From Information to Knowledge: How to Talk to Knowledge Graphs
 Ali Yazdizadeh
Ali Yazdizadeh
In the previous parts of this series, we explored the foundational aspects of Knowledge Graphs (KGs), including their difference from traditional databases and the critical role that ontology plays in structuring and organizing data. Now that we have a solid understanding of how Knowledge Graphs are built and what makes them powerful, it's time to know how to interact with them. This brings us to query languages, the tools we use to ask questions and extract meaningful insights from Knowledge Graphs.
Recap with Example
Let's recap with a simple example. Imagine you're working with a Knowledge Graph for an online bookstore. The graph represents entities like customers, books, authors, and orders, and captures relationships such as "purchased," "wrote," or "recommended." So far, we've discussed how this graph helps link different entities together, making it easier to ask complex questions. For instance, instead of simply asking, "What books did customer X buy?" we could ask more nuanced questions like, "What books do customers who purchased a particular author’s work also tend to recommend?"
We need to "talk" to the Knowledge Graph to extract these insights. In this part, we’ll explore the different languages you can use to communicate with your graph and how modern AI tools, like Large Language Models (LLMs), are making this easier than ever.
How to Talk to Knowledge Graphs
At the core of interacting with Knowledge Graphs is the concept of querying—requesting specific data or patterns from the graph. To perform these queries, there are specialized languages designed for graph-based data. Just as SQL is used for querying relational databases, there are query languages tailored for Knowledge Graphs.
What is a Query Language?
A query language is a specialized syntax used to retrieve, manipulate, or update data from a database. In the context of Knowledge Graphs, query languages allow us to explore the relationships between entities and extract specific pieces of knowledge from the graph. The three most popular query languages for Knowledge Graphs are:
Cypher (used by Neo4j and other property graph databases)
SPARQL (designed for querying RDF-based graphs)
Gremlin (a graph traversal language used by property graphs like Amazon Neptune)
Let's take a look at each of these in more detail.
Cypher: The Language for Property Graphs
Cypher is the most commonly used query language for property graph databases, particularly Neo4j. It is designed to be intuitive and easy to read, borrowing elements from SQL but tailored for traversing relationships in a graph.
For example, if you wanted to find all customers who bought a book written by a specific author in a Neo4j Knowledge Graph, the query might look like this:
MATCH (author:Author {name: 'George Orwell'})-[:WROTE]->(book:Book)<-[:PURCHASED]-(customer:Customer)
RETURN customer.name
This query specifies a pattern that connects an author to their book and retrieves the customers who purchased that book. Cypher makes querying intuitive by focusing on the relationships between entities.
SPARQL: The Language for RDF Stores
SPARQL is the query language specifically designed for querying RDF (Resource Description Framework) data in triple stores like Apache Jena. SPARQL excels at handling semantic queries and enables users to query across vast, highly interconnected datasets.
An equivalent query to find customers who bought books by George Orwell in an RDF-based Knowledge Graph would look like this in SPARQL:
SELECT ?customerName WHERE {
?author rdf:type :Author .
?author :name "George Orwell" .
?author :wrote ?book .
?purchase :purchased ?book .
?purchase :customer ?customer .
?customer :name ?customerName .
}
SPARQL uses the triple-based subject-predicate-object model, which is more formal and specific compared to Cypher. SPARQL also allows for more advanced semantic queries, such as reasoning and inference.
Gremlin: A Graph Traversal Language
Gremlin is a more general-purpose query language for graphs, used in databases like Amazon Neptune and Apache TinkerPop. Gremlin focuses on graph traversal—navigating through nodes and edges to extract insights.
The same query in Gremlin would look like this:
g.V().hasLabel('Author').has('name', 'George Orwell')
.out('WROTE').in('PURCHASED')
.values('customerName')
Gremlin is highly versatile and works well for complex traversals, but it can be less intuitive than Cypher or SPARQL, as it focuses on step-by-step navigation through the graph’s structure.
Comparing Query Languages
Here’s a quick comparison of the three query languages:
| Query Language | Database Type | Focus | Strengths |
| Cypher | Property Graph | Pattern Matching | Intuitive, easy to learn, great for traversals |
| SPARQL | RDF (Triple Stores) | Semantic Queries | Supports reasoning, standardized, semantic relationships |
| Gremlin | Property Graph | Graph Traversal | Powerful for custom traversals, highly flexible |
How LLMs Help Knowledge Graphs: Easier Query Generation
One of the most exciting recent developments in the world of Knowledge Graphs is the ability to combine them with Large Language Models (LLMs) like GPT. LLMs can make querying Knowledge Graphs far more accessible, even to non-experts, by translating natural language queries into formal query languages like Cypher or SPARQL.
For example, instead of manually writing a query, a user could simply ask the system in natural language:
"Show me all the customers who bought a book by George Orwell."
An LLM can then generate the corresponding Cypher or SPARQL query behind the scenes, making it easier for users to interact with Knowledge Graphs without needing deep technical expertise.
How Knowledge Graphs Help LLMs: Retrieval-Augmented Generation (RAG)
On the flip side, Knowledge Graphs can enhance the performance of LLMs through Retrieval-Augmented Generation (RAG). LLMs, which are typically trained on vast amounts of unstructured data, can sometimes struggle with specific, detailed queries or with retrieving facts that aren't easily deduced from general patterns. Integrating a Knowledge Graph into this process allows the model to retrieve precise, structured information from the graph, improving the accuracy and relevance of generated responses.
For example, if an LLM is answering questions about an e-commerce platform, it could query the Knowledge Graph to retrieve product information, purchase history, or customer preferences—data that would otherwise be hard for the model to infer from free-form text alone.
Problem with Unstructured Data and Vector Databases
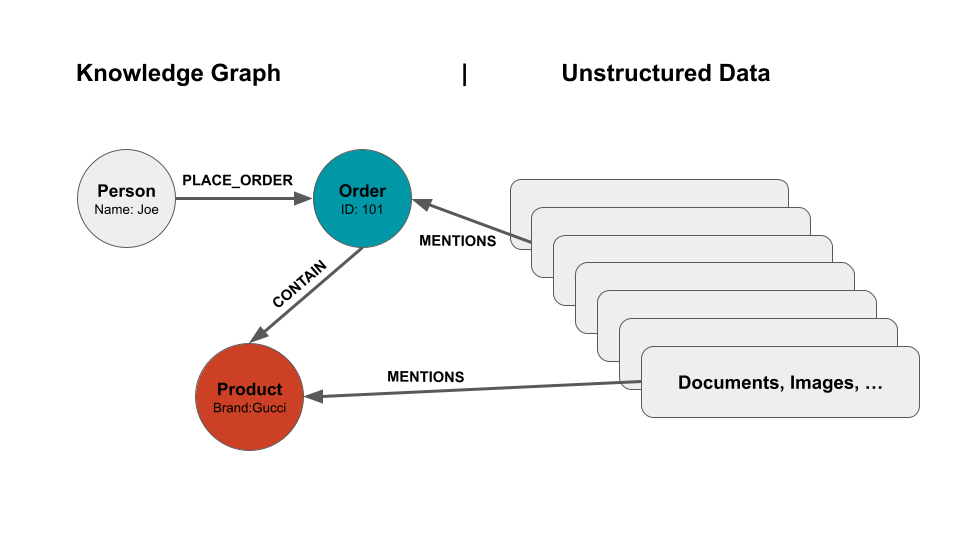
Unstructured data stored in systems like vector databases (which index data by converting it into embeddings for similarity searches) often miss out on critical connections between pieces of information. For instance, while vector databases might return documents that are contextually similar, they may lack the ability to understand and exploit the explicit relationships between entities, as Knowledge Graphs do, resulting in missing the right context or a misleading one!
How Knowledge Graphs Solve This Problem
By integrating Knowledge Graphs into the RAG framework, we can overcome this limitation. A Knowledge Graph provides structured, interconnected data that helps ensure the system doesn’t just return the closest match based on textual similarity but instead retrieves the most relevant and accurate knowledge based on real-world relationships. For example, if the query mentions something about the brand “Gucci”, the Knowledge Graph helps the RAG system to find the documents that mention the brand name too! This makes Knowledge Graphs a key component in improving the precision of RAG systems, enhancing their ability to answer complex questions effectively.
Conclusion: A Win-Win Relationship
Query languages enable us to interact with Knowledge Graphs, and with the integration of LLMs, even non-technical users can now create these queries. The relationship between AI and Knowledge Graphs is symbiotic, with Knowledge Graphs enhancing LLMs' ability to provide better context through techniques like RAG.
In our course, AI for Business, we'll explore how businesses can leverage AI to supercharge decision-making, streamline data retrieval, and much more. Stay tuned and don't miss out on learning how these technologies can transform your organization!
Subscribe to my newsletter
Read articles from Ali Yazdizadeh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by