Database Sharding: The Key to Scalability in Modern Data Management
 Jayachandran Ramadoss
Jayachandran Ramadoss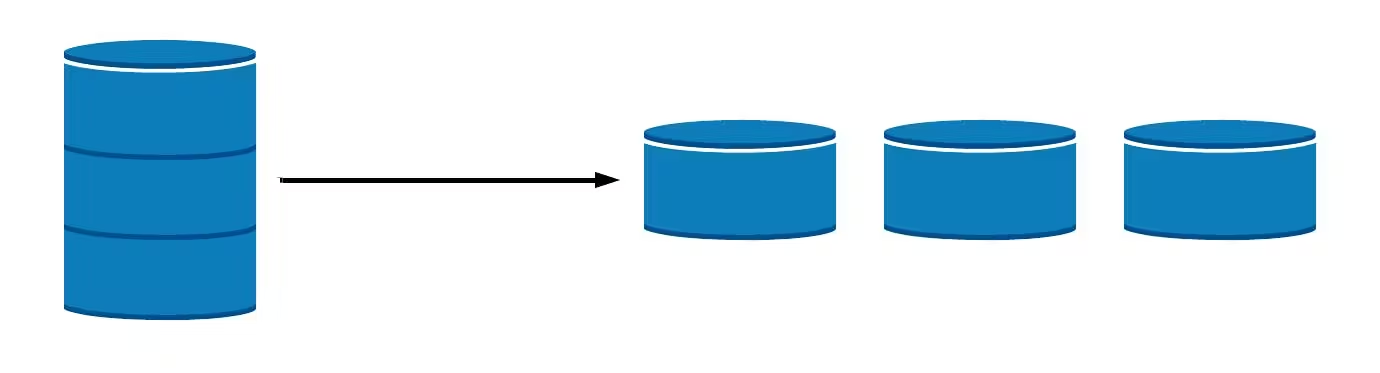
As data grows exponentially, businesses increasingly require databases capable of handling massive, distributed workloads. Enter database sharding, a powerful solution for database partitioning that divides a large database into smaller, manageable parts, known as “shards.” Sharding allows organizations to scale horizontally by distributing data across multiple nodes, improving performance, manageability, and resilience.
we’ll explore what database sharding is, how it works, and the critical components and considerations involved in implementing it.
What is Database Sharding?
At its core, sharding is a method of partitioning data where each “shard” represents a small, isolated portion of the database. Each shard contains a subset of the database rows, while each shard structure (or schema) remains identical. The concept of sharding can be likened to a puzzle: each shard is a piece of the whole database puzzle, holding unique data that is independently manageable.
Database sharding is essential for applications with high data volumes, as it:
• Increases data storage capabilities by distributing data across multiple nodes.
• Enhances performance by allowing parallel processing across shards.
• Provides scalability through horizontal partitioning, as new shards can be added when needed.
This form of horizontal scaling is crucial for modern applications, particularly those in finance, social media, and e-commerce, where databases must handle vast amounts of transactional data without sacrificing speed or stability.
How Does Database Sharding Work?
The process of sharding involves dividing and distributing data across multiple nodes based on a specific criterion. Let’s break down how a sharded system operates:
1. Data Partitioning:
Data is first partitioned based on a chosen shard key, which is a unique identifier, such as a user ID, date, or geographic region.
For example, a student record database might be divided by the year of enrollment, ensuring records from different years are stored on separate nodes.
2. Data Distribution:
After partitioning, data is distributed across multiple servers or nodes. Each node, or shard, is responsible for storing and processing a subset of data, effectively balancing the load and improving overall system efficiency.
3. Data Retrieval:
When querying data, the system uses the shard key to identify which shard contains the necessary information. The query is directed to the correct node, ensuring quick data retrieval and reducing the load on any single server.
By distributing data across multiple nodes, sharding supports applications with high concurrent usage and massive data requirements, reducing latency and enabling the system to manage higher throughput efficiently.
Key Components of Sharding
1. Shard Key
The shard key is a column value within the dataset that determines the distribution of data across shards. A carefully selected shard key optimizes data retrieval, balances load, and prevents hotspotting, where certain shards become overloaded with requests. A poorly chosen shard key, however, can lead to imbalanced data distribution and affect performance.
Choosing a Good Shard Key:
• Cardinality: The shard key should have high cardinality, meaning it should offer a wide range of unique values to promote balanced distribution.
• Data Growth: The shard key should account for anticipated data growth. For instance, sharding by user ID allows seamless user growth without having to rebalance shards.
• Query Patterns: Select a key that aligns with common query patterns. For example, an e-commerce application might shard by user region if queries often require regional data.
2. Sharding Algorithm
The sharding algorithm distributes data across shards based on the shard key. The most commonly used algorithms are:
• Range-Based Sharding: Data is divided based on a range of values, like date ranges or user IDs. This approach is easy to implement but can lead to data imbalances if certain ranges receive higher traffic.
• Hash-Based Sharding: A hashing function distributes data uniformly across shards, reducing the risk of imbalance. However, it can make range queries more challenging.
• Directory-Based Sharding: A lookup table is used to map data to shards, allowing for flexible shard key choices and rebalancing. This method can be more complex but allows dynamic data distribution.
The algorithm choice should align with the application’s data patterns and growth, as each algorithm has unique strengths and trade-offs.
3. Partitions
Partitions are the sub-units within each shard. Each partition stores data as defined by the sharding logic, and the partition’s size and structure can significantly impact database performance.
Benefits of Database Sharding
1. Scalability
Sharding supports horizontal scaling, allowing databases to accommodate data growth by adding nodes rather than overloading a single database. This scalability is ideal for applications where data growth is unpredictable or continuous.
2. Improved Performance
By spreading the database load across multiple servers, sharding reduces latency, increases response times, and improves overall performance. Each shard processes a smaller dataset, so queries complete faster, even under high usage.
3. Enhanced Resilience
Sharding improves resilience by isolating data across nodes. A failure in one shard does not affect the availability of other shards, ensuring that applications remain functional even during partial outages.
4. Manageability
Breaking down large databases into smaller, manageable shards makes routine maintenance, backups, and upgrades easier. Administrators can maintain shards independently, reducing downtime and improving efficiency.
Challenges and Considerations of Sharding
Despite its benefits, database sharding presents certain challenges that need careful planning:
1. Increased Complexity: Sharding adds complexity to the database structure, requiring specialized logic to handle data distribution, querying, and transactions across shards.
2. Rebalancing Data: As data grows, shards may need to be rebalanced to maintain optimal performance. This process can be resource-intensive and may require downtime.
3. Cross-Shard Queries: Queries spanning multiple shards can become complex and costly, requiring careful query planning or restructuring to minimize performance impacts.
4. Consistency: Maintaining data consistency across shards can be challenging, especially in distributed systems with high volumes of concurrent transactions. Techniques like distributed ACID (Atomicity, Consistency, Isolation, Durability) compliance are often used to manage this.
Real-World Applications of Database Sharding
Many high-traffic applications rely on sharding to support their operations:
• Social Media: Platforms like Facebook and Twitter shard user data to manage billions of posts and interactions daily.
• E-Commerce: Sites like Amazon use sharding to handle large, dynamic product databases, with sharding keys based on product categories or regions.
• Financial Services: Banks and trading platforms shard transaction data for fast processing, compliance, and security, reducing response times for high-frequency trading systems.
These applications highlight the importance of efficient data partitioning, as sharding enables them to remain responsive, resilient, and scalable.
Should I use Sharding?
Because of this added complexity, sharding is usually only performed when dealing with very large amounts of data. Here are some common scenarios where it may be beneficial to shard a database:
The amount of application data grows to exceed the storage capacity of a single database node.
The volume of writes or reads to the database surpasses what a single node or its read replicas can handle, resulting in slowed response times or timeouts.
The network bandwidth required by the application outpaces the bandwidth available to a single database node and any read replicas, resulting in slowed response times or timeouts.
Before sharding, you should exhaust all other options for optimizing your database.
Setting up remote database
caching
Database Replication
Vertical Scaling
Final Thoughts
Database sharding is a fundamental approach for organizations needing to scale out their database infrastructure to accommodate massive datasets and high demand. While it requires careful planning around shard keys, partitioning, and algorithms, sharding ultimately delivers scalability, performance, and resilience.
For organizations anticipating growth, implementing a sharded database architecture can be a game-changer in maintaining robust and responsive data management systems.
This guide offers a foundational understanding of database sharding and its role in high-scale applications, serving as a resource for both developers and database administrators.
Subscribe to my newsletter
Read articles from Jayachandran Ramadoss directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by