How to Use Raycast & Firecrawl to Transform Websites into Markdown
 maguro
maguroOverview
To effectively enhance LLM performance, providing context is one of the most essential elements. However, for a well-structured website, crawling all the pages can be a bit challenging, and we need to develop an application to achieve this. In this article, I will show you how I created a Raycast script to call Firecrawl and convert the data accordingly.
What is Raycast?
Raycast is a fantastic application launcher and productivity software designed for macOS. This app makes it a breeze to launch applications, search for files, execute commands, and manage your Mac through an intuitive interface. Plus, it serves as a clipboard manager and text expander, and you can enhance its functionality with extensions. It's available for free, with a pro version that offers exciting AI features.
What is Firecrawl?
Firecrawl is an incredible tool designed to efficiently gather data from websites and format it specifically for large language models (LLMs). Here are its key features and characteristics:
Web Crawling: Firecrawl begins at a specified URL and thoroughly crawls the entire website. If a sitemap is available, it takes advantage of that; if not, it follows links to explore pages. This approach ensures comprehensive data extraction.
Data Extraction and Transformation: The data collected is automatically transformed into Markdown format or structured data. This makes it easy to integrate the acquired information into AI models, making it especially convenient for use in RAG.
There are two versions of Firecrawl available:
Cloud Offering: Enjoy all the features without worrying about your machine specifications, as everything is hosted in the cloud. You can start for free, but there will be charges for ongoing use.
Open Source: This option is available for free, although it has some limitations compared to the cloud version, and you will need to host it yourself or run it locally.
Prerequisites
Before you begin, please ensure you have the following ready:
Mac OS (Currently, Raycast is only available for Mac OS)
jq (It’s necessary for the script)
Running Firecrawl locally
In this guide, we use Open Source version of Firecrawl as it can be used for free.
1. Clone the repository
git clone https://github.com/mendableai/firecrawl.git
cd firecrawl
2. Configure Environment file
# Copy to root of the project
cp ./apps/api/.env.example ./.env
# Update the following:
# USE_DB_AUTHENTICATION=false
3. Run docker container
docker compose up --build -d
# You can view the logs by using this command:
docker compose logs -f
4. Check your server response
# This command initiates a crawling job for "https://docs.firecrawl.dev"
curl -X POST http://localhost:3002/v1/crawl \
-H 'Content-Type: application/json' \
-d '{
"url": "https://docs.firecrawl.dev",
"limit": 100,
"scrapeOptions": {
"formats": ["markdown", "html"]
}
}'
Create Raycast script
1. Create a directory to store your scripts
# Feel free to change the location as you wish
mkdir -p ~/.raycast/scripts # placing the Raycast script here
mkdir ~/.raycast/scripts/images # storing the script logo here (which will be displayed in the app)
2. Create Raycast script
Create a script file:
touch ~/.raycast/scripts/firecrawl-markdown.sh
Paste the following:
This script crawls websites and bundles them into markdown text. You can change the application used to open the file, with the default set to “Google Chrome”.
If you would like to use the cloud version of Firecrawl, please change the URL and provide the API key in your request. See here for more details.
#!/bin/bash
# @raycast.schemaVersion 1
# @raycast.icon images/fire.svg
# @raycast.title FireCrawl Markdown
# @raycast.mode fullOutput
# @raycast.packageName FireCrawl Markdown
# @raycast.description Crawl a website and turn it into markdown
# @raycast.author @maguroid
# @raycast.argument1 {"type": "text", "placeholder": "URL"}
# @raycast.argument2 {"type": "text", "placeholder": "Pages limit", "optional": true}
# Colors
RED='\033[0;31m'
GREEN='\033[0;32m'
YELLOW='\033[0;33m'
NC='\033[0m' # No Color
# Arguments
URL="$1"
LIMIT=${2:-100}
# Constants
FIRECRAWL_ENDPOINT="http://localhost:3002"
BROWSER="Google Chrome"
# Variables
JOB_DATA=""
JOB_ID=""
TEMP_FILE=""
# Function to execute crawl job and retrieve results
crawl_job() {
local url="$1"
local next_url
local job_response
if [ -z "$url" ]; then
echo "No URL provided"
exit 1
fi
echo -e "${GREEN}crawl_website: $url${NC}"
# Execute the crawl job
job_response=$(curl -s -X POST "$FIRECRAWL_ENDPOINT/v1/crawl" \
-H 'Content-Type: application/json' \
-d "{\"url\": \"$url\", \"limit\": $LIMIT, \"scrapeOptions\": {\"formats\": [\"markdown\"]}}")
JOB_ID=$(echo "$job_response" | jq -r '.id')
echo -e "${GREEN}job_started: $JOB_ID${NC}"
if [ -z "$JOB_ID" ]; then
echo -e "${RED}Failed to initiate crawl job${NC}"
exit 1
fi
# Get the crawl job result
while :; do
sleep 5
job_response=$(curl -s -X GET "$FIRECRAWL_ENDPOINT/v1/crawl/$JOB_ID" \
-H 'Content-Type: application/json')
status=$(echo "$job_response" | jq -r '.status')
echo -e "${YELLOW}job_status: $status${NC}"
if [ "$status" == "completed" ]; then
# Add markdown data to JOB_DATA
JOB_DATA+=$(echo "$job_response" | jq -r '.data[].markdown')
next_url=$(echo "$job_response" | jq -r '.next')
# Handle next page if available
# next_url equals null or empty string when there are no more pages
while [ -n "$next_url" ] && [ "$next_url" != null ]; do
next_url=${next_url/https/http}
echo -e "${GREEN}next_url_found: $next_url${NC}"
job_response=$(curl -s -X GET "$next_url" \
-H 'Content-Type: application/json')
JOB_DATA+=$(echo "$job_response" | jq -r '.data[].markdown')
next_url=$(echo "$job_response" | jq -r '.next')
done
break
elif [ "$status" == "failed" ]; then
echo -e "${RED}Crawl job failed${NC}"
exit 1
fi
done
}
onExit() {
curl -s -o /dev/null -X DELETE "$FIRECRAWL_ENDPOINT/v1/crawl/$JOB_ID"
echo -e "${GREEN}Crawl job deleted${NC}"
if [ -n "$TEMP_FILE" ]; then
rm -f "$TEMP_FILE"
echo -e "${GREEN}Deleted temp file: $TEMP_FILE${NC}"
fi
}
onInterrupt() {
curl -s -o /dev/null -X DELETE "$FIRECRAWL_ENDPOINT/v1/crawl/$JOB_ID"
echo -e "${GREEN}Crawl job deleted${NC}"
exit 1
}
trap 'onInterrupt' INT # Ctrl+C from Raycast cannot be trapped
trap 'onExit' EXIT
# Start the crawl job
crawl_job "$URL"
# Open the result in browser
if [ -n "$JOB_DATA" ]; then
temp_dir=$(mktemp -d)
TEMP_FILE="$temp_dir/firecrawl-markdown.md"
echo "$JOB_DATA" >"$TEMP_FILE"
echo -e "${GREEN}Created temp file: $TEMP_FILE${NC}"
open -a "$BROWSER" "file://$TEMP_FILE"
# Wait for the browser to open the file not to delete the temp file
sleep 5
else
echo -e "${RED}No markdown data found${NC}"
fi
3. Register script location
Open the settings in Raycast (⌘,), then add the directory. You can set up a hotkey to use the script (⌃⌥F in my case)
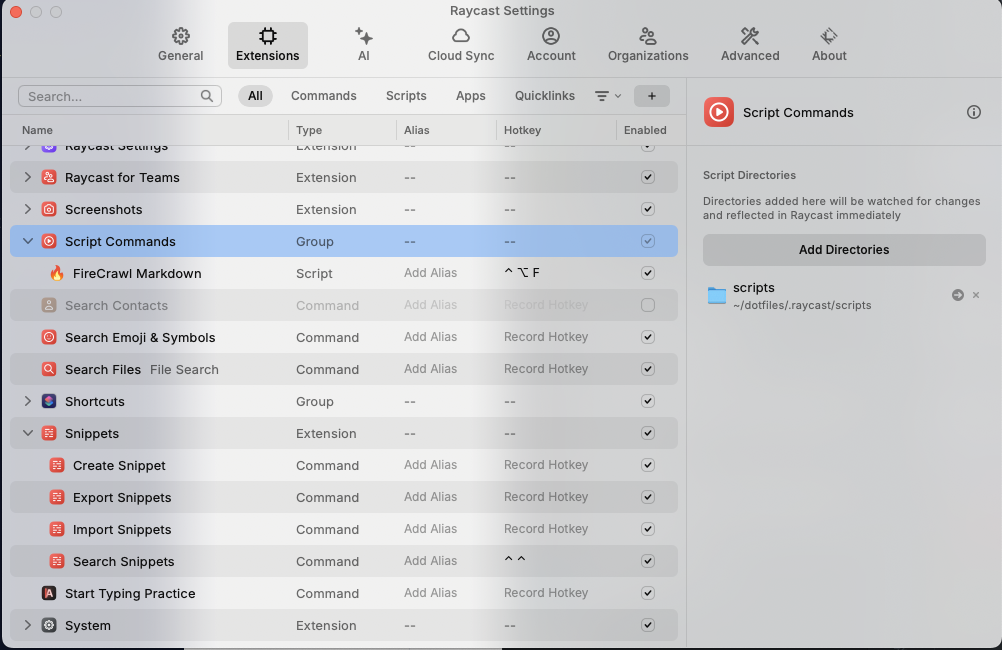
Run the script from Raycast
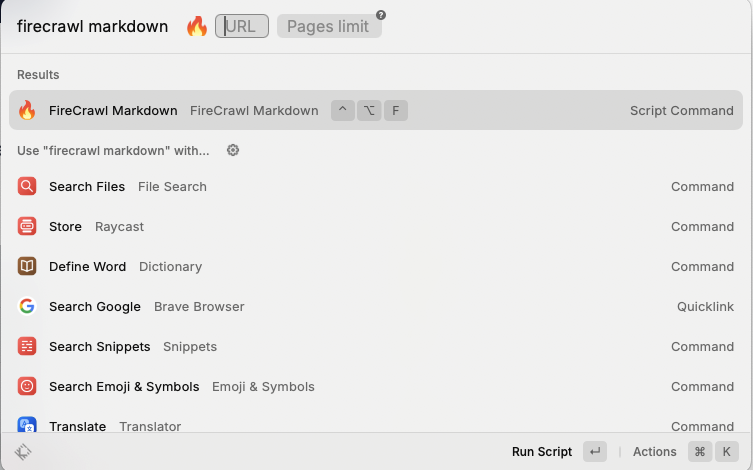
You're almost there! Now it's time to run the crawling script. Just enter the shortcut or type the script name in the box.
The first argument is the website URL you wish to crawl. The second optional argument is the maximum number of pages to crawl, which is set to a default of 100.
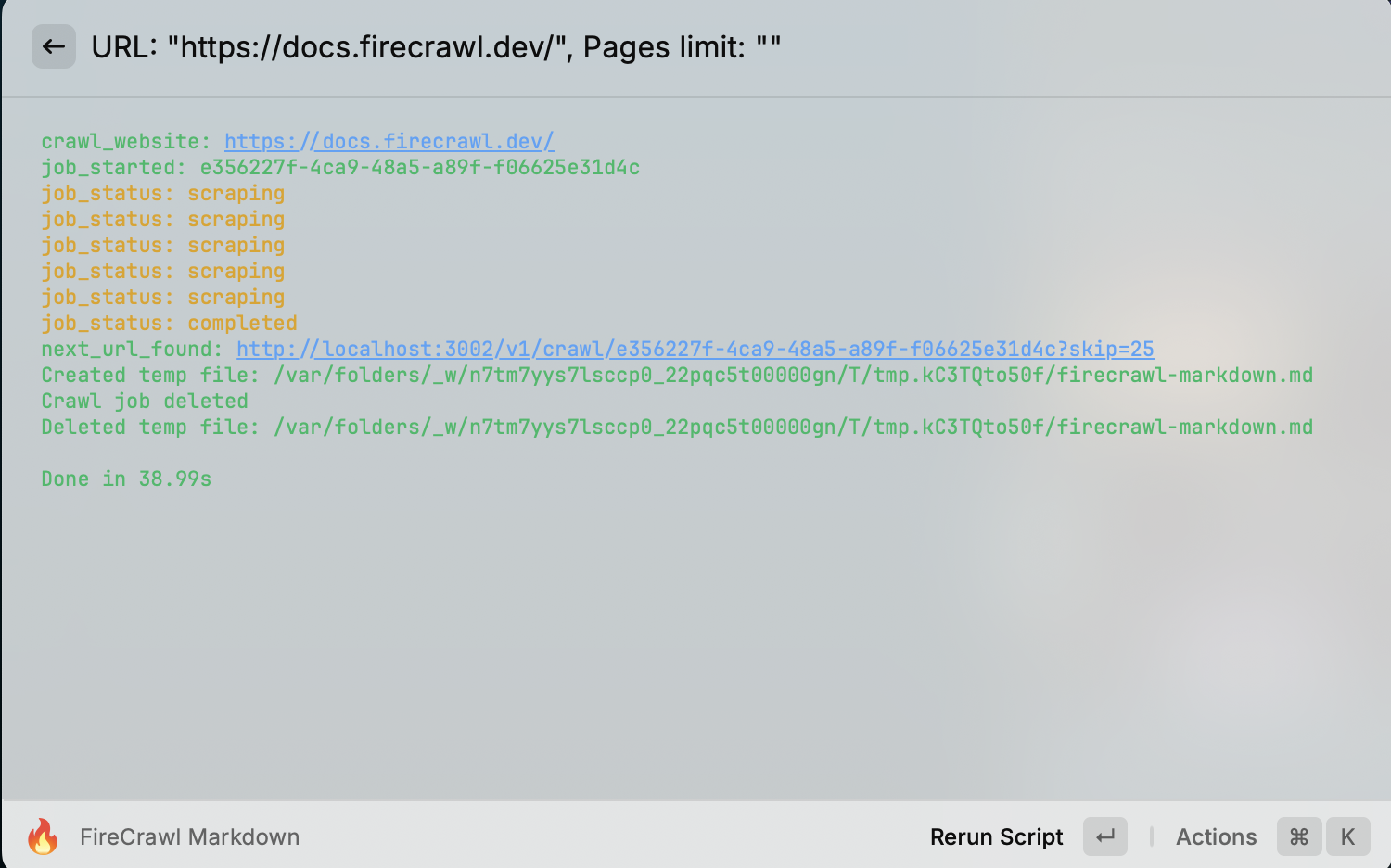
Once the execution is complete, the extracted document will appear in the browser.

Conclusion
In this guide, we’ve delved into how to utilize Raycast and Firecrawl to efficiently crawl websites and transform the data into markdown format, which is perfect for large language models (LLMs). By following the steps outlined, you can effortlessly set up Firecrawl locally using Docker, create a custom Raycast script, and automate the crawling process. This method streamlines data collection for AI model training and boosts productivity by seamlessly integrating these tools into your workflow. Whether you opt for the open-source or cloud version of Firecrawl, this solution provides flexibility and efficiency for all your web data extraction needs.
Subscribe to my newsletter
Read articles from maguro directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by