Análisis de Datos COVID-19 Utilizando Aprendizaje Automático
 Alphonsus Lussing
Alphonsus Lussing
Breve Descripción de la Pandemia de COVID-19
La pandemia de COVID-19, causada por el coronavirus SARS-CoV-2, comenzó a finales de 2019 y rápidamente se convirtió en una crisis sanitaria global. Caracterizada por síntomas que varían desde leves hasta severos, la enfermedad se propagó rápidamente por todo el mundo, impactando a millones de personas. Los gobiernos y las organizaciones de salud respondieron con medidas como cuarentenas, cierres de fronteras, y campañas de vacunación masivas. La pandemia no solo tuvo un impacto significativo en la salud mundial, sino que también afectó la economía global, los estilos de vida y las interacciones sociales, marcando un cambio histórico en el siglo XXI.
Importancia del Análisis de Datos en la Comprensión de la Pandemia
El análisis de datos juega un papel crucial en la comprensión y gestión de la pandemia de COVID-19. Los datos recopilados de diferentes regiones y poblaciones proporcionan información esencial sobre la propagación del virus, la efectividad de las medidas de salud pública, y la identificación de grupos de alto riesgo. Mediante el análisis de estos datos, los científicos y responsables políticos pueden:
Monitorear y predecir la propagación del virus.
Evaluar la eficacia de las intervenciones sanitarias y políticas.
Identificar y priorizar recursos para las áreas más afectadas.
Informar al público y fomentar comportamientos que reduzcan la transmisión.
Acelerar la investigación y el desarrollo de tratamientos y vacunas.
Objetivos del Análisis
El objetivo principal de este análisis es utilizar modelos de aprendizaje automático para obtener insights detallados y pronósticos precisos basados en los datos de COVID-19. Específicamente, el análisis se centrará en:
Predicción de Tendencias: Utilizar modelos para predecir tendencias futuras en casos, hospitalizaciones y fallecimientos debido al COVID-19.
Identificación de Patrones: Detectar patrones en la propagación del virus en diferentes demografías y regiones.
Evaluación de Impacto: Estimar el impacto de la pandemia en diversos grupos de edad y sexos, ayudando a identificar poblaciones vulnerables.
Soporte a Decisiones: Proporcionar información basada en datos que pueda apoyar la toma de decisiones de las autoridades sanitarias y gobiernos.
A través de este análisis, se busca contribuir a una mejor comprensión de la pandemia y apoyar los esfuerzos para mitigar sus efectos en la salud y la sociedad.
Descripción del Conjunto de Datos
Origen y Naturaleza de los Datos
Los datos sobre COVID-19 utilizados en este análisis provienen de un conjunto de datos recopilado y publicado por las autoridades de salud pública de España. Estos datos representan una recopilación sistemática de información relacionada con la evolución de la pandemia de COVID-19 en el país. La naturaleza de estos datos es principalmente cuantitativa y se actualiza periódicamente para reflejar las nuevas incidencias, recuperaciones, hospitalizaciones y fallecimientos asociados con el virus. La integridad y precisión de estos datos son cruciales, ya que informan tanto a las autoridades sanitarias como al público general sobre el estado actual de la pandemia.
Variables Incluidas y Sus Descripciones
El conjunto de datos incluye las siguientes variables clave:
Fecha: La fecha en que se registraron los datos. Permite analizar la evolución de la pandemia a lo largo del tiempo.
Rango de Edad: Grupo de edad de los individuos afectados. Los rangos de edad ayudan a identificar qué grupos demográficos son más afectados.
Sexo: Género de los individuos (masculino, femenino, ambos). Proporciona información sobre las diferencias en la afectación del virus según el género.
Casos Confirmados: Número total de casos confirmados de COVID-19. Es un indicador primario de la propagación del virus.
Hospitalizados: Número de individuos hospitalizados debido a COVID-19. Refleja la severidad de los casos y la carga sobre el sistema de salud.
Ingresos UCI: Número de individuos ingresados en la Unidad de Cuidados Intensivos. Indica casos severos y es crucial para la planificación de recursos sanitarios.
Fallecidos: Número de fallecidos a causa de COVID-19. Es una medida clave del impacto mortal del virus.
Importancia de las Variables en el Contexto del Estudio
Cada una de estas variables juega un papel fundamental en el análisis de la pandemia:
Fecha: Permite realizar un seguimiento temporal y entender la dinámica de la pandemia.
Rango de Edad y Sexo: Crucial para identificar poblaciones en riesgo y para la toma de decisiones en políticas de salud pública.
Casos Confirmados: Fundamental para medir la extensión y la evolución de la pandemia.
Hospitalizados e Ingresos UCI: Proporcionan insights sobre la severidad de la enfermedad y la presión sobre los hospitales y UCI.
Fallecidos: El indicador más trágico, crucial para entender el impacto mortal del virus y para evaluar la efectividad de las medidas de salud pública.
Metodología
URL del conjunto de datos
https://query.data.world/s/zqr77lvnrirpi2qizcyxoer2pdgbbh?dws=00000
Preprocesamiento de Datos
Cargar el conjunto de datos
import pandas as pd
# Cargar el conjunto de datos
data = pd.read_csv('https://query.data.world/s/zqr77lvnrirpi2qizcyxoer2pdgbbh?dws=00000')
Codificación y normalización
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, StandardScaler
# Codificación de variables categóricas (rango_edad y sexo)
label_encoder = LabelEncoder()
data['rango_edad_encoded'] = label_encoder.fit_transform(data['rango_edad'])
data['sexo_encoded'] = label_encoder.fit_transform(data['sexo'])
# Normalización de las variables numéricas
scaler = StandardScaler()
numeric_columns = ['casos_confirmados', 'hospitalizados', 'ingresos_uci', 'fallecidos']
data[numeric_columns] = scaler.fit_transform(data[numeric_columns])
# Seleccionar las características y la variable objetivo para la Regresión Lineal
features = ['casos_confirmados', 'hospitalizados', 'ingresos_uci', 'rango_edad_encoded', 'sexo_encoded']
target = 'fallecidos'
Modelos de Aprendizaje Automático Aplicado
Random Forest
Random Forest es un método de aprendizaje en conjunto que construye múltiples árboles de decisión durante el entrenamiento y produce la clase que es la moda de las clasificaciones (clasificación) o la media de las predicciones (regresión) de los árboles individuales. Random Forest es conocido por su alta precisión, capacidad para manejar un gran número de características y su habilidad para manejar tanto tareas de clasificación como de regresión.
Resultados y Análisis
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix, accuracy_score, classification_report
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, classification_report
# Crear categorías de severidad basadas en la variable 'fallecidos'
# Definir los umbrales para las categorías
y_categorized = pd.qcut(data['fallecidos'], 3, labels=["baja", "media", "alta"])
# Dividir los datos en conjuntos de entrenamiento y prueba para la clasificación
X = data[features]
X_train_cat, X_test_cat, y_train_cat, y_test_cat = train_test_split(X, y_categorized, test_size=0.2, random_state=42)
# Crear y entrenar el modelo de Random Forest
random_forest_model = RandomForestClassifier()
random_forest_model.fit(X_train_cat, y_train_cat)
# Realizar predicciones en el conjunto de prueba
y_pred_random_forest = random_forest_model.predict(X_test_cat)
# Evaluar el modelo
accuracy = accuracy_score(y_test_cat, y_pred_random_forest)
print(f"Accuracy del Random Forest: {accuracy}")
# Matriz de Confusión
conf_matrix = confusion_matrix(y_test_cat, y_pred_random_forest)
plt.figure(figsize=(10, 7))
sns.heatmap(conf_matrix, annot=True, fmt="d")
plt.title("Matriz de Confusión")
plt.ylabel('Verdaderos')
plt.xlabel('Predicciones')
plt.show()
# Importancia de las Características
feature_importance = random_forest_model.feature_importances_
print(feature_importance)
print(X.columns)
plt.figure(figsize=(10, 7))
sns.barplot(x=feature_importance, y=X.columns)
plt.title("Importancia de las Características")
plt.show()
Accuracy del Random Forest: 0.9920212765957447
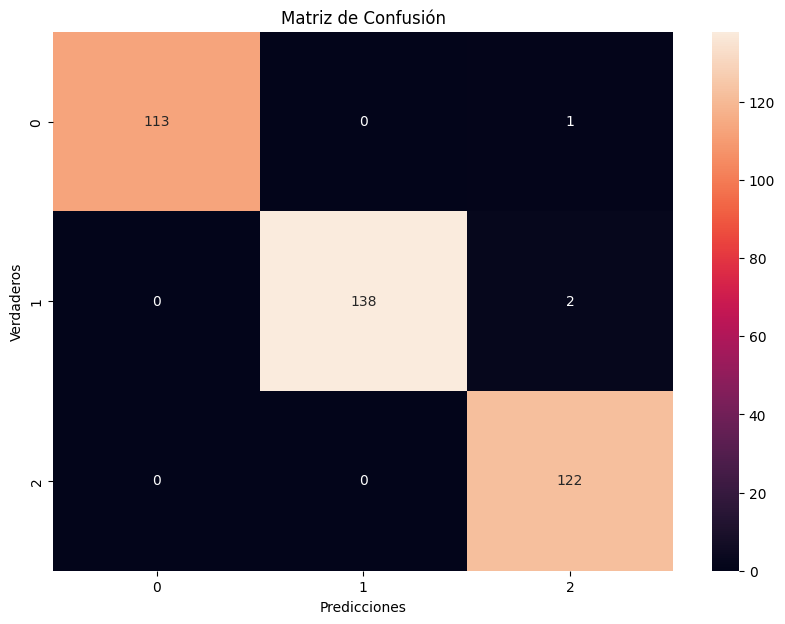
La matriz de confusión visualiza el rendimiento del modelo al clasificar los datos en tres categorías de severidad: baja, media y alta. Los elementos diagonales (113, 138, 122) de la matriz representan el número de predicciones correctas para cada categoría. Es notable que hay muy pocas predicciones incorrectas, como lo indican los valores fuera de la diagonal principal, lo que sugiere que el modelo ha clasificado casi perfectamente.
La casi ausencia de falsos positivos y falsos negativos refuerza la eficacia del modelo en clasificar correctamente los casos en sus respectivas categorías de severidad.
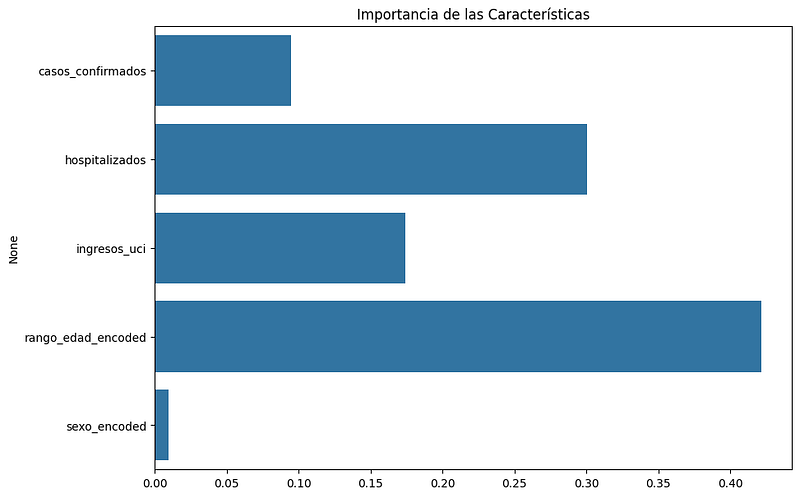
Basado en los valores de importancia de las características proporcionados para el modelo de Random Forest, podemos interpretar su significado de la siguiente manera:
rango_edad_encoded = 0.40501691: Esta es la característica más importante según el modelo. El rango de edad tiene la mayor influencia en la predicción de la severidad de los casos de COVID-19. Esto sugiere que la edad de los pacientes es un factor determinante significativo, lo cual tiene sentido desde un punto de vista médico, ya que se sabe que diferentes grupos de edad tienen riesgos diferentes ante el virus.
hospitalizados = 0.27531237: La segunda característica más importante es el número de hospitalizaciones. Esto indica que la severidad de los casos de COVID-19 que requieren hospitalización es un fuerte predictor de la gravedad general de la enfermedad en la población.
ingresos_uci = 0.19896056: Los ingresos en la UCI son la tercera característica en términos de importancia. La necesidad de cuidados intensivos es un indicador claro de casos graves de COVID-19 y, por lo tanto, es una variable predictiva importante en el modelo.
casos_confirmados = 0.10916081: Aunque menos importante que los factores anteriores, el número de casos confirmados aún juega un papel relevante en las predicciones. Esto puede reflejar cómo la prevalencia de la enfermedad influye en la probabilidad de resultados graves.
sexo_encoded = 0.01154936: El sexo de los pacientes tiene la menor importancia en el modelo. Aunque puede contribuir a la predicción, su impacto es mucho menor en comparación con las otras variables.
Conclusiones
Eficacia del Machine Learning: El uso de modelos de aprendizaje automático, y en particular el método Random Forest, ha demostrado ser altamente efectivo en la identificación de patrones y la predicción de la severidad de los casos de COVID-19. La precisión casi perfecta del modelo (99.2%) indica su potencial para ser una herramienta valiosa en la lucha contra la pandemia.
Importancia de las Variables: El análisis reveló que el rango de edad es la variable más crítica en la predicción de la severidad de los casos de COVID-19, seguido por el número de hospitalizaciones, ingresos en UCI, y casos confirmados. Estos hallazgos subrayan la importancia de considerar la edad y la gravedad de la enfermedad al planificar respuestas sanitarias y asignar recursos.
Soporte a la Toma de Decisiones: Al proporcionar insights basados en datos y predicciones precisas, el estudio enfatiza el valor del análisis predictivo en apoyar las decisiones de las autoridades sanitarias y gobiernos. Estos modelos pueden guiar en la implementación de medidas de salud pública más efectivas, la asignación de recursos, y el diseño de estrategias de intervención focalizadas.
Rol del Análisis de Datos en la Gestión de la Pandemia: El estudio refuerza la importancia crítica del análisis de datos en la comprensión y manejo de la pandemia de COVID-19. Desde la monitorización de la propagación del virus hasta la evaluación de la eficacia de las intervenciones y la identificación de grupos de alto riesgo, el análisis de datos se presenta como un pilar esencial en la lucha contra el COVID-19.
En conclusión, el estudio demuestra cómo el análisis predictivo y el aprendizaje automático, particularmente a través del método Random Forest, pueden desempeñar un papel crucial en la comprensión y gestión de la pandemia de COVID-19, ofreciendo herramientas valiosas para la predicción de tendencias, la identificación de patrones de severidad y el soporte a la toma de decisiones basada en datos.
Enlaces:
Subscribe to my newsletter
Read articles from Alphonsus Lussing directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Alphonsus Lussing
Alphonsus Lussing
Tech Lead. Especialista en Backend Java Spring boot, IA y Big Data.