Fleet Ingress options for GKE Enterprise
 Tim Berry
Tim Berry
This is the fifth post in a series exploring the features of GKE Enterprise, formerly known as Anthos. GKE Enterprise is an additional subscription service for GKE that adds configuration and policy management, service mesh and other features to support running Kubernetes workloads in Google Cloud, on other clouds and even on-premises. If you missed the first post, you might want to start there.
So far in this series we’ve been focussing on how to build various types of clusters, and of course we’ve lightly touched on the concept of fleets while doing so. As we know, fleets are collections of GKE clusters, and we can use this top-level organisational concept to enable features and assign configurations across all clusters in a fleet.
In this post we’ll expand our knowledge of fleets and learn how they are used for advanced patterns of network and cluster isolation, and how we manage ingress across multi-cluster fleets. Fleets are an advanced grouping concept that allow us to manage collections of clusters based on different ideas of separation, such as deployment environment or even business unit. Fleets also allow us to distribute workloads and services easily across multiple clusters for high availability and failover.
In my previous post, we looked at an example of enabling configuration and policy management across all clusters in a fleet. But fleets also enable us to scale to multiple clusters while encouraging the normalisation of configuration and resources across clusters inside the same fleet. Google recommends the concept of sameness across all clusters in a fleet, using configuration management to create the same namespace and identity objects. This makes it much easier to deploy workloads that can span clusters in different ways, helping to provide advantages like geo-redundancy and workload isolation. By the end of this post, you’ll be able to identify which of Google’s recommended fleet design patterns would be most appropriate for your organisation!
Specifically, we’re going to learn:
Examples of Google-recommended fleet designs
The concepts of north-south and east-west routing
Use-cases for deploying workloads to multiple clusters
How to set up multi-cluster services and gateways
Let’s jump in!
Multi-cluster Design Patterns
We've already seen fleets in action in previous posts in this series, but let’s take a step back and truly familiarise ourselves with the fundamentals of fleets on GKE Enterprise before continuing any further.
Fleets, as we’ve said, are logical grouping of clusters and other configuration artifacts that belong to those clusters. There is a one-to-one mapping of projects and fleets: a single host project may hold a single fleet. However, as we’ll see in a moment, it is common to maintain multiple host projects and fleets, and clusters in different projects can belong to a fleet in another project.
Features such as configuration management and policy controllers are enabled at the fleet level. While it is possible to be selective about which clusters in the fleet are affected by these features, it’s a recommended best practice to normalise your fleet and apply configurations to all clusters. Clusters can only belong to a single fleet, but by grouping and managing multiple clusters into a fleet, we move the isolation boundary of trust from individual clusters to the level of the fleet itself. This means that there is an implied level of trust between individual clusters, and we must now consider the trust boundary from the point of view of different fleets and projects. If you have followed Google’s best practices for the organizational hierarchy of your cloud resources already, it’s likely that you already have similar project-based trust boundaries already established.
Let’s look at a multi-cluster example to explore this approach further.
A multi-cluster example
For this fictional example, we will consider an organisation with users in Europe and Asia, with a development team in the USA. The organisation currently deploys production workloads to GKE clusters in the europe-west1 and asia-southeast1 regions within the same Google Cloud project. Additionally, within that project, a staging GKE cluster is maintained in the us-central1 region. Development work takes place on an on-premises GKE cluster in the organisation’s USA office.
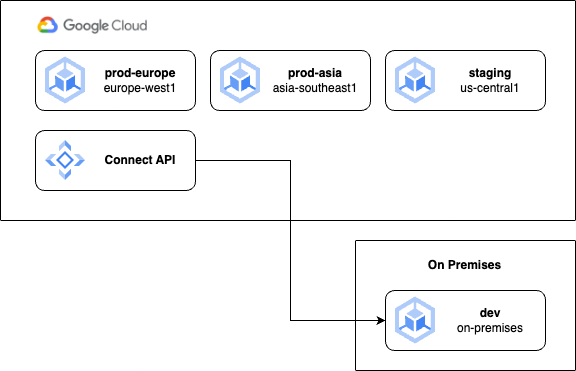
Within each production cluster we can imagine several namespaces for different applications, or frontend and backend services. When deciding how these clusters should be set up in fleets, we need to consider the concepts of isolation and consistency. If clusters are consistent, they may belong to the same fleet, however a degree of isolation is usually required to keep a production environment safe from unwanted changes. Right now, all the clusters belong to the same project and fleet, which may not be the best approach. So let’s look at a few different design patterns to see how we can achieve different levels of isolation and consistency, which should help you choose which one is right for your team.
Maximum isolation with multiple fleets
Let’s rearrange our clusters across different projects which are separated based on their operating environment: production, staging or development. As I mentioned earlier, this is a common approach to managing Google Cloud projects themselves, not just GKE clusters.
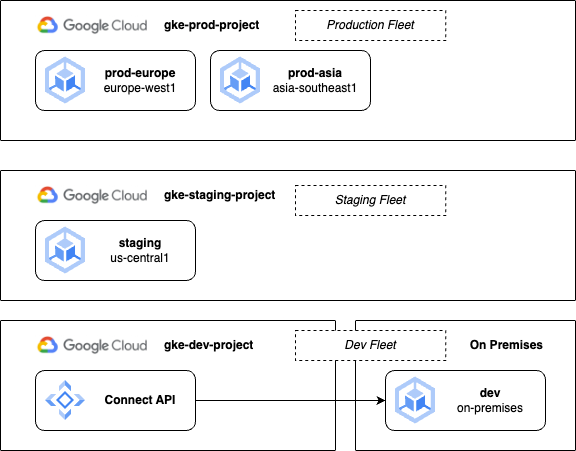
In a high-security environment this gives us the strongest possible isolation between clusters. However, we have now increased our operational complexity because we are managing three different fleets, which means three different sets of configuration management and feature settings. For example, some extra effort will be required to maintain consistency across namespaces and policies in the three sources of truth used. Additionally, development teams will need permissions configured across both development and staging fleets.
Project isolation with a shared fleet
To simplify management while retaining some resource isolation, let’s modify our design pattern to use a single fleet even if our clusters remain in different projects:
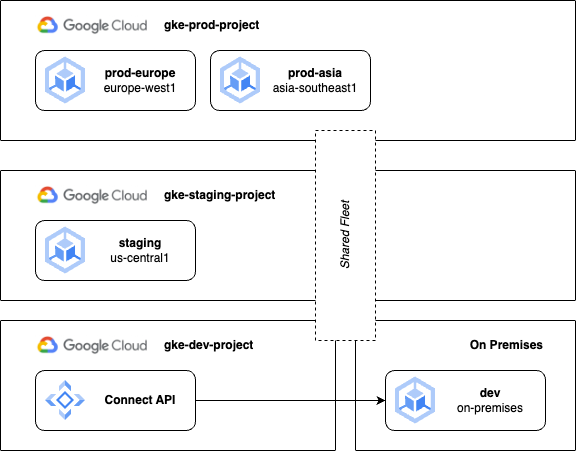
Using a single fleet achieves the maximum level of “sameness” across our clusters. In other words, we are back to using a single source of truth to define configurations, policies and namespaces. However, we haven’t eradicated the complexity completely, we’ve merely shifted it to a different set of tools. Now we’ll need to manage different namespaces for different environments (such as frontend-staging and frontend-prod), and potentially rely on a service mesh to decide which services may communicate across cluster and environment boundaries. This arrangement does however guarantee consistency between our development and production environments, which is important when testing application changes before promoting them to production.
Production and non-production fleets
Our final approach achieves a compromise, combining staging and development clusters into a single fleet to reduce some management complexity, while keeping the hard isolation of a separate fleet for production. This approach additionally allows you to test changes to fleet features and policies before promoting them to production.
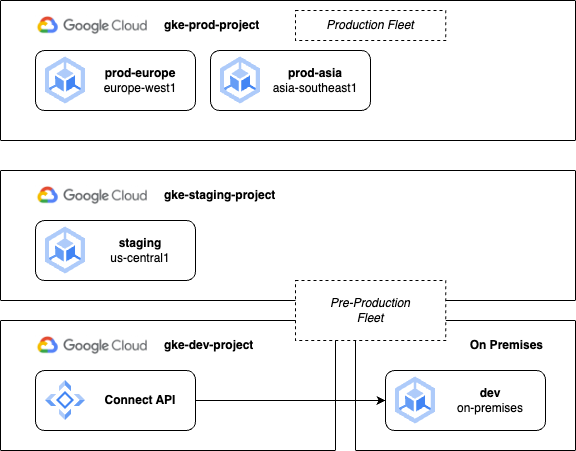
These examples represent just some basic examples of multi-cluster configurations. You may choose one of these or a different variation based on your own team or business requirements. Generally, Google’s recommended best practices suggest that you minimise the differences between production and non-production environments. If developers cannot build and test applications in an environment with parity to production, the chances of successful changes and deployments are reduced. This can be achieved through enforcing configuration management and using GitOps practices to manage the differences between a production and non-production source of truth.
There are other reasons to run multiple clusters despite separating environments. Often, an organization will want to run clusters in multiple locations to bring services closer to their users. Running multiple clusters in different regions also significantly increases availability in the event of downtime in a particular region, which may be a requirement of your organization. Sometimes, data must be held in a specific locality, such as data on European consumers which may be subject to EU data legislation.
Now, to help us map out use cases for multiple clusters, it's important to understand the conceptual terms of north-south and east-west routing in GKE Enterprise.
North-South routing
If you visualise your system in a diagram, think of the outside world at the top of the drawing and all your clusters next to each other below that. North-south routing in this pattern represents traffic or communications coming into your system from outside. Typically, this would be traffic from the Internet received via a Load Balancer, but it could also be communications inside Google Cloud that are still considered outside of your fleet of clusters. The important thing is the communication enters your system via a north-south route.
East-West routing
East-west routing by comparison represents communication between your clusters. The traffic has already entered your system, or it may have originated there, but it may be routed to different clusters inside the system based on different variables such as availability and latency. In a moment we’ll look at some basic patterns to help us understand these concepts, and this will lay the foundation for us to explore more advanced east-west patterns when we get to service mesh later in the series.
Multi-cluster Services
As we’ve already established, there are many use cases for running multiple clusters such as increased availability, capacity or data locality. Now that we’re running multiple clusters within a single fleet, we can start treating the fleet like one big virtual cluster. But how do we enable services and workloads to communicate across the cluster boundaries of our fleet?
We’re of course aware of the humble Kubernetes Service object, which creates a ClusterIP and a logical routing to a set of Pods defined by some label selectors. However, a Service only operates within the confines of a single cluster. To access a Service running on a different cluster within the same fleet in GKE Enterprise, we can configure something called a Multi-cluster Service (MCS). This configuration object creates a fleet-wide discovery mechanism, allowing any workload to access a Service anywhere in the fleet. Additionally, MCS objects can reference services running on more than one cluster for high availability.
To create an MCS, you export an existing service from a specific cluster. The MCS controller will then create an import of that service on all other clusters in the fleet. The controller will configure firewall rules between your clusters to allow Pod to Pod communication, set up Cloud DNS records for exported services, and use Google’s Traffic Director as a control plane to keep track of service endpoints.
At the time of writing, MCS objects were only supported on VPC-native GKE clusters running in Google Cloud, where the clusters can communicate either on the same VPC network (including a Shared VPC network) or a peered VPC network. MCS services cannot span clusters outside of a single project. Depending on your use case, these may be significant constraints. However, the MCS object is designed to be a simplistic approach to extending a standard Service object. As we’ll see later in future posts, more advanced patterns can be achieved using a service mesh.
An example multi-cluster service
Let’s walk through a basic example where we have a fleet of clusters providing a middleware service for our application stack, in this case, an imaginary service called checkfoo. As illustrated below, our clusters are distributed geographically so that frontend services run as close to our users as possible, but right now the checkfoo service only runs on a single cluster in the europe-west2 region. For simplicity, we’ll exclude the actual Pods from these diagrams. All clusters belong to the same fleet.
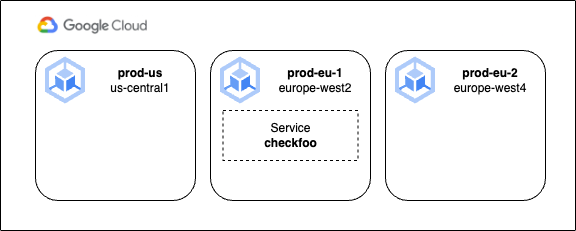
Because the checkfoo service runs on a ClusterIP on the prod-eu-1 cluster, it is currently only accessible from that cluster. So let’s fix that! The first thing we’ll need to do is enable multi-cluster services on the fleet. This can be done from the Cloud Console, or via the command line:
gcloud container fleet multi-cluster-services enable
Next, we’ll need to enable Workload Identity Federation for our clusters. When we set up multi-cluster services, GKE deploys a component to our clusters called the gke-mcs-importer, which needs permissions to read information about your VPC network and incoming traffic.
Side note: Workload Identity Federation is a very useful feature, which allows you to map Kubernetes service accounts to IAM service accounts and leverage those service accounts’ permissions for your Kubernetes workloads. You can read more about it here: https://cloud.google.com/kubernetes-engine/docs/concepts/workload-identity
If you’re using Autopilot clusters, Workload Identity Federation will already be enabled by default. I think it may soon be the default for standard clusters too, but if you’re working with existing clusters, you may have to enable it manually. Here’s an example for our prod-eu-1 cluster:
gcloud container fleet memberships register prod-eu-1 \
--gke-cluster europe-west2/prod-eu-1 \
--enable-workload-identity
Once Workload Identity Federation is enabled, we need to grant the required roles to the gke-mcs-importer service account (don’t forget to replace my-project-id in these examples with your own project ID):
gcloud projects add-iam-policy-binding my-project-id \
--member "serviceAccount:my-project-id.svc.id.goog[gke-mcs/gke-mcs-importer]" \
--role "roles/compute.networkViewer"
All that’s left to do now is to create a ServiceExport object on the cluster that is hosting our service. This simple object essentially just flags the target Service object for export and will be picked up by the MCS controller. Note in the example below, our service is running a namespace called foo:
kind: ServiceExport
apiVersion: net.gke.io/v1
metadata:
namespace: foo
name: checkfoo
There is quite a bit of scaffolding for the controller to set up the first time you create a ServiceExport, so it may take up to 20 minutes to synchronise changes to all other clusters in the fleet. Further exports and updates should only take a minute or so.
The process includes creating the matching ServiceImport object on every cluster, allowing the original service to be discovered, as well as setting up Traffic Director endpoints and health checks, plus the necessary firewall rules. Finally, MCS will register a cross-cluster FQDN in Cloud DNS that will resolve from anywhere in the fleet. In this example, the FQDN would be: checkfoo.foo.svc.clusterset.local (combining the service name checkfoo, with the namespace foo).
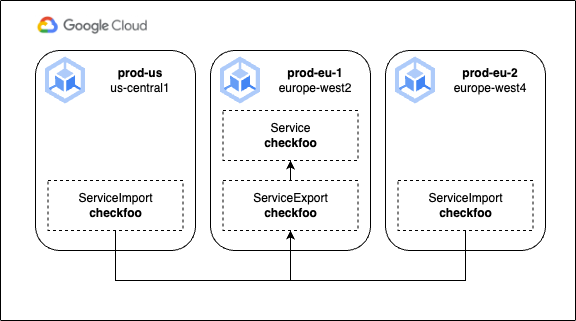
Note that at this stage, we could deploy a further checkfoo service to the prod-eu-2 cluster as well. Unlike a regular Service, an MCS can also use clusters as selectors, selecting any matching Pod on any cluster where those Pods may be running. The MCS provides a simple east-west internal routing for multi-cluster services, but as we’ll learn next, it provides a backbone for north-south incoming requests as well.
Multi-cluster Gateways
Controlling incoming traffic or network ingress for our Kubernetes clusters has taken many forms over the years as it has evolved. We started by integrating Load Balancer support into the humble Service object, then moved on to more advanced implementations of ingress with Ingress and IngressController objects. The current way forward is based on the Kubernetes project’s Gateway API, a more role-oriented, portable and expressive way to define service networking for Kubernetes workloads.
Inside Google Cloud, the GKE Gateway Controller implements the Gateway API and provides integration with Google’s cloud Load Balancing services. The Gateway controller is a managed service that runs in your project, but not inside your clusters themselves. It watches for changes in managed clusters, and then deploys and manages the necessary Load Balancing and other network services for you. The Gateway controller has an extensive list of features:
Support for internal and external load balancing, with HTTP, HTTPS and HTTP/2
Traffic splitting and mirroring
Geography and capacity-based load balancing
Host, path and header-based routing
Support for enabling and managing supporting features such as Google Cloud Armor, Identity-Aware Proxy and Cloud CDN
The Gateway Controller is available as a single-cluster or multi-cluster implementation. Conceptually the two approaches are the same, but we’ll explore the multi-cluster implementation in this post on the assumption that your fleets will be running more than one cluster.
Configuring Multi-cluster Gateways
If you’re already familiar with the Kubernetes Gateway API, it will help you understand how Google has implemented this API to support a multi-cluster gateway. If this is completely new to you, you might want to review the documentation here first.
The GKE Gateway Controller provides you with multiple GatewayClasses that can be used to define a gateway. These are:
gke-l7-global-external-managed-mcfor global external multi-cluster Gatewaysgke-l7-regional-external-managed-mcfor regional external multi-cluster Gatewaysgke-l7-rilb-mcfor regional internal multi-cluster Gatewaysgke-l7-gxlb-mcfor global external Classic multi-cluster Gateways
You choose a class when you create the Gateway object, as we’ll see in a moment. Just like in our previous example, a typical scenario for a multi-cluster gateway would involve multiple clusters, but these must all be in the same fleet and have Workload Identity Federation enabled.
You’ll need to choose one of your clusters to act as the config cluster. This cluster will host the Gateway API resources (Gateway, Routes and Policies) and control routing across all your clusters. This does however make the config cluster a potential single point of failure, because if its API is unavailable, gateway resources cannot be created or updated. For this reason, it's recommended to use regional rather than zonal clusters for high availability. It doesn’t have to be a dedicated cluster – it may also host other workloads, but it does need to have all of the namespaces that will be used by target clusters set up, and any user who will need to create ingress services across the fleet will need access to the config cluster (although potentially only for their own namespace).
Assuming we already have multi-cluster services enabled in our fleet (as described earlier), we can now enable the multi-cluster gateway by nominating a config cluster, such as the prod-us cluster from our previous example:
gcloud container fleet ingress enable \
--config-membership=projects/my-project-id/locations/us-central1/memberships/prod-us
Next, we need to grant IAM permissions required by the gateway controller. Note that in this command, you will need your project ID and your project number, which you can find in the Cloud Console. In this example, we’re using the fake project number of 555123456555 just so you can see how this references the relevant service account:
gcloud projects add-iam-policy-binding my-project-id \
--member "serviceAccount:service-555123456555@gcp-sa-multiclusteringress.iam.gserviceaccount.com" \
--role "roles/container.admin"
We can now confirm that the GKE Gateway Controller is enabled for our fleet, and that all the different GatewayClasses exist in our config cluster, with the following two commands:
gcloud container fleet ingress describe
kubectl get gatewayclasses
We’re now ready to configure a gateway! For this example, we’ll deploy a sample app to both of our European clusters, then configure the services to be exported as a multi-cluster service, and finally set up an external multi-cluster Gateway.
We’ll use the gke-l7-global-external-managed-mc gateway class, which provides us with an external application load balancer. When we’ve finished, external requests should be routed to either cluster based on the cluster health and capacity, and the proximity of the cluster to the user making the request. This provides the lowest latency and best possible service for the end-user. The app itself is just a basic web server that tells us where it’s running to help us test this.
Another quick aside: This stuff is cutting edge! At the time of writing, the command to enable ingress and set up the controller didn’t exactly have a 100% success rate. If at this stage you don’t see any GatewayClasses in your config cluster, you can force the controller to install with this command:
gcloud container clusters update --gateway-api=standard --zone=<cluster zone>
Substitute --region=<cluster-region> for regional clusters. Also, if you see some classes, but not the multi-cluster ones (denoted with the suffix mc), try disabling the fleet ingress feature and re-enabling it sometime later (after you have forced the controller to install). Hopefully some of these bugs will get ironed out as the features mature!
Deploying the app and setting up the multi-cluster service
Using our existing fleet, we’ll now create a namespace across all our clusters, and deploy a test app to just our EU clusters. Then we’ll set up the Gateway and HTTPRoute on our config cluster, and test ingress traffic from different network locations. Let’s imagine we’re creating something like an e-commerce store, but again we’ll just be using an app that shows us the Pod it’s running from.
First, we'll create the store namespace on all the clusters in the fleet:
kubectl create ns store
You need to repeat this for every cluster; you could use different contexts in kubectl or a tool like kubectx.
Next, we’ll create the store deployment. This is just a basic 2-replica deployment that uses Google’s whereami container to answer requests with details about where it is running. We'll use the following YAML, and we’ll create this deployment on the prod-eu-1 and prod-eu-2 clusters. (Just write the YAML to a file and use kubectl apply):
apiVersion: apps/v1
kind: Deployment
metadata:
name: store
namespace: store
spec:
replicas: 2
selector:
matchLabels:
app: store
version: v1
template:
metadata:
labels:
app: store
version: v1
spec:
containers:
- name: whereami
image: us-docker.pkg.dev/google-samples/containers/gke/whereami:v1.2.20
ports:
- containerPort: 8080
We’ll also create a Service object for each deployment, as well as a ServiceExport, so that the MCS controller can pick it up and create a ServiceImport on every cluster in the fleet. Once again, the YAML required is very simple:
apiVersion: v1
kind: Service
metadata:
name: store
namespace: store
spec:
selector:
app: store
ports:
- port: 8080
targetPort: 8080
---
kind: ServiceExport
apiVersion: net.gke.io/v1
metadata:
name: store
namespace: store
These objects are applied to the prod-eu-1 and prod-eu-2 clusters, where the previous deployments were also applied. Unlike our intentions in the first part of this post, we’re not doing this for cluster-to-cluster communication, but to help our Gateway find our services on either cluster. A corresponding ServiceImport will be created on any cluster that does not host the ServiceExport (in this case, prod-us), and this object will be used by our Gateway as a logical identifier for a backend service, pointing it at the other cluster endpoints. Using a ServiceImport as a backend instead of a Service means our target Pods could run on any cluster in the fleet!
Here’s what it all looks like now:
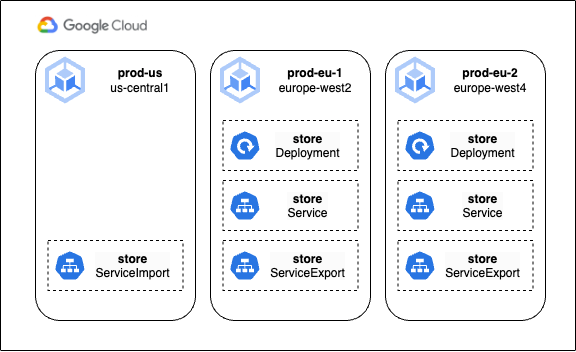
With our multi-cluster workload running happily in our fleet, we can now set up the necessary objects to expose it to the outside world. As we’ve already enabled the multi-cluster gateway controller, we can now create a Gateway object which defines how we would like to create and leverage a Load Balancer.
We’ll use the gke-l7-global-external-managed-mc class for our Gateway, which specifies that we want to use the global HTTPs load balancer with multi-cluster support. The separation of duties enabled by the Kubernetes Gateway API means that we create the Load Balancer now with this object, but we can configure HTTP routes (in other words, its URL map) later.
We’ll deploy this configuration object to our config cluster (in our example, prod-us):
kind: Gateway
apiVersion: gateway.networking.k8s.io/v1beta1
metadata:
name: external-http
namespace: store
spec:
gatewayClassName: gke-l7-global-external-managed-mc
listeners:
- name: http
protocol: HTTP
port: 80
allowedRoutes:
kinds:
- kind: HTTPRoute
Finally, we’ll add an HTTPRoute to the config cluster to configure how we would like the load balancer to route requests to our backend services (or service imports in this case):
kind: HTTPRoute
apiVersion: gateway.networking.k8s.io/v1beta1
metadata:
name: public-store-route
namespace: store
labels:
gateway: external-http
spec:
hostnames:
- "store.example.com"
parentRefs:
- name: external-http
rules:
- backendRefs:
- group: net.gke.io
kind: ServiceImport
name: store
port: 8080
This is a very basic example, where all requests to the load balancer that contain the hostname store.example.com in the header will be routed to the ServiceImport called store. Of course, you have the full power of the Kubernetes Gateway API at your disposal, and you could configure your HTTPRoute object to route to multiple different backends based on URL path, HTTP headers or even query parameters. For more details see https://gateway-api.sigs.k8s.io/api-types/httproute/
After a few minutes, the Gateway should be ready. You can confirm its status with this command:
kubectl -n store describe gateways.gateway.networking.k8s.io external-http
Now we just need to grab the external IP address to test a connection. We get this with a modified kubectl command:
kubectl get gateways.gateway.networking.k8s.io external-http -o=jsonpath="{.status.addresses[0].value}" --context prod-us --namespace store
We can use curl from the command line to test the external IP, passing in a header to request the hostname we specified in the HTTPRoute. In this example, replace the sample IP address with the one you got from the previous command:
curl -H "host: store.example.com" http://142.250.200.14
You should see some output similar to the screenshot below, showing a response from the Pod that includes its cluster name, Pod name, and even the Compute Engine instance ID its running from. Which region serves your request will depend on your current location (or if you’re using the Cloud Shell terminal, the location of your Cloud Shell VM).

We can experiment with the locality-based routing by creating test VMs in different regions. For example, if we create a test VM in europe-west4, we should see our request served by the prod-eu-2 cluster:

We have now successfully configured a multi-cluster service running across different regions in our fleet, with a single global HTTPS load balancer directing incoming traffic to the backend that is closest to our users and in a healthy state. Additionally, we know from the power of the HTTPRoute object that we could introduce URL maps and more complex route matching for multiple backend services and service imports. In a later post we’ll look at how to integrate additional Google Cloud services into gateways, such as Cloud Armor for web-application firewall protection, and the Identity-Aware-Proxy (IAP).
The final state of our example fleet, including the flow of requests, is shown below. Note that despite the seemingly complex logic we’ve set up, the actual flow of traffic goes directly from the load balancer frontend to the Pods themselves via Network Endpoint Groups (NEGs):
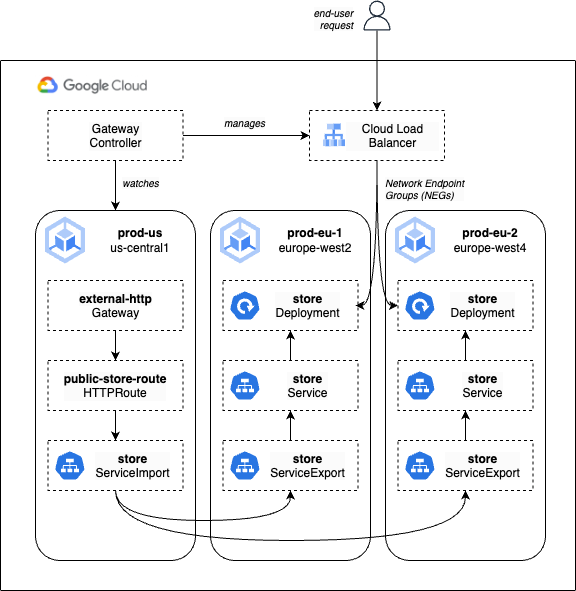
Summary
In the first few posts in this series we introduced some of the new fundamental concepts that set GKE Enterprise apart from a standard Kubernetes infrastructure deployment. Along the way we’ve gradually built up our knowledge of fleets, and you should now have a good idea of how you might design your own systems based on multiple clusters and potentially multiple fleets.
Of course there are many ways to achieve a desired outcome, and each will have their own tradeoffs. It’s worth sketching out the possibilities before committing to any design, and if you commit to reading future posts in this series (thank you!) you should still feel free to revisit the ideas in this post on how to achieve different levels of isolation or management complexity.
Hopefully you’ve finished this post with an understanding of how to create a truly multi-cluster deployment. While the fully managed Gateway controller dynamically provisions and operates load balancers for us, you may be wondering about its limitation to back-ends that run inside Google Cloud clusters. There are two scenarios where this limitation may impact you:
If your back-end service runs in an on-premises cluster, but you still want to use a Google Cloud load balancer. According to Google Cloud, this isn’t exactly a preferred design pattern. However, it is still achievable outside of GKE Enterprise services using Network Endpoint Groups with hybrid connectivity. For more information see https://cloud.google.com/load-balancing/docs/negs/hybrid-neg-concepts.
If your front-end workloads run in Google Cloud, but they need to communicate with workloads on external clusters.
While this arrangement isn’t supported by a standard MCS, we’ll soon learn that this can be achieved, along with so much more, in the amazing world of service mesh. We’ve got the fundamentals out of the way, so in the next post I can really dig into the nuts and bolts of Istio and use service mesh for traffic routing, service identity, service security and more!
Subscribe to my newsletter
Read articles from Tim Berry directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by