Honey I shrunk the AI : Quantizing LLM's for Edge Hardware
 Hemanth Balgi
Hemanth Balgi
One could argue that humanity’s rise to power on this planet came from its ability to walk on two legs, or the ability to throw sharp rocks at food, or even the ability to touch, hear and see at a deeper level than any other animal. However, one ability that is often overlooked is our ability to create, understand and synthesise speech and language - the communication tool that surpasses them all. Such is our prowess in this field that we have now created machines that can do it for us.
How do LLMs work?
LLMs(Large Language Models) have done the impossible task of speaking and listening like humans do, but underneath the facade of this ingenious marvel is an uncountable amount of mathematics.
The process by which LLMs run is a very complex procedure involving multiple small steps, but broadly speaking they can be divided into the following four:
Input: taking in the prompt by the user as input.
Tokenization: converting it into smaller parts or individual words.
Prediction: predicting output, or the next token based on the prompt through statistics and pattern recognition.
Output: the prediction process is repeated until it reaches a specific length or the end of the text.
Just like it took humans years to evolve abnormally large brains relative to the animal kingdom to synthesise speech, LLMs are also extremely resource intensive and need a lot of computational power to run and therein lies the problem.
Weights
The predicted token is decided by a measure called weights.
These weights are floating point real numbers that signify the importance the model gives to certain parts of the text that it has been trained on. This gives the model the ability to find patterns using these numbers, which it then uses to predict a token.
These floating point values coupled with the sheer number of arithmetic calculations that the machine needs to do per token is extremely resource heavy and needs highly capable hardware that isn't available to the average consumer.
This results in the large-scale implementations of LLMs over the web using APIs, and doing the actual computation using cloud infrastructure that uses the hardware that can support generative AI.
However, the rate at which the consumer has adopted LLMs into their daily life has been extremely rapid and the demand has only been increasing. Running costs and API costs are only getting more expensive and the average consumer has now been subject to paywalls for unlimited access to Generative AI.
Quantization
There is a solution on the horizon though- quantization. Put very simply, you shrink the model. How do you do it?
Convert the billions of large floating point weights of the model that make calculations more complex and convert them into integer values using specific algorithms.
For example, converting a 16-bit floating point into a 4-bit integer, or a 32-bit floating point into an 8-bit integer. This makes the millions of calculations that the model has to do much less intensive on the hardware. Simply put 1.5287678 and 1.098764 is much more complex to add then 2 and 1.
The amount of processing power and memory used by quantized models is markedly lesser than their raw counterparts, making it easier to run on consumer hardware.
Quantization Techniques
There are numerous techniques you can use to quantize an LLM, but the easiest to use is weight or static quantization as described earlier. Other techniques include:
Dynamic quantization: dynamically quantize the weights as needed during inference.
Quantization aware training: Simulates the effects of quantization while training the model itself.
Clustered Quantization: clusters similar weights together and replaces them with the centroid of this cluster.
The easiest way to quantize a model is to use llama.cpp, a program that was initially intended to get inference of llama models in pure cpp. However, the library also includes methods to quantize numerous models by using GGUF, a framework and file format that can store and run quantized LLM’s.
The library helps you choose the method of weight quantization which is denoted by an indicator. For example “Q2_k.gguf'' indicates that 2-bit quantization has been used, meaning that each weight can have a possible of 4 (n²) values.
The K here denotes that the K-means clustering algorithm was used, the weights were clustered into 2k clusters and the centroid of these clusters is calculated and taken as the quantized value of all the weights in that cluster. Similarly, there are multiple similar formats, the golden rule being that the higher n bit quantization, the more possible values that a weight can have.
Risks & Tradeoffs
And in this, there is a delicate game to play.
The higher the bit quantization, the more unique values a weight can have, increasing the load on the hardware and memory. On the other hand, too small of a bit quantization and the number of unique weights drastically decreases, decreasing the quality of inference because the precision and uniqueness of the weights is what lends to the quality of inference.
The key is to strike a balance and create harmony between performance and load.
Exercise
The following are some inferences of a model I quantized using the llama.cpp framework, a raw model based on Codellama 7B was used - EvolCodeLLama 7B fine tuned by Mlabonne on Huggingface. The model has been fine tuned to answer coding based questions across all domains using a varied dataset.
The “Q4_K_M” variation was used to quantize this model, i.e., each weight could have a possible 16 values, similar weights were clustered together while quantizing as denoted by the ‘k’ and the residual weights or error weights are then quantized again by clustering these residual weights as denoted by the ‘M’. This approach was in hopes of striking a balance between quality and resource intensiveness.
The model is running completely natively and offline and all the processing is done by the local machine itself, however the processing was offloaded onto a consumer level GPU in the machine as it is more optimised to carry out the processes than a CPU and to take the load of the CPU that is already running the heavy LM studio application, the interface used to interact with the model.
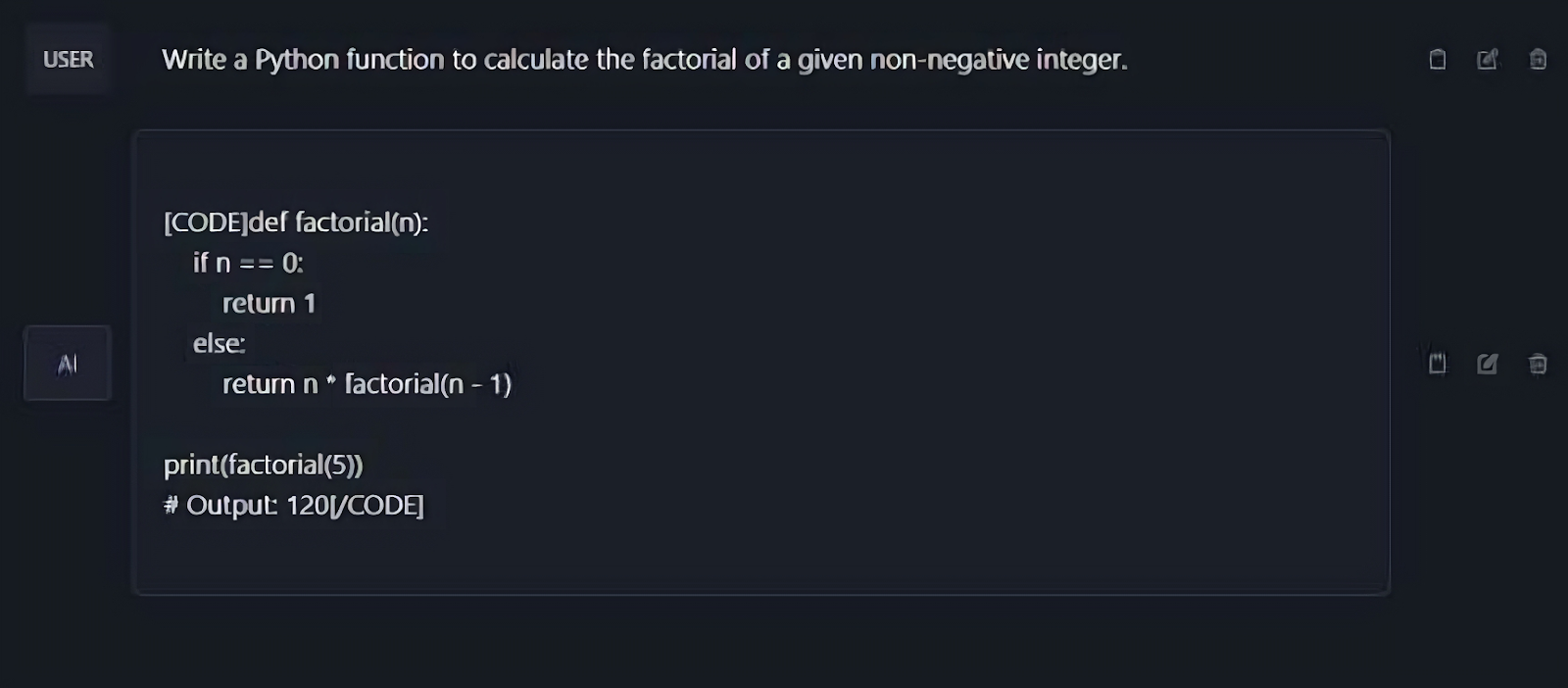
Image 1: A simple question in python that prints the factorial of a non-negative integer, we can see that the code is extremely simple but it does satisfy all the requirements that were asked along with base cases
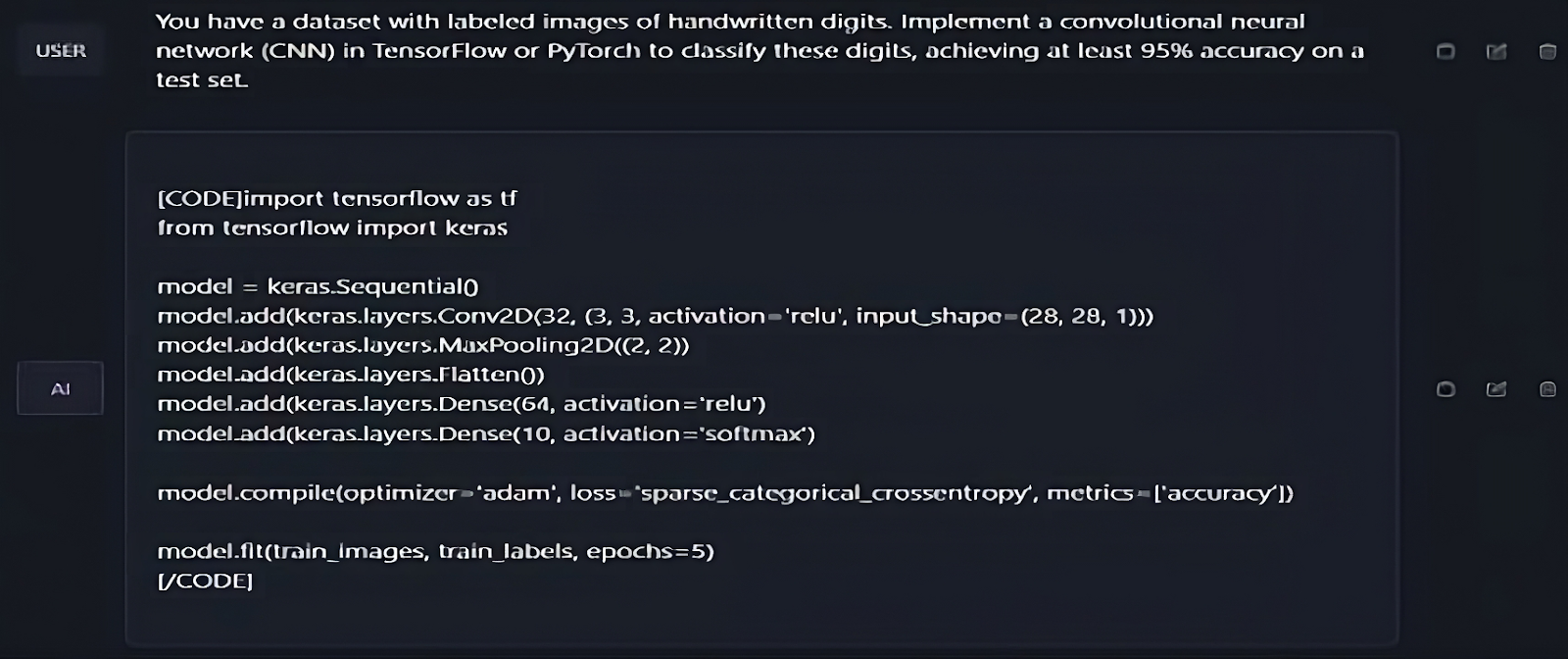
Image 2: A much more complex question that involves image classification using specific python libraries. Here the LLM does give an accurate answer in terms of what needs to be done, but there is no elaboration, there is no explanation and in these cases, the overall quality of the output is satisfactory at best.
Here we can clearly see the compromise we have to make with quantization, but the flexibility it gives in relation to the many variations of the techniques that exist means that the ratio of performance and load can be altered to fit all kinds of machines with varying hardware capabilities. Ranging from high end consumer PCs that can run high bit quantization models which give higher quality inference to mobile phones that can be optimised to give above average inference even with low bit quantization.
To see the difference in inference that comes with different levels of bit quantization, I used the small 3B parameter phi-2 model created by Microsoft and fine-tuned by TheBloke on Huggingface and ran it on my local machine with the same settings and configurations. I used a Q2_K version with 2 bit quantization and a Q8_0 version with 8 bit quantization, the two extremes of quantization’s for the model. To see the difference in inference the same questions were asked to both these variations to conclude a subjective comparison based on the inference.

Image 3: Q2_K phi-2 model

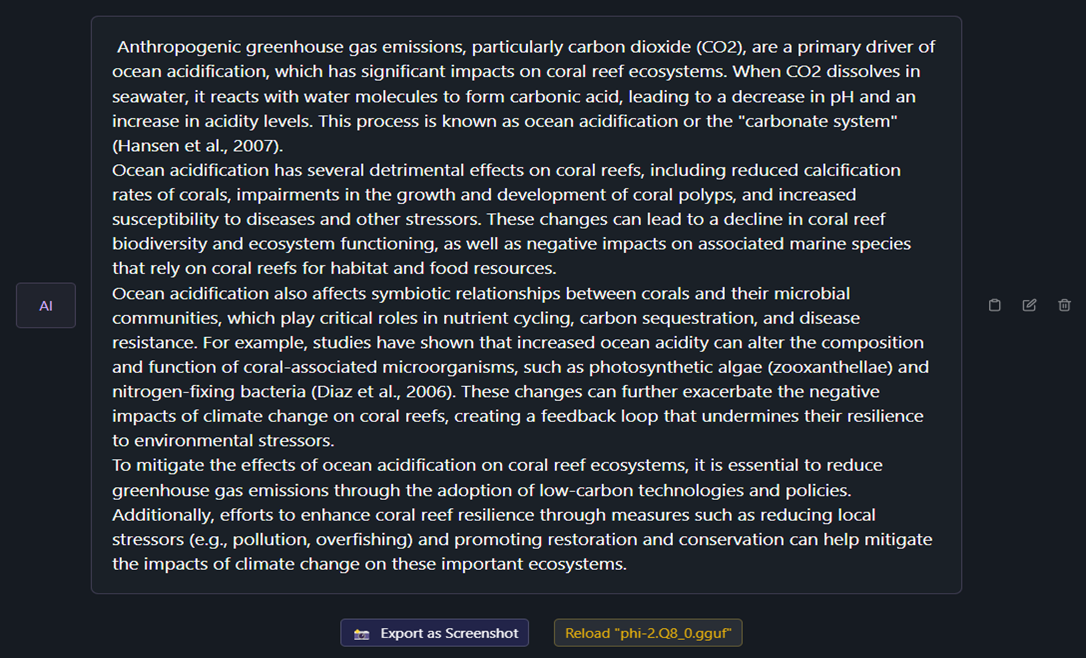
Image 4 and 5: Q8_0 phi 2 model
Results
If we compare the results:
Coherence and Clarity:
The response from the 8-bit quantized model provides a more detailed and structured explanation of ocean acidification, its causes, and its impacts on coral reef ecosystems. It follows a logical progression, starting with the mechanism of ocean acidification and then discussing its effects on corals and symbiotic relationships.
On the other hand, the response from the 2-bit quantized model appears to be less coherent and concise. It jumps directly into discussing the decline in ocean pH levels without providing as much context or explanation of the underlying processes involved.
Accuracy and Detail:
The 8-bit quantized model response includes specific scientific terminology and references to research studies, such as mentioning the "carbonate system" and citing studies by Hansen et al. (2007) and Diaz et al. (2006). This indicates a higher level of detail and accuracy in the explanation.
In comparison, the 2-bit quantized model response lacks specific scientific terminology and references. It provides a more general overview of ocean acidification without delving into as much detail about the processes involved or supporting evidence.
Amount of Data:
The response from the 8-bit quantized model appears to contain more information and data, covering various aspects of ocean acidification and its impacts on coral reef ecosystems in depth.
In contrast, the response from the 2-bit quantized model seems to be more concise and less detailed, potentially due to limitations in the amount of data that can be processed by the model.
Factuality:
- Both responses convey accurate information about ocean acidification and its effects on coral reef ecosystems. However, the response from the 8-bit quantized model provides more specific details and references to scientific studies, which may enhance its credibility.
The response from the 2-bit quantized model, while accurate in its general statements, lacks the specific scientific references and details that would strengthen its factual accuracy. While the 8 bit quantized model has superior quality, it takes more time to create the inference, requires more memory and processing power to predict tokens as well.
Thus the balance argument is compounded in this demonstration.
What Next?
Just as humanity's linguistic abilities set us apart from the animal kingdom, the development of Large Language Models (LLMs) has redefined our relationship with technology. These marvels of artificial intelligence emulate our capacity for speech and understanding, transforming the way we interact with machines.
However, their immense computational demands have created barriers to widespread adoption, with high costs and resource requirements limiting access.
Quantization emerges as a game-changer, shrinking models to make them more accessible without sacrificing their core capabilities. By converting complex floating-point weights into simpler integer values, quantization strikes a balance between performance and resource efficiency. This innovation democratises LLMs, allowing even consumer-grade hardware to harness their power.
The true potential of LLMs lies in finding this balance, much like our own evolution in language and communication.
By making these models more efficient, we open the door to a future where advanced AI is a tool for everyone, seamlessly integrated into our daily lives. As we refine and optimise these techniques, we pave the way for a new era of human-AI collaboration, unlocking possibilities we have yet to imagine!
Subscribe to my newsletter
Read articles from Hemanth Balgi directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by