CUDA Programming : An Introduction
 Param Thakkar
Param ThakkarTable of contents
Introduction
CUDA is a programming platform developed by Nvidia in 2006. Since its introduction in 2006 it has been widely used in many applications involving high performance computing, parallel computing, GPU programming, etc.
CUDA is short for Compute Unified Device Architecture. It is a parallel computing platform and application programming interface (API) that allows application to use the power of graphics processing units (GPUs) for accelerated computation, also known as GPGPUs (General Purpose computing on GPUs).
CUDA is an extension of the C programming language that adds the ability to specify thread level parallelism in C and also specify GPU device specific operations like moving data between CPU and GPU.
Benefits of using GPUs
There are lot of benefits of using GPUs for running are applications and many more benefits are being discovered with time. GPUs offer significant benefits, especially in field like deep learning, data analysis, scientific computing.
Some of the reasons why GPUs have become essential for many computational tasks :
Parallel Processing Power
- GPUs are designed for parallel processing with thousands of smaller cores optimized for handling multiple tasks simultaneously. This is ideal for tasks like matrix operations and other computations in AI and machine learning, where we have large datasets which are to be processed concurrently
Speed and efficiency
- The architecture of GPUs allows them to perform specific types of calculations like linear algebra operations much fast than CPUs. This can reduce the time needed for training models from days to hours, or even minutes, depending on the workload.
Energy efficiency for high performance
- GPUs can deliver high performance per watt making them an efficient option for high compute tasks. Instead of adding more CPUs to increase computational power, GPUs can offer a most cost effective solution
Improved performance
- Tasks that involve vector or matrix operations such as deep learning, simulations, etc. perform exceptionally well on GPUs due to their design for handling large blocks of data.
Versatility with General Purpose (GPGPU) Computing
- Frameworks like CUDA and OpenCL have enabled GPUs to handle a broader range of general purpose computing tasks beyond just graphics rendering (graphics rendering is something which comes first to our mind when we hear GPU, but its not just that, it’s even more).
Enhanced Scalability for Distributed Systems
- In data centers and cloud platforms, GPUs are used in clusters, allowing computations to scale efficiently across multiple GPUs, making it possible to handle even larger datasets and more complex models without a significant drop in performance.
Support for Modern Software Libraries and Frameworks
- GPUs are compatible with popular libraries like Tensorflow, Pytorch and RAPIDS which are optimized for GPU acceleration. This enables developers to leverage GPUs more easily and increases productivity and ease of deployment for GPU-acceleration applications.
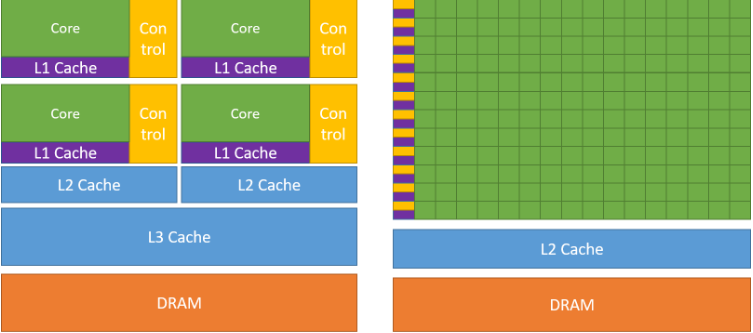
In the above image taken from https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html . On the left is the CPU and on the right is the GPU. GPU is seen to have more cores compared to CPU in the same space and the GPU puts this cores for parallel processing of incoming data.
CUDA : A Programming Platform for GPUs
Compute Unified Device Architecture (CUDA) is a scalable programming platform for programming GPUs for high performance, parallel and GPU based computing applications. This platform was developed by Nvidia for developers to leverage Nvidia GPUs for their industry level applications.
CUDA extends the standard C / C++ programming and allows for high performance computation by executing functions which are known as kernels in CUDA across thousands of GPU cores simultaneously.
This parallel processing capability is beneficial for tasks that require significant processing and computational power, such as deep learning, scientific simulations, and real-time data processing applications.
It has a robust set of libraries like cuBLAS, cuDNN, cuGraph, etc. and memory management model.
Whether you’re optimizing a machine learning model or performing complex computations, CUDA opens up new possibilities in the world of high-performance computing.
Conclusion
In all, CUDA is a great platform for high performance computing and a must learn if you want to understand how deep learning models, HPCs and really complex calculations take place at a large scale.
In the articles to come we will dive deeper into the GPU architecture and CUDA programming.
Subscribe to my newsletter
Read articles from Param Thakkar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by