Kubernetes 101: Part 7
 Md Shahriyar Al Mustakim Mitul
Md Shahriyar Al Mustakim MitulStorage in Docker
Docker has storage driver and volume driver

Storage Drivers:
When you install docker, it created a file path called /var/lib/docker
It stores everything here.

Read more here
These are the storage drivers → AUFS, ZFS, BTRFS,……….

Volume drivers
We learned that if we want to persist storage, we must create volume. Volume are handled by volume driver plugins. The default volume driver plugin is Local
There are other volume drivers for cloud solutions or 3rd party like Azure File storage, Convoy, DIgitalOccean

How to use them?
While running a container, we can specify the volume driver . Here, we used rexray storage driver that can be used to provision storage on AWS EBS.
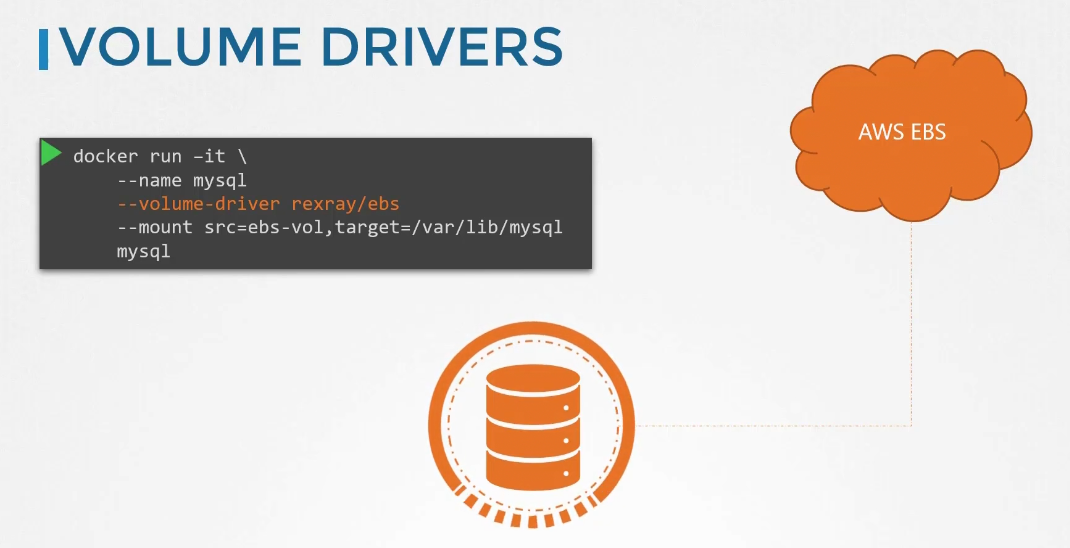
This will let us create a container and attach a volume on AWS Cloud. When the container exists, data will still be saved on the cloud.
Volumes in Kubernetes
Docker containers are supposed to get deleted once the task is done. In this way, the data within that also gets deleted.

But if we attach them to a volume, the data remains despite the pods are destroyed

In kubernetes, same thing happens. Once a pod is deleted, the data get deleted as well.
To solve this issue, we attach a volume to the pod. The data is now safe even after the pod is deleted.

Here, you can see that we specified the volumes where we have provided the path where we want our data to be saved.

This pod generated value from 0 to 100 and saves it on the number.out file. This file is kept on the /data folder
Also to access the folder from the container, we need to use volumeMounts
The generated number (between 0 to 100) will be generated now on the /opt/data-volume and then saved on the /data folder on the host

But this is not a good practice if we have multiple nodes.
We can use 3rd party services to solve that storage issue for multiple nodes

For example, if we use AWS, we need to use AWS volume id and type.

After that, those will be saved in the aws cloud

Container Storage Interface
As kubernetes wants to extend its support to all container runtimes (ex: docker), it introduced CRI (Container Runtime interface). Some CRI solutions are docker, rkt, cri-o

Also for networking, support was extended for different networking solutions and thus came CNI (Container Networking Interface). Some CNI solutions are weaveworks, flannel, cilium
Again for storage, Container Interface Solutions (CIS) was given to support multiple storage solutions. Some CIS are portworx, amazon ebs, glusterFS, dell emc

Currently Kubernetes, cloud foundry, mesos are on board with CSI.
How does this work?
CSI says, When a pod is created and requires a volume, the container orchestrator (here, kubernetes; on the left) should call the create volume RPC(Remote Procedure Calls) and pass a set of details such as the volume name.

The storage driver ( On the right) should implement this RPC and handle that request and provision a new volume on the storage array and return the results of the operations.
Same goes for delete volume RPC and others.
Volumes
As we know docker container volumes do get deleted if we delete them. So, we can attach the containers with a volume (we can create that under a location)
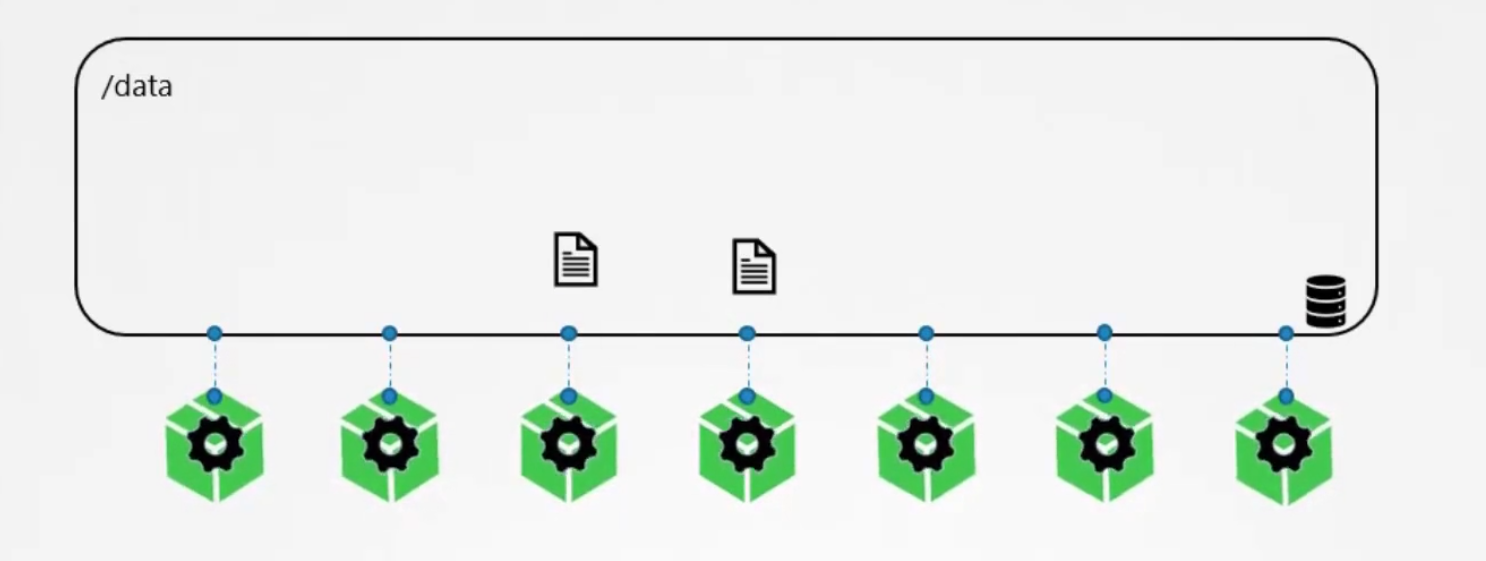
This way, the data will be there in the volume even if the containers are deleted.
Assume that we created a pod which generates random number between 0-100 and keeps that in /opt/number.out folder
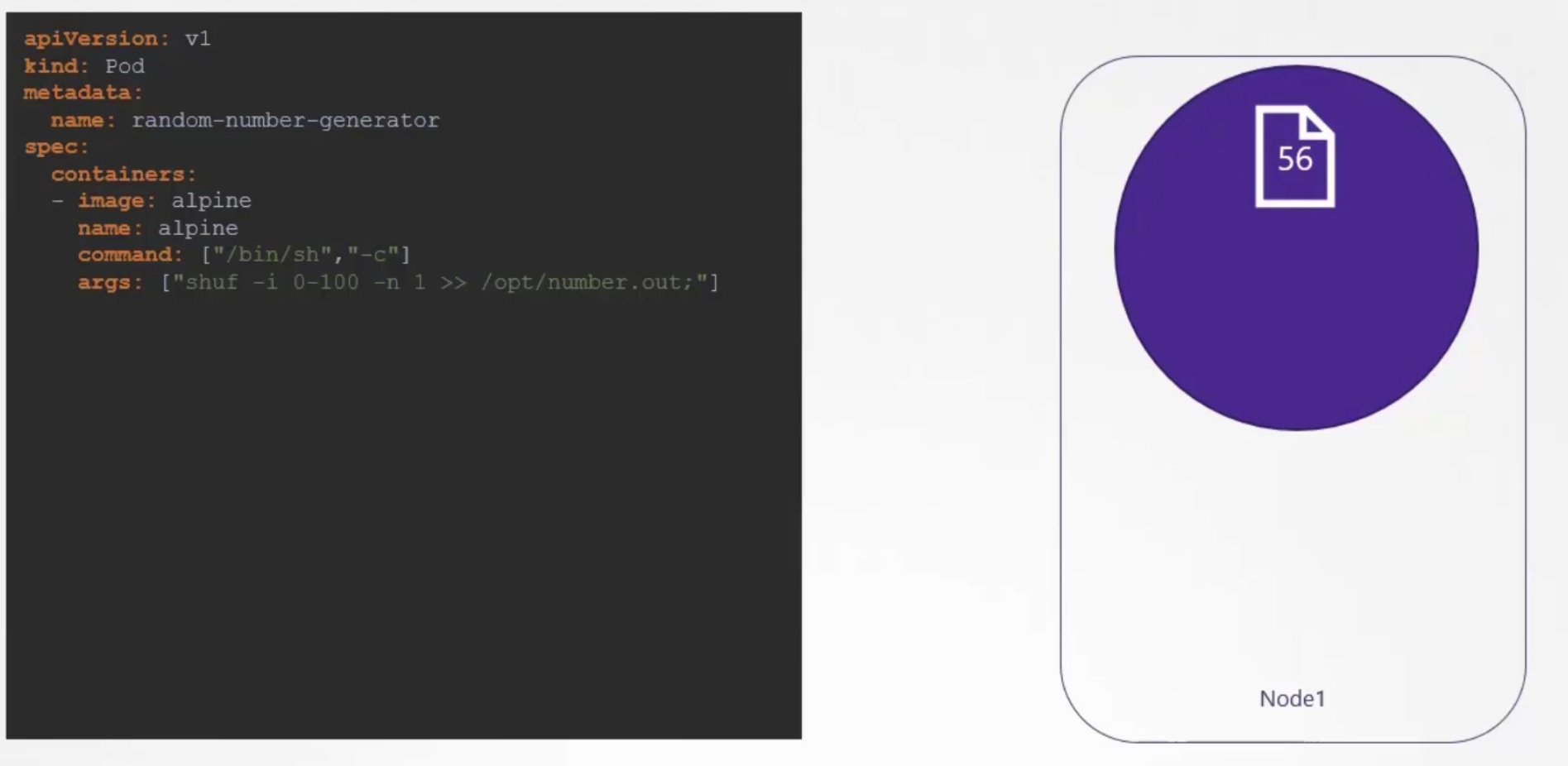
For example, here 56 is generated.
Then we hoped to delete the pod
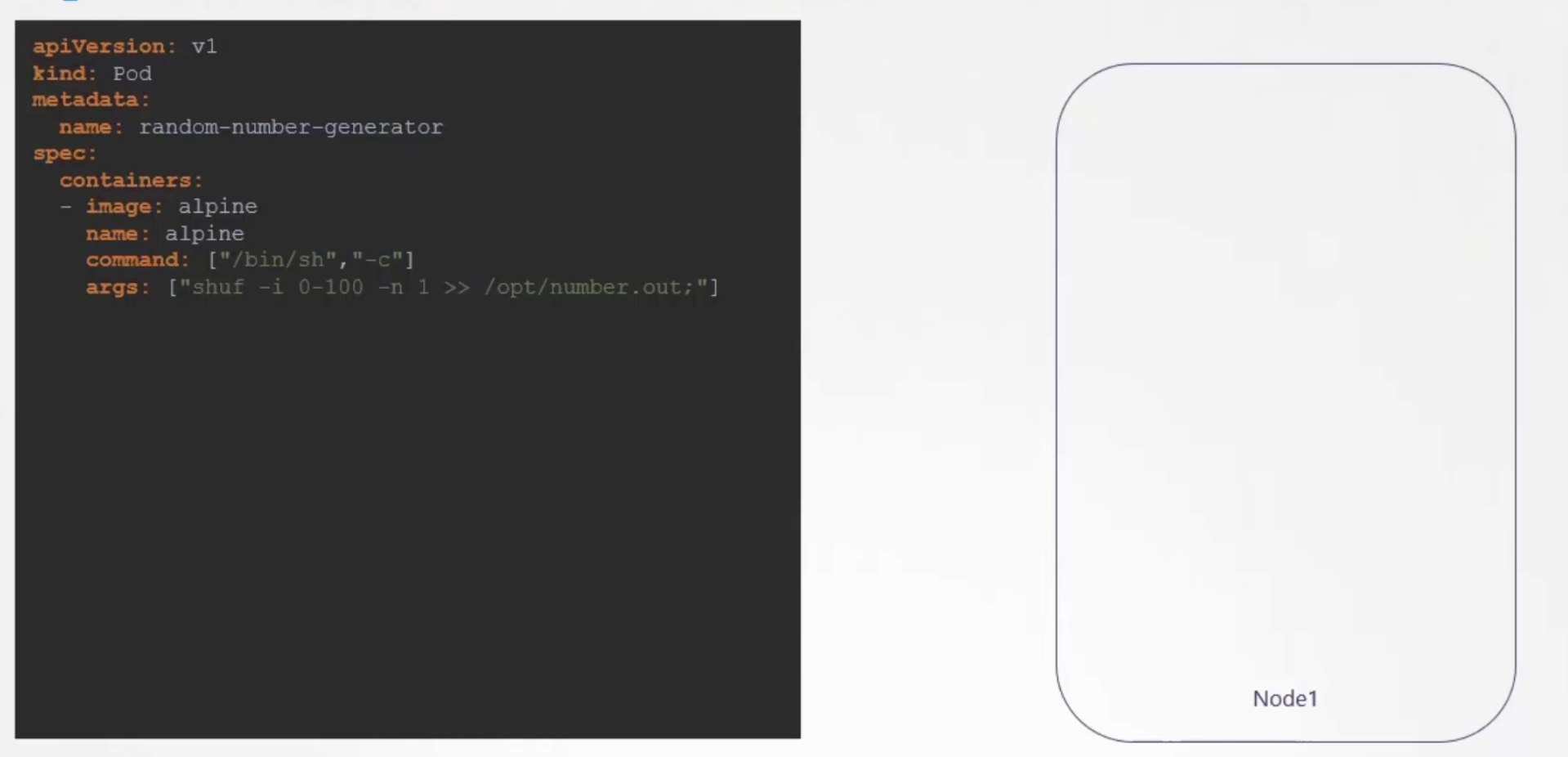
So, the data and the pod both are gone!
To keep the data saved, we can create a volume on the pod called “data-volume” and then connect this to local device’s folder (/data) . So, pod’s volume is connected to local device. Now, we see that our generated random number will be saved on /opt/number.out file . So, let’s connect the /opt file with data-volume.
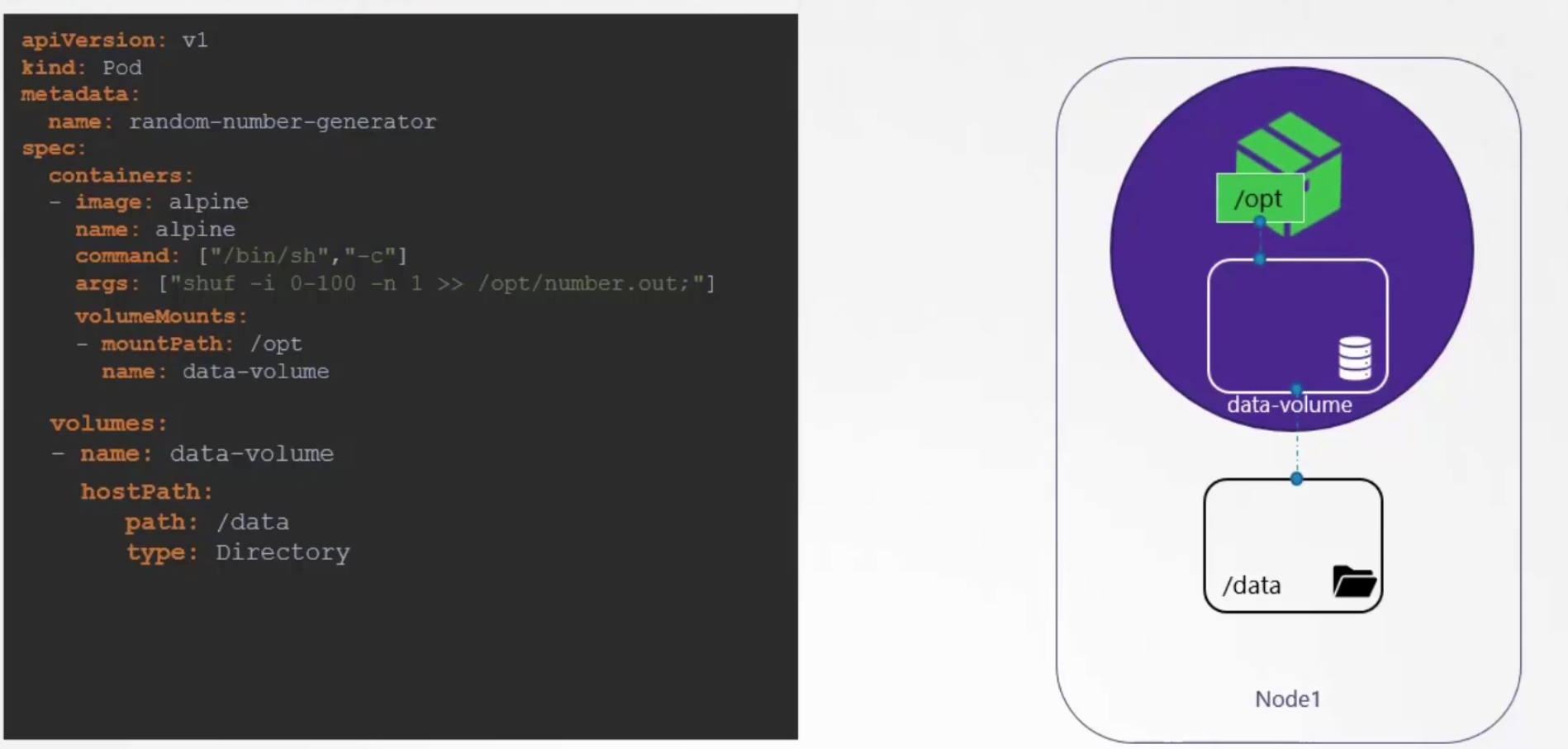
In this way, once a random value is generated , it will be stored in the /data-volume/opt/number.out and then stored in the local device’s (PC/laptop) storage.
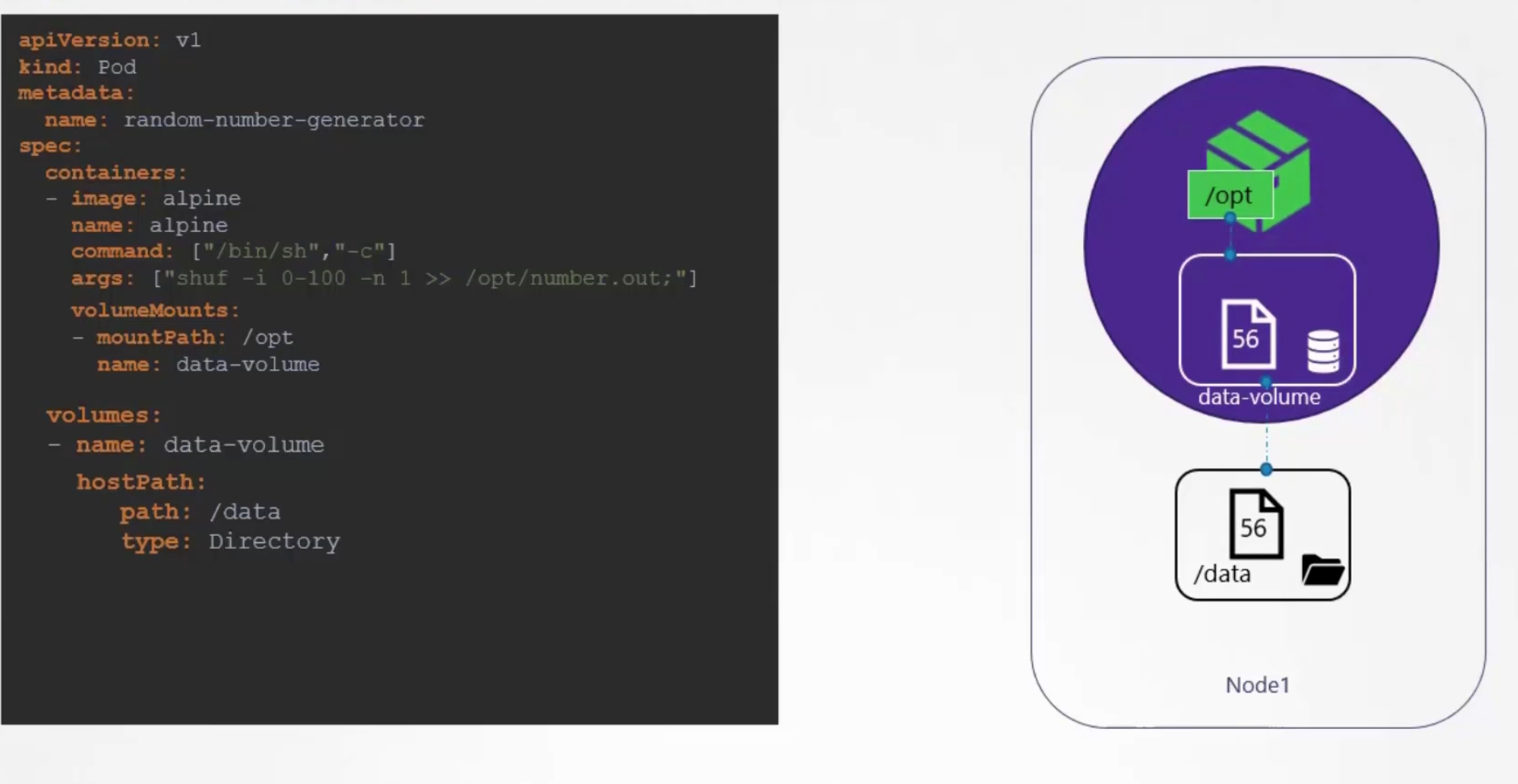
This time, if the pod is deleted, the file with random number is still saved in the local system.
In general , it does not happen that a person keeps all of the node data to the same folder (here, /data)
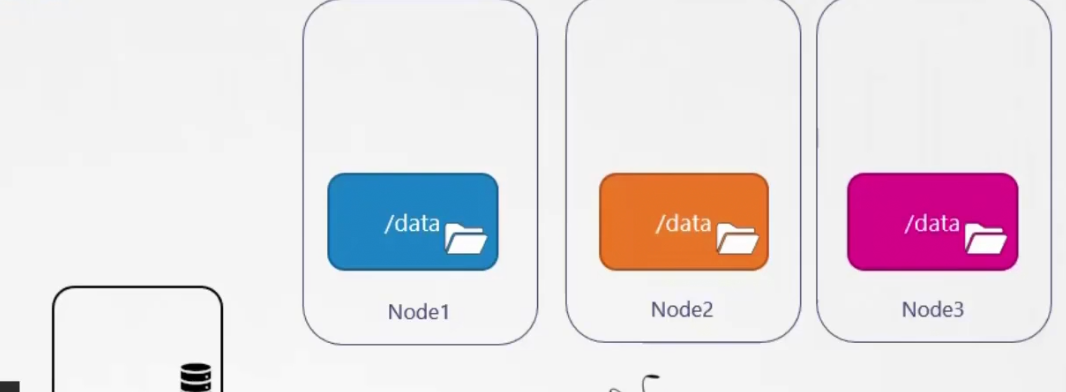
This was easy for managing one node. But for a huge cluster, we can’t use local device’s storage.
To deal with those, there are several storage solutions such as NFS, GlusterFS, FLocker, fiber, channel, CephFS, ScaleIO , AWS EBS, Azure disk, Google’s persistent disk.

Persistent Volumes
We know that we can create pods and attach local volume with it using a storage solutions. But while doing so, we have to configure the yaml file everytime

But what you can do is, you can create a central storage from where an administrator can create large pool of storage and let users use storage from it. This is where Persistent Volume (PV) helps us in.
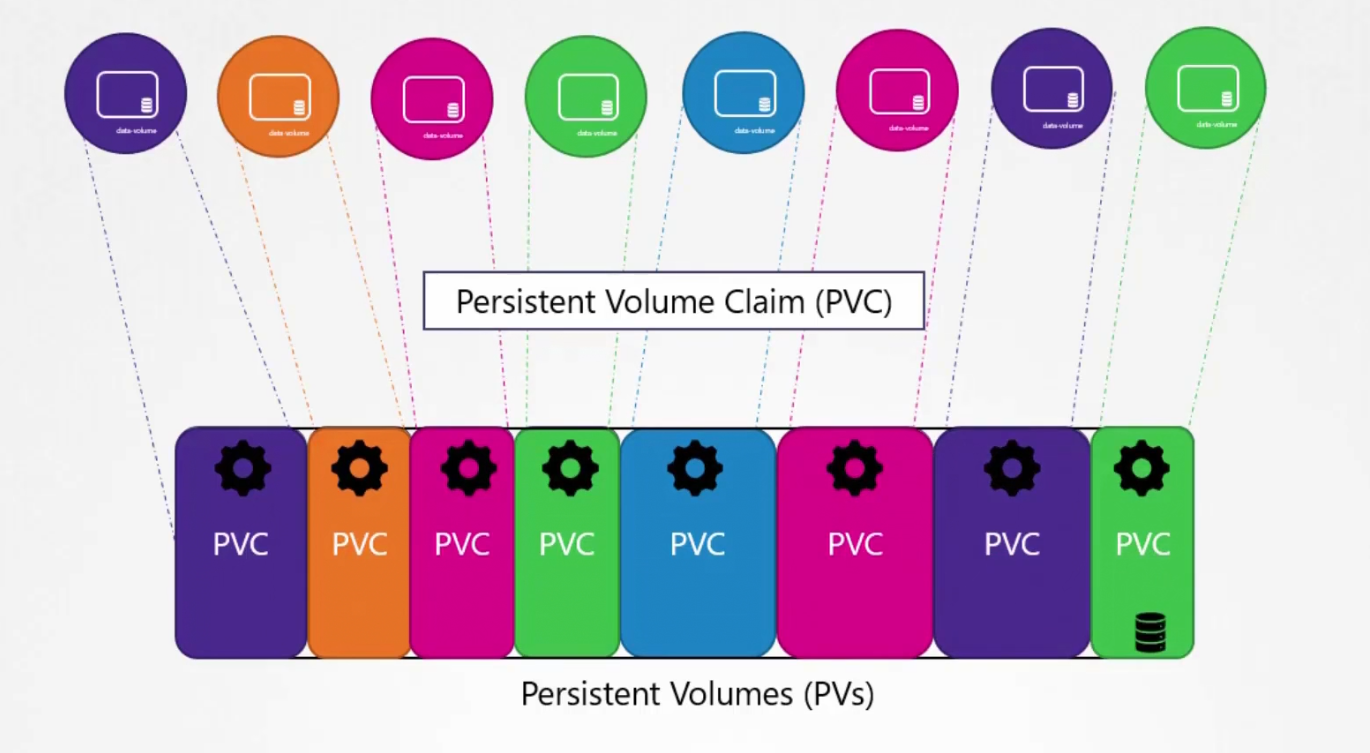
If users use the PV, they can select storage from the pool using Persistent Volume Claim (PVC)
But how to define the Persistent Volume?
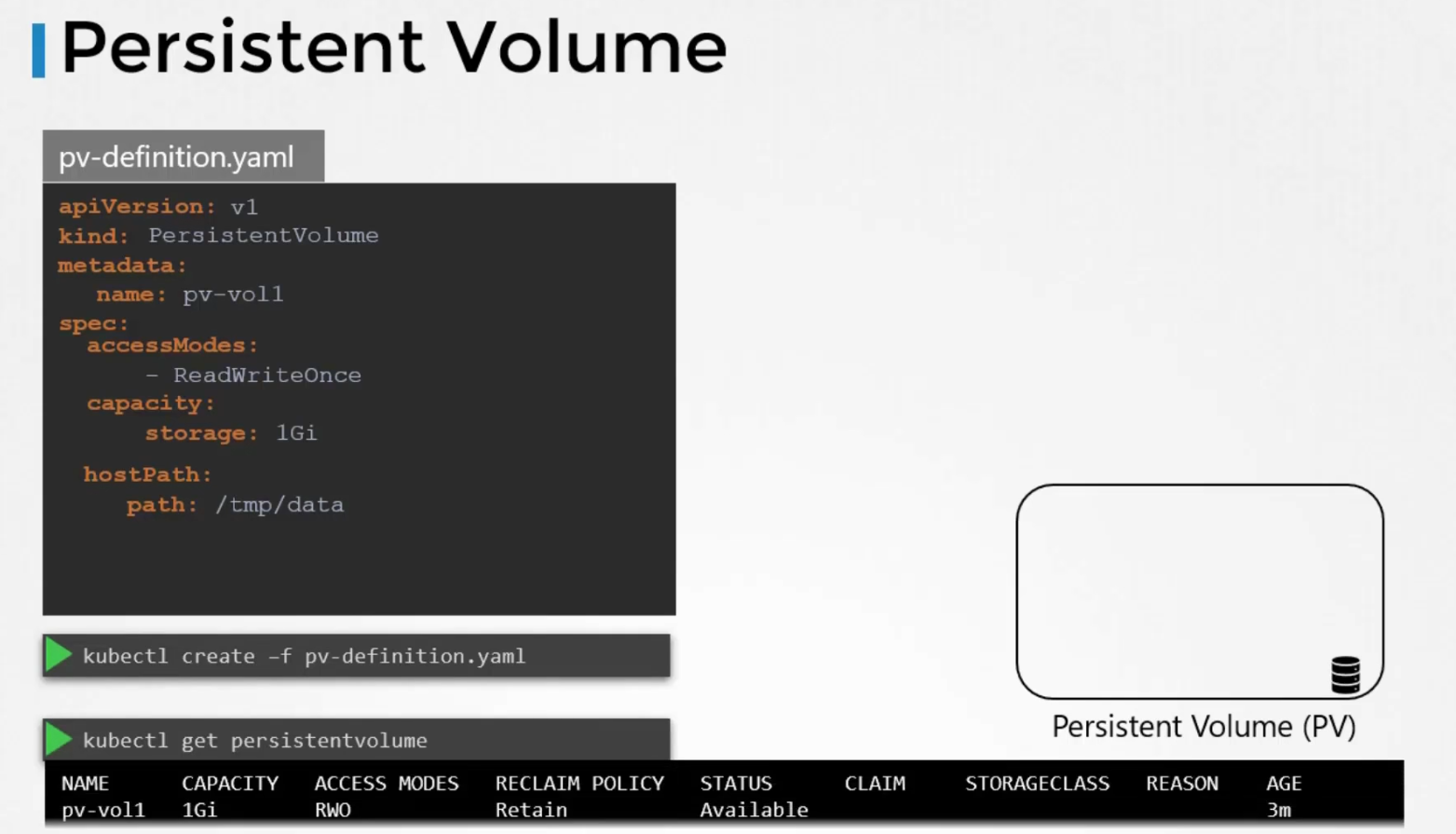
Create the yaml file and then create it.
Here, the name of the volume is pv-vol1, and ReadWriteOnce access is given. Although there are other accessModes too.
Then the storage is selected and the path for the Volume.
If we want to use Public cloud storage solutions instead of local storage (here /tmp/data), we can use this

Here, AWS ELB support was used.
Persistent Volumes Claims (PVC)
Persistent volume and persistent volume claims are both different things. An administrator created Persistent volume (PV) and a user created Persistent volume claims (PVC)
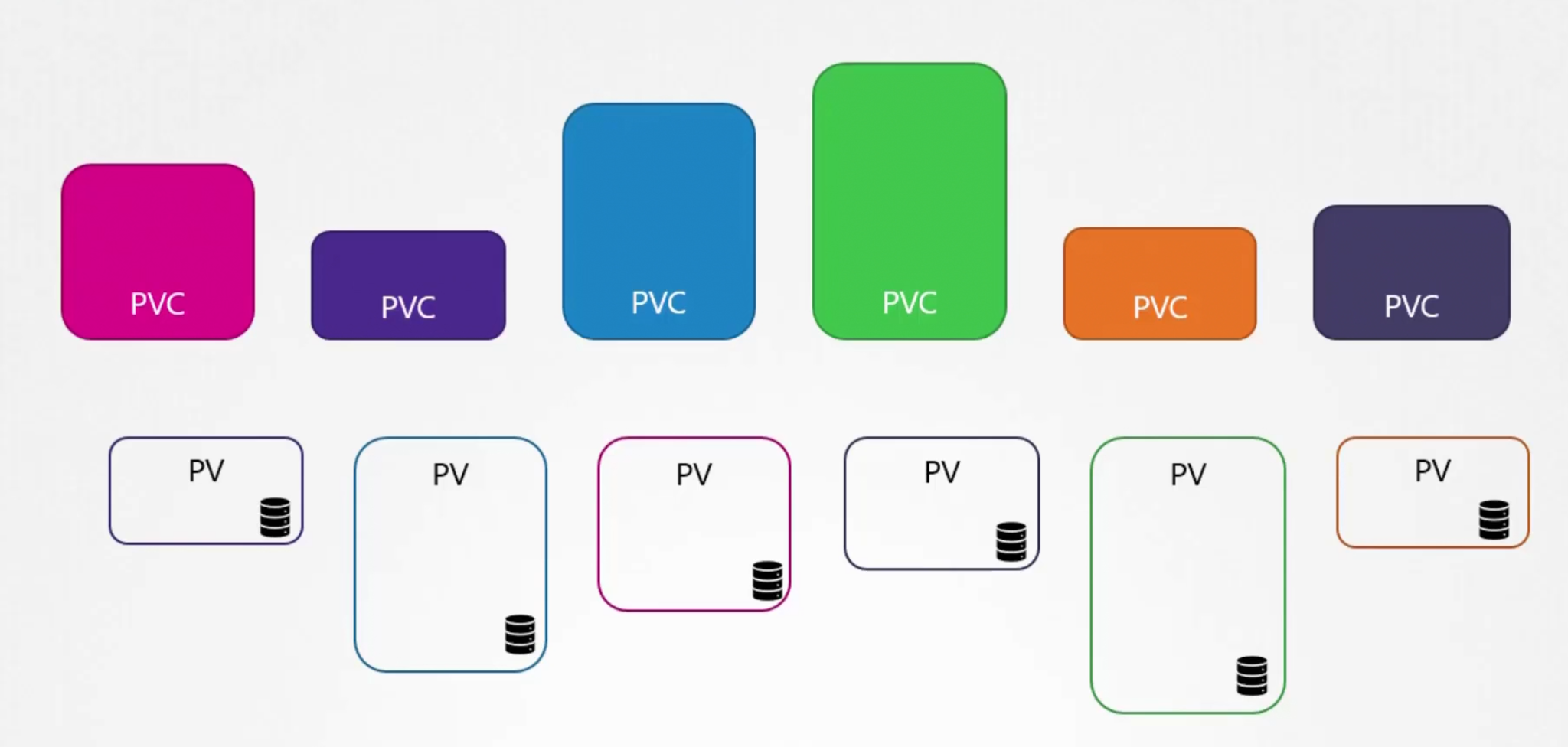
Once a create a PVC, kubernetes binds PV with PVC

What kubernetes does is, it looks for volumes which has the same capacity that has been asked for using PVC. It also looks for Access Modes, Volume Modes, Storage class as matrix and then if that matches , it binds PVC with PV.
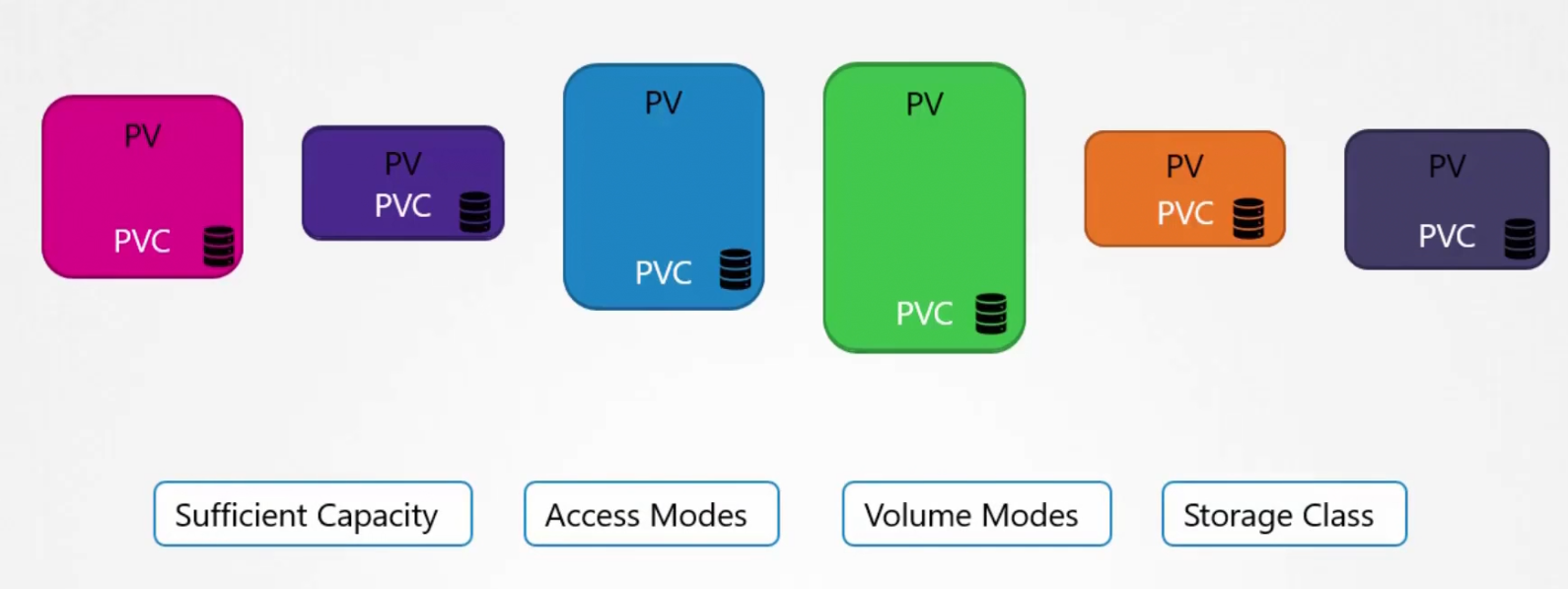
Also, keep in mind that a smaller Claim (PVC) might get binded with a big volume (PV) if all other criteria mathches (Access mode, volume modes etc)
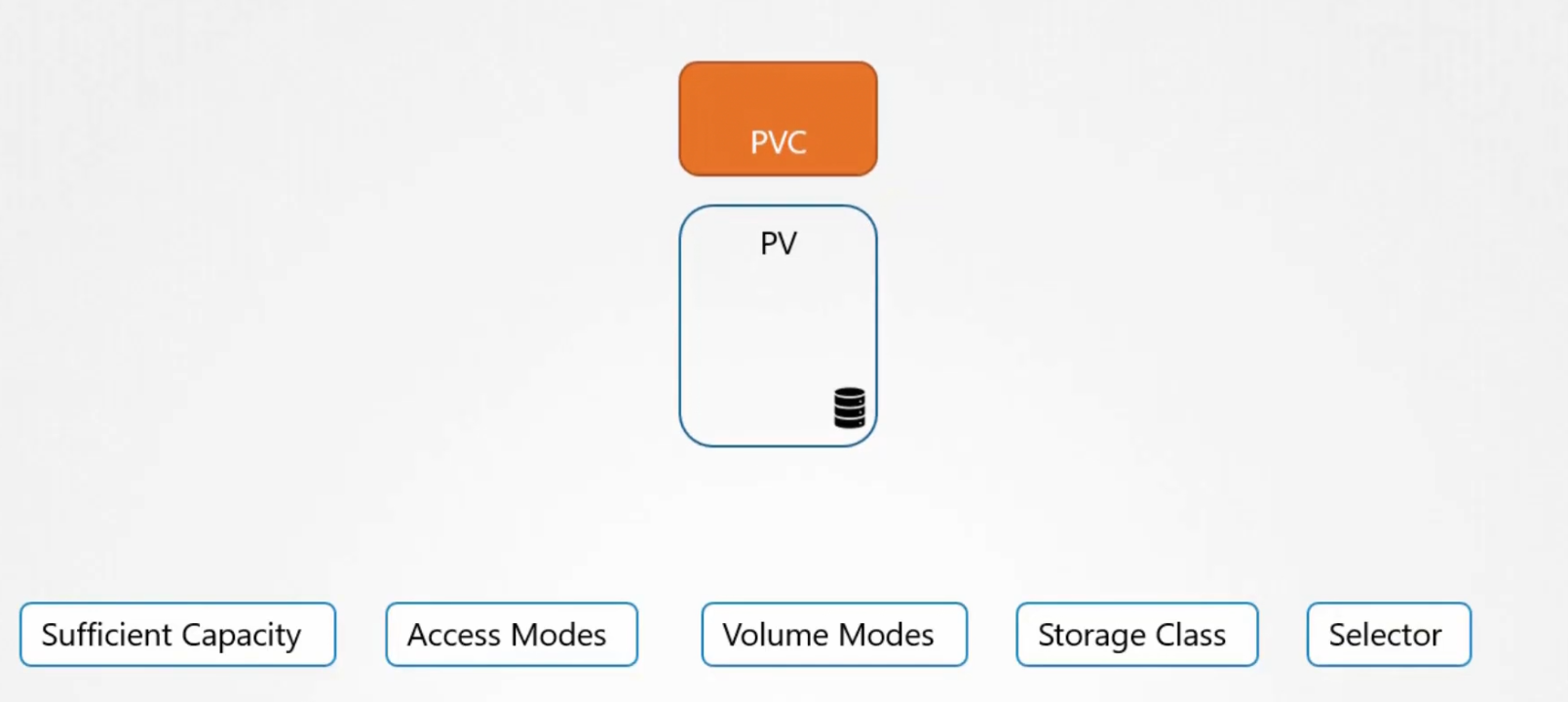
Then the binding happens and the remaining space of the volume can’t be used by other PVC
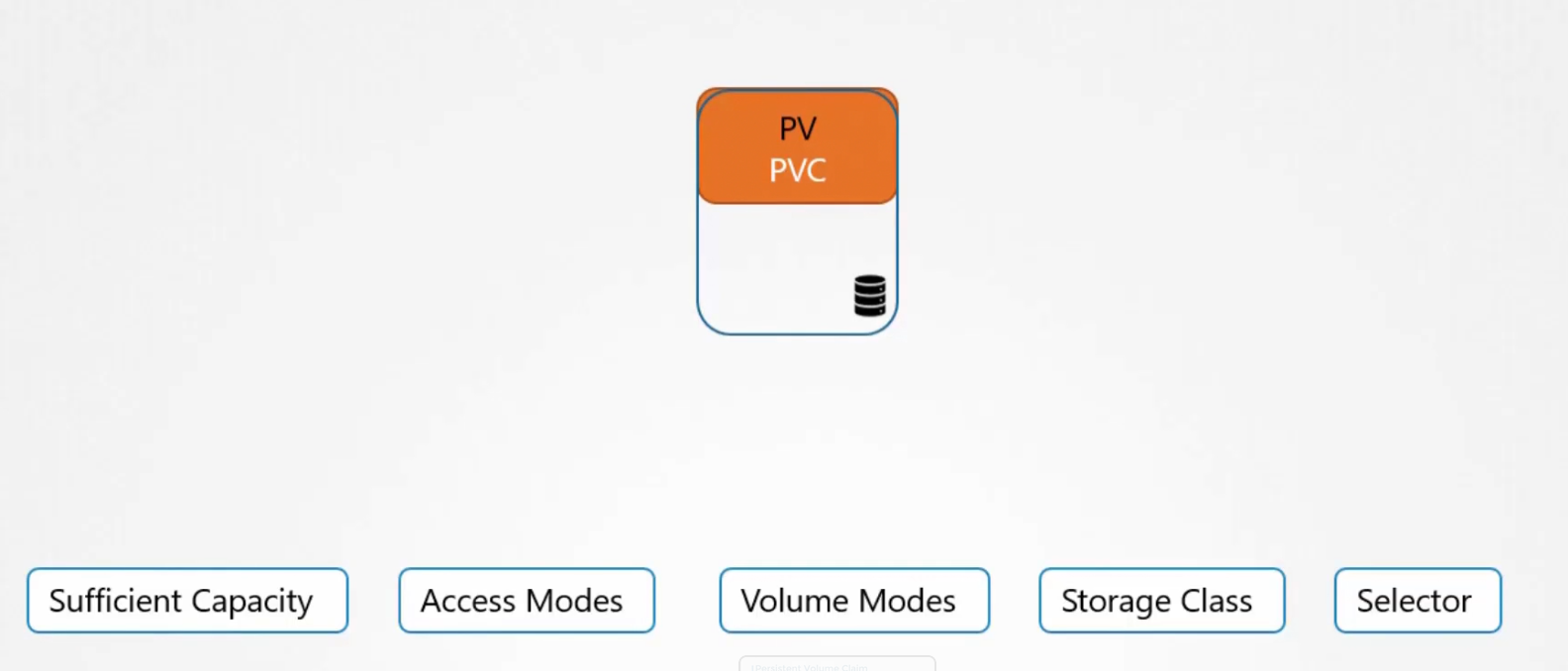
What if we don’t have volumes to bind with a PVC?

Then the PVC remains in a pending state untill new volumes are available to bind with it.
How to create the PVC?
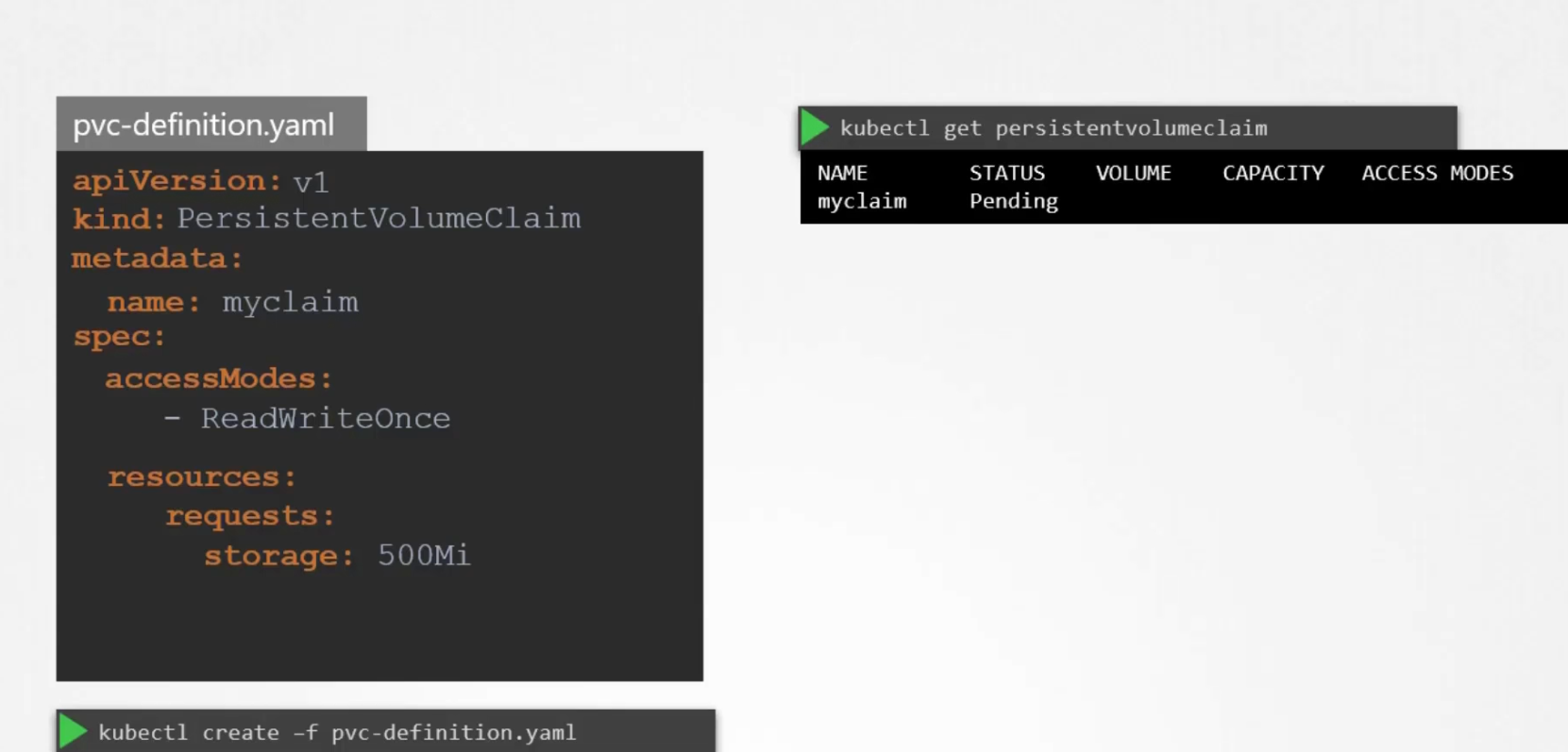
We can create the PVC, with accessMode (ReadWriteOnce), and 500 MB storage request
Once done, it will be in the pending state. Because it looks for existing persistent volumes which fulfills it’s requirements.
Remember that we created a Persistent volume which had a name pv-vol1, accessmode (ReadWriteOnce) and storage 1 GB
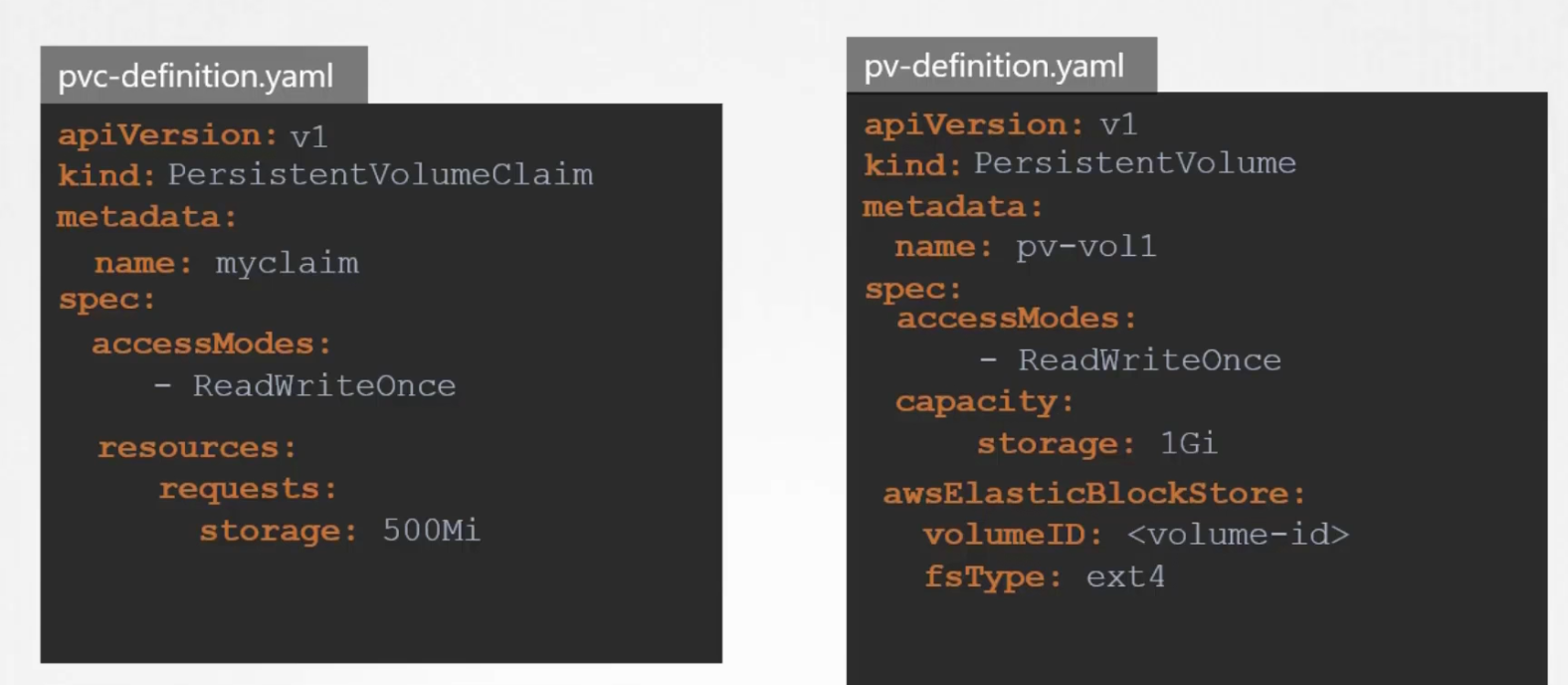
As the accessmodes matches, PVC’s storage requirement is fulfilled by PV (persistent volume), our PVC (myclaim) will be bounded with PV (here pv-vol1)

We can also delete a PVC using this
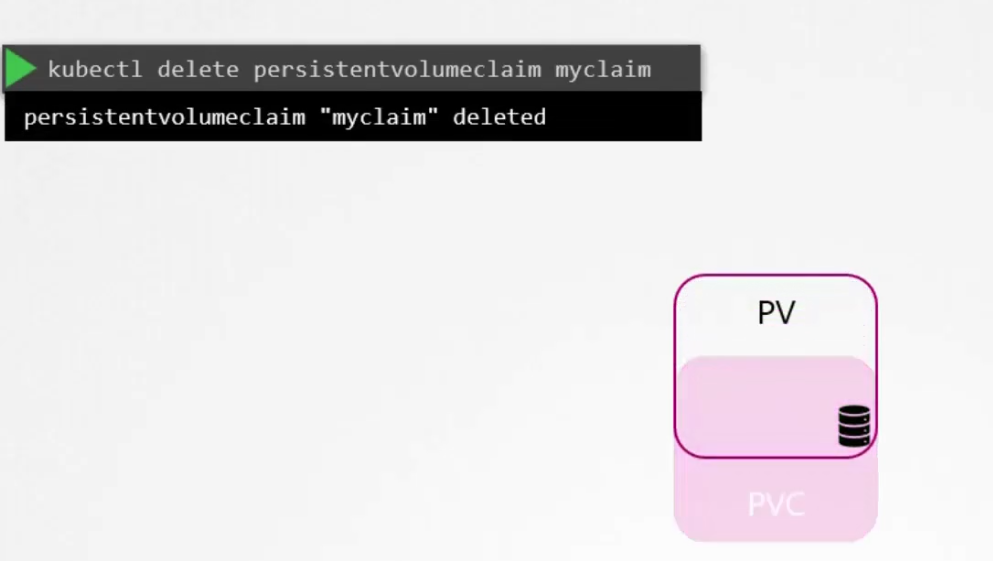
But the volume still remains because there is a variabale called persistentVolumeReclaimPolicy which is set to Retain.

But we can set it to delete so that , the Persistent volume (PV) is deleted once the PVC is deleted too

Storage Class
Assume that you are now creating a persistent volume using Google cloud. To do that, you have to create a disk on google cloud

Then use it to create a Persistent Volume (PV)
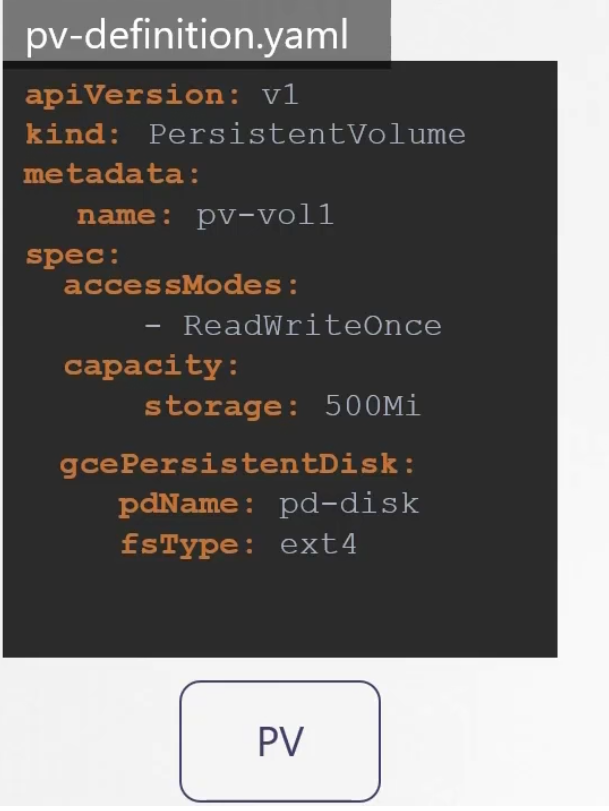
This is called static provisioning volumes
But it would be great if we can do it dynamically using storage classes.
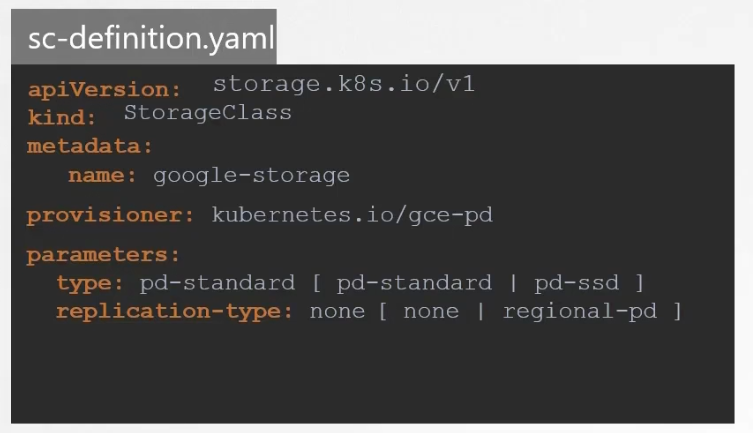
With storage class, we can define Provisioner such as Google Storage that can automatically provision storage on Google Cloud and attach that to pods when a claim is made.
How to create that?
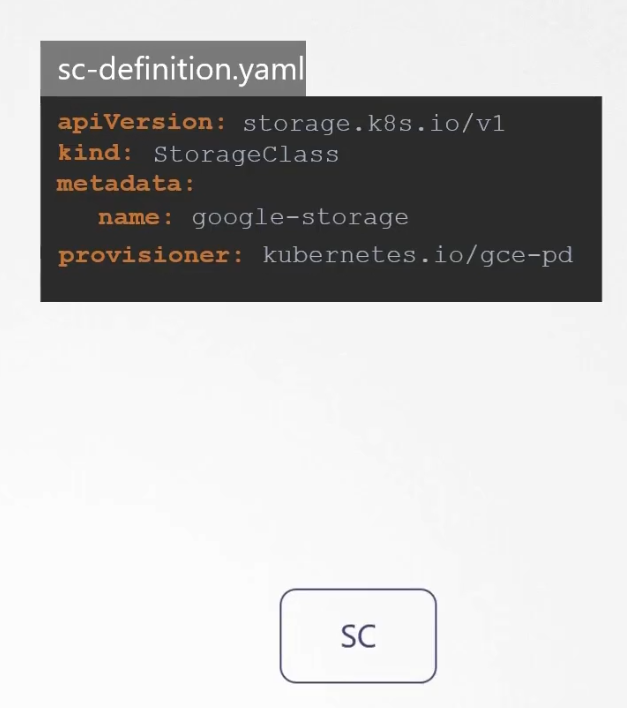
Here we chose google storag by mentioning provisioner.
Now, we don’t need Persistent definition yaml file any more. We just need to make a change in the pvc-definition.yaml file by adding storageClassName and set the name we set in the sc-definition.yaml file
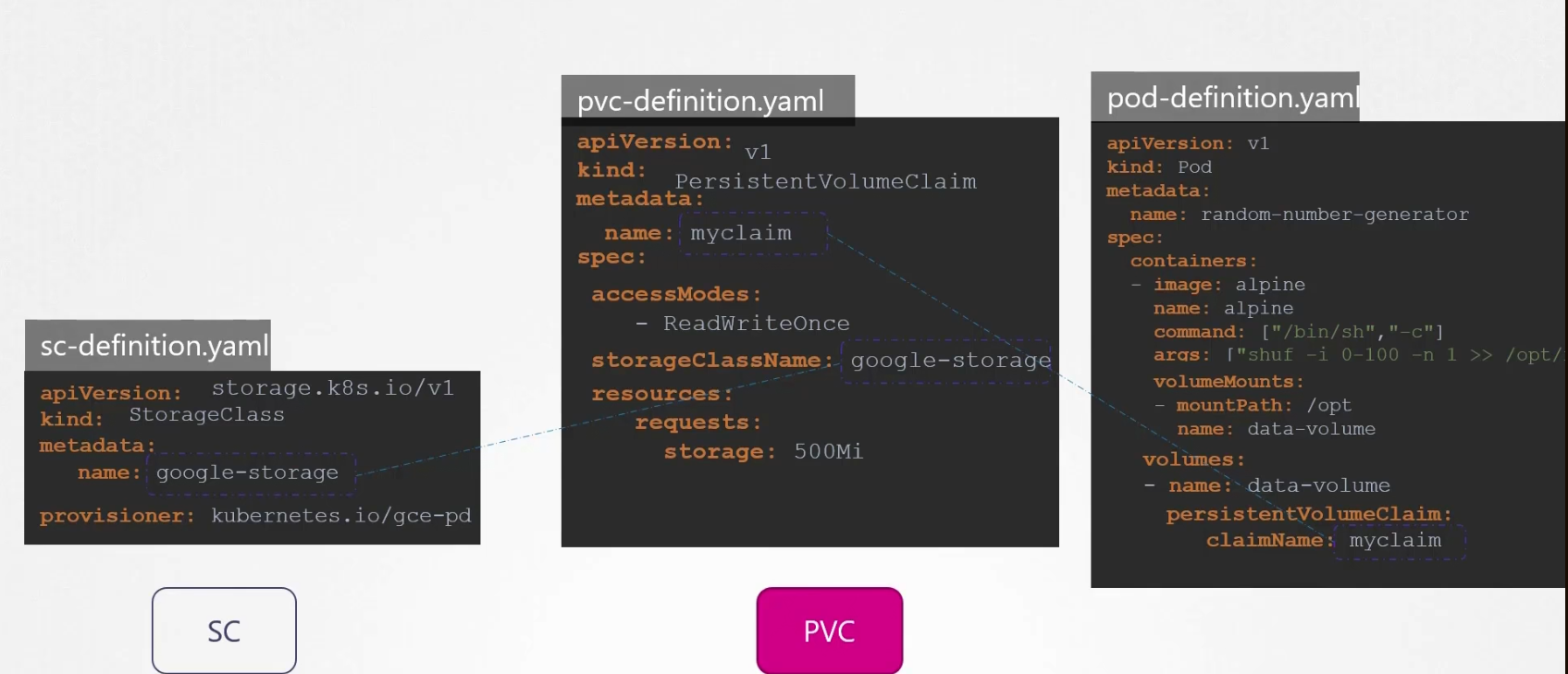
So, next time a PVC is created, the storage class (sc) associated with it (here, google-storage) uses the defined provisioner (here kubernetes.io/gce-pd) to provision a new disk with required size .
Then it creates a persistent volume (PV) and then binds the PVC to the volume it just crated earlier.
So, in the whole process we didn’t manually create a PV. Instead depending on the need of PVC, a PC was created on GCP.
There are other provisioners too just like Google Storage
We can also add additional parameters specific to the provisioner. Here for google storage, we can use type (standard → pd-standard or, ssd→ pd-ssd), replication-type (none or regional)
Subscribe to my newsletter
Read articles from Md Shahriyar Al Mustakim Mitul directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by