Machine Learning Chapter 2.6: Random Forest Regression
 Fatima Jannet
Fatima Jannet
Hello and welcome back to Machine Learning! Today, we'll learn about the intuition behind random forests and how to apply them step by step in Python. Let's get started. This will be our final blog on regression.
Intuition
Random forest is a version of ensemble learning. Ensemble learning is when you take multiple algorithm or the same algorithm multiple times and you use them together to make something much more powerful than the original.

You keep building many regression decision trees. Then, you use all of them to make predictions. Each tree predicts the value of y for the data point in question, and you assign the new data point the average of all the predicted y values.
Instead of getting just one prediction, you get many predictions by default. These algorithms are typically set to use at least 500 trees, so you're getting 500 predictions for the value of y. You then take the average of these predictions.
This method means you're not relying on a single tree but on a forest of trees, which improves the accuracy of your prediction. By averaging many predictions, you reduce the chance of error. Even if one decision tree is not perfect due to the way data points were selected, using the average makes it less likely to get a bad prediction.
This approach leads to more accurate and stable predictions. Ensemble algorithms like this are more stable because changes in your dataset might affect one tree, but it's much harder for them to impact an entire forest of trees. Therefore, ensemble methods are more powerful in this way.
Resources
colab file: https://colab.research.google.com/drive/1bqXQKwI48-BkEa0PfM0P7WCIaZ_eRFCG#scrollTo=PVmESEFZX4Ig (save a copy)
Data sheet: https://colab.research.google.com/drive/1bqXQKwI48-BkEa0PfM0P7WCIaZ_eRFCG#scrollTo=PVmESEFZX4Ig (download)
Data preprocessing template: https://colab.research.google.com/drive/17Rhvn-G597KS3p-Iztorermis__Mibcz
Python Steps
So, this is our final model for the regression section, and we're going to build it quickly and efficiently because it closely resembles the decision tree regression model. We'll be very efficient.
As usual, delete all the codes and import the libraries and the data sheet
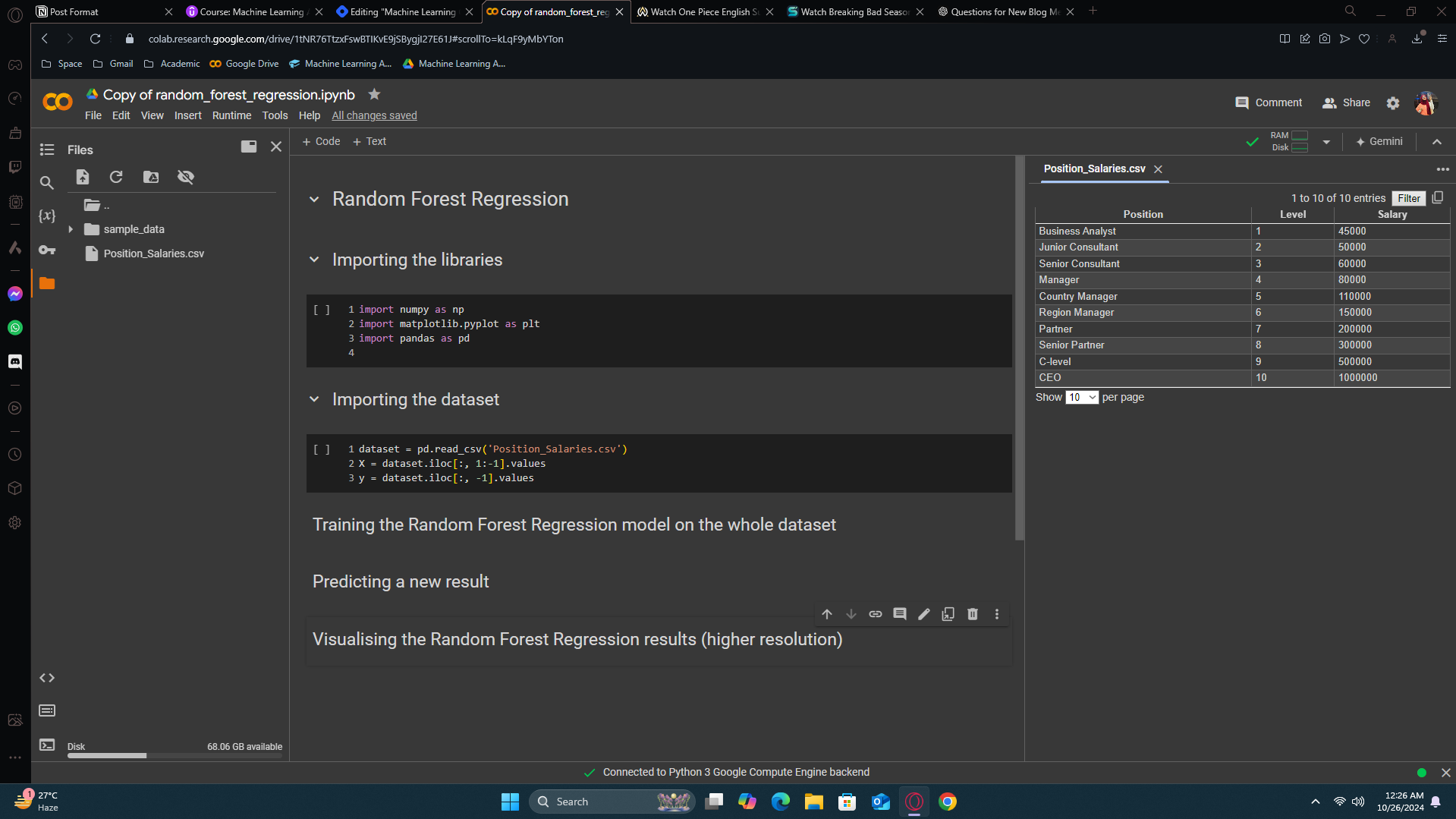
Training the Random Forest Regression model on the whole dataset
Predicting a new result

We got a pretty good prediction actually! 167,000 dollar is pretty close to what the person had mentioned, remember?
Visualising the Random Forest Regression results (higher resolution)
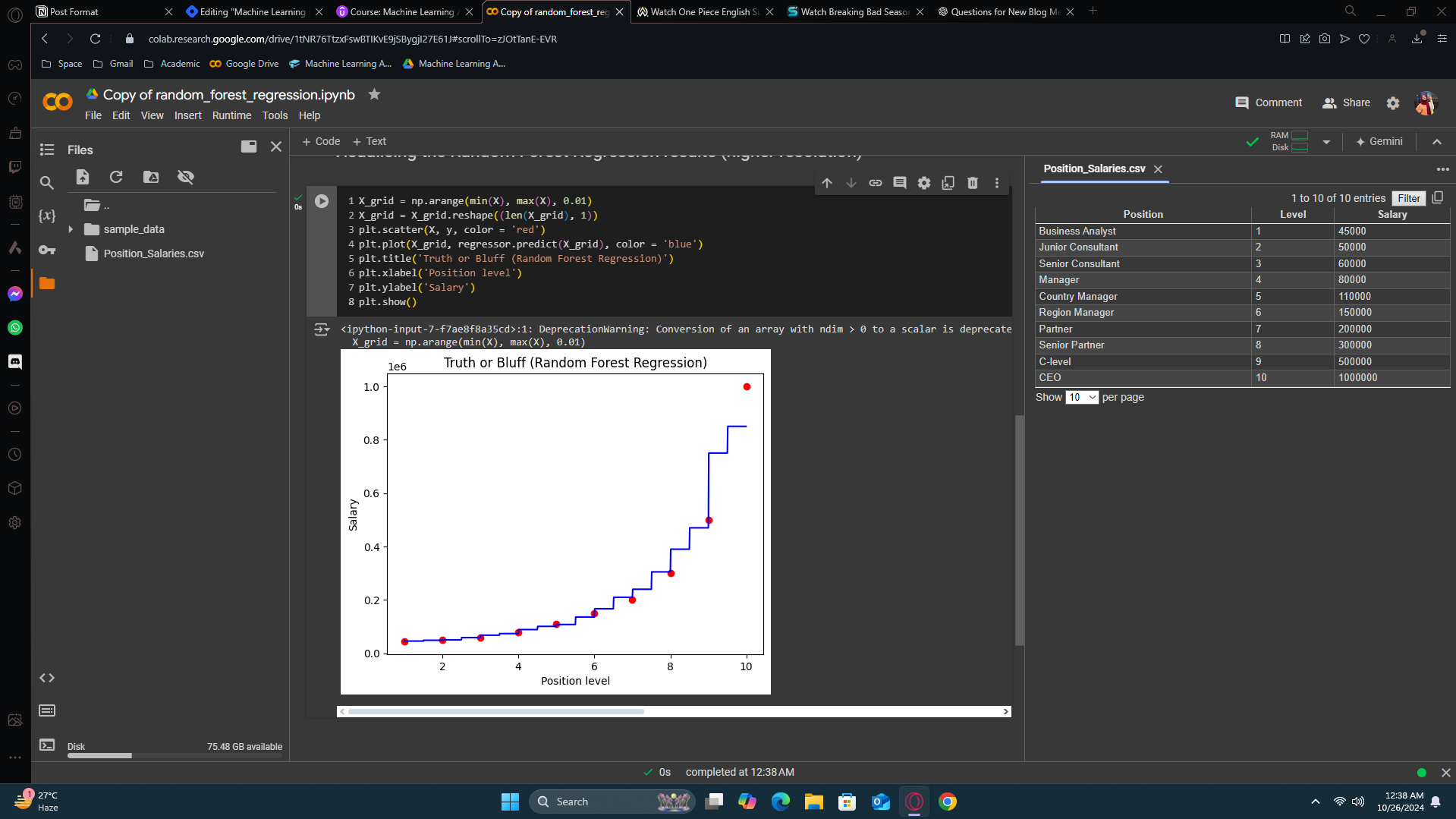
Although it look like the previous one but it has more splits this time cause it got more trees in it.
Alright, this is it! Our regression part of Machine Learning is finally over!
Subscribe to my newsletter
Read articles from Fatima Jannet directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by