Kubernetes Pod Autoscaling: Understanding Horizontal and Vertical Scaling
 Shazia Massey
Shazia Massey
Horizontal Pod Autoscaling (HPA) in Kubernetes is a mechanism that automatically adjusts the number of pod replicas in a deployment or replica set based on observed metrics like CPU or memory usage.
How HPA Works:
HPA constantly monitors the specified metrics, such as CPU usage. If the average utilization across all pods exceeds the target threshold, more pods are added to handle the load. Conversely, if utilization drops below the threshold, the number of pods is reduced.
Benefits:
Efficient Resource Utilization: Pods are scaled up or down based on demand, ensuring the application runs efficiently.
Cost Savings: Scaling down when demand is low can reduce resource costs.
Improved Performance: Scaling up during high demand ensures the application remains responsive.
Vertical Pod Autoscaling (VPA) in Kubernetes is a feature that dynamically adjusts the resource requests (CPU and memory) of individual pods based on real-time usage. Unlike Horizontal Pod Autoscaling (HPA), which scales the number of pod replicas to handle load, VPA optimizes the resources allocated to each pod, ensuring that they are neither over-provisioned nor under-provisioned. This enables efficient resource utilization and maintains application performance by adjusting pod resources according to their actual needs.
How VPA Works:
VPA continuously monitors the resource consumption of pods and provides recommendations to increase or decrease resource requests based on actual usage. When configured to operate automatically, VPA reschedules the pod with the updated resource allocations, ensuring optimal resource utilization without manual intervention.
Benefits:
Efficient Resource Utilization: Helps ensure that pods have the exact amount of CPU and memory they need, neither under-provisioned nor over-provisioned.
Cost Savings: Avoids over-provisioning, ensuring only the necessary resources are used, leading to potential cost savings.
Simplified Scaling: Instead of adding more pods when existing pods are underutilized, VPA allows you to scale resource requests dynamically.
Let’s understand this concept through practical implementation in a project.
Provisioned and configured an Amazon EKS cluster on an EC2 instance of type t2.medium.
*--------------- Install AWS CLI
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
sudo apt install unzip
unzip awscliv2.zip
sudo ./aws/install
aws configure
# git clone https://github.com/shazia-massey/Pod-Auto-Scaling.git
# cd Pod-Auto-Scaling
# ls
# cd Cluster
# ls
# eks-rbac.md main.tf output.tf variables.tf
*----------------terraform
# sudo snap insatll terraform --classic
# terraform init
# terraform plan
# terraform apply --auto-approve
*---------------kubectl
# sudo snap install kubectl --classic
# aws eks --region us-east-1 update-kubeconfig --name devopsshack-cluster
# kubectl get nodes
Now our cluster is ready
In our manifest YAML file (ds.yml), we define resource limits for the MySQL deployment, specifying the CPU and RAM allocations. We also set resource requests to ensure that the necessary resources are consistently available. Similarly, resource requests are configured for the application deployment to guarantee optimal performance and resource utilization.
# cd Pod-Auto-Scaling
# ls
# Cluster Dockerfile Jenkinsfile bankapp-hpa.yml ds.yml mvn mysql-hpa.yml pom.xml src
# kubectl apply -f ds.yml
# kubectl get all
# application is running now
---
# MySQL Deployment with Resource Requests
apiVersion: apps/v1
kind: Deployment
metadata:
name: mysql
spec:
selector:
matchLabels:
app: mysql
strategy:
type: Recreate
template:
metadata:
labels:
app: mysql
spec:
containers:
- image: mysql:8
name: mysql
env:
- name: MYSQL_ROOT_PASSWORD
value: "Test@123"
- name: MYSQL_DATABASE
value: "bankappdb"
ports:
- containerPort: 3306
name: mysql
resources:
requests:
memory: "1Gi"
cpu: "500m"
limits:
memory: "2Gi"
cpu: "1000m"
---
# MySQL Service
apiVersion: v1
kind: Service
metadata:
name: mysql-service
spec:
ports:
- port: 3306
selector:
app: mysql
---
# Java Application Deployment with Resource Requests
apiVersion: apps/v1
kind: Deployment
metadata:
name: bankapp
spec:
replicas: 1
selector:
matchLabels:
app: bankapp
template:
metadata:
labels:
app: bankapp
spec:
containers:
- name: bankapp
image: adijaiswal/bankapp:latest
ports:
- containerPort: 8080
env:
- name: SPRING_DATASOURCE_URL
value: jdbc:mysql://mysql-service:3306/bankappdb?useSSL=false&serverTimezone=UTC&allowPublicKeyRetrieval=true
- name: SPRING_DATASOURCE_USERNAME
value: root
- name: SPRING_DATASOURCE_PASSWORD
value: Test@123
resources:
requests:
memory: "500Mi"
cpu: "500m"
limits:
memory: "1000Mi"
cpu: "1000m"
---
# Bank Application Service
apiVersion: v1
kind: Service
metadata:
name: bankapp-service
spec:
type: LoadBalancer
ports:
- port: 80
targetPort: 8080
selector:
app: bankapp
To handle increased load on a pod and enable horizontal scaling, we can set up the following flow:
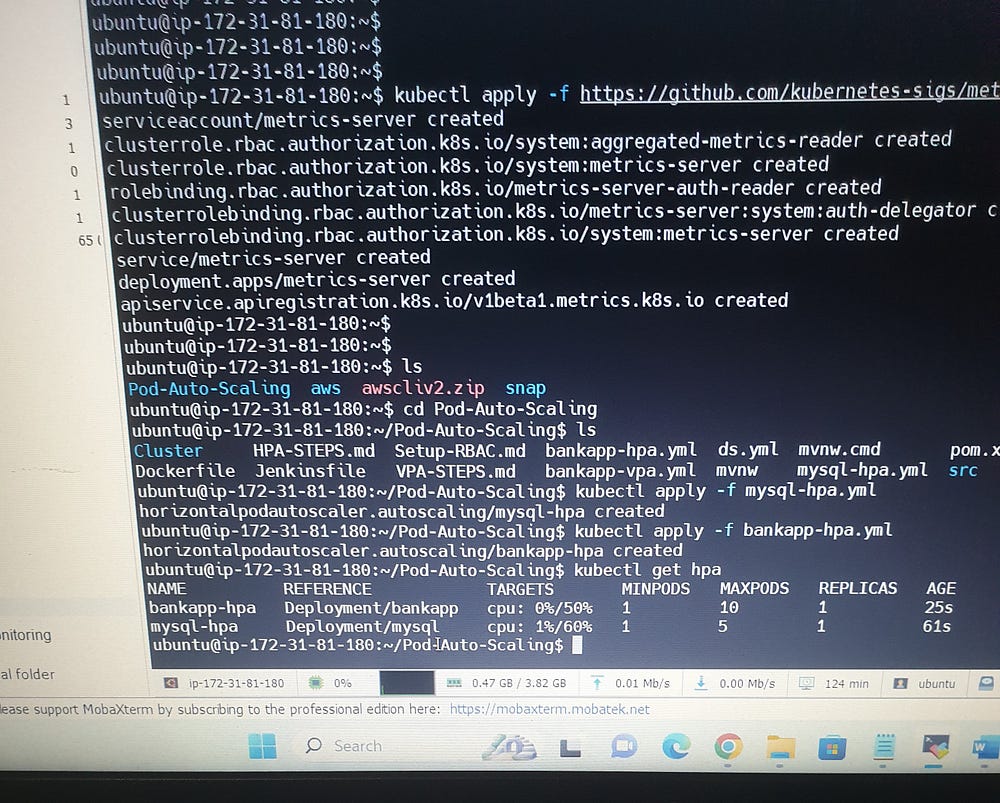
Install Metrics Server:
The Metrics Server collects resource metrics (like CPU and memory usage) from the cluster nodes and pods. It is required for Kubernetes to scale pods based on resource usage.
* - - - Install metrics-server
# kubectl apply -f
https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
# kubectl apply -f mysql-hpa.yml
# kubectl apply -f bankapp-hpa.yml
# kubectl get hpa
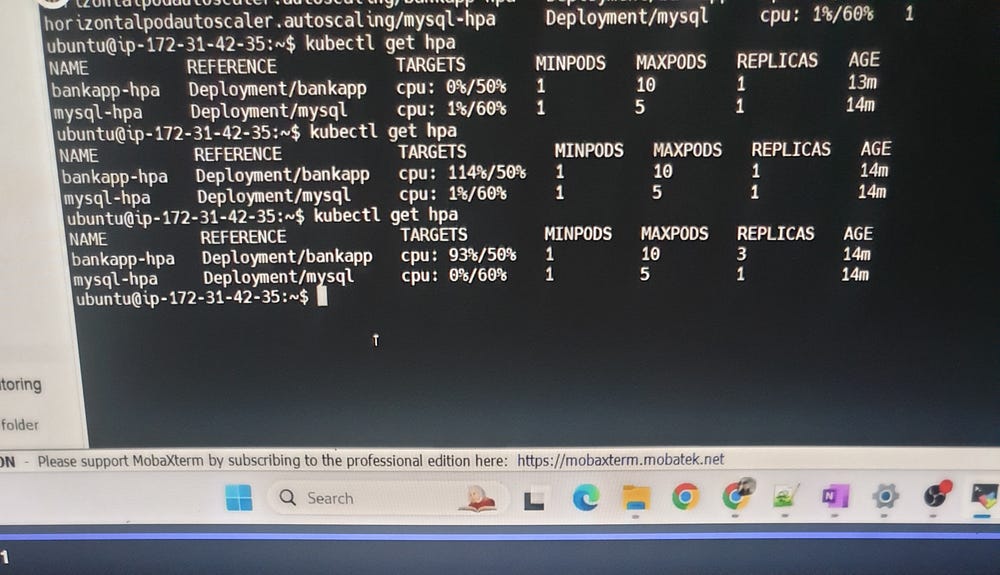
Define a Horizontal Pod Autoscaler (HPA):
Once the Metrics Server is running, create a Horizontal Pod Autoscaler to automatically scale the pods based on CPU or memory usage.
---
# Horizontal Pod Autoscaler for Java Application
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: bankapp-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: bankapp
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50 # Scale when CPU utilization goes above 50%
Explanation of Horizontal Pod Autoscaler (HPA):
This YAML file defines a Horizontal Pod Autoscaler (HPA) for a Java application deployment named bankapp. The HPA automatically adjusts the number of pods (replicas) in response to changes in the CPU utilization of the application. Here's a breakdown of its key components:
apiVersion and kind specify that this is an HPA configuration using version
autoscaling/v2.metadata provides a name for the HPA resource,
bankapp-hpa.scaleTargetRef tells the HPA which resource to scale. In this case:
apiVersion is
apps/v1, meaning it refers to a deployment resource.kind is
Deployment, indicating that it’s scaling a Kubernetes deployment.name is
bankapp, specifying the exact deployment that will be monitored and scaled.minReplicas is set to
1, meaning the deployment will always have at least one pod running.maxReplicas is set to
10, so the number of pods can scale up to a maximum of ten if necessary.metrics specifies the criteria for scaling. In this case, it’s based on CPU utilization:
If the CPU utilization exceeds 50% (set by
averageUtilization), the HPA will automatically increase the number of pods to handle the increased load.
The scaleTargetRef ensures that the bankapp deployment is dynamically scaled based on its CPU usage, allowing the system to maintain responsiveness by adjusting the number of pods as needed.
---
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: mysql-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: mysql
minReplicas: 1
maxReplicas: 5
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60 # Scale when CPU utilization goes above 60%
Explanation of Horizontal Pod Autoscaler(HPD) for MySQL:
This YAML configuration defines a Horizontal Pod Autoscaler(HPA) for a MySQL application deployment named mysql. The HPA is designed to automatically adjust the number of pod replicas based on CPU utilization metrics to ensure optimal performance and resource usage. Here are its key components:
apiVersion and kind indicate that this is an HPA configuration using version
autoscaling/v2.metadata includes the name of the HPA resource,
mysql-hpa.scaleTargetRef specifies the deployment to be scaled:
apiVersion is
apps/v1, referring to the version for deployment resources.kind is
Deployment, indicating the type of resource.name is
mysql, pointing to the specific deployment that the HPA will monitor and scale.minReplicas is set to
1, ensuring that at least one pod is always running.maxReplicas is set to
5, allowing the number of pods to scale up to five if necessary.metrics defines the scaling criteria based on CPU utilization:
The HPA will trigger scaling actions if the CPU utilization exceeds 60% (as indicated by
averageUtilization), automatically increasing the number of replicas to handle increased load.
Overall, this configuration allows the MySQL deployment to dynamically adjust its pod count based on CPU demand, helping maintain performance while efficiently utilizing resources.
Vertical-Pod-Autoscaler:
*------------autoscaler
# git clone https://github.com/kubernetes/autoscaler.git
# ./hack/vpa-up.sh
# cd Pod-Auto-Scaling
# ls
# Cluster Dockerfile Jenkinsfile bankapp-hpa.yml ds.yml bankapp-vpa.yml mvn mysql-hpa.yml pom.xml src
# kubectl apply -f bankapp-vpa.yml
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: bankapp-vpa
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: bankapp
updatePolicy:
updateMode: "Auto" # This mode automatically updates the resources
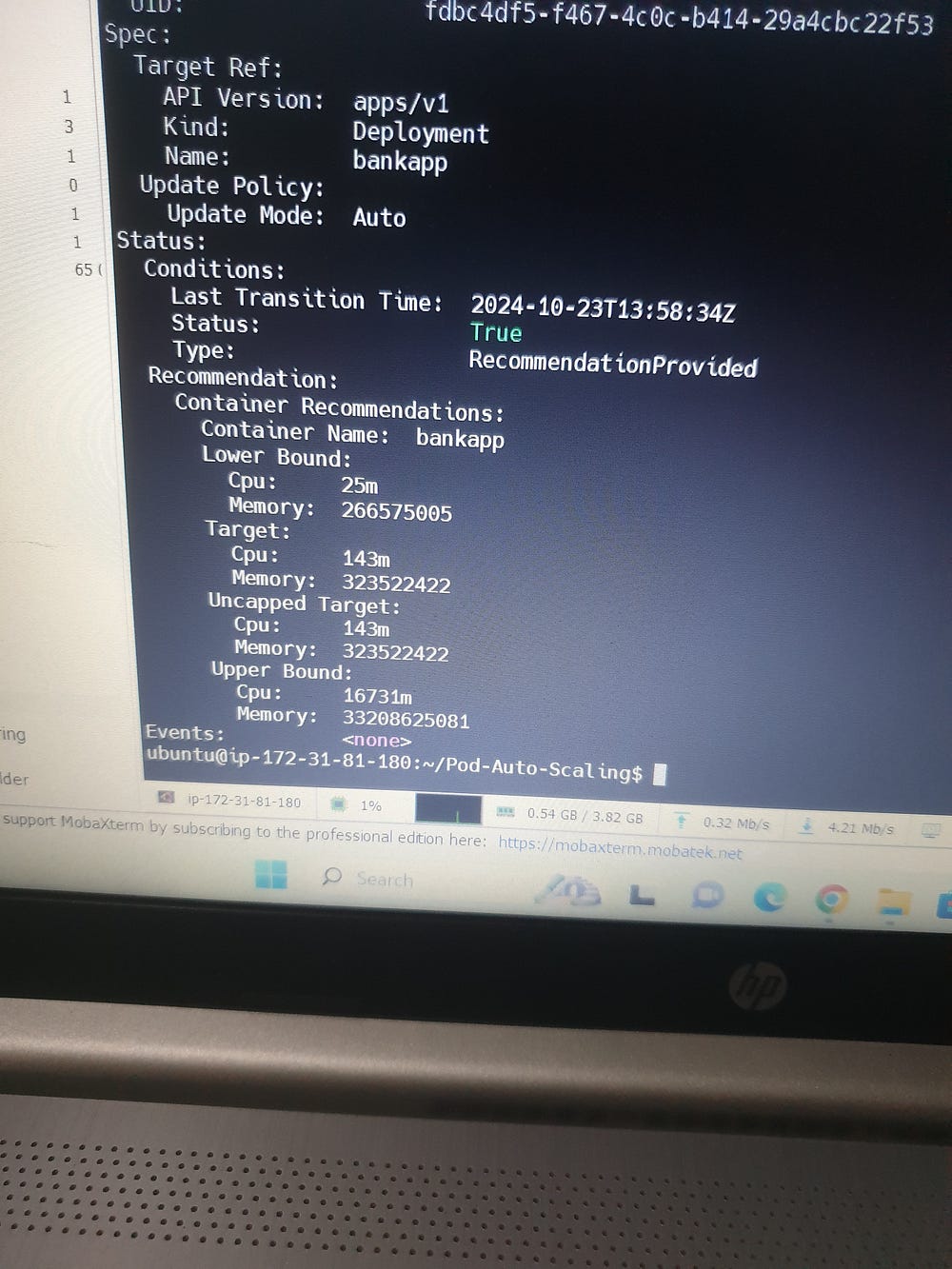
# kubectl describe vpa bankapp-vpa
Explanation of Horizontal Pod Autoscaler (HPA) for MySQL:
The Horizontal Pod Autoscaler (HPA) for MySQL is a Kubernetes feature that automatically adjusts the number of MySQL pod replicas based on CPU utilization or other specified metrics, ensuring that the database can scale efficiently in response to varying workloads. By setting a minimum of 1 pod and a maximum of 5 pods, the HPA allows the MySQL deployment to dynamically increase or decrease its capacity, maintaining optimal performance and resource usage when CPU utilization exceeds a defined threshold, such as 60%. This capability enhances the reliability and responsiveness of MySQL in a cloud-native environment.
We need to test this now; using a load generator will help evaluate the system’s performance under heavy load.
*------load-generator
# kubectl get all
# kubectl exec -it load-generator -- /bin/sh
# while true; do wget -q -O- http://bankapp-service/api/transactions; done
kubectl get vpa
Overall, the project illustrates the significant benefits of using Kubernetes autoscaling features for modern cloud-native applications, reinforcing the need for dynamic resource management in today’s diverse and fluctuating workloads.
Subscribe to my newsletter
Read articles from Shazia Massey directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by