DynamoDB: conceitos importantes
 Marcelo Amorim
Marcelo AmorimTable of contents
- 🌟 Breve Introdução ao DynamoDB
- → Tipos de dados suportados pelo DynamoDB
- 🔑 Partition Key (Chave de Partição)
- 🔑 Sort Key
- 🔍 Global Secondary Index
- 🔍 Local Secondary Index
- → RCU (read capacity unit)
- → WRU (write capacity unit)
- 🚀 Capacidade de Throughput no DynamoDB
- → DynamoDB Streams
- 🔎 Scan vs Query no DynamoDB
- Links para Documentação
🌟 Breve Introdução ao DynamoDB
O DynamoDB é um serviço de banco de dados não relacional totalmente gerenciado oferecido pela AWS. Suas principais características o tornam uma escolha ideal para aplicações modernas que exigem alta performance e escalabilidade. Confira alguns destaques:
🚀 Serverless: Escalabilidade automática, sem necessidade de gerenciar servidores.
⚡ Baixa Latência: Respostas rápidas para aplicações em tempo real.
📈 Capacidade de Throughput: Configuração de capacidade on-demand ou provisionada.
💪 Alto Desempenho: Ótima solução para cargas de trabalho intensivas e de grande escala.
🔗 Integração Fácil com AWS: Conecte-se facilmente a diversos serviços da AWS. Veja alguns exemplos no Serverless Land.
Este resumo captura alguns dos conceitos iniciais do DynamoDB, com base na documentação oficial da AWS, para oferecer uma visão rápida de suas principais vantagens.
→ Tipos de dados suportados pelo DynamoDB
Antes de começarmos a falar sobre nossa chave de partição e outros conceitos, deixo aqui um breve resumo sobre os tipos de dados suportados por esse banco de dados. O Amazon DynamoDB oferece suporte a uma variedade de tipos de dados, permitindo flexibilidade no armazenamento. Esses tipos são classificados em três categorias principais:
Escalares:
String (S): Texto, com limite de 400 KB.
Number (N): Valores numéricos, incluindo inteiros e decimais, representados com até 38 dígitos de precisão.
Binary (B): Dados binários, como arquivos e imagens, com limite de 400 KB.
Boolean: Valores
trueoufalse.Null: Representa valores nulos.
Documentos:
Map: Estruturas tipo chave-valor, permitindo dados aninhados.
List: Arrays de valores, que podem incluir qualquer combinação de tipos de dados, inclusive listas e mapas aninhados.
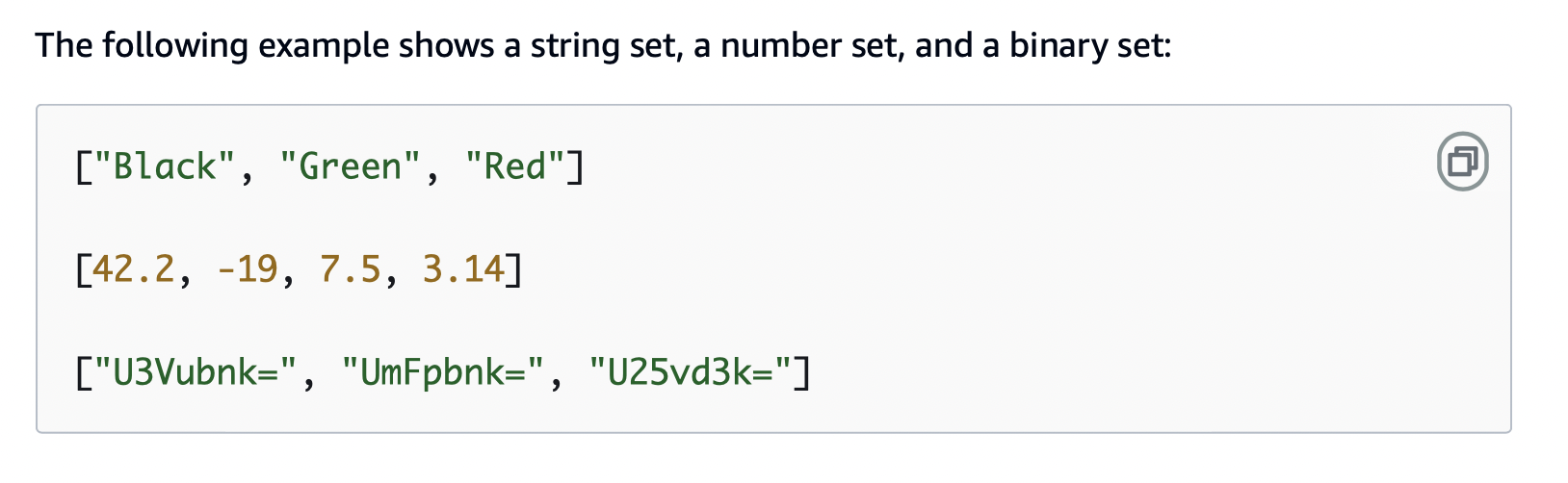
Conjuntos:
String Set (SS): Conjunto de strings sem valores duplicados.
Number Set (NS): Conjunto de números únicos.
Binary Set (BS): Conjunto de dados binários, sem valores duplicados.
Observação importante - importante ressaltar qual o conceito de binário utilizado nesse contexto:

Por fim, esses tipos de dados dão ao DynamoDB uma estrutura flexível, permitindo desde dados simples até objetos complexos e aninhados. Para mais informações detalhadas, confira a documentação oficial em Documentação de Tipos de Dados do DynamoDB.
🔑 Partition Key (Chave de Partição)
A chave de partição (partition key) é essencial para o DynamoDB, pois determina em qual partição física – armazenada em SSDs – cada item será guardado. Esse conceito permite que o DynamoDB distribua dados de forma eficiente.
Segundo a documentação da AWS:
"O DynamoDB usa o valor da chave de partição como entrada para uma função de hash interna. A saída da função de hash determina a partição (armazenamento físico interno do DynamoDB) em que o item será armazenado. Todos os itens com o mesmo valor de chave de partição são armazenados juntos, na ordem classificada por valor de chave de classificação."
Em resumo, todos os itens com a mesma partition key são armazenados juntos, ordenados pelo valor da sort key (quando existe). Isso permite o rápido acesso a dados que compartilham uma mesma chave de partição, otimizando consultas e operações de leitura/escrita no banco.
Para mais informações sobre o funcionamento da partition key, consulte a documentação oficial do DynamoDB.

Na nota abaixo, também retirada do link acima, fica a explicação da razão pela qual vemos a PK (partition key) sendo chamada de hash attribute e a SK (sort key) de range attribute.

- Quer algumas dicas de como escolher sua partition key? A documentação tem ótimas dicas.
Da própria documentação do DynamoDB, vejamos uma representação gráfica de como os itens são distribuídos em partições - conhecer como é feita essa distribuição ajuda bastante na hora de pensarmos na abordagem que utilizaremos para a modelagem de nossa(s) tabela(s):

🔑 Sort Key
A sort key é uma chave de classificação (na tradução da documentação - deixo abaixo a variedade de possibilidades de tradução para a palavra sort, usualmente utilizada como ordenação) que organiza itens dentro de uma mesma partição de forma sequencial, facilitando buscas específicas e consultas em intervalos. Essa chave é também chamada de range attribute, pois define a sequência e o alcance dos itens armazenados dentro de uma partição associada a uma partition key (ou hash attribute). Com a sort key, consultas podem ser feitas utilizando operadores como BETWEEN, >, <, e >=, permitindo filtragens ordenadas e precisas.
- possibilidades de tradução da palavra sort (linguee):

🔍 Global Secondary Index
Este índice pode ser criado a qualquer momento (não é obrigatório criar durante a criação da tabela como o LSI).
Suporte para uma combinação de partition key e sort key distinta da tabela principal.
Consistência eventual: leituras são eventualmente consistentes.
Limite de 20 global secondary indexes por tabela.

🔍 Local Secondary Index
O Local Secondary Index (LSI) permite criar uma visão alternativa da tabela principal, com uma nova configuração de sort key sem alterar a partition key. Este índice é ideal para realizar consultas adicionais em dados já armazenados, utilizando diferentes critérios de ordenação.
Principais características:
Criação no momento da tabela: O LSI deve ser criado junto com a tabela; não pode ser adicionado posteriormente.
Mesma partition key da tabela principal: A partition key do LSI deve ser idêntica à da tabela principal, mas permite definir uma sort key alternativa.
Consistência forte: Leituras no LSI são sempre consistentes, garantindo que os dados lidos reflitam as últimas alterações.
Limite de 5 LSIs por tabela: Cada tabela pode ter no máximo 5 LSIs, sendo um recurso finito a ser planejado de acordo com as necessidades de consultas.
O LSI é útil para casos em que diferentes ordenações dos dados são necessárias sem alterar a estrutura de partições.
→ RCU (read capacity unit)
Unidade de capacidade de leitura
Unidade de capacidade de leitura no DynamoDB. Uma unidade de capacidade de leitura (RCU) permite uma leitura fortemente consistente de até 4 KB por segundo, ou uma leitura eventualmente consistente de até 4 KB duas vezes por segundo. As RCUs devem ser dimensionadas de acordo com a carga esperada de leituras e o tamanho dos itens a serem lidos.
Em resumo, (a) Se for fortemente consistente, uma leitura de até 4 KB/s. Se for eventualmente consistente, duas leituras de até 4KB/s. Documentação
→ WRU (write capacity unit)
Unidade de capacidade de escrita
Uma unidade de capacidade de escrita (WCU) permite uma escrita de até 1 KB por segundo para um item na tabela. Documentação

🚀 Capacidade de Throughput no DynamoDB
O DynamoDB oferece duas opções principais para gerenciar a capacidade de throughput, garantindo flexibilidade e escalabilidade para atender a diferentes padrões de uso:
Capacidade Sob Demanda (On-Demand):
Ideal para cargas de trabalho imprevisíveis ou com variações extremas.
O DynamoDB automaticamente aloca e ajusta a capacidade para atender a picos de demanda.
Não exige planejamento prévio de RCUs (Read Capacity Units) e WCUs (Write Capacity Units).
Pagamento por solicitação, garantindo que você pague apenas pelo que usar.
Capacidade Provisionada (Provisioned):
Mais econômica para cargas de trabalho constantes e previsíveis.
Permite definir manualmente o número de RCUs e WCUs, com a opção de Auto Scaling para ajustar automaticamente a capacidade quando a demanda aumenta.
RCU (Read Capacity Unit): Cada RCU permite ler até 4 KB duas vezes por segundo para leitura eventualmente consistente, ou 4 KB a cada segundo para leitura fortemente consistente.
WCU (Write Capacity Unit): Cada WCU permite escrever até 1 KB por segundo.
Configurar corretamente o throughput evita throttling e reduz custos em cargas previsíveis.

A escolha entre capacidade on-demand e provisionada depende das necessidades específicas da aplicação, sendo a on-demand ideal para cargas variáveis e a provisionada para cargas estáveis (com a flexibilidade do autoscaling).
Para mais detalhes sobre o gerenciamento de throughput, consulte a documentação oficial.
→ DynamoDB Streams
Definição: Permite a geração de um stream de eventos a partir da modificação de dados na tabela.
DynamoDB Streams é um recurso que captura alterações em uma tabela do DynamoDB em tempo real. Cada vez que um item na tabela é inserido, atualizado ou excluído, o DynamoDB Streams registra essa modificação e permite que outras aplicações acessem esses eventos de mudança. Cada alteração é mantida no stream por até 24 horas e pode ser consumida por serviços como o AWS Lambda, possibilitando o processamento automático dessas mudanças.

- Desenho explicativo presente na documentação:

🔎 Scan vs Query no DynamoDB
No DynamoDB, as operações de scan e query são usadas para recuperar dados das tabelas, mas funcionam de maneiras muito diferentes e apresentam custos distintos, especialmente em tabelas de grande porte. Entender quando usar cada uma pode ter um impacto significativo em performance e custo.
🚀 Query
A query é uma operação eficiente, focada em recuperar itens específicos a partir de uma partition key (e, opcionalmente, uma sort key). Como a query busca apenas os dados em uma partição específica, o consumo de recursos é reduzido, tornando-a a escolha mais econômica para consultas direcionadas.
Eficiência: Como a query acessa apenas uma partição, evita percorrer dados desnecessários.
Consistência: Pode ser configurada para leitura fortemente consistente ou eventualmente consistente, sendo que esta última consome metade das unidades de leitura.
Custos: Ideal para buscas que podem ser delimitadas pela chave de partição, reduzindo o número de RCUs (Read Capacity Units) necessárias.
🌀 Scan
O scan é uma operação que lê toda a tabela ou índice, aplicando filtros nos dados apenas após a leitura. Em tabelas grandes, essa abordagem pode se tornar bastante custosa, já que o scan percorre todos os itens e consome mais RCUs, inclusive para dados que serão descartados pelos filtros.
Versatilidade: Permite filtros sem precisar de uma partition key, mas acessa a tabela inteira, tornando-se mais pesado.
Consistência: Assim como as queries, as leituras de scan podem ser configuradas para consistência forte ou eventual.
Custos: Tabelas grandes resultam em alto consumo de RCUs, tornando o scan caro para grandes volumes de dados.

Para mais detalhes, veja a documentação sobre Query e Scan no DynamoDB.
Links para Documentação
Subscribe to my newsletter
Read articles from Marcelo Amorim directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Marcelo Amorim
Marcelo Amorim
Senior Software Engineer - Java, Spring and AWS