Understanding Search Engines: The Role of Vector Space Model in Google’s Information Retrieval Process
 ooopsss_shreya
ooopsss_shreya
In our digital age, search engines are indispensable tools for navigating the vast sea of information available on the internet. Among these, Google stands out as the dominant player, processing billions of queries daily.
What is a Search Engine?
A search engine is a software system designed to search for information on the World Wide Web. It indexes web pages and other content to allow users to find relevant information based on their queries. The process involves several steps:
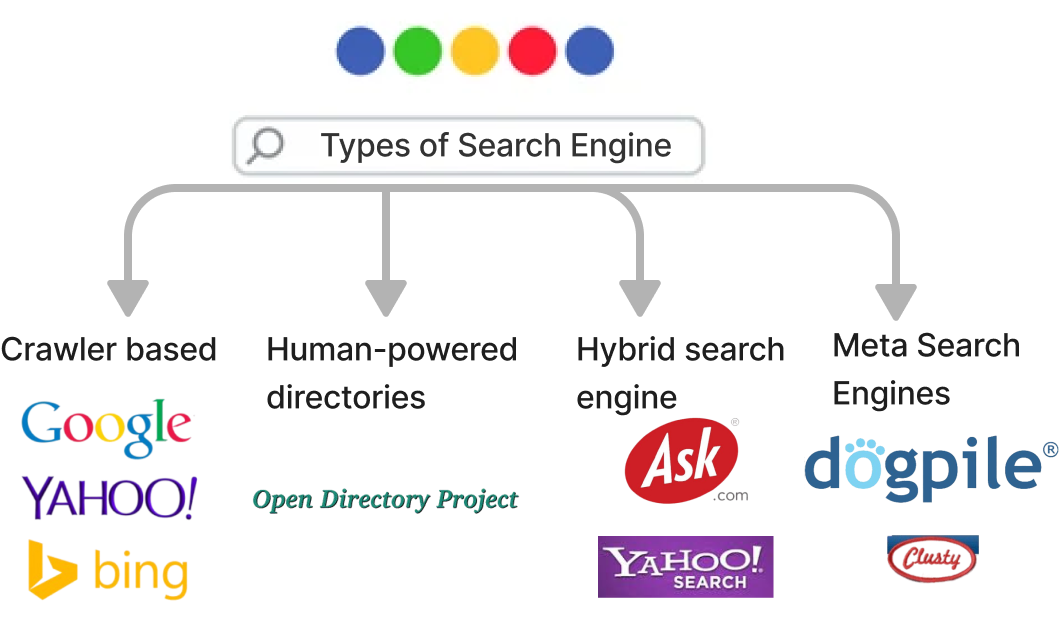
Crawling: Automated bots (or crawlers) scan the web to discover and index new content.
Indexing: The discovered content is processed and stored in a structured format in a database, enabling quick retrieval.
Retrieval: When a user enters a query, the search engine retrieves relevant documents from the index based on various algorithms.
Ranking: The retrieved documents are ranked according to their relevance to the query, considering multiple factors.
Types of Search Engine?
How Does Google Deliver Relevant Results?
The secret behind Google’s ability to deliver relevant results in fractions of a second lies in the Vector Space Model (VSM), a crucial component of information retrieval.
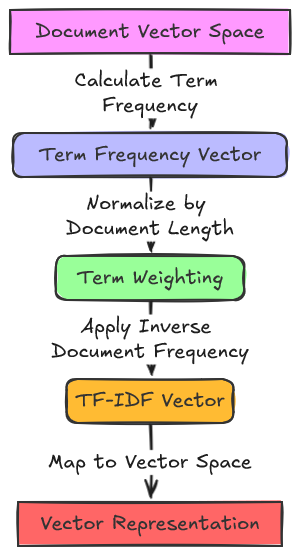
Vector Space Model : It is a mathematical way of representing and analyzing text documents in information retrieval (IR) and natural language processing (NLP). It works by transforming documents and queries into vectors, which are essentially arrows in a high-dimensional space.
The Vector Space Model is a mathematical framework used for information retrieval. It represents both documents and queries as vectors in a high-dimensional space.
Here’s how it works:
Step 1 : Representation
Document and Query Vectorization:
Documents and queries are first preprocessed, which involves steps like tokenization, stemming, and removing stop words to extract meaningful terms.
Each unique term is assigned a dimension in a high-dimensional space.
Documents and queries are then represented as vectors in this space, where each dimension corresponds to a term, and the value represents the importance or frequency of that term in the document or query.
Term Weighting:
Terms can be weighted using techniques like TF-IDF (Term Frequency-Inverse Document Frequency).
TF-IDF assigns higher weights to terms that are more frequent in the document but less frequent across all documents, thus capturing their importance in the specific document.
Step 2 : Similarity Calculation
Cosine Similarity:
Cosine similarity is commonly used to measure the similarity between two vectors.
It calculates the cosine of the angle between the document and query vectors, indicating the similarity in their directions.
Cosine similarity ranges from -1 (opposite directions) to 1 (same direction), with 0 indicating orthogonality (no similarity).
Formula:
The cosine similarity between two vectors a and b is calculated using their dot product and magnitudes as follows:
Similarity(a,b)= ∥a∥×∥b∥ / a⋅b
Here, a⋅b is the dot product of the vectors, and ∥a∥ and ∥b∥ are their magnitudes.
Interpretation:
Higher cosine similarity values indicate greater similarity between the document and query vectors.
Documents with higher similarity scores are considered more relevant to the query and are typically ranked higher in search results.
Step 3 : Retrieval
Presentation to User:
The top-ranked documents are presented to the user as search results.
These documents are considered most relevant to the user's query based on their similarity to the query vector.
Feedback and Refinement:
Users may provide feedback on the presented results, such as marking documents as relevant or irrelevant.
This feedback can be used to refine the retrieval process, potentially adjusting the weights of terms or incorporating relevance feedback mechanisms.
Basic Flow
Step 1: Corpus and Query
Corpus:
Document 1: “The quick brown fox jumps over the lazy dog.”
Document 2: “A brown dog chased the fox.”
Document 3: “The dog is lazy.”
Query:
- Query: “brown dog”
Step 2: Create the Document-Term Matrix (DTM)
We first preprocess the documents by tokenizing, stemming, and removing stop words. After this, we create the DTM based on the unique terms.
Unique Terms (Vocabulary):
brown
dog
fox
jumps
lazy
quick
chased
the (common stop word, may be omitted)
is (common stop word, may be omitted)
Document-Term Matrix (DTM) with TF-IDF Values:
Term | Doc 1 | Doc 2 | Doc 3 |
brown | 0.29 | 0.58 | 0 |
dog | 0.29 | 0.29 | 0.58 |
fox | 0.29 | 0.29 | 0 |
jumps | 0.58 | 0 | 0 |
lazy | 0.29 | 0 | 0.58 |
quick | 0.58 | 0 | 0 |
chased | 0 | 0.58 | 0 |
(Note: The values are illustrative; actual TF-IDF values would be calculated based on term frequency and document frequency.)
Step 3: Vectorize the Query
The query “brown dog” is represented as a vector indicating the presence of terms.
Query Vector (Binary Representation):
- Query Vector: [1 (brown), 1 (dog), 0 (fox), 0 (jumps), 0 (lazy), 0 (quick), 0 (chased)]
Vector with TF-IDF Weighting: Assuming TF-IDF values are derived:
- Query Vector: [0.58 (brown), 0.58 (dog), 0, 0, 0, 0, 0]
Step 4: Calculate Cosine Similarity
Now we calculate the cosine similarity between the query vector and each document vector.
Document 1 Vector: [0.29, 0.29, 0.29, 0.58, 0.29, 0.58, 0]
Document 2 Vector: [0.58, 0.29, 0.29, 0, 0, 0, 0.58]
Document 3 Vector: [0, 0.58, 0, 0, 0.58, 0, 0]
Cosine Similarity Calculations:
Cosine Similarity(Query, Doc 1) , Cosine Similarity(Query, Doc 2), Cosine Similarity(Query, Doc 3 ) is calculated
Step 5: Rank Documents by Similarity
The documents are ranked based on their cosine similarity values.
Ranking:
Document 2: Cosine Similarity ≈ 0.61
Document 3: Cosine Similarity ≈ 0.48
Document 1: Cosine Similarity ≈ 0.41
In this example, Google’s retrieval process effectively ranks Document 2 as the most relevant to the query “brown dog,” followed by Document 3 and then Document 1.
This demonstrates how the Vector Space Model enables efficient and relevant document retrieval based on user queries.
Search Engine/Information retrieval systems using vector space model/ analysis:
Google Search
Microsoft Bing
Apache Lucene : open-source search library
Elasticsearch : Distributed search engine
Sphinx : Full-text search engine
Subscribe to my newsletter
Read articles from ooopsss_shreya directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by