How to Build LangGraph Agent with Long-term Memory
 Shreyas Dhaware
Shreyas Dhaware
Introduction
The future of AI depends on solving a key issue with large language models (LLMs): their inability to retain long-term information during extended conversations. This limitation can lead to inaccurate responses in fields like healthcare and customer support, where continuous context is crucial. Stateful or "memory-augmented" models offer a solution by storing and recalling information over time, enabling more seamless, context-aware interactions. These models provide richer insights, making them ideal for complex, data-driven environments requiring sustained attention and accuracy.
In the context of AI systems, short-term memory and long-term memory refer to how information is stored and retrieved across different interactions:
Short-term memory: It captures information from a single conversation or interaction thread. This memory is typically used to maintain context within a session and allows AI to recall recent actions, queries, and responses. In LangGraph, short-term memory is managed using a state
checkpointer. Thecheckpointersaves a checkpoint of the graph state at every super-step within a Thread.Long-term memory: Long-Term Memory is used to retain information across multiple sessions or conversations. Long-term memory enables an AI to remember details about previous interactions even after a session ends. In LangGraph, long-term memory is persisted using a Memory Store. We can define a store to add Personalized Information about a User across threads.
If you're interested in learning how to build and customize LangGraph agents for specific tasks or workflows, I recommend checking out LangGraph Tutorial: A Comprehensive Guide for Beginners
What is Long Term Memory in Langchain
Long Term Memory persists across different threads, allowing the AI to recall user preferences, instructions, or other important data. LangGraph handles long-term memory by saving it in custom "namespaces," which essentially reference specific sets of data stored as JSON documents. Each memory type is a Python class. This kind of memory can be useful for creating more personalized and adaptive user experiences.
A memory type is associated with a list of attributes such as a namespace, key, and value. The namespace helps organize and categorize the memory. However, namespaces are flexible and can represent anything, not limited to user-specific information. The key is used to represent the memory ID, acting as a unique identifier
from langgraph.store.memory import InMemoryStore
in_memory_store = InMemoryStore()
user_id = "1"
namespace_for_memory = (user_id, "memories")
memory_id = str(uuid.uuid4())
memory = {"food_preference" : "I like pizza"}
in_memory_store.put(namespace_for_memory, memory_id, memory)
memories = in_memory_store.search(namespace_for_memory)
memories[-1].dict()
{'value': {'food_preference': 'I like pizza'},
'key': '07e0caf4-1631-47b7-b15f-65515d4c1843',
'namespace': ['1', 'memories'],
'created_at': '2024-10-02T17:22:31.590602+00:00',
'updated_at': '2024-10-02T17:22:31.590605+00:00'}
Explore how to enhance your Langchain applications with Mem0, a memory management system that personalizes AI interactions. This blog highlights Mem0's integration, showcasing its similarity search feature
Setting Up Your Environment
Before you begin, ensure you have the necessary prerequisites:
Python environment with required libraries.
Access to OpenAI API keys.
Install Required Packages
Before setting up your environment, make sure to install the necessary packages. If you're using a Google Colab notebook, you can run the following command in a cell:
pip install -U langgraph langchain_openai
Setting up environment variables
Once the packages are installed, set up your environment variables:
import getpass
import os
def _set_env(var: str):
if not os.environ.get(var):
os.environ[var] = getpass.getpass(f"{var}: ")
_set_env("OPENAI_API_KEY")
Building Long-Term Memory Example
Loading Checkpointer and Storage Long-Term Storage
from langgraph.store.memory import InMemoryStore
in_memory_store = InMemoryStore()
LangGraph provides an InMemoryStore system to manage long-term memory within conversational agents or workflows. It is not a Persistence Storage.
import uuid
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnableConfig
from langgraph.graph import StateGraph, MessagesState, START, END
from langgraph.store.base import BaseStore
from typing import Annotated, Optional
from langchain_core.tools import InjectedToolArg, tool
import uuid:- This generates universally unique identifiers (UUIDs), often used to create unique references.
from langgraph.graph import StateGraph, MessagesState, START, END:StateGraph: Represents a graph that tracks the state of a conversational agent. It allows for storing and handling the flow of state and data.MessagesState: Handles conversation history as part of the agent's memory and automatically appends every interaction to the state.
from langchain_core.tools import InjectedToolArg, tool:The
InjectedToolArgannotation lets us hide certain parameters, likeuser_id,configfrom the model, ensuring they're injected automatically at runtime. This keeps sensitive data secure while simplifying the model's responsibilities.tool: A decorator used to define tools or functions that the agent can call as part of its process.
Constructing a Tool
@tool
def upsert_memory(
content: str,
context: str,
memory_id: Optional[str] = None,
*,
config: Annotated[RunnableConfig, InjectedToolArg],
store: Annotated[BaseStore, InjectedToolArg],
):
"""Upsert a memory in the database.
If a memory conflicts with an existing one, then just UPDATE the
existing one by passing in memory_id - don't create two memories
that are the same. If the user corrects a memory, UPDATE it.
Args:
content: The main content of the memory. For example:
"User expressed interest in learning about French."
context: Additional context for the memory. For example:
"This was mentioned while discussing career options in Europe."
memory_id: ONLY PROVIDE IF UPDATING AN EXISTING MEMORY.
The memory to overwrite.
"""
mem_id = memory_id or uuid.uuid4()
user_id = config["configurable"]["user_id"]
store.put(
("memories", user_id),
key=str(mem_id),
value={"content": content, "context": context},
)
return f"Stored memory {content}"
The upsert_memory function either creates a new memory or updates an existing one if it already exists. It allows the user to store memories with two key attributes: content (the main memory) and context (additional information to help frame the memory).
Storing memories as a collection of documents simplifies certain tasks, making each memory more focused and easier to generate while improving recall, since creating new objects for new information is often more effective than trying to update one profile.
For more on profile-based and document-based memory organization, refer to the official LangGraph documentation. It provides insights into managing complexity in long-term memory updates and balancing efficient recall with accurate information storage.
Setting Nodes for Memory Storage
def store_memory(state: MessagesState, config: RunnableConfig, store: BaseStore):
# Extract tool calls from the last message
tool_calls = state["messages"][-1].tool_calls
saved_memories=[]
for tc in tool_calls:
content = tc['args']['content']
context = tc['args']['context']
saved_memories.append([
upsert_memory.invoke({'content': content, 'context': context, 'config':config, 'store':store})
])
print("saved_memories: ", saved_memories)
results = [
{
"role": "tool",
"content": mem[0],
"tool_call_id": tc["id"],
}
for tc, mem in zip(tool_calls, saved_memories)
]
print(results)
return {"messages": results[0]}
In LangGraph, nodes are key components of a workflow that perform distinct tasks, such as communicating with an LLM, interacting with external tools, or processing data. the function store_memory extracts tool calls from the latest message and uses them to save memories in store. Memory is saved by invoking the upsert_memory function, which takes content, and context as inputs. For Tool Message the stored Memory ID is formatted, with the role ("tool"), and the corresponding tool call ID, before being returned. Can return the memory content so the user knows what memory is being stored.
Writing memories in the hot path involves saving them while the application is running, offering benefits like real-time updates—making memory immediately available—and greater transparency. This builds trust, since the system explicitly decides what to save. However, there are downsides. The system is multitasking, balancing memory management with its primary task.
Setting Nodes for Agent
def call_model(state: MessagesState, config: RunnableConfig, *, store: BaseStore):
user_id = config["configurable"]["user_id"]
namespace = ("memories", user_id)
memories = store.search(namespace)
info = "\n".join(f"[{mem.key}]: {mem.value}" for mem in memories)
if info:
info = f"""
<memories>
{info}
</memories>"""
system_msg = f'''You are a helpful assistant talking to the user. You must decide whether to store information as memory from list of messages and then answer the user query or directly answer the user query
User context info: {info}'''
print("system_msg:", system_msg)
# Store new memories if the user asks the model to remember
last_message = state["messages"][-1]
print( [{"type": "system", "content": system_msg}] + state["messages"])
response = model.bind_tools([upsert_memory]).invoke(
[{"type": "system", "content": system_msg}] + state["messages"]
)
return {"messages": response}
The call_model function retrieves stored memories for a specific user from a storage (store), formats these memories as part of a system message, and uses that information to provide context for generating a response to the user's query. The memories are fetched based on the user ID and are then formatted into a structured XML-like block (<memories> tag) to be included in the system message.
The system message is intended to inform the model of any relevant context from prior interactions to help it determine whether to update the memory or simply respond to the current user query. Finally, the function returns the generated response.
Conditional Edge Logic
def route_message(state: MessagesState):
"""Determine the next step based on the presence of tool calls."""
msg = state["messages"][-1]
if msg.tool_calls:
# If there are tool calls, we need to store memories
return "store_memory"
# Otherwise, finish; user can send the next message
return END
The route_message function determines the next action based on the presence of tool calls in the latest message. If tool calls exist, it directs the workflow to store memories by returning "store_memory"; otherwise, it concludes the current process by returning END.
Loading and Compiling Graph
builder = StateGraph(MessagesState)
builder.add_node("call_model", call_model)
builder.add_node(store_memory)
builder.add_edge(START, "call_model")
builder.add_conditional_edges("call_model", route_message, ["store_memory", END])
builder.add_edge("store_memory", "call_model")
graph = builder.compile(store=in_memory_store)
StateGraph is constructed by adding nodes representing different actions like call_model and store_memory, with conditional routing between them based on the route_message function. After defining the workflow, the graph is compiled into a runnable instance using the provided in_memory_store, enabling the execution of the defined conversational flow. Optionally, a checkpointer MemorySaver can be used for short-term memory handling.
Visualize the Graph:
By running a simple Python code, you can visualize the graph with nodes and edges.
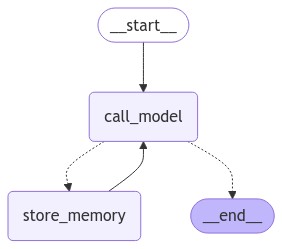
Source: Author
Run the graph!
config = {"configurable": {"thread_id": "1", "user_id": "1"}}
input_message = {"type": "user", "content": "Hi! My name is Bob. I love keep updated on Latest Tech"}
for chunk in graph.stream({"messages": [input_message]}, config, stream_mode="values"):
chunk["messages"][-1].pretty_print()
This code initiates a conversation by passing the user's input (input_message) and configuration to the compiled graph. The conversation flow is executed in streaming mode, with the chatbot processing the message and outputting a response, which is printed. To improve this, a loop can be added to continuously interact with the user, feeding their inputs into the graph and displaying the chatbot's responses, enabling an ongoing conversation instead of a single exchange.
Output
================================ Human Message =================================
Hi! My name is Bob. I love keep updated on Latest Tech
system_msg: You are a helpful assistant talking to the user. You must decide whether to store information as memory from list of messages and then answer the user query or directly answer the user query
User context info:
================================== Ai Message ==================================
Tool Calls:
upsert_memory (call_DEstE5sEOltuEE4lbfcgZPar)
Call ID: call_DEstE5sEOltuEE4lbfcgZPar
Args:
content: User's name is Bob and he loves keeping updated on the latest tech.
context: Bob introduced himself and shared his interest in technology.
================================= Tool Message =================================
Stored memory User's name is Bob and he loves keeping updated on the latest tech.
system_msg: You are a helpful assistant talking to the user. You must decide whether to store information as memory from list of messages and then answer the user query or directly answer the user query
User context info:
<memories>
[7a5a3425-4617-4794-9207-0dd7ffe28f05]: {'content': "User's name is Bob and he loves keeping updated on the latest tech.", 'context': 'Bob introduced himself and shared his interest in technology.'}
</memories>
================================== Ai Message ==================================
Hi Bob! It's great to meet someone who loves staying updated on the latest tech. How can I assist you today?
Conclusion
Integrating long-term memory into AI systems marks a major step forward in enhancing language models (LLMs). Managing long-term memory—whether in real-time (hot path) or in the background—balances performance with data retention. Techniques like profile-based and document-based memory organization also improve the system's ability to store and recall relevant information.
By integrating nodes for memory storage, retrieval, and conversational processing, developers can build more context-aware agents capable of updating and refining user information in real-time. The use of conditional edge logic ensures that memory storage and retrieval only occur when needed, balancing performance with accuracy.
To build a reliable LLM agent, leveraging both short-term and long-term memory is crucial. Short-term memory helps maintain session context, while long-term memory allows the agent to recall past interactions, leading to more personalized and accurate responses over time. Combining these ensures more intelligent, responsive, and user-friendly applications.
Resources and References
Follow FutureSmart AI to stay up-to-date with the latest and most fascinating AI-related blogs - FutureSmart AI
Looking to catch up on the latest AI tools and applications? Look no further than AI Demos This directory features a wide range of video demonstrations showcasing the latest and most innovative AI technologies.
Next Steps: Bringing AI into Your Business
Whether you're looking to integrate cutting-edge NLP models or deploy multimodal AI systems, we're here to support your journey. Reach out to us at contact@futuresmart.ai to learn more about how we can help.
Don't forget to check out our futuresmart.ai/case-studies to see how we've successfully partnered with companies to implement transformative AI solutions.
Let us help you take the next step in your AI journey.
Subscribe to my newsletter
Read articles from Shreyas Dhaware directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by