What is Data Engineering?: Everything You Need to Know
 Harvey Ducay
Harvey Ducay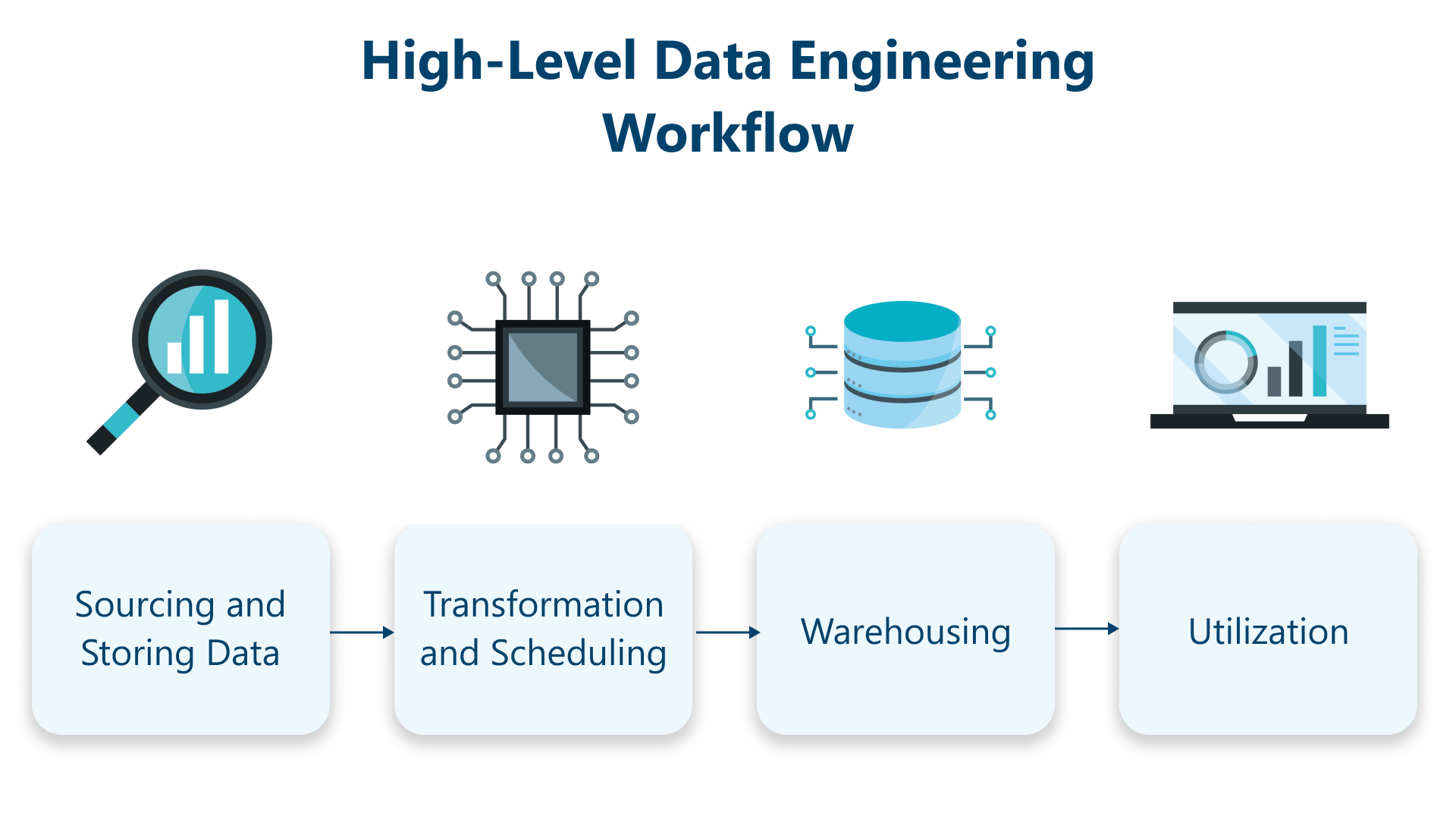
Ever found yourself drowning in a sea of data, trying to make sense of countless Excel sheets while your computer fan sounds like it's about to take off? Trust me, I've been there. As someone who once tried to train a machine learning model on my laptop with 100GB of unstructured data (spoiler alert: it didn't end well), I learned the hard way why data engineering is the unsung hero of the data world.
My laptop trying to process 100GB of data…

Introduction
In today's digital age, data is the new gold – but just like raw gold, raw data needs refining before it becomes valuable. That's where data engineering comes in. Whether you're a startup trying to make sense of your customer data or a large enterprise handling petabytes of information, data engineering is the foundation that makes modern data science and analytics possible.
The Data Pipeline Journey
Raw Data → Data Engineering → Clean Data → Analysis → Insights
In this post, we'll define data engineering, explore its crucial role in the data ecosystem, and provide practical insights into how it can transform your business's data operations. We'll also look at real-world examples and best practices that can help you get started on your data engineering journey.
What is Data Engineering?
Data engineering is the practice of designing, building, and maintaining the infrastructure and systems needed to collect, store, process, and deliver data for analysis. Think of data engineers as the architects and plumbers of the data world – they build the pipelines and systems that ensure data flows smoothly from source to destination, arriving clean and ready for analysis.
A sample python BigQuery snippet
from google.cloud import bigquery
import pandas as pd
import logging
from datetime import datetime
class BigQueryETL:
def __init__(self, project_id: str):
"""Initialize BigQuery client"""
self.client = bigquery.Client(project=project_id)
logging.basicConfig(level=logging.INFO)
self.logger = logging.getLogger(__name__)
def extract(self, query: str) -> pd.DataFrame:
"""Extract data from BigQuery"""
try:
df = self.client.query(query).to_dataframe()
self.logger.info(f"Extracted {len(df)} rows")
return df
except Exception as e:
self.logger.error(f"Extraction failed: {str(e)}")
raise
def transform(self, df: pd.DataFrame) -> pd.DataFrame:
"""Apply transformations to the data"""
try:
# Convert dates
date_cols = df.select_dtypes(include=['datetime64[ns]']).columns
for col in date_cols:
df[col] = pd.to_datetime(df[col])
# Handle missing values in numeric columns
num_cols = df.select_dtypes(include=['float64', 'int64']).columns
df[num_cols] = df[num_cols].fillna(df[num_cols].mean())
# Add time-based features if timestamp exists
if 'timestamp' in df.columns:
df['hour'] = df['timestamp'].dt.hour
df['is_weekend'] = df['timestamp'].dt.dayofweek.isin([5, 6]).astype(int)
return df.drop_duplicates()
except Exception as e:
self.logger.error(f"Transformation failed: {str(e)}")
raise
def load(self, df: pd.DataFrame, table_id: str) -> None:
"""Load data into BigQuery"""
try:
job_config = bigquery.LoadJobConfig(
write_disposition='WRITE_TRUNCATE',
schema_update_options=[bigquery.SchemaUpdateOption.ALLOW_FIELD_ADDITION]
)
load_job = self.client.load_table_from_dataframe(
df, table_id, job_config=job_config
)
load_job.result() # Wait for job to complete
self.logger.info(f"Loaded {len(df)} rows to {table_id}")
except Exception as e:
self.logger.error(f"Load failed: {str(e)}")
raise
def run_pipeline(self, query: str, destination_table: str) -> None:
"""Execute the full ETL pipeline"""
start_time = datetime.now()
try:
df = self.extract(query)
df_transformed = self.transform(df)
self.load(df_transformed, destination_table)
duration = datetime.now() - start_time
self.logger.info(f"Pipeline completed in {duration}")
except Exception as e:
self.logger.error(f"Pipeline failed: {str(e)}")
raise
# Example usage
if __name__ == "__main__":
# Initialize pipeline
etl = BigQueryETL("your-project-id")
# Example query
query = """
SELECT user_id, timestamp, activity_type, duration
FROM `your-project-id.dataset.user_activity`
WHERE DATE(timestamp) >= DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY)
"""
# Run pipeline
etl.run_pipeline(query, "your-project-id.dataset.processed_activity")
Why is Data Engineering Important?
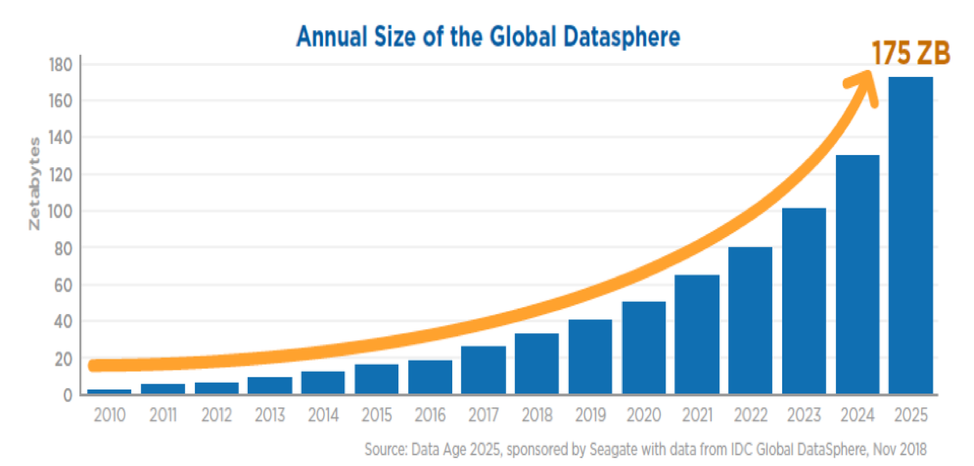
1. Data Volume: 175 Zettabytes by 2025
By 2025, global data creation will hit 175 zettabytes (that's 175 billion terabytes!). To put this in perspective, if you stored this data on DVDs, the stack would reach the moon 23 times. This explosive growth, driven by IoT devices, social media, and streaming services, makes robust data engineering not just important, but critical for business survival.
2. Decision Speed: 25% Faster
Organizations with proper data engineering make decisions 25% faster than their competitors. Think retail making inventory decisions in hours instead of days, or healthcare reducing patient diagnosis time by a third. This speed comes from automated data pipelines, real-time analytics, and streamlined access to clean, reliable data.
3. Cost Reduction: Up to 70%
Companies can slash data-related costs by up to 70% through data engineering. How? Through smart infrastructure optimization (30% savings), automated processes (20% savings), and better resource allocation (20% savings). Instead of throwing money at storing and processing messy data, proper engineering means you spend less while getting better results.
Real Examples of Data Engineering
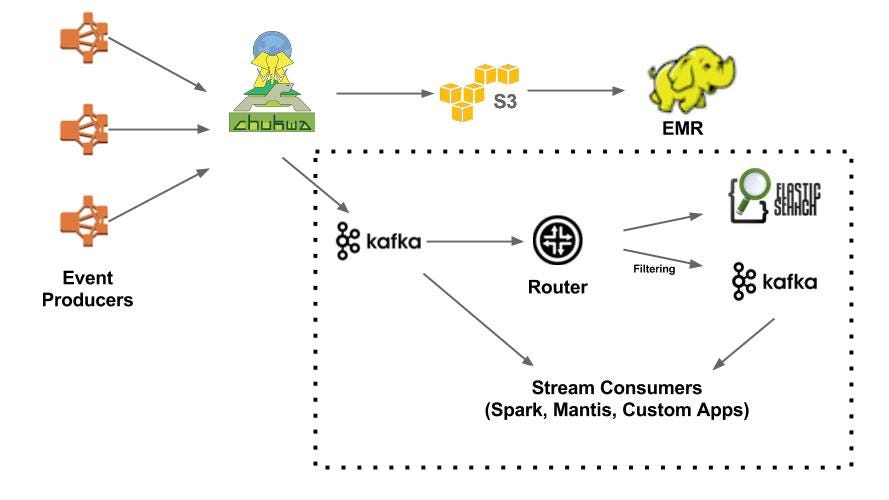
Real-World Data Engineering Examples
1. Netflix's Data Pipeline
[ARCHITECTURE DIAGRAM SUGGESTION: Netflix Data Flow]
graph TD
A[User Interactions] -->|Streaming Events| B[Kafka]
B -->|Real-time Processing| C[Apache Flink]
B -->|Batch Processing| D[Spark]
C -->|Hot Data| E[Cassandra]
D -->|Cold Data| F[S3 Data Lake]
E --> G[Feature Store]
F --> G
G -->|ML Training| H[Model Training]
H -->|Model Serving| I[Recommendation Service]
I -->|Personalization| J[User Interface]
Netflix processes a staggering 450+ billion events per day through their data pipeline. Here's how their architecture works:
Data Collection Layer
Captures user interactions (clicks, views, pauses, ratings)
Records viewing quality metrics
Tracks device-specific information
Processes content metadata
Processing Layer
Real-time processing for immediate recommendations
Batch processing for deeper insights
A/B testing data for feature optimization
Content performance analytics
Storage Layer
Hot data in Cassandra for real-time access
Cold data in S3 for historical analysis
Feature store for ML model training
Redis cache for quick access to recommendations
The result? Those eerily accurate "Because you watched..." recommendations that keep us binge-watching!
2. Uber's Real-Time Analytics
[ARCHITECTURE DIAGRAM SUGGESTION: Uber's Real-time System]
graph TD
A[Rider/Driver Apps] -->|Events| B[Apache Kafka]
B -->|Stream Processing| C[Apache Flink]
B -->|Batch Processing| D[Apache Spark]
C -->|Real-time Metrics| E[Apache AthenaX]
D -->|Historical Data| F[Hudi Data Lake]
E -->|Current State| G[Redis]
F -->|Analytics| H[Presto]
G -->|Real-time Decisions| I[Matching Service]
H -->|Business Intelligence| J[Analytics Dashboard]
Uber's real-time data pipeline handles millions of events per second. Here's their architecture breakdown:
Real-time Processing Layer
Processes GPS coordinates every 4 seconds
Handles surge pricing calculations
Manages driver-rider matching
Monitors service health
Storage Layer
Temporal data in Redis for immediate access
Historical data in Apache Hudi
Geospatial indexing for location services
Cached frequently accessed routes
Analytics Layer
Real-time city demand forecasting
Dynamic pricing algorithms
Driver supply optimization
Route optimization based on traffic patterns
The result is a system that can match you with a driver in seconds while optimizing for countless variables in real-time!
Conclusion: The Future is Data-Driven
Looking at these real-world examples, it's clear that data engineering isn't just about moving data from point A to point B – it's the backbone of modern digital experiences we take for granted. From Netflix knowing exactly what show you'll love next to Uber finding you the perfect driver in seconds, data engineering makes the impossible possible.
Remember when I mentioned my laptop meltdown trying to process 100GB of data? That's like trying to deliver packages on a bicycle when you need a fleet of trucks. Modern data engineering is that fleet of trucks, complete with GPS, route optimization, and real-time tracking.
As we move toward an even more data-intensive future, the role of data engineering will only grow. Whether you're a startup processing your first thousand users' worth of data or an enterprise handling petabytes, the principles remain the same:
Build scalable, resilient pipelines
Automate everything you can
Monitor religiously
Plan for growth
Subscribe to my newsletter
Read articles from Harvey Ducay directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by