How to Fine-Tune OpenAI GPT-4o Model: A Step-by-Step Guide
 Pradip Nichite
Pradip NichiteTable of contents
- Why Consider Fine-Tuning?
- Understanding the Fine-Tuning Process
- Preparing Data for Fine-Tuning OpenAI Models
- Creating Training and Validation Sets
- Setting Up and Starting the Fine-Tuning Process
- Testing and Using Your Fine-Tuned Model
- Conclusion: Building Custom AI Solutions with Fine-Tuning
- Interested in Learning More?

Fine-tuning OpenAI models like GPT-4 has become essential for businesses looking to create specialized AI applications. In this comprehensive guide, you'll learn exactly how to fine-tune OpenAI models using Python, complete with working code examples and real-world applications.
Fine-tuning allows you to improve model performance on specific tasks by training it with your own examples. Instead of relying on complex prompts, you can teach the model to understand your exact requirements through demonstration.
Why Consider Fine-Tuning?
Three main benefits make fine-tuning particularly valuable:
Higher Quality Results When basic prompting isn't enough to get consistent results, fine-tuning helps the model adapt to your specific business use case.
Handling Multiple Examples Sometimes your use case requires many examples that won't fit in a standard prompt. Fine-tuning lets you incorporate all these examples into the model itself.
Simplified Prompts After fine-tuning, you can achieve better results with shorter prompts, leading to faster execution times.
Real-World Applications
Fine-tuning particularly shines in two common scenarios:
Style and Format Consistency
Generating product descriptions with specific tones
Maintaining consistent writing styles
Formatting outputs in particular ways
Reliable Structured Output
Converting unstructured text into JSON
Extracting specific fields consistently
Ensuring standardized response formats
For example, in our medical data extraction implementation, we'll turn medical reports into structured data:
# Example of the structured output we want to achieve
{
"patient name": "Sarah Johnson",
"age": 32,
"diagnosis": "migraine headaches",
"prescribed medication": "Sumatriptan"
}
Understanding the Fine-Tuning Process
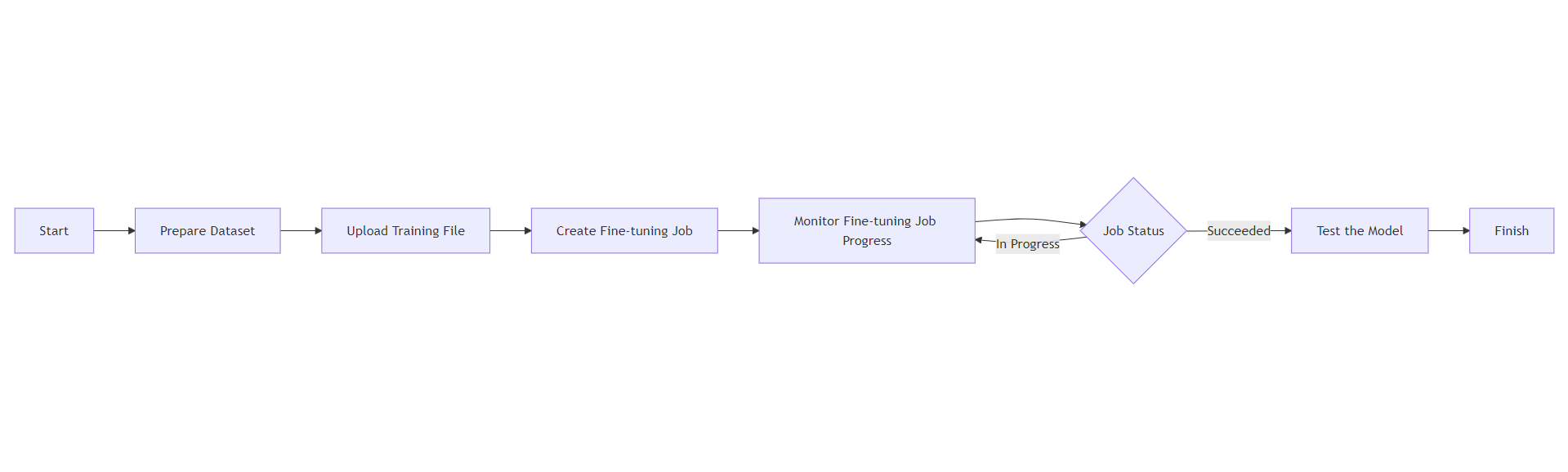
The process involves several stages:
File validation
Job queuing
Training initialization
Training progress
Completion or failure
Preparing Data for Fine-Tuning OpenAI Models
Understanding the Data Format
Before we start fine-tuning, we need to prepare our data in the correct format. For chat models like GPT-4, the training data should be in JSONL format (JSON Lines), where each line represents a conversation with messages between the system, user, and assistant.
Here's what a single training example looks like:
{
"messages": [
{
"role": "system",
"content": "Extract Details from medical report"
},
{
"role": "user",
"content": "Sarah Johnson, a 32-year-old female, presented to the clinic with complaints of severe migraine headaches occurring 3-4 times per week for the past 3 months. Patient reports throbbing pain on the right side of head, accompanied by photophobia and nausea. No previous history of migraines. Family history positive for migraines (mother). Physical examination revealed normal neurological findings. Blood pressure 118/76 mmHg. Prescribed Sumatriptan 50mg for acute episodes, with instructions to take at onset of symptoms."
},
{
"role": "assistant",
"content": "{\"patient name\": \"Sarah Johnson\", \"age\": 32, \"diagnosis\": \"migraine headaches\", \"prescribed medication\": \"Sumatriptan\"}"
}
]
}
Converting CSV to JSONL Format
Let's write a Python function to convert our medical records CSV into the required JSONL format:
import csv
import json
def convert_csv_to_training_format(input_csv, output_file):
system_message = {
"role": "system",
"content": "Extract Details from medical report"
}
with open(input_csv, 'r', encoding='utf-8') as csvfile, \
open(output_file, 'w', encoding='utf-8') as outfile:
reader = csv.reader(csvfile)
next(reader) # Skip header
for row in reader:
medical_report = row[0]
extracted_json = row[1]
training_example = {
"messages": [
system_message,
{"role": "user", "content": medical_report},
{"role": "assistant", "content": extracted_json}
]
}
outfile.write(json.dumps(training_example) + '\n')
Creating Training and Validation Sets
It's good practice to split your data into training and validation sets. Here's how to prepare both:
# Prepare training data
convert_csv_to_training_format("medical-records.csv", "training_data.jsonl")
# Prepare validation data
convert_csv_to_training_format("validation-medical-records.csv", "validation_data.jsonl")
Key Components of the Training Data
System Message: A consistent instruction that sets the context for all examples
User Messages: The input medical reports
Assistant Messages: The expected structured JSON output
JSONL Format: Each line is a complete, valid JSON object
Best Practices for Data Preparation
Keep the system message consistent across all examples
Ensure your JSON is properly formatted in the assistant responses
Include diverse examples to help the model generalize
Use validation data to monitor training progress
Setting Up and Starting the Fine-Tuning Process
Initial Setup with OpenAI
First, let's set up the OpenAI client and necessary imports:
from openai import OpenAI
from time import sleep
# Initialize OpenAI client
client = OpenAI(api_key = your_api_key)
Step 1: Uploading Training Files
Before we can start fine-tuning, we need to upload our prepared data files to OpenAI. Here's the function to handle file uploads:
def upload_training_file(file_path):
"""Upload training file to OpenAI"""
with open(file_path, "rb") as file:
response = client.files.create(
file=file,
purpose="fine-tune"
)
return response.id
# Upload both training and validation files
training_file_id = upload_training_file("training_data.jsonl")
validation_file_id = upload_training_file("validation_data.jsonl")
Step 2: Creating a Fine-Tuning Job
Once our files are uploaded, we can create a fine-tuning job:
def create_fine_tuning_job(training_file_id, validation_file_id=None, model="gpt-4o-mini-2024-07-18"):
"""Create a fine-tuning job"""
response = client.fine_tuning.jobs.create(
training_file=training_file_id,
validation_file=validation_file_id,
model=model
)
return response.id
# Start the fine-tuning job
job_id = create_fine_tuning_job(training_file_id, validation_file_id, model)
Step 3: Monitoring Training Progress
Fine-tuning isn't instant - we need to monitor the job's progress. Here's a function to track the status:
def monitor_job(job_id):
"""Monitor fine-tuning job progress"""
while True:
job = client.fine_tuning.jobs.retrieve(job_id)
print(f"Status: {job.status}")
if job.status in ["succeeded", "failed"]:
return job
# List latest events
events = client.fine_tuning.jobs.list_events(
fine_tuning_job_id=job_id,
limit=5
)
for event in events.data:
print(f"Event: {event.message}")
sleep(30) # Check every 30 seconds
# Monitor the job until completion
job = monitor_job(job_id)
if job.status == "succeeded":
fine_tuned_model = job.fine_tuned_model
print(f"Fine-tuned model ID: {fine_tuned_model}")
else:
print("Fine-tuning failed.")
Important Notes:
The process typically takes several minutes to complete
Keep track of your fine-tuned model ID for later use
The status updates help monitor training progress
The job either succeeds or fails - no partial completions
Testing and Using Your Fine-Tuned Model
Making Predictions with Your Model
Let's test our fine-tuned model with a new medical report. Here's how to use it:
def test_model(model_id, test_input):
"""Test the fine-tuned model"""
completion = client.chat.completions.create(
model=model_id,
messages=[
{
"role": "system",
"content": "Extract Details from medical report"
},
{"role": "user", "content": test_input}
]
)
return completion.choices[0].message
Let's try it with a new medical report:
# Test input
test_report = """Marcus Wong, a 19-year-old male, presents with severe acne
on face and upper back present for 1 year. Multiple inflammatory papules
and nodules noted on examination. Previous trials of over-the-counter
treatments ineffective. Started on Isotretinoin 40mg daily with monthly
liver function monitoring."""
# Get prediction
result = test_model(fine_tuned_model, test_report)
# Parse the JSON response
import json
extracted_data = json.loads(result.content)
print(json.dumps(extracted_data, indent=2))
Output:
{
"patient name": "Marcus Wong",
"age": 19,
"diagnosis": "severe acne",
"prescribed medication": "Isotretinoin"
}
Improved Performance Benefits
The fine-tuned model shows several improvements:
Simpler Prompts: Notice we don't need complex instructions anymore
Consistent Output: The model maintains the exact JSON structure we trained it for
Faster Processing: Shorter prompts mean quicker responses
Reliable Extraction: Accurately pulls out key information even from complex medical text
Best Practices for Using the Model
- Input Consistency:
# Keep system message consistent with training
messages=[
{"role": "system", "content": "Extract Details from medical report"},
{"role": "user", "content": medical_report}
]
- Error Handling:
try:
extracted_data = json.loads(result.content)
except json.JSONDecodeError:
print("Error: Invalid JSON response")
- Validation:
required_fields = ["patient name", "age", "diagnosis", "prescribed medication"]
missing_fields = [field for field in required_fields if field not in extracted_data]
if missing_fields:
print(f"Warning: Missing fields: {missing_fields}")
Conclusion: Building Custom AI Solutions with Fine-Tuning
Real Success Stories from FutureSmart AI
At FutureSmart AI, we've successfully implemented fine-tuned models for various client requirements. Here are some of our proven use cases:
1. Product Description Generation
We fine-tuned a model for precision product description generation, achieving significant improvements in:
Maintaining consistent brand tone
Following specific style guidelines
Generating market-ready content
2. Structured Data Extraction
Our team developed a reliable JSON output model that:
Consistently extracts structured data
Reduces the need for fallback mechanisms
Maintains high accuracy across diverse inputs
Interested in Learning More?
Explore How We Can Help Your Business:
Case Studies: Visit FutureSmart AI Case Studies to see real-world applications of our NLP solutions
Contact Us: Have a project in mind? Reach out at contact@futuresmart.ai
Let us help you transform your business with custom AI solutions tailored to your specific needs.
Subscribe to my newsletter
Read articles from Pradip Nichite directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Pradip Nichite
Pradip Nichite
🚀 I'm a Top Rated Plus NLP freelancer on Upwork with over $300K in earnings and a 100% Job Success rate. This journey began in 2022 after years of enriching experience in the field of Data Science. 📚 Starting my career in 2013 as a Software Developer focusing on backend and API development, I soon pursued my interest in Data Science by earning my M.Tech in IT from IIIT Bangalore, specializing in Data Science (2016 - 2018). 💼 Upon graduation, I carved out a path in the industry as a Data Scientist at MiQ (2018 - 2020) and later ascended to the role of Lead Data Scientist at Oracle (2020 - 2022). 🌐 Inspired by my freelancing success, I founded FutureSmart AI in September 2022. We provide custom AI solutions for clients using the latest models and techniques in NLP. 🎥 In addition, I run AI Demos, a platform aimed at educating people about the latest AI tools through engaging video demonstrations. 🧰 My technical toolbox encompasses: 🔧 Languages: Python, JavaScript, SQL. 🧪 ML Libraries: PyTorch, Transformers, LangChain. 🔍 Specialties: Semantic Search, Sentence Transformers, Vector Databases. 🖥️ Web Frameworks: FastAPI, Streamlit, Anvil. ☁️ Other: AWS, AWS RDS, MySQL. 🚀 In the fast-evolving landscape of AI, FutureSmart AI and I stand at the forefront, delivering cutting-edge, custom NLP solutions to clients across various industries.