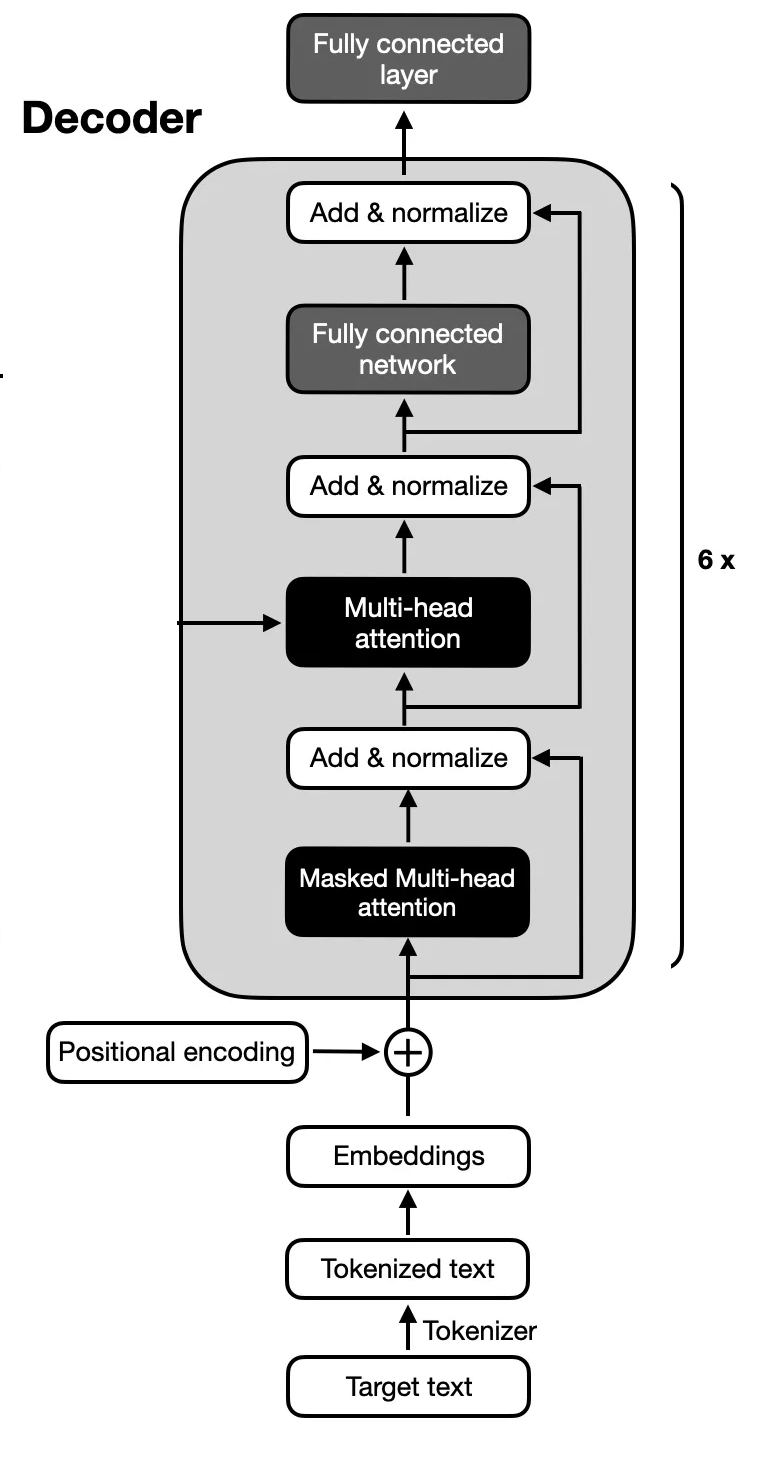
But the decoder isn’t just a copy of the encoder. It has a couple of extra tricks up its sleeve:
2.1 Masked Self-Attention: No Peeking Ahead!
When generating text, you don’t want the model to cheat by looking ahead at the words it hasn’t generated yet. That’s why the decoder uses masked self-attention—it only focuses on the words it has already generated, ensuring that each word is predicted one step at a time. So, while the encoder can look at the entire input sentence, the decoder has to work more sequentially.
2.2 Encoder-Decoder Attention: Linking Input and Output
The decoder doesn’t work in isolation. It also pays attention to what the encoder has learned. This is called encoder-decoder attention and it ensures that the decoder takes the input into account when generating output. Think of it as referencing a translation dictionary to ensure the translation makes sense.
2.3 Feedforward Networks and Layer Normalization
Just like the encoder, the decoder also has its own feedforward neural networks to make sense of the data. It also uses something called layer normalization, which helps keep the model stable during training (so it doesn’t get overwhelmed by large numbers or noise)
Why Are Transformers So Popular?
why are transformers such a big deal? Well, there are a few reasons:
They’re Fast: Transformers can handle huge amounts of data in parallel, making them much faster than older models like RNNs, which process information one step at a time.
They Scale: Transformers work great with large datasets and big models, which is why they’re used in massive AI systems like GPT-4 and BERT.
They Handle Long-Range Relationships: Unlike older models that struggle with long sentences or complex sequences, transformers are great at understanding relationships between words, no matter how far apart they are.
Why Are Transformers So Effective?
Transformers bring several advantages that have revolutionized how AI handles sequential data:
Parallelization: Unlike RNNs that must process inputs sequentially, transformers allow for simultaneous data processing, significantly accelerating training times.
Scalability: They effectively manage long-range dependencies within data, making them suitable for complex tasks in natural language processing (NLP).
State-of-the-Art Performance: Transformers have set new benchmarks across various NLP tasks, including translation, summarization, and text generation.
Applications of Transformers
Transformers aren’t just used for language—they’re popping up in all kinds of AI fields:
Text Generation: Models like ChatGPT are based on transformers and can generate human-like text.
Language Translation: Google Translate uses transformers to translate text between different languages.
Speech Recognition: Transformers help in converting speech to text in applications like voice assistants.
Computer Vision: With a few tweaks, transformers can even be used for image recognition in tasks like object detection.
Wrapping Up
At their core, transformers are all about understanding relationships—whether it’s between words, pixels, or data points. The encoder handles understanding the input, while the decoder generates the output based on what the encoder has learned. These two components, powered by mechanisms like self-attention, make transformers the go-to model for today’s most advanced AI applications.
Want to dive deeper? Stay tuned for future posts where we’ll explore advanced transformer models like GPT, BERT, and their real-world applications!
Subscribe to my newsletter
Read articles from Himanshu Singh Shekhawat directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by