Airflow: An Introduction
 Sai Prasanna Maharana
Sai Prasanna Maharana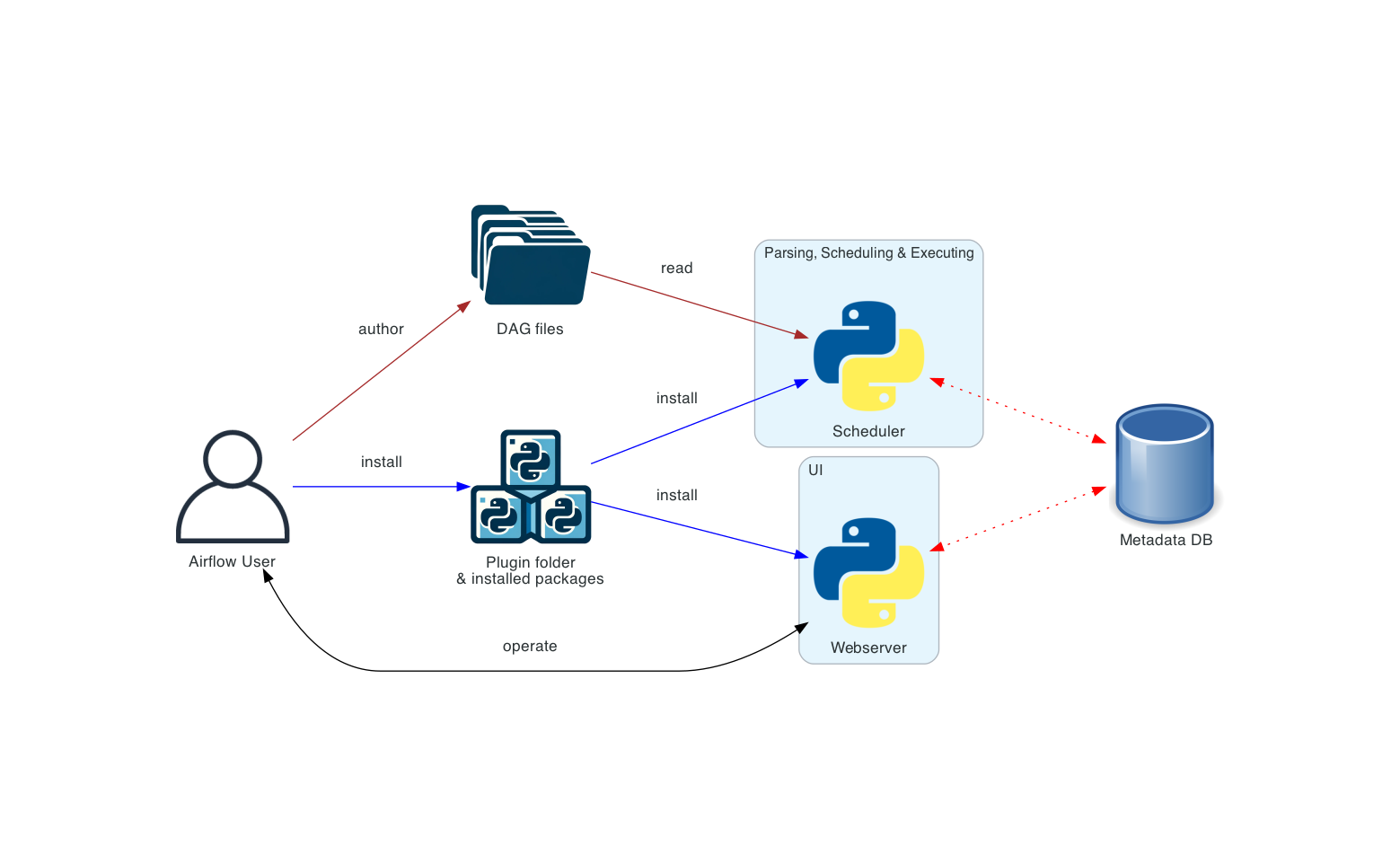
What is Apache Airflow?
Apache Airflow is an open-source platform to programmatically author, schedule, and monitor workflows. It allows you to create dynamic, extensible, and scalable workflows as code, ensuring maintainability, versioning, testing, and collaboration.
Why Use Airflow?
Dynamic Pipelines: Define workflows in Python code for flexibility.
Scalability: Manage complex workflows with hundreds of tasks.
Extensibility: Integrate with various services using built-in operators.
Monitoring & Scheduling: Visualize and track workflows using a rich UI.
Key Concepts of Airflow
DAG (Directed Acyclic Graph): A collection of tasks with dependencies.
Task: A unit of work in a DAG, represented by an operator.
Operator: Defines what action a task will perform (e.g., PythonOperator, BashOperator).
Task Instance: An execution instance of a task at a point in time.
Scheduler: Monitors DAGs and triggers task instances when dependencies are met.
Executor: Determines how tasks are executed (locally, in parallel, etc.).
Setting Up Airflow
Prerequisites
Python 3.6+
pip (Python package manager)
Installation Steps
1. Create a Virtual Environment (Optional but Recommended)
python3 -m venv airflow_env
source airflow_env/bin/activate
2. Install Apache Airflow
pip install apache-airflow
3. Set the AIRFLOW_HOME Environment Variable
By default, Airflow uses ~/airflow as its home directory. You can set a custom path:
export AIRFLOW_HOME=~/airflow
4. Initialize the Airflow Metadata Database
airflow db init
5. Create an Admin User
airflow users create \
--username admin \
--firstname Admin \
--lastname User \
--role Admin \
--email admin@example.com \
--password admin123
Starting Airflow Services
Start the Webserver
airflow webserver --port 8080
Start the Scheduler
Open a new terminal window and activate the virtual environment if used.
airflow scheduler
Access the Airflow UI
Navigate to http://localhost:8080 in your web browser and log in with the admin credentials.
Creating a Basic ETL Pipeline with Airflow
Overview
We will build an ETL pipeline that:
Extracts data from a CSV file.
Transforms the data (e.g., multiplies a column by 10).
Loads the transformed data into a new CSV file.
Step-by-Step Guide
1. Prepare the Data
Create a directory for data files:
mkdir -p $AIRFLOW_HOME/data
Create an input CSV file named input_data.csv in $AIRFLOW_HOME/data:
id,value
1,100
2,200
3,300
2. Create the ETL DAG
Create a new DAG file in $AIRFLOW_HOME/dags:
mkdir -p $AIRFLOW_HOME/dags
touch $AIRFLOW_HOME/dags/etl_pipeline.py
Add the following code to etl_pipeline.py:
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime, timedelta
import pandas as pd
import os
# Define default arguments
default_args = {
'owner': 'airflow',
'start_date': datetime(2021, 1, 1),
'retries': 1,
'retry_delay': timedelta(minutes=5),
}
# Define the DAG
dag = DAG(
'simple_etl_pipeline',
default_args=default_args,
description='A simple ETL pipeline',
schedule_interval=timedelta(days=1),
catchup=False,
)
# Define task functions
def extract(**kwargs):
ti = kwargs['ti']
df = pd.read_csv(f"{os.environ['AIRFLOW_HOME']}/data/input_data.csv")
ti.xcom_push(key='extracted_data', value=df.to_json())
def transform(**kwargs):
ti = kwargs['ti']
extracted_data = ti.xcom_pull(key='extracted_data', task_ids='extract')
df = pd.read_json(extracted_data)
df['value'] = df['value'] * 10
ti.xcom_push(key='transformed_data', value=df.to_json())
def load(**kwargs):
ti = kwargs['ti']
transformed_data = ti.xcom_pull(key='transformed_data', task_ids='transform')
df = pd.read_json(transformed_data)
df.to_csv(f"{os.environ['AIRFLOW_HOME']}/data/output_data.csv", index=False)
print("Data loaded successfully.")
# Define tasks
extract_task = PythonOperator(
task_id='extract',
python_callable=extract,
provide_context=True,
dag=dag,
)
transform_task = PythonOperator(
task_id='transform',
python_callable=transform,
provide_context=True,
dag=dag,
)
load_task = PythonOperator(
task_id='load',
python_callable=load,
provide_context=True,
dag=dag,
)
# Set task dependencies
extract_task >> transform_task >> load_task
Explanation:
DAG: Defines the workflow with default arguments and schedule.
Tasks:
extract,transform, andloadfunctions wrapped inPythonOperator.XComs: Used to pass data between tasks (
xcom_pushandxcom_pull).Environment Variable:
os.environ['AIRFLOW_HOME']ensures paths are dynamic.
3. Enable the DAG
Restart the Airflow services if necessary.
In the Airflow UI, locate
simple_etl_pipelineand toggle it to ON.
4. Trigger the DAG
- In the DAG's page, click on Trigger DAG to run it immediately.
5. Monitor Execution
Use the Graph View and Tree View to monitor task execution.
Check logs for each task by clicking on it and selecting View Log.
6. Verify the Output
Check the output_data.csv file in $AIRFLOW_HOME/data:
id,value
1,1000
2,2000
3,3000
End-to-End Functionality of Airflow
Workflow Execution
DAG Parsing: Airflow scans the
dagsfolder and parsesetl_pipeline.py.Scheduling: Based on
schedule_interval, Airflow schedules DAG runs.Task Execution:
Extract Task:
Reads
input_data.csv.Pushes data to XComs.
Transform Task:
Pulls data from XComs.
Transforms the data.
Pushes transformed data to XComs.
Load Task:
Pulls transformed data from XComs.
Writes data to
output_data.csv.
Monitoring:
Airflow UI displays task statuses.
Logs provide detailed execution information.
Error Handling:
Retries are configured (
retries: 1,retry_delay: 5 minutes).Failures can be diagnosed via logs.
Data Passing with XComs
XComs (Cross-Communications):
Allow tasks to exchange small amounts of data.
Not suitable for large datasets; use external storage if needed.
Usage:
xcom_push(key, value): Pushes data.xcom_pull(key, task_ids): Retrieves data from a specific task.
Airflow Operators
PythonOperator: Executes a Python callable.
BashOperator: Executes a bash command.
Others:
EmailOperator, MySqlOperator, HttpSensor, etc.
Custom operators can be created for specific needs.
Airflow Commands Explained
Initialization
Initialize Database:
airflow db initCreate User:
airflow users create \ --username admin \ --firstname Admin \ --lastname User \ --role Admin \ --email admin@example.com \ --password admin123
Starting Services
Webserver:
airflow webserver --port 8080Scheduler:
airflow scheduler
DAG Management
List All DAGs:
airflow dags listTrigger a DAG:
airflow dags trigger simple_etl_pipelinePause/Unpause a DAG:
airflow dags pause simple_etl_pipeline airflow dags unpause simple_etl_pipelineList Tasks in a DAG:
airflow tasks list simple_etl_pipeline
Task Management
Run a Task Manually:
airflow tasks run simple_etl_pipeline extract 2021-01-01Test a Task (without affecting state):
airflow tasks test simple_etl_pipeline extract 2021-01-01
Viewing Logs
View Task Logs:
airflow tasks logs simple_etl_pipeline extract 2021-01-01
Miscellaneous
Clear Task Instances:
airflow tasks clear simple_etl_pipeline --start-date 2021-01-01 --end-date 2021-01-02Restart Airflow Scheduler:
pkill -f "airflow scheduler" airflow scheduler
Quick Revision Notes
Key Concepts
Airflow: Platform to programmatically author, schedule, and monitor workflows.
DAG: Defines a workflow; tasks and their dependencies.
Task: Individual unit of work.
Operator: Defines what action a task performs.
Scheduler: Triggers tasks based on DAG definitions.
Executor: Runs tasks (e.g., SequentialExecutor, LocalExecutor).
Workflow Creation Steps
Define the DAG:
Import necessary modules.
Set default arguments.
Define the DAG with a unique
dag_id.
Define Tasks:
Create Python functions for tasks.
Wrap functions with operators (e.g.,
PythonOperator).
Set Task Dependencies:
- Use
>>and<<to set the execution order.
- Use
Place DAG in
dagsDirectory:- Airflow automatically detects DAGs in this folder.
Essential Commands
Initialize DB:
airflow db initCreate User:
airflow users create ...Start Webserver:
airflow webserverStart Scheduler:
airflow schedulerList DAGs:
airflow dags listTrigger DAG:
airflow dags trigger <dag_id>Pause DAG:
airflow dags pause <dag_id>Unpause DAG:
airflow dags unpause <dag_id>List Tasks:
airflow tasks list <dag_id>Run Task:
airflow tasks run <dag_id> <task_id> <execution_date>Test Task:
airflow tasks test <dag_id> <task_id> <execution_date>
Best Practices
Version Control: Keep DAGs under version control (e.g., Git).
Idempotency: Ensure tasks can run multiple times without adverse effects.
Avoid Heavy Processing in DAG Files: DAG files should be lightweight; heavy computations should be in task functions.
Use Connections: Store credentials and connection info securely in Airflow Connections.
Monitor Resource Usage: Be mindful of resource constraints, especially when scaling up.
Remember: Airflow allows for flexible and powerful workflow management. By defining workflows as code, you gain the benefits of code versioning, modularity, and scalability. Practice building different DAGs, explore various operators, and get comfortable with Airflow's UI and CLI to harness its full potential.
Subscribe to my newsletter
Read articles from Sai Prasanna Maharana directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by