23ai Vector / Semantic Search in APEX
 Jon Dixon
Jon Dixon
Introduction
With the introduction of Oracle Database 23ai, AI Vector Search or Semantic search is now within easy reach of all APEX developers. This provides more options for improving search and a mechanism to perform the first step of RAG (Retrieval Augmented Generation) without reaching outside the database.
This post will focus on setting up a Vector/Semantic search using Oracle DB 23ai and APEX. I will illustrate the steps using blog posts from my APEX Developer Blogs site.
In my next post, I will elaborate and show you how to use the Vector Search results to improve results from LLM-based questions using Retrieval Augmented Generation or RAG.
Terms
Before getting into the details, I need to define some terms that will be used throughout this post.
Semantic Search
Semantic search is a technique that uses natural language processing to understand the intent and contextual meaning behind search queries, rather than just matching keywords. It aims to improve search accuracy by analyzing the relationships between words and concepts. This allows for more relevant results, even if the exact keywords aren't used.
Vector Search
Vector search is a method that retrieves information by representing data (like text, images, or audio) as high-dimensional vectors in a continuous space. It uses mathematical models to capture the semantic relationships between data points, enabling similarity-based searches. This allows for more nuanced and accurate results, especially in cases where traditional keyword-based methods fall short.
How is Semantic Search Related to Vector Search?
Vector search and semantic search are closely related because both aim to improve the accuracy of information retrieval by understanding the meaning behind data rather than relying on exact keyword matches. In semantic search, vector representations (embeddings) of words, sentences, or documents are often created to capture the relationships and contextual meaning between them. Vector search leverages these embeddings by comparing their positions in a multi-dimensional space, enabling searches based on semantic similarity, which powers more accurate and context-aware results. Essentially, vector search provides the underlying mechanism that enables semantic search to function effectively.
Embeddings
An embedding is a way of turning information, like words or images, into numbers that a computer can understand. Think of it as translating complex data into coordinates in a big, multi-dimensional space, where similar things are placed closer together, and different things are farther apart. This helps computers find patterns and relationships between the data, even if it’s not exactly the same, like knowing that “cat” and “kitten” are related even though they’re different words.
Preparation
The first thing we need to do is ‘vectorize’ our dataset. This involves breaking our data into manageable chunks and turning these chunks into vectors. Once we have a vector for a given chunk of text, we need to store it in a way that allows us to relate it to the original data.
We need to use an LLM to create a vector from a chunk of text. We could use a REST API, like the Embeddings API from Open AI, to generate embeddings, but the goal is to stay inside the database. The good news is that we can import a pre-built embedding generation model (Hugging Face's all-MiniLM-L12-v2 model) inside Oracle DB 23ai.
To import this pre-built Onyx model into your database, follow the ‘Load the augmented model to Oracle Autonomous Database’ section in this post.
Once you have done this, you have everything you need to do a vector search in your database.
Creating Chunks
Data Model
I have simplified the APEX Developer Blogs data model to one table to simplify the use case as much as possible.

The goal is to perform a semantic search on the plain_content column containing the blog post's content.
What is Chunking
One of the most essential steps in the embedding process is determining how to break up the content of the blog posts into manageable chunks.
Instead of turning an entire blog into one vector, it is better to split it into smaller “chunks” so that each part can be represented individually as a vector. This allows for more precise searching and analysis, as each chunk captures a specific idea or piece of content, making it easier to find relevant information within large amounts of data.
Embeddings Table
Before we break our blog posts into chunks, we need somewhere to store them. Let’s expand our simple data model to include a table cnba_post_chunks to store these chunks.
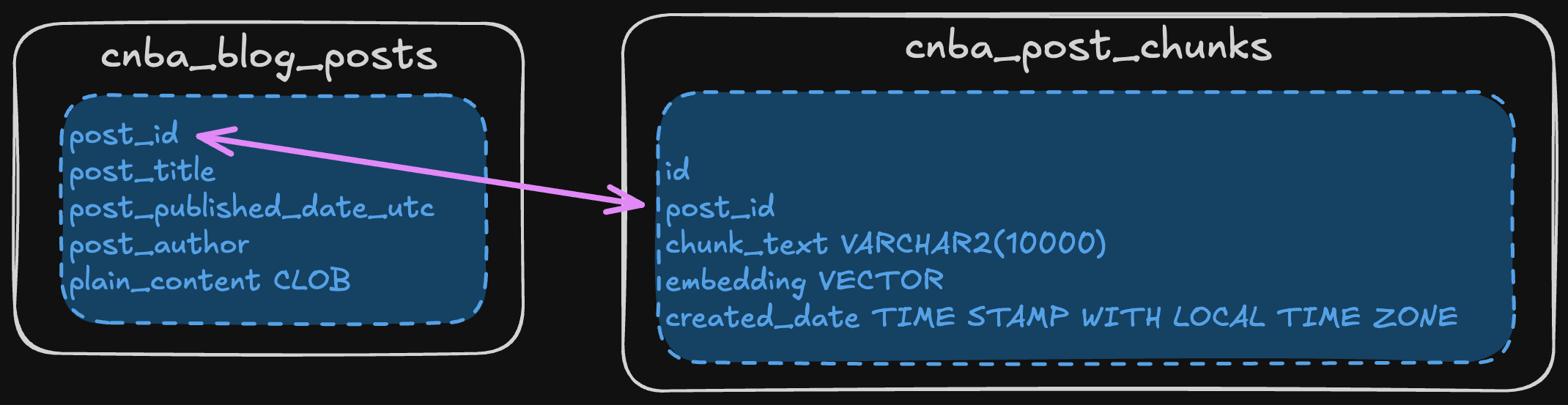
The cnba_post_chunks table will store the generated vectors and the chunks of text the vector represents.
Overall Process
The diagram below shows the high-level process for turning content (in this case, blog posts) into Embedded Elements and Vectors that can be used for Vector Search.
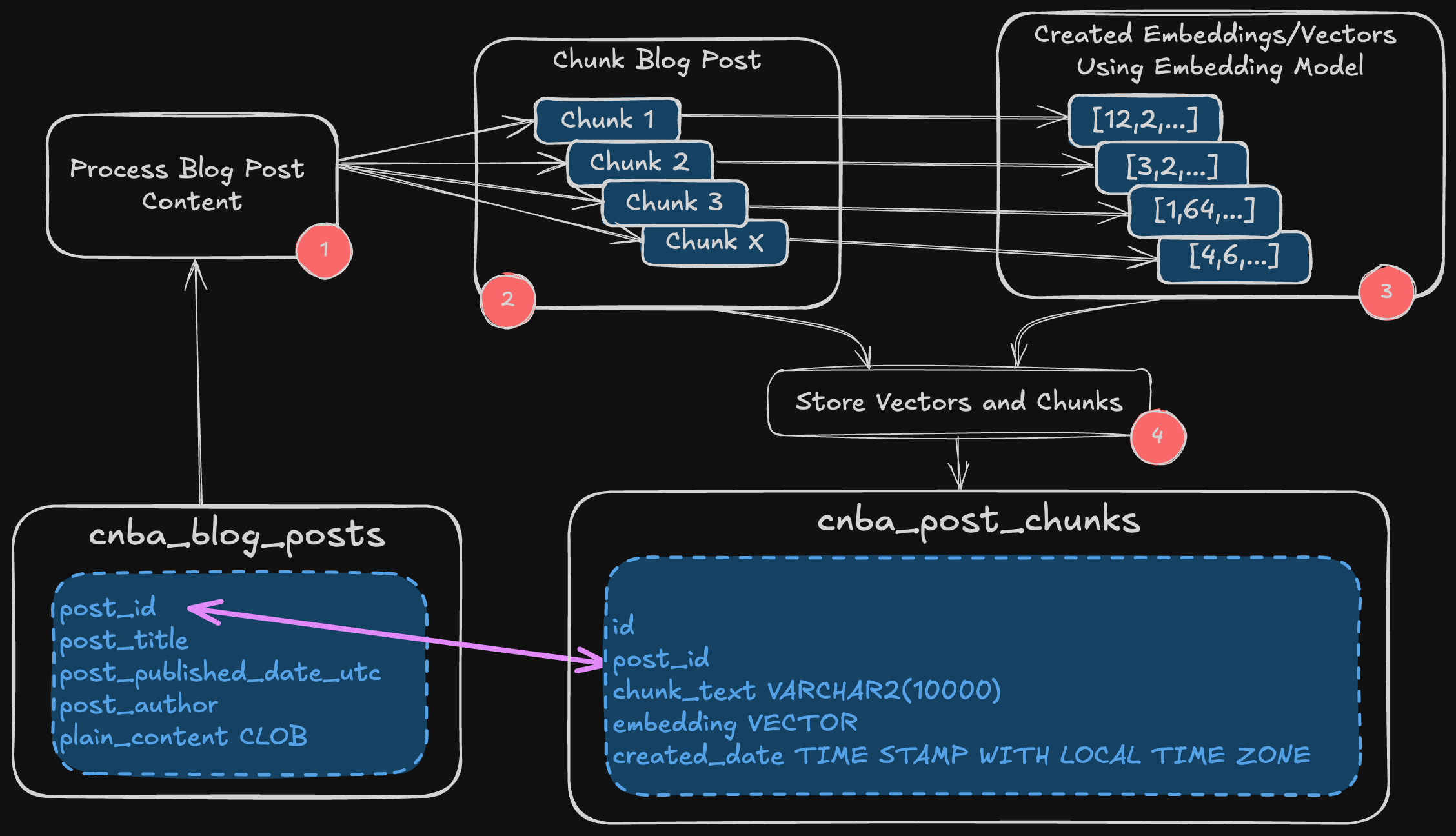
Take a specific blog post.
Convert the CLOB content of the Blog Post into manageable chunks of text.
Convert each text chunk into a Vector.
Store the text chunk and vector in a table with a link to the source blog.
How Do We Chunk?
We can use the 23ai VECTOR_CHUNKS function to turn our post content into chunked records. However, some decisions must be made before we use this function.
How Much Should Be in Each Chunk (MAX Value)
Finding this value requires some trial and error using your data set. The VECTOR_CHUNKS API has the following options to control chunk size:
CHARACTERS: The simplest method is to break each chunk into X characters. However, as these chunks break across words, we will lose some of the semantic meaning we seek.WORDS: We can break our chunks into X words with this approach. This helps us with semantic meaning but makes the size of each chunk more variable.VOCABULARYTokens: The final option is to break chunks into ‘vocabulary tokens’. I have not investigated this in detail, so I will not cover this approach in this post.
Decision: 200 WORDS
Overlap
We can also overlap our chunks. This takes the last X% of the previous chunk and adds it to the start of the next chunk, helping maintain context across chunks.
Decision: Overlap 10%.
Where to Split Chunks
The final decision is determining which character(s) should be used to split each chunk. Periods or line feeds would be the obvious choice for content focused on the written word.
NONE: Split when you reach the number of words or characters.NEWLINE, BLANKLINE, and SPACE: These are single-split character conditions that split at the last split character before the MAX value.RECURSIVELY: This is a multiple-split character condition that breaks the input text using an ordered list of characters (or sequences).RECURSIVELYis predefined asBLANKLINE,NEWLINE,SPACE,NONEin this order:1. If the input text exceeds the
MAXvalue, split by the first split character.2. If that fails, then split by the second split character.
3. And so on.
4. If no split characters exist, then split by
MAXwherever it appears in the text.
SENTENCE: This end-of-sentence split condition breaks the input text at a sentence boundary. This condition automatically determines sentence boundaries using knowledge of the input language's sentence punctuation and contextual rules.CUSTOM: Splits based on a custom split characters list. You can provide custom sequences up to a limit of 16 split character strings, with a maximum length of 10 each.
Decision: RECURSIVELY
Normalize Text During Chunking
Normalizing automatically pre-processes or post-processes issues (such as multiple consecutive spaces and smart quotes) that may arise when documents are converted into text. Normalization options include:
NONE: Specifies no normalization.ALL: Normalizes common multi-byte (Unicode) punctuation to standard single-byte.PUNCTUATION: Includes the smart quotes, smart hyphens, and other multi-byte equivalents to simple single-byte punctuation.WHITESPACE: Minimizes whitespace by eliminating unnecessary characters.For example, retain blanklines, but remove any extra newlines and interspersed spaces or tabs:
" \n \n " => "\n\n"WIDECHAR: Normalizes wide, multi-byte digits and (a-z) letters to single-byte.These are multi-byte equivalents for
0-9anda-z A-Z, which can show up inZH/JAformatted text.
Decision: ALL
Note: This decision is grounded in ignorance. I could not find any examples of the other options, such as PUNCTUATION, WHITESPACE, or WIDECHAR.
Let’s Chunk
Let’s turn these decisions into an SQL statement to extract chunks for a specific blog post using the VECTOR_CHUNKS function:
SELECT cnk.chunk_text
FROM cnba_blog_posts cbp
, VECTOR_CHUNKS (REGEXP_REPLACE(cbp.plain_content,
'[^]0-z[!"#$%{|}~óíáú' ||
chr(58) || chr(38) ||
chr(39) || chr(13) ||
chr(10) || ' ()*+,-./]', '*')
BY WORDS MAX 200 OVERLAP 10 SPLIT BY RECURSIVELY
LANGUAGE american NORMALIZE all) cnk
WHERE post_id = 8190;
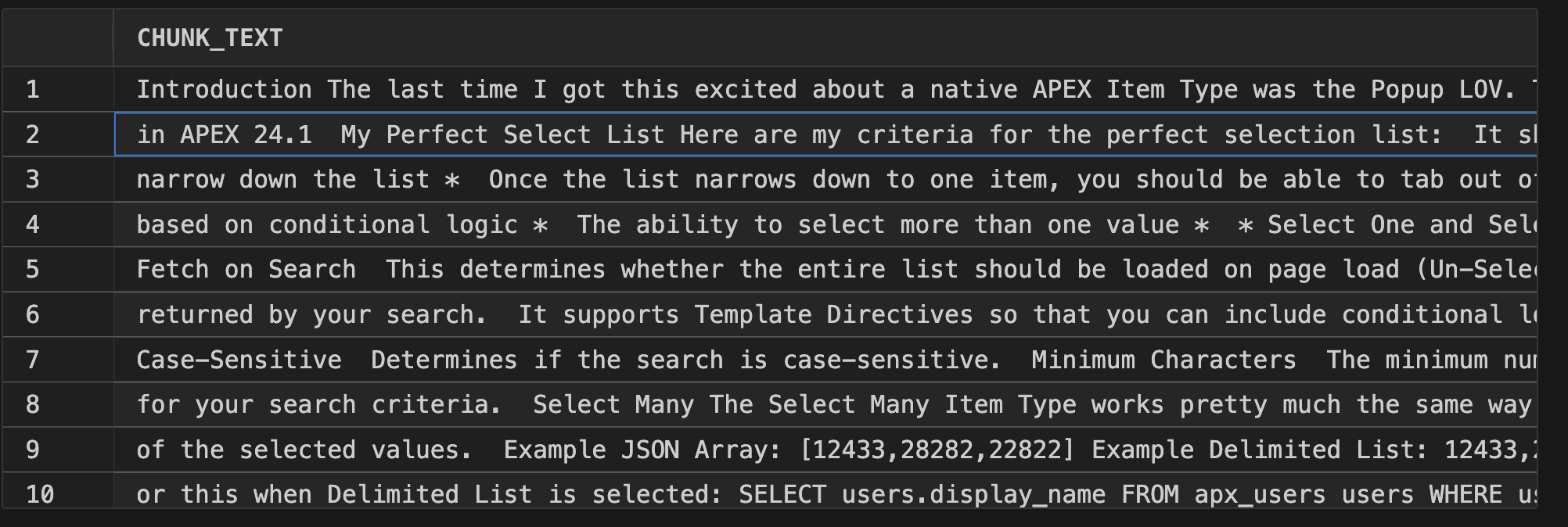
REGEXP_REPLACE is doing. Unfortunately, the VECTOR_CHUNKS function does not handle multi-byte characters. Whenever a post contained multi-byte characters, I would get the error “ORA-22831: Offset or offset+amount does not land on character boundary”. Despite spending 30 minutes with Chat GPT, I could not come up with anything more elegant than this REGEX to replace multi-byte characters with a ‘*’. I would welcome feedback if anyone has a better approach for removing multi-byte characters or a more elegant REGEX.In the results, you can see how the function broke this blog post into ten chunks:
Chunking Other Content
Oracle has made it easy to generate chunks from many different file types. The SQL below uses dbms_vector_chain.utl_to_text to generate chucks for the PDF version of the APEX 24.1 API guide.
INSERT INTO cn_document_chunks (doc_id, line_Number, chunk_text)
SELECT 1, rownum, chunk_text
FROM VECTOR_CHUNKS
(dbms_vector_chain.utl_to_text
(data => apex_web_service.make_rest_request_b
(p_url => 'https://docs.oracle.com/en/cloud/saas/subscription-management/fasim/implementing-subscription-management.pdf',
p_http_method => 'GET'))
BY words MAX 150 OVERLAP 10 SPLIT BY SENTENCE LANGUAGE american NORMALIZE all);
Creating Embeddings
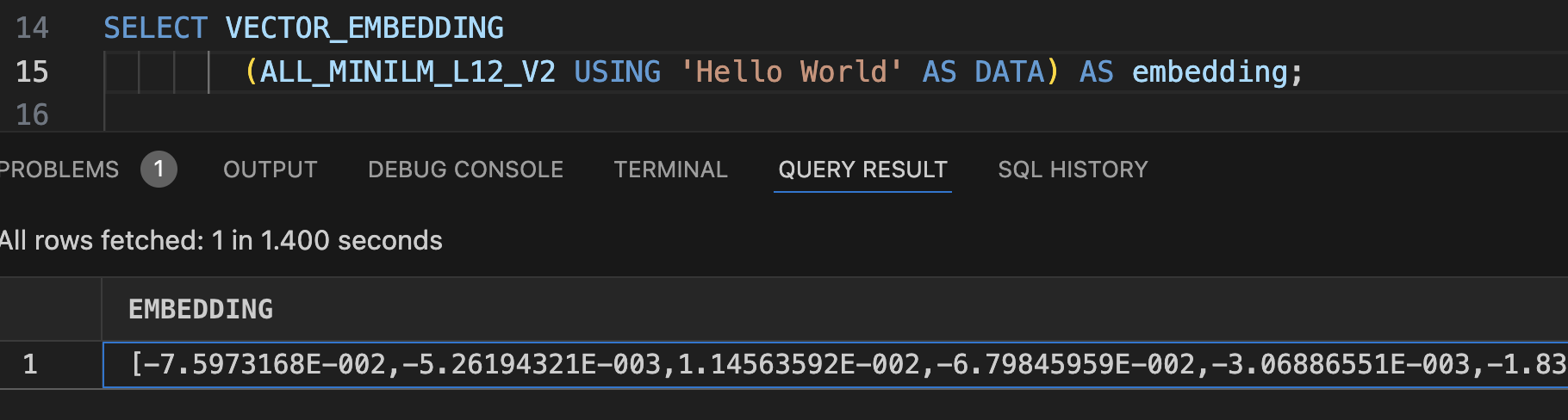
Now that we have manageable chunks, we must create vectors for them using the 23ai VECOR_EMBEDDING function. In its simplest form, you can create a vector using the following SQL:
SELECT VECTOR_EMBEDDING
(ALL_MINILM_L12_V2 USING 'Hello World' AS DATA) AS embedding;
The model name ‘ALL_MINILM_L12_V2’ is the name of the model loaded from this post.
We can now put the VECTOR_CHUNKS and VECTOR_EMBEDDING functions together to create a single INSERT statement that will split all blog posts into chunks and create vectors for each chunk:
INSERT INTO CNBA_POST_CHUNKS (post_id, chunk_text, embedding)
SELECT cbp.post_id
, cnk.chunk_text
, VECTOR_EMBEDDING
(ALL_MINILM_L12_V2 USING cnk.chunk_text AS DATA) AS embedding
FROM cnba_blog_posts cbp
, VECTOR_CHUNKS (REGEXP_REPLACE(cbp.plain_content,
'[^]0-z[!"#$%{|}~óíáú' || chr(58) ||
chr(38) || chr(39) || chr(13) ||
chr(10) || ' ()*+,-./]', '*')
BY WORDS MAX 200 OVERLAP 10 SPLIT BY RECURSIVELY
LANGUAGE american NORMALIZE ALL) cnk;
-- Again, my sincere apologies for the REGEXP_REPLACE. 😕
Note: The VECTOR_EMBEDDING function only supports VARCHAR2 text.
Note: The model determines the number of dimensions in the returned vector. The all-MiniLM-L12-v2 model loaded earlier in this post has 384 dimensions.
Performance
The INSERT statement above took about 10 minutes to chunk and embed 2,500 blog posts on an Always Free ATP instance. I am sure some of this was due to my hacky removal of multi-byte characters.
Semantic Search
Now that we have created embeddings/vectors for the chunked blog posts, we can focus on querying the posts using Vector/Semantic Search.
The foundation for Vector Search is the 23ai VECTOR_DISTANCE function. This function takes two vectors and returns the distance between them.
To perform a vector search, we must convert the search term into a vector to compare it with the vectors in the blog chunks table.
Query 1 Basic ‘Exact’ Search
SELECT ROUND(vector_distance,2) AS dist
, post_title
, chunk_text
, post_id
FROM (SELECT cbp.post_title
, vector_distance
(cbc.embedding,
vector_embedding
(ALL_MINILM_L12_V2 USING 'background page process' AS DATA),
COSINE) AS vector_distance
, cbc.chunk_text
, cbp.post_id
FROM cnba_post_chunks cbc
, cnba_blog_posts cbp
WHERE cbp.post_id = cbc.post_id)
ORDER BY vector_distance
FETCH EXACT FIRST 10 ROWS ONLY
Comments about the above query:
The query takes the search text 'background page process', converts it to a vector, and then uses the
vector_distancefunction to measure the distance between the vectorized search term and all vectors in cnba_post_chunks.The third parameter for vector_distance is the metric. In the above example, I am using
COSINE, the default metric. Other options for metric are:DOTor inner product, calculates the negated dot product of two vectors.EUCLIDEANorL2_DISTANCE, calculates the Euclidean distance between two vectors.EUCLIDEAN_SQUAREDorL2_SQUAREDis the Euclidean distance without taking the square root.HAMMINGcalculates the hamming distance between two vectors.MANHATTANorL1_DISTANCEcalculates the Manhattan distance.
The query sorts the results so the lowest values appear first. For the cosine metric, the closer the values are to each other, the lower the value returned by the
vector_distancefunction.The query fetches the first ten rows of the result.
Query 1 Result
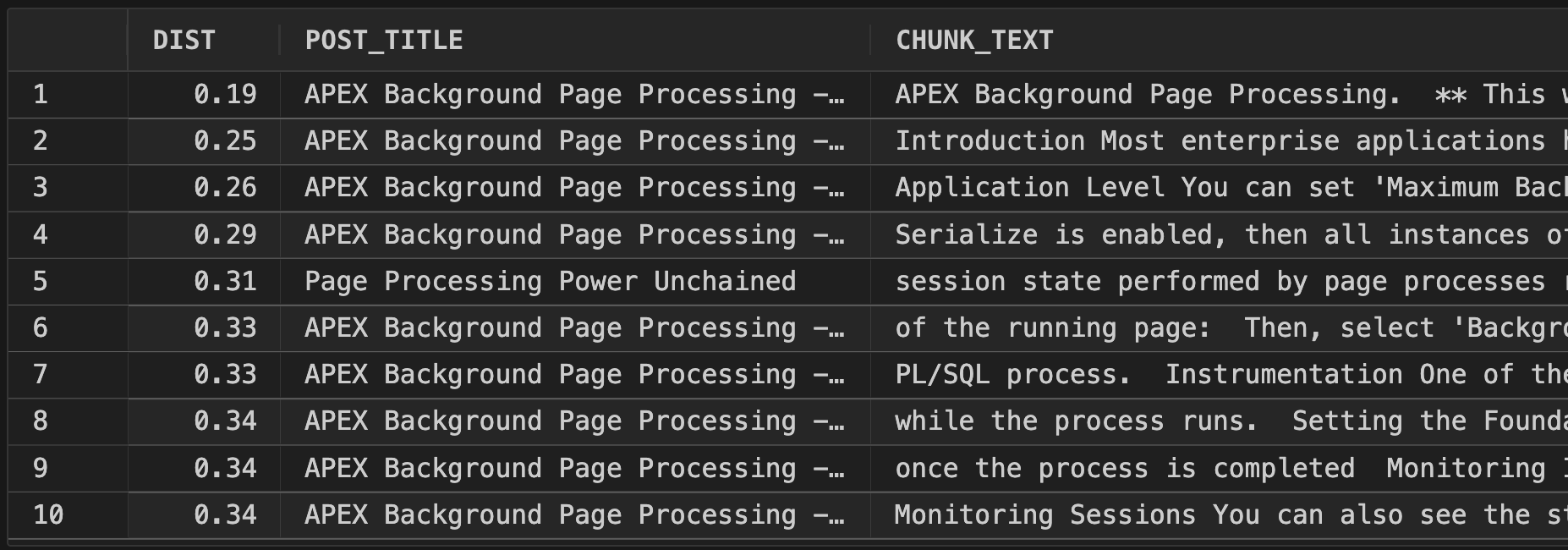
We can see that we got several results from chunks in the same blog post. This makes sense because that blog post was all about background page processing. What if we wanted more variety in our responses?
Query 2 Partioned ‘Exact’ Search
SELECT ROUND(vector_distance,2) AS dist
, post_title
, chunk_text
, post_id
FROM (SELECT cbp.post_title
, vector_distance
(cbc.embedding,
vector_embedding
(ALL_MINILM_L12_V2 USING 'background page process' AS DATA),
COSINE) AS vector_distance
, cbc.chunk_text
, cbp.post_id
FROM cnba_post_chunks cbc
, cnba_blog_posts cbp
WHERE cbp.post_id = cbc.post_id)
ORDER BY vector_distance
FETCH EXACT FIRST 10 PARTITIONS BY post_id, 1 ROWS ONLY
The difference between this query and query 1 is the FETCH clause. We are still asking Oracle to fetch ten rows but only return one row for each post_id.
Query 2 Result
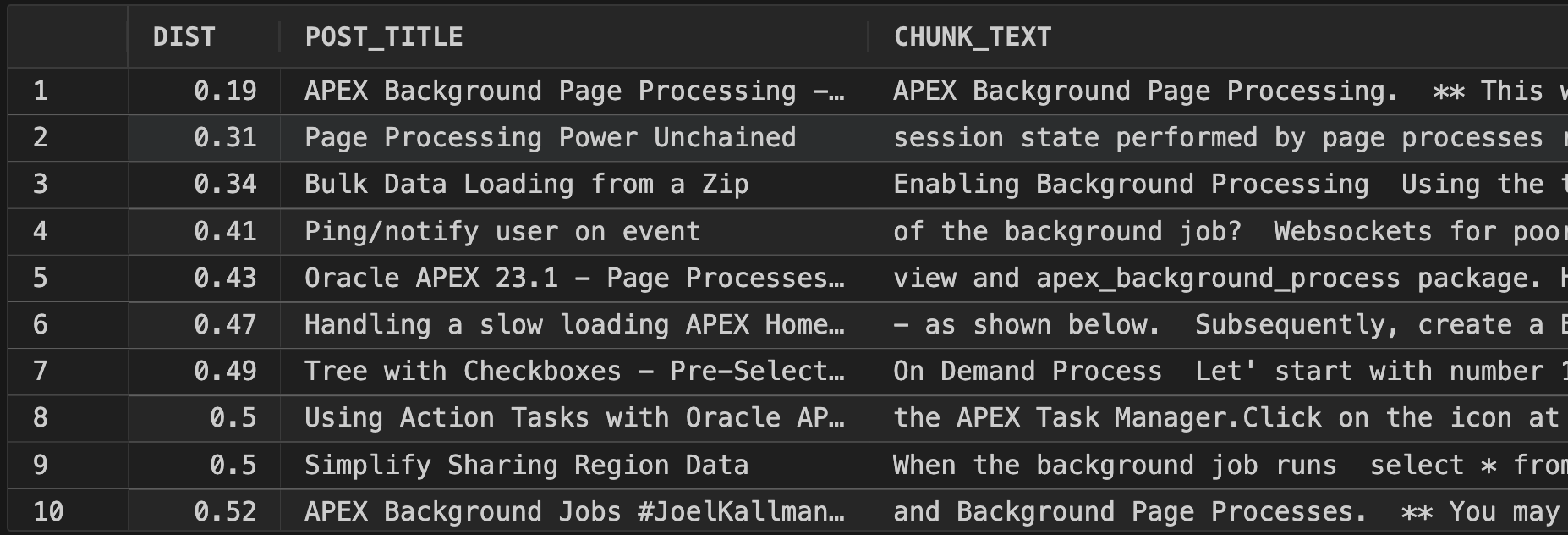
We now have just one chunk from each post. Overall, the distance scores are worse because many of the chunks are not as relevant.
Query 3 Focus the Search
Because our chunked table is related to the blog posts table, we can filter the blogs we consider in the search, thus limiting the scope of the vector search and providing users with more relevant data.
SELECT ROUND(vector_distance,2) AS dist
, post_title
, chunk_text
, post_id
FROM (SELECT cbp.post_title
, vector_distance
(cbc.embedding,
vector_embedding
(ALL_MINILM_L12_V2 USING 'background page process' AS DATA),
COSINE) AS vector_distance
, cbc.chunk_text
, cbp.post_id
FROM cnba_post_chunks cbc
, cnba_blog_posts cbp
WHERE cbp.post_id = cbc.post_id
AND cbp.post_published_date_utc >=
ADD_MONTHS(SYSDATE, -12))
ORDER BY vector_distance
FETCH EXACT FIRST 10 PARTITIONS BY post_id, 1 ROWS ONLY;
Query 3 Result
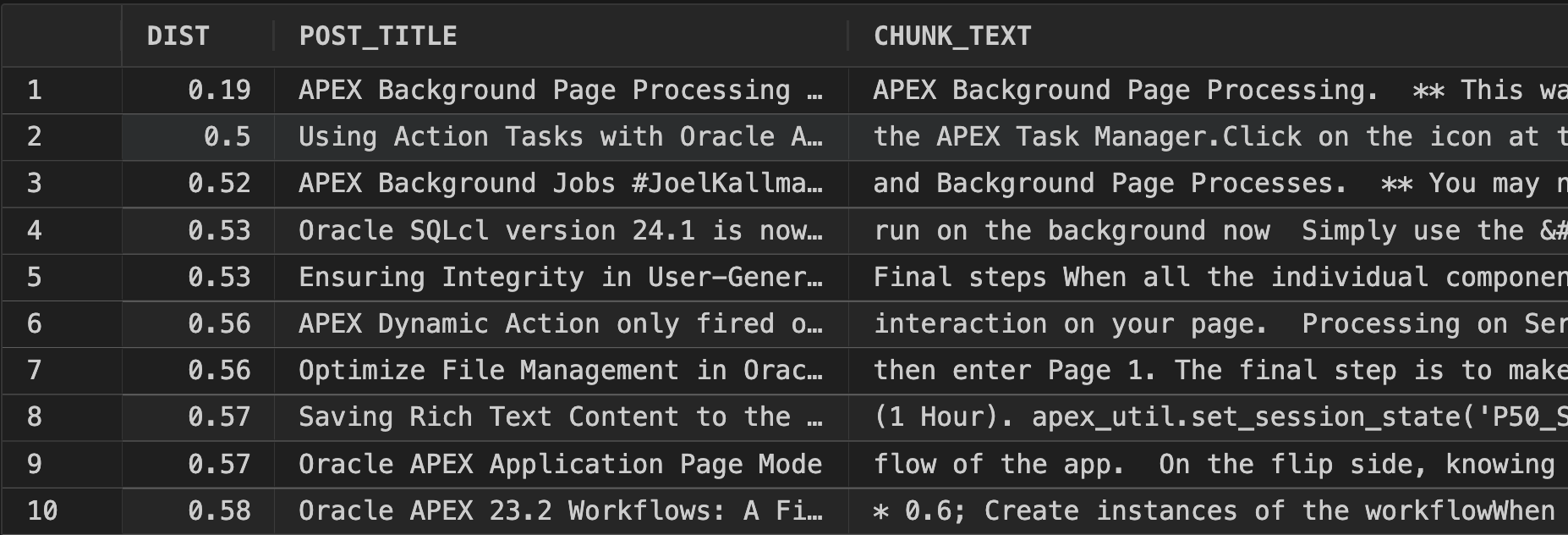
Of course, this is SQL, so we can do anything we like to filter the data set on which we want to perform the vector search.
Query 4 Vector Index and Approximate Search
You can implement approximate similarity search using vector indexes to achieve faster search speeds in large vector spaces.
Creating a Vector Index
The below statement creates an In Memory Vector Index with a target accuracy of 90%
CREATE VECTOR INDEX cnba_post_chunks_v1 ON cnba_post_chunks (embedding)
ORGANIZATION INMEMORY NEIGHBOR GRAPH
DISTANCE COSINE
WITH TARGET ACCURACY 90;
Using a Vector Index
We can then use the APPROX clause along with TARGET ACCURACY to query blogs using the vector index. Note: In the below query, I am overriding the target accuracy from the index (90%) with a target accuracy of 80%.
The documentation does an excellent job of explaining approximate similarity searches using vector indexes.
WITH vs AS
(SELECT cbp.post_title
, vector_distance
(cbc.embedding,
vector_embedding
(ALL_MINILM_L12_V2 USING 'background page process' AS DATA),
COSINE) AS vector_distance
, cbc.chunk_text
, cbp.post_id
FROM cnba_post_chunks cbc
, cnba_blog_posts cbp
WHERE cbp.post_id = cbc.post_id)
SELECT ROUND(vector_distance,2) AS dist
, post_title
, chunk_text
, post_id
FROM vs
ORDER BY vector_distance
FETCH APPROX FIRST 10 ROWS ONLY WITH TARGET ACCURACY 80;
Here is the SQL explain plan showing the use of the Vector Index:
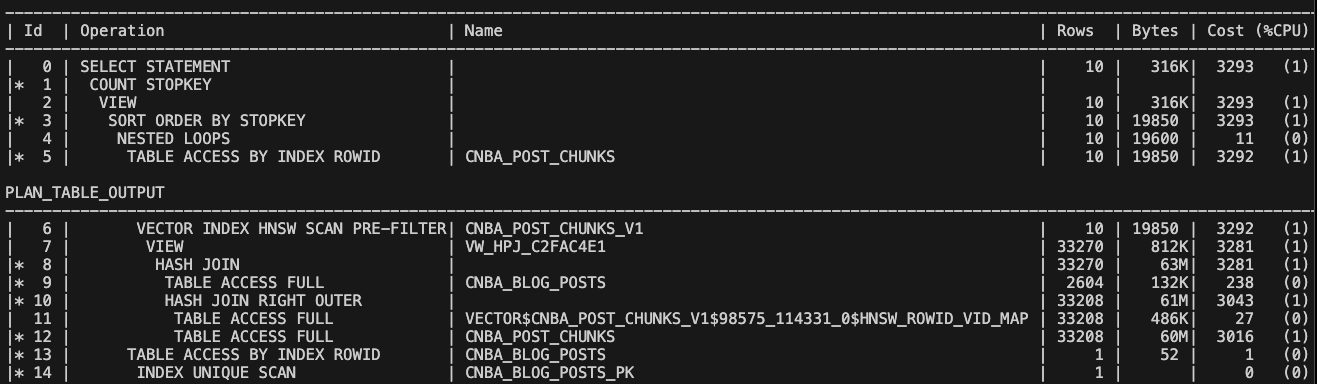
You can use the below query to see how much memory your Memory based Vector Indexes consume:
-- Run as priveledged user e.g. ADMIN on OCI.
SELECT con_id
, pool
, apex_string_util.to_display_filesize(alloc_bytes) allocated
, apex_string_util.to_display_filesize(used_bytes) used
FROM v$vector_memory_pool
ORDER BY 1,2;
Adding Vector Search to APEX
APEX Application Search
Unfortunately, APEX Application Search does not support Vector Search queries. In the search configuration, you must select at least one ‘Searchable Column’, which means any search you define will filter on that column, which is not what we want.
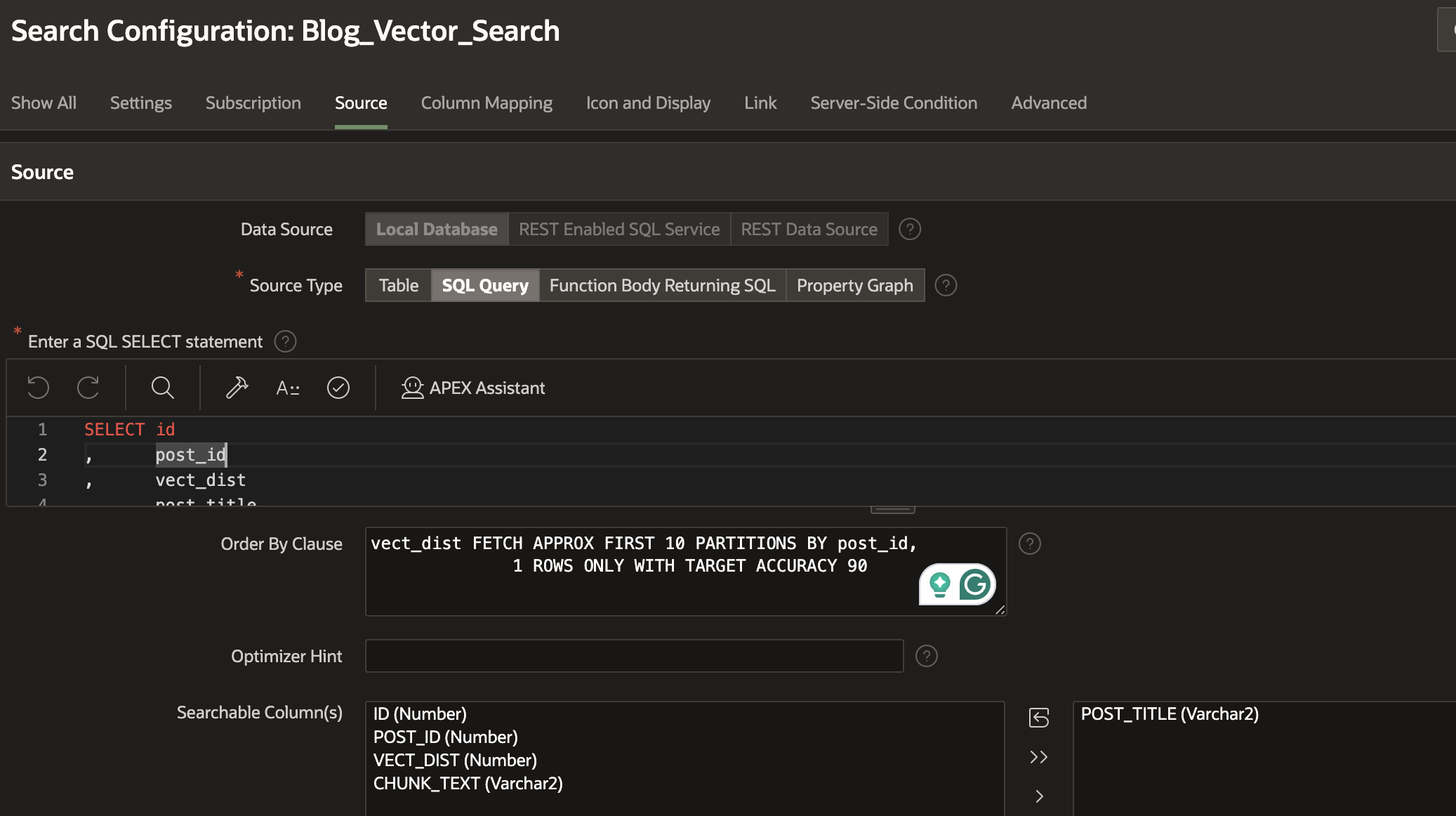
Alternate Approach
In reality, we have done the hard part; implementing Vector Search in APEX is just a matter of choosing a Region Type and utilizing the queries we worked on earlier in this post. The approach I used was to use a ‘Content Row’ Region type:
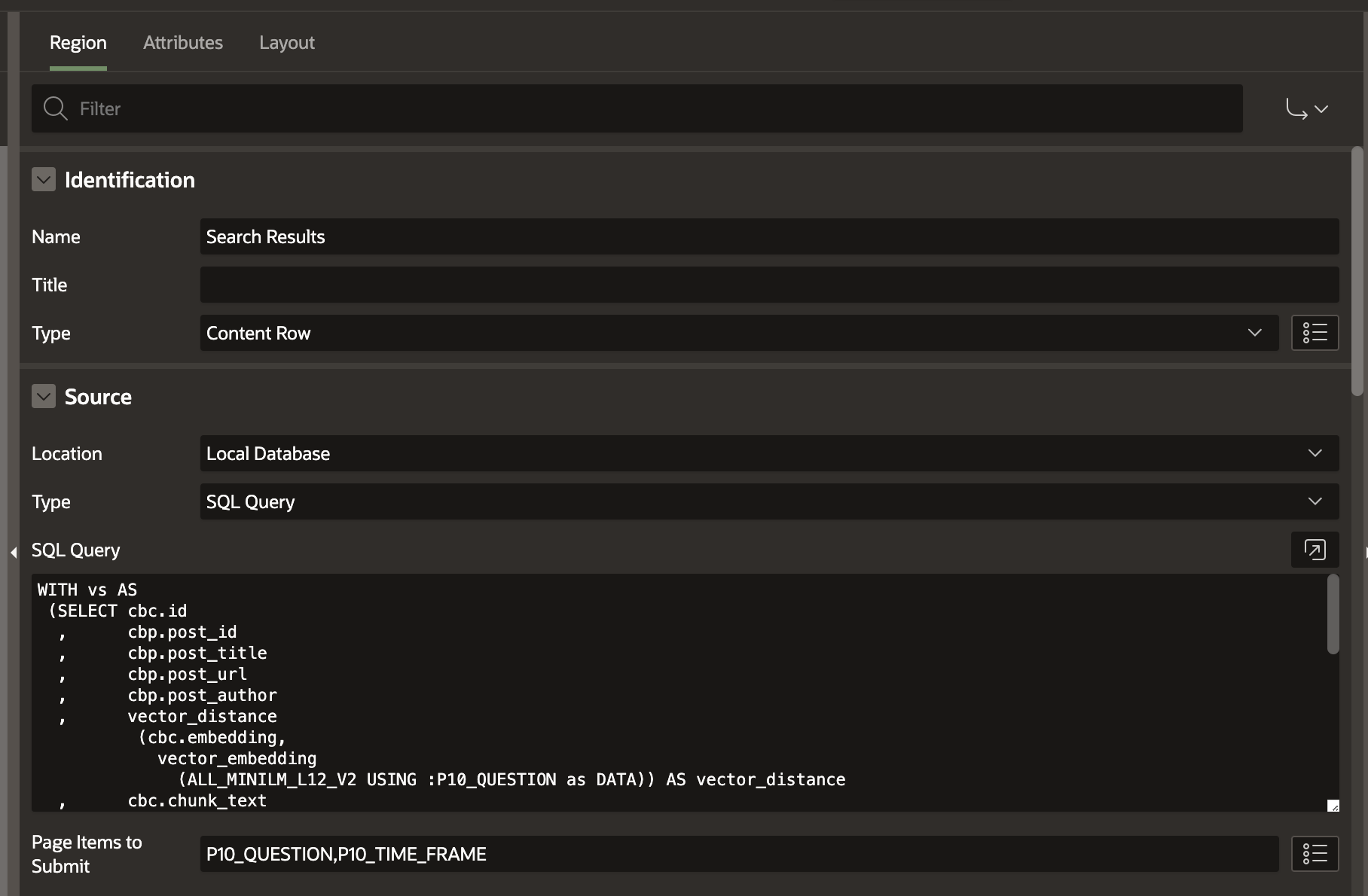
The complete SQL query looks like this:
WITH vs AS
(SELECT cbc.id
, cbp.post_id
, cbp.post_title
, cbp.post_url
, cbp.post_author
, vector_distance
(cbc.embedding,
vector_embedding
(ALL_MINILM_L12_V2 USING :P10_QUESTION as DATA)) AS vector_distance
, cbc.chunk_text
FROM cnba_post_chunks cbc
, cnba_blog_posts cbp
WHERE cbp.post_id = cbc.post_id
AND :P10_QUESTION IS NOT NULL
-- Utilize business data to limit the search.
AND cbp.post_published_date_utc > (ADD_MONTHS(CURRENT_DATE, (-1* :P10_TIME_FRAME))))
SELECT id
, post_id
-- Here I am converting the Cosine Distance (number between 0 an 1)
-- to a Percentage to make it easier for the end-user to understand.
, ROUND((1 - TO_NUMBER(vector_distance)) * 100) AS vect_dist_pct
, CASE
WHEN ROUND((1 - TO_NUMBER(vector_distance)) * 100) >=65 THEN 'success'
WHEN ROUND((1 - TO_NUMBER(vector_distance)) * 100) >=50 THEN 'info'
ELSE 'warning'
END badge_state
, post_title
, chunk_text
, post_url
, post_author
FROM vs
ORDER BY vector_distance
FETCH EXACT FIRST 15 PARTITIONS BY post_id, 1 ROWS ONLY
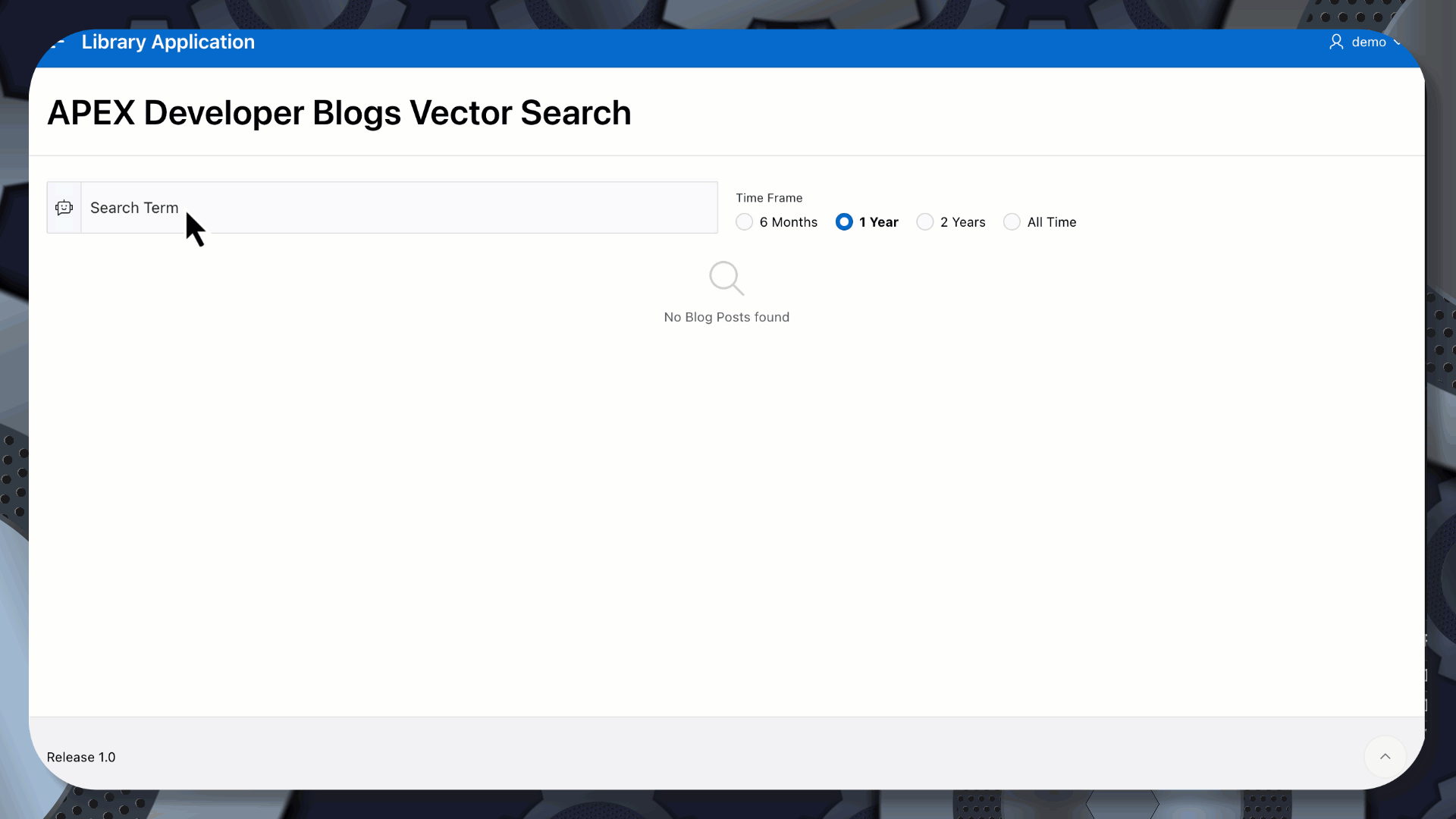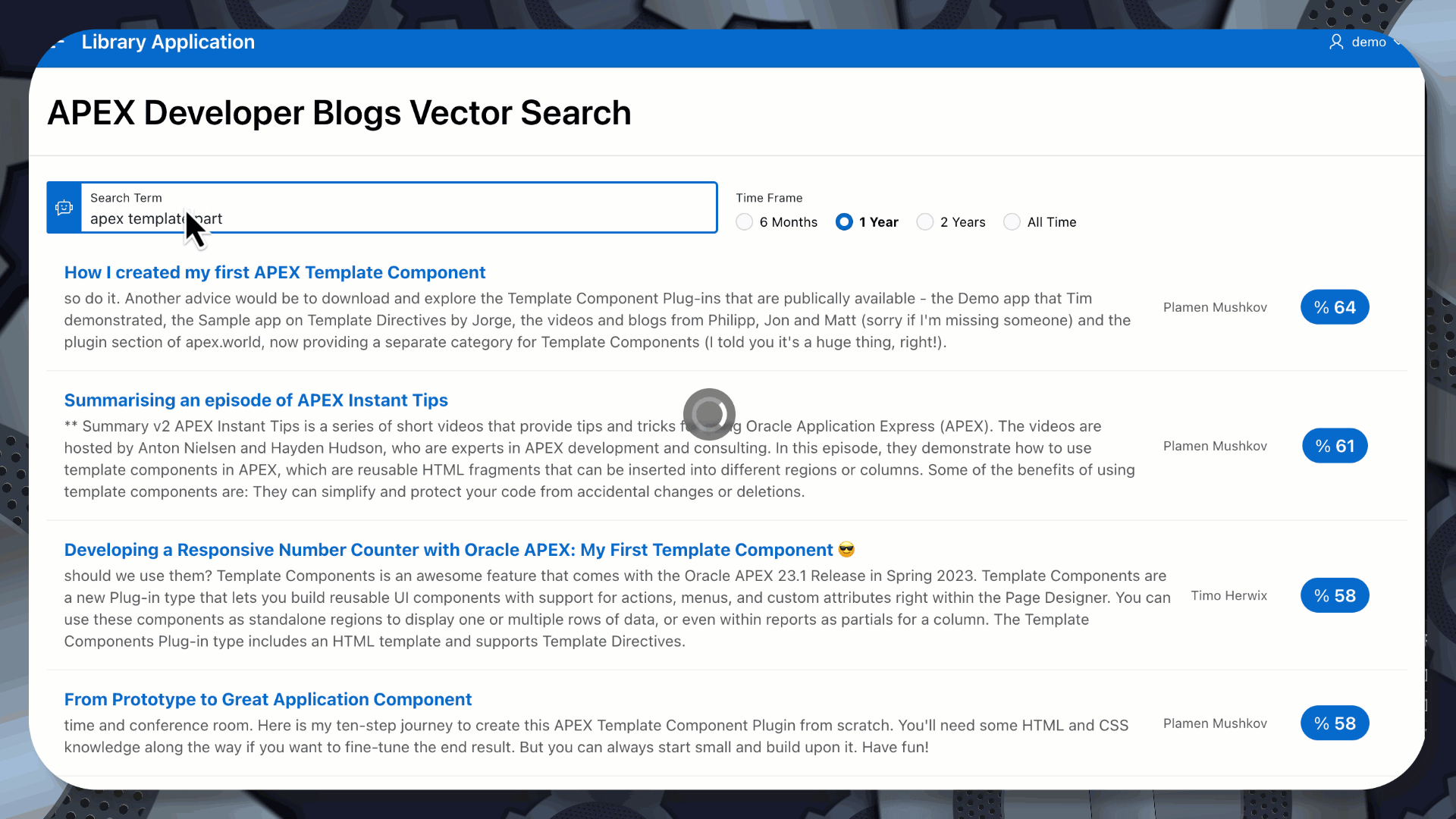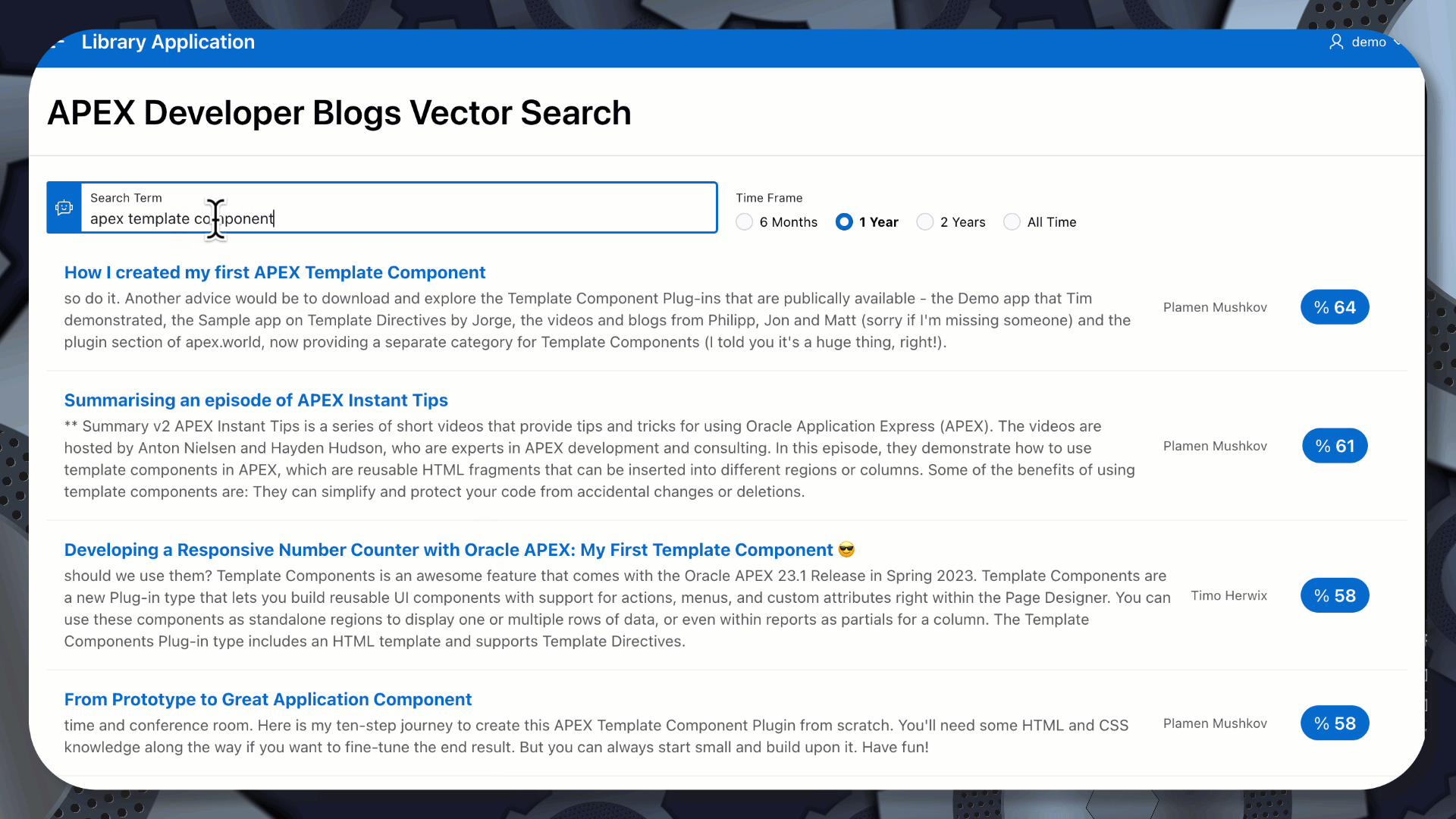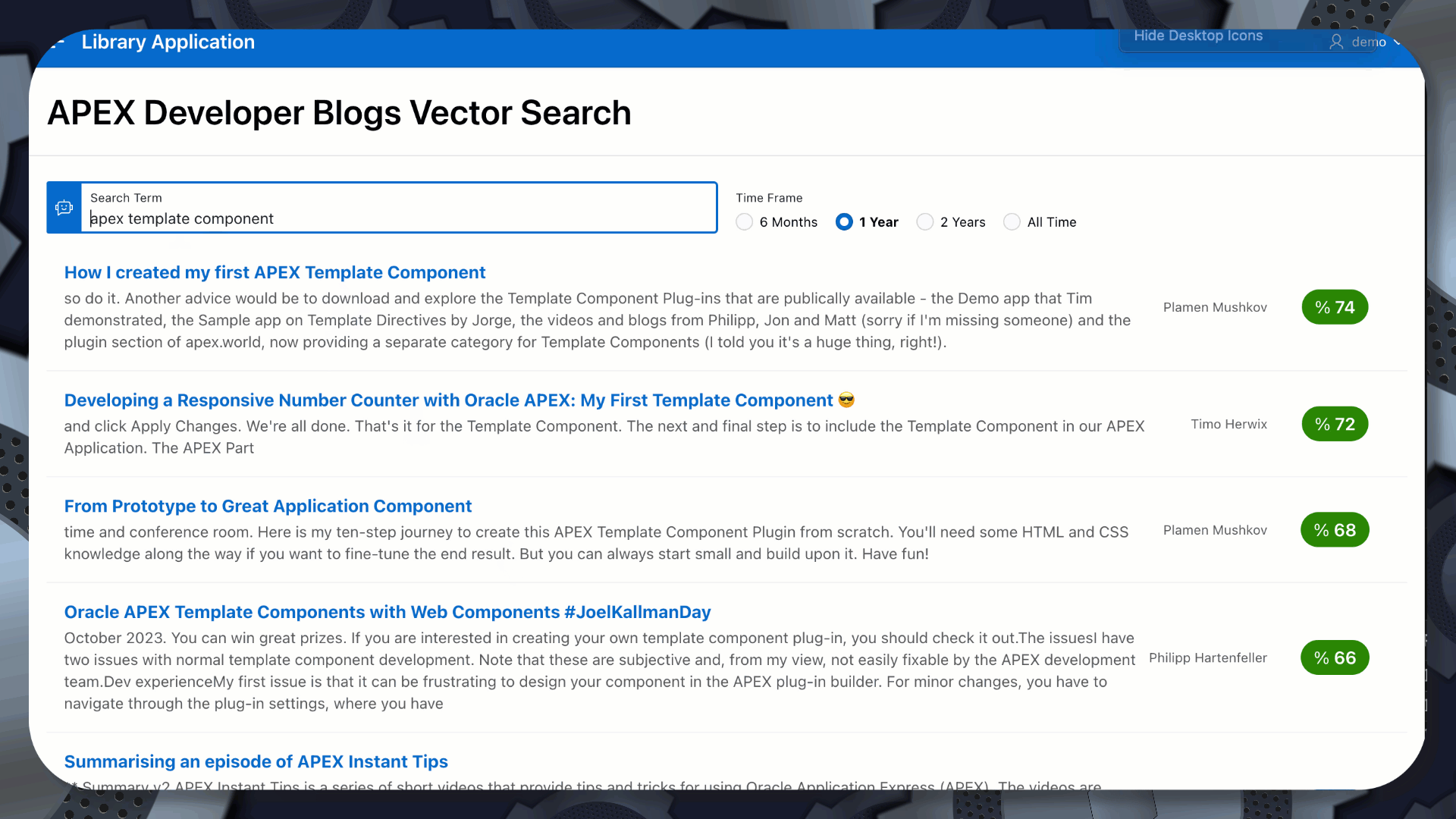
Demo
In the below example, I initially searched for ‘apex template part’. A Vector/Semantic search still finds several posts related to ‘APEX Template Components’, but with a slightly lower score than the second search, using the exact term.
Vector PLSQL Packages
Each SQL function mentioned in this post has equivalent PL/SQL APIs, which you can read about here.
Documentation Links
Conclusion
I realize this was quite a lengthy post. For me, it was a voyage of discovery. I learned many nuances related to preparing data for Vector Search and the variables that impact the accuracy of these kinds of searches.
Vector search in the database may still be a few years off for many of you, especially those building APEX Apps on EBS, for which database upgrades take longer to plan. I still encourage you to start understanding this significant technology, which has the potential to revolutionize the way we search for data and media.
Subscribe to my newsletter
Read articles from Jon Dixon directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Jon Dixon
Jon Dixon
Hi, thanks for stopping by! I am focused on designing and building innovative solutions using the Oracle Database, Oracle APEX, and Oracle REST Data Services (ORDS). I hope you enjoy my blog.