OpenAI Swarm: A Hands-On Introduction to Multi-Agent Orchestration
 Rounak Show
Rounak Show
Introduction to OpenAI Swarm
Multi-agent orchestration is a trending topic in the field of large language models (LLMs). Instead of relying on a single, all-encompassing LLM, multi-agent systems employ a team of specialized agents, each designed to excel at a particular task. This approach allows for more complex and nuanced problem-solving, as agents can collaborate, share information, and leverage their individual strengths. OpenAI Swarm is an experimental framework designed to make multi-agent orchestration more accessible and user-friendly. Swarm is built on a practical, lightweight approach, prioritizing ease of use and clear, intuitive interactions between agents.
This blog post will provide a hands-on introduction to OpenAI Swarm, with a strong emphasis on practical examples using Python code. You will learn how to set up Swarm, create agents, implement handoffs, and build a simple multi-agent system along with LangChain integration. By the end, you'll have a solid understanding of how to leverage Swarm to build your own multi-agent LLM applications.
Setting Up OpenAI Swarm
To get started with OpenAI Swarm, you first need to install it. Make sure you have Python 3.10 or later installed on your system. You can install Swarm directly from the GitHub repository using the following command:
pip install git+ssh://git@github.com/openai/swarm.git
Or:
pip install git+https://github.com/openai/swarm.git
Next, you need to set up your OpenAI API key. This key allows Swarm to access OpenAI’s language models and other services. You can find your API key on the OpenAI website. Once you have your key, you can set it as an environment variable:
import os
os.environ['OPENAI_API_KEY'] = 'YOUR_OPENAI_API_KEY'
Replace ‘YOUR_OPENAI_API_KEY’ with your actual API key. With Swarm installed and your API key set up, you are ready to start building multi-agent systems!
Understanding Agents and Handoffs in OpenAI Swarm
In OpenAI Swarm, agents are the core building blocks of a multi-agent system. They encapsulate a set of instructions, functions, and the ability to hand off execution to other agents. Think of agents as specialized units, each responsible for a specific aspect of a larger task. For example, in a travel planning system, you could have separate agents for booking flights, hotels, and transportation.
Creating Agents and Handoffs in Python
You can create agents in Python using the Agent class from the swarm module. Here’s a basic example:
from swarm import Swarm, Agent
# creating handoffs functions
def handoff_to_weather_agent():
"""Transfer to the weather agent for weather queries."""
print("Handing off to Weather Agent")
return weather_agent
def handoff_to_math_agent():
"""Transfer to the math agent for mathematical queries."""
print("Handing off to Math Agent")
return math_agent
# Initialize the agents with specific roles
math_agent = Agent(
name="Math Agent",
instructions="You handle only mathematical queries.",
functions=[handoff_to_weather_agent]
)
weather_agent = Agent(
name="Weather Agent",
instructions="You handle only weather-related queries.",
functions=[handoff_to_math_agent]
)
In this example, two agents (math_agent and weather_agent) are created. Each agent has instructions specifying the types of queries they handle. Additionally, each agent has a handoff function, allowing them to delegate queries outside their area of expertise.
Handoffs Between Agents
Let’s see how these agents transfer control using the handoff mechanism. Here’s how the process works for mathematical and weather-related queries:
# Initialize the Swarm client
client = Swarm()
# Test handoff by asking a math question to the weather agent
messages = [{"role": "user", "content": "What is 2+2?"}]
handoff_response = client.run(agent=weather_agent, messages=messages)
print(handoff_response.messages[-1]["content"])
# Response:
# Handing off to Math Agent
# The answer to 2 + 2 is 4.
In this example, we intentionally send a math query ("What is 2+2?") to the weather_agent. The weather_agent detects this and hands off control to the math_agent, which provides the correct answer.
Handling a Weather Query
Now, let’s send a weather-related query to the math_agent and observe the handoff:
messages = [{"role": "user", "content": "How is the weather in Canada in December?"}]
response = client.run(agent=math_agent, messages=messages)
print(response.messages[-1]["content"])
# Response:
# Handing off to Weather Agent
# Canada generally experiences cold weather during December, with varying conditions depending on the region. Coastal areas like Vancouver may have milder temperatures, while areas like Toronto, Ottawa, and Montreal see cooler, snowy conditions. Northern regions experience extreme cold. Checking a reliable weather service will provide the most accurate information.
Here, the math_agent receives a weather-related query and hands it off to the weather_agent, which provides an overview of Canada’s typical December weather.
This example illustrates how agents can seamlessly collaborate to handle different types of queries, ensuring a flexible, adaptive multi-agent system.
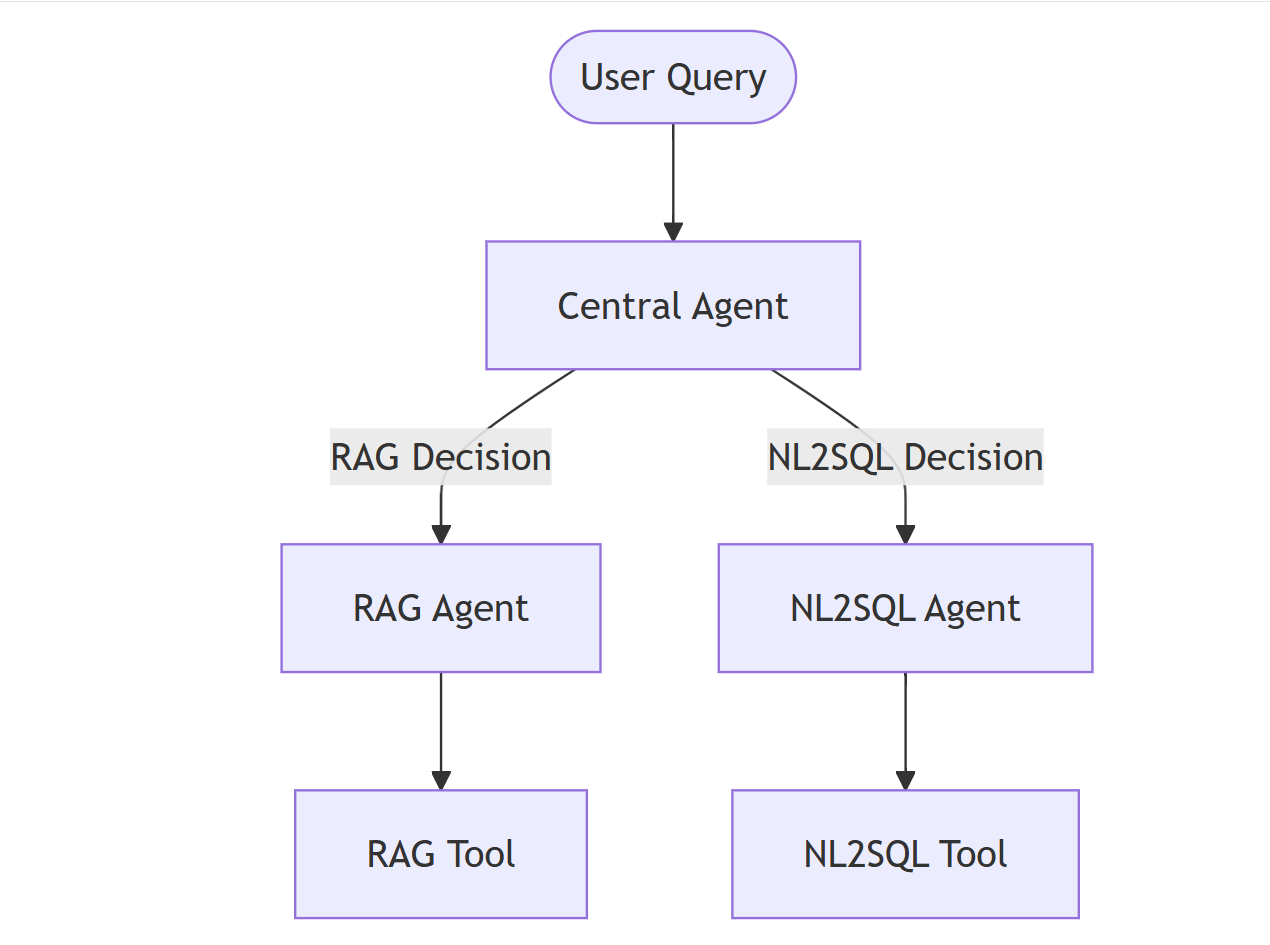
Creating and Orchestrating RAG and NL2SQL Agents with OpenAI Swarm
In this section, we will demonstrate how to set up two key agents: a RAG Agent for retrieval-augmented generation (RAG) and an NL2SQL Agent for querying a SQL database. These agents will collaborate to handle user queries based on their nature, either by retrieving relevant information from documents or by generating SQL queries to fetch results from a database. Finally, we will orchestrate the agents using a Central Agent that determines which agent should handle the query.
Step 1: Installing the Required Packages
Before getting started, make sure you have installed the necessary Python packages. You can install them using the following command:
pip install langchain langchain-chroma langchain-openai langchain-community pypdf sentence-transformers
Step 2: Loading and Splitting Documents for the RAG Agent
To create a RAG agent, you first need to load documents that contain the knowledge base. In this example, we load .pdf and .docx files from a folder and split them into smaller chunks for efficient retrieval.
from langchain_community.document_loaders import PyPDFLoader, Docx2txtLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.documents import Document
import os
def load_documents(folder_path: str) -> List[Document]:
documents = []
for filename in os.listdir(folder_path):
file_path = os.path.join(folder_path, filename)
if filename.endswith('.pdf'):
loader = PyPDFLoader(file_path)
elif filename.endswith('.docx'):
loader = Docx2txtLoader(file_path)
else:
print(f"Unsupported file type: {filename}")
continue
documents.extend(loader.load())
return documents
# Load documents from a folder
folder_path = "/content/docs"
documents = load_documents(folder_path)
print(f"Loaded {len(documents)} documents from the folder.")
# Split documents into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(documents)
print(f"Split the documents into {len(splits)} chunks.")
Step 3: Creating and Persisting a Vector Store
Next, we create a vector store using the SentenceTransformerEmbeddings to embed the document chunks for efficient retrieval.
from langchain_community.embeddings.sentence_transformer import SentenceTransformerEmbeddings
from langchain_chroma import Chroma
embedding_function = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
collection_name = "my_collection"
vectorstore = Chroma.from_documents(
collection_name=collection_name,
documents=splits,
embedding=embedding_function,
persist_directory="./chroma_db"
)
print("Vector store created and persisted to './chroma_db'")
Step 4: Creating the RAG Agent
We now set up the RAG Agent, which retrieves relevant document chunks and generates answers to user queries based on the retrieved context. Here's how the retrieval and generation are done:
from langchain_core.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini")
def retrieve_and_generate(question):
print("Calling retrieve_and_generate")
template = """Answer the question based only on the following context:
{context}
Question: {question}
Answer: """
prompt = ChatPromptTemplate.from_template(template)
def docs2str(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | docs2str, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
response = rag_chain.invoke(question)
return response
If you want to dive even deeper into practical implementations of Langchain and retrieval-augmented generation (RAG), don’t miss our detailed video tutorial on Langchain RAG Course: From Basics to Production-Ready RAG Chatbot. It provides step-by-step guidance for taking a Langchain project from concept to production.
Step 5: Setting up the NL2SQL Agent
Next, we create an NL2SQL Agent that handles natural language queries and converts them into SQL queries, executing them on a database.
Download and load the Chinook SQLite database:
!wget https://github.com/lerocha/chinook-database/raw/master/ChinookDatabase/DataSources/Chinook_Sqlite.sqlite !mv Chinook_Sqlite.sqlite Chinook.dbConnect to the Database: Use the
SQLDatabaseutility fromlangchain_communityto create a connection toChinook.db.from langchain_community.utilities import SQLDatabase db = SQLDatabase.from_uri("sqlite:///Chinook.db")Setup Environment Variables for Langsmith Tracing
import os os.environ["LANGCHAIN_TRACING_V2"] = "true" os.environ["LANGCHAIN_API_KEY"] = "your_langchain_api_key" os.environ["LANGCHAIN_PROJECT"] = "openai-swarm"Clean SQL Query Function: Define a helper function to clean up SQL queries by removing unnecessary markdown syntax. This is useful when you need to process queries embedded in code blocks.
def clean_sql_query(markdown_query): # Split the query into lines lines = markdown_query.strip().split('\n') # Remove markdown syntax lines cleaned_lines = [] for line in lines: # Skip lines that only contain backticks and optional language identifier if line.strip().startswith('```') or line.strip() == 'sql': continue cleaned_lines.append(line) # Join the remaining lines and clean up extra whitespace cleaned_query = ' '.join(cleaned_lines).strip() # Remove any remaining backticks cleaned_query = cleaned_query.replace('`', '') # Ensure semicolon at the end if not present if not cleaned_query.strip().endswith(';'): cleaned_query += ';' return cleaned_query # Example usage markdown_query = '''```sql SELECT * FROM table; ```''' cleaned_query = clean_sql_query(markdown_query) print(cleaned_query) # Cleaned Query # SELECT * FROM table;Set up the SQL Query Chain: Now, define the core logic of your SQL generation and execution process. This involves connecting LangChain components and defining a template to format the response based on the query results.
from langchain_core.prompts import ChatPromptTemplate from langchain.chains import create_sql_query_chain from langchain_community.tools.sql_database.tool import QuerySQLDataBaseTool from operator import itemgetter import re from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import PromptTemplate from langchain_core.runnables import RunnablePassthrough, RunnableLambda from langchain_openai import ChatOpenAI sql_prompt = ChatPromptTemplate.from_messages( [ ("system", "You are a SQLite expert expert. Given an input question, create a syntactically correct SQL query to run. Unless otherwise specificed.\n\nHere is the relevant table info: {table_info}\n\n Use max {top_k} rows"), ("human", "{input}"), ] ) llm = ChatOpenAI(model="gpt-4o") def sql_response_gen(question): print("Calling sql_response_gen") # remove_code_block_syntax = lambda text: re.sub(r"```(sql|)\s*(.*?)\s*```", r"\2", text, flags=re.DOTALL) execute_query = QuerySQLDataBaseTool(db=db) write_query = create_sql_query_chain(llm, db,sql_prompt) answer_prompt = PromptTemplate.from_template( """Given the following user question, corresponding SQL query, and SQL result, answer the user question. Question: {question} SQL Query: {query} SQL Result: {result} Answer: """ ) chain = ( RunnablePassthrough.assign(query=write_query | RunnableLambda(clean_sql_query)).assign( result=itemgetter("query") | execute_query ) | answer_prompt | llm | StrOutputParser() ) response = chain.invoke({"question": question}) return response
Let’s try the NL2SQL function
question = "How many customers are there?"
result = sql_response_gen(question)
print(f"Question: {question}")
print(f"Answer: {result}")
## Calling sql_response_gen
## Question: How many customers are there?
## Answer: There are 59 customers.
If you want to watch a detailed video on building NL2SQL chatbots, then watch this video:
Step 6: Orchestrating the Agents with a Central Agent
Now that we have both the RAG and NL2SQL tools, we can create RAG and NL2SQL agents and as well as the Central Agent that determines which agent should handle the user's query:
from swarm import Swarm, Agent
# Define the RAG and NL2SQL agents
rag_agent = Agent(
name="RAG Agent",
instructions="You retrieve relevant information from the company's knowledge base and generate responses to general queries about the company.",
functions=[retrieve_and_generate]
)
nl2sql_agent = Agent(
name="NL2SQL Agent",
instructions="You handle database queries.",
functions=[sql_response_gen]
)
# Define the Central Agent
central_agent = Agent(
name="Central Agent",
instructions="Determine if the query is about general company information (RAG) or a database query (NL2SQL), and route the query accordingly."
)
# Define handoff functions
def transfer_to_nl2sql():
print("Handing off to the NL2SQL Agent.")
"""Transfer the task to the NL2SQL Agent for database queries."""
return nl2sql_agent
def transfer_to_rag():
print("Handing off to the RAG agent.")
"""Transfer the task to the RAG Agent for general queries."""
return rag_agent
# Attach the handoff functions to the central agent
central_agent.functions = [transfer_to_nl2sql, transfer_to_rag]
Step 7: Running the Central Agent
Finally, we test the Central Agent with different user queries to see how it delegates tasks to the appropriate agent:
client = Swarm()
# Example 1: Asking about the company
print("\n--- Example 1: Asking about the company ---")
messages = [{"role": "user", "content": "What does Futuresmart AI offer?"}]
response = client.run(agent=central_agent, messages=messages)
if isinstance(response, Agent):
selected_agent = response
result = selected_agent.functions
print(result)
else:
print(response.messages[-1]["content"])
# Example 2: SQL query about employees
print("\n--- Example 2: Asking from the SQL DB ---")
messages = [{"role": "user", "content": "How many employees are there in the database?"}]
response = client.run(agent=central_agent, messages=messages)
if isinstance(response, Agent):
selected_agent = response
result = selected_agent.functions
print(result)
else:
print(response.messages[-1]["content"])
Output:
--- Example 1: Asking about the company ---
Handing off to the RAG agent.
Calling retrieve_and_generate
FutureSmart AI offers a range of services including customized speech-to-text services, Natural Language Processing (NLP) solutions, text classification, and the creation of custom chatbots. These services are designed to enhance productivity, accessibility, decision-making processes, and operational efficiency through advanced technologies and tailored solutions.
--- Example 2: Asking from the SQL DB ---
Handing off to the NL2SQL Agent.
Calling sql_response_gen
There are 8 employees in the database.
Find all the Python Code Here: OpenAI Swarm Notebook
Conclusion
OpenAI Swarm represents a valuable contribution to the growing field of multi-agent LLM frameworks. Its lightweight design and focus on user-friendliness make it a great starting point for developers exploring multi-agent orchestration. Swarm simplifies the process of building multi-agent systems with its straightforward approach to defining agents, their capabilities, and their interactions. The handoff mechanism, as illustrated in our previous examples, enables seamless transitions between agents, facilitating complex workflows.
However, it's crucial to recognize that Swarm is still in its experimental stages and primarily serves educational purposes. This means it may not possess the robust features or extensive functionalities of more established frameworks like LangChain, or CrewAI. For instance, Swarm's reliance solely on the OpenAI API may limit its flexibility and integration capabilities. Moreover, the absence of built-in memory management could pose challenges to making personalized agents.
If you found this guide helpful and you're looking to learn more then don’t forget to follow us.
If you're looking to further enhance your skills in multi-agent app development with a more robust framework, I recommend checking out our LangGraph Tutorial for Beginners
At FutureSmart AI, we specialize in helping companies build cutting-edge AI solutions similar to the ones discussed in this blog. To explore how we can assist your business, feel free to reach out to us at contact@futuresmart.ai.
For real-world examples of our work, take a look at our case studies, where we showcase the practical value of our expertise.
Subscribe to my newsletter
Read articles from Rounak Show directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Rounak Show
Rounak Show
Learning Data Science and Sharing the journey through Hashnode.