Project On LINUX STORAGE ADMINISTRATION
 Aditya Gadhave
Aditya Gadhave
INTRODUCTION :
The Linux Storage Administration project is designed to provide practical experience in managing and configuring storage systems in a Linux environment, with a focus on CentOS. Effective storage management is a fundamental aspect of system administration, as it ensures that data is stored efficiently, remains accessible, and is protected against potential failures. In this project, we explore various aspects of storage administration, including disk partitioning, Logical Volume Management (LVM), file system creation, and disk quota management. We also delve into advanced topics such as RAID configuration and performance optimization to ensure a robust and scalable storage infrastructure. The project begins with setting up the necessary environment and tools, followed by the implementation of storage management techniques. Key tasks include creating and managing partitions, configuring physical and logical volumes, and setting up automated mount points for persistent storage. Furthermore, we demonstrate how to monitor storage usage and implement disk quotas to prevent overutilization of resources. This project not only showcases the practical application of storage administration commands and tools but also highlights troubleshooting strategies and best practices for maintaining a stable and efficient storage environment. By the end of this project, we aim to provide a comprehensive understanding of storage management, which iscrucial for ensuring data reliability and system performance in a professional IT setting.
Objective: Briefly state the purpose of the project. For example, "The objective of this project is to demonstrate proficiency in managing and administering storage in a Linux environment using CentOS."
Scope: Describe what will be covered in the report, including types of storage management and administrative tasks.
WHAT IS FILE SYSTEM AND TYPES OF FILE SYSTEM?
A file system is a set of processes that controls how, where and when data is stored and retrieved from a storage device. An efficient file system is essential for everyday system processes. The Linux kernel supports various file systems, but the most commonly used is the ext4 file system
FS stands for File System, which is a way of organizing and storing data on a disk. It manages how data is stored, retrieved, and updated on storage devices like hard drives, SSDs, and USB drives.
EXT3 (Third Extended File System):
Features: Introduced journaling to reduce the risk of data corruption in case of a system crash.Limited scalability compared to modern file systems.
Uses: Suitable for older Linux distributions, stable for general-purpose use but less optimal for high-performance applications.
EXT4 (Fourth Extended File System):
Features: Successor to EXT3, offering improvements like larger file and volume sizes (up to 1 exabyte). Better performance with delayed allocation, which helps with more efficient disk space usage. Fast file system checks and journaling for crash recovery.
Uses: Widely used in modern Linux distributions (e.g., Ubuntu, Fedora) for generalpurpose workloads and high-performance tasks.
XFS (Extended File System):
Features: High-performance 64-bit journaling file system with a focus on scalability. Excellent for handling large files and managing high-performance workloads. Supports parallel input/output operations, which is useful for multi-threaded applications.
Uses: Ideal for systems that handle large files and high-throughput environments like databases, multimedia processing, and scientific computing.
REAL TIME SCENARIO BASED STORAGE ADMINISTRATION:
In a real-world scenario, consider an e-commerce company managing massive amounts of customer data, including personal details, order histories, payment information, and product catalog. The storage administrator's role becomes critical in ensuring that all this data is stored, managed, and secured efficiently.
The company uses a hybrid cloud environment to store structured and unstructured data. A storage administrator is tasked with optimizing the use of both on-premises storage (for mission-critical applications) and cloud-based solutions (for scalability and cost-effectiveness). Daily operations involve monitoring storage usage, ensuring data availability, performing backups, and managing storage capacity.
One day, a sudden spike in customer activity during a promotional event leads to a surge in data generation. The storage administrator needs to quickly allocate more storage to handle the influx without impacting system performance. They dynamically provision additional cloud storage through the company’s cloud service provider to ensure there is no disruption.
Simultaneously, the administrator notices a slower-than-usual database performance. Upon investigation, they discover that outdated and redundant data in the on-premises storage is consuming valuable space and affecting retrieval times. They initiate a data archiving process, moving older data to cheaper, long-term storage solutions in the cloud while retaining frequently accessed data locally for faster performance.Additionally, the administrator must ensure that all stored data complies with relevant privacy regulations (like GDPR) by configuring encryption for sensitive customer data and ensuring regular audits of storage systems for vulnerabilities.
By balancing storage needs in a dynamic, hybrid environment, the administrator ensures high performance, scalability, cost-efficiency, and security, all while maintaining business continuity and compliance with legal requirements.
TYPES OF STORAGE:
1)Direct-Attached Storage (DAS) :
DAS is directly connected to a computer or server without a network in between. Examples include internal hard drives, SSDs, and external USB drives.
Pros: High performance and low latency since the storage is directly connected. It’s also relatively simple to set up and manage.
Cons: Limited scalability and flexibility. It cannot be easily shared across multiple systems.
2)Network-Attached Storage (NAS) :
NAS is a dedicated file storage device that connects to a network, allowing multiple users and devices to access the data.
Pros: Easy to share files across multiple devices. It often includes features like RAID for redundancy and data protection.
Cons: Network performance can be a bottleneck. It may require more complex setup and management compared to DAS.
3)Storage Area Network (SAN)
SAN is a high-speed network that provides access to consolidated block-level storage. It is typically used in enterprise environments.
Pros: High performance and scalability. It supports advanced features like clustering and disaster recovery.
Cons: Expensive and complex to set up and manage. Requires specialized hardware and expertise.
Implimentation:
DISK PARTITIONING IN LINUX
Disk Partitioning is the process of dividing a disk into one or more logical areas, often known as partitions, on which the user can work separately. It is one step of disk formatting. If a partition is created, the disk will store the information about the location and size of partitions in the partition table. With the partition table, each partition can appear to the operating system as a logical disk, and users can read and write data on those disks. The main advantage of disk partitioning is that each partition can be managed separately.
Why do we need it?
To upgrade Hard Disk (to incorporate a new Hard Disk into the system)
Dual Booting (Multiple Operating Systems on the same system)
Efficient disk management
Ensure backup and security.
Work with different File Systems using the same system.
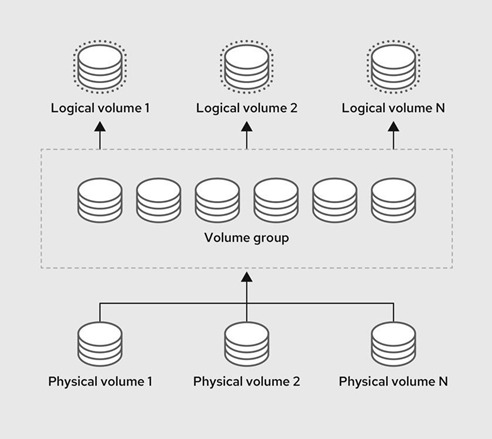
LVM (Logical Volume Manager)
LVM is a system used for managing disk storage in a more flexible and efficient way compared to traditional partitioning. It allows for dynamic resizing, creation, and management of logical volumes, which can be used in place of conventional disk partitions.
Key Concepts of LVM:
1 Physical Volumes (PVs): These are the actual storage devices, such as hard drives or partitions, that LVM uses. You can combine multiple physical volumes into a pool of storage.
2 Volume Groups (VGs): A volume group is created by combining one or more physical volumes. It acts as a pool of storage space from which logical volumes can be allocated. Think of a VG as a large virtual container made up of several physical disks or partitions.
3 Logical Volumes (LVs): Logical volumes are created within a volume group and are similar to partitions but much more flexible. You can resize, create, or remove logical volumes without worrying about the physical layout of the storage. LVs can be easily resized on-the-fly (even while the system is running), making them ideal for systems where the storage needs fluctuate.
Common Use Cases for LVM: -
Servers and Databases: Where storage needs to grow dynamically and manage large amounts of data efficiently.
Workstations: For users who need flexible partitioning, such as developers or data scientists.
Virtual Machines (VMs): To easily allocate and manage disk space between multiple virtual environments.
Step to Configure LVM :



RAID In Linux
RAID contains groups or sets or Arrays. A combine of drivers make a group of disks to form a RAID Array or RAID set. It can be a minimum of 2 number of disk connected to a raid controller and make a logical volume or more drives can be in a group. Only one Raid level can be applied in a group of disks. Raid are used when we need excellent performance. According to our selected raid level, performance will differ. Saving our data by fault tolerance & high availability.
TYPES OF RAID:
RAID 0 (Striping):
Concept: Data is split into blocks and written across multiple disks in a striped pattern. For example:block 1 goes to disk 1, block 2 goes to disk 2, block 3 goes to disk 1, and so on. This allows for parallel read/write operations, significantly boosting performance.
Strengths:
High Performance: Offers the fastest read and write speeds among RAID levels.
Easy Setup: Relatively simple to configure.
Weaknesses:
No Redundancy: If one disk fails, all data is lost.
Risk Aversion: Not suitable for critical data or applications that require high availability.
Use Cases:
High-Performance Applications: Video editing, gaming, scientific simulations, where speed is paramount.
Temporary Data: Storage for temporary files, scratch space, or logs where data loss is acceptable.
RAID 1 (Mirroring):
Concept: Data is duplicated exactly onto two or more disks. Any write operation is applied to all disks in the array.
Strengths:
High Reliability: Offers excellent data protection. If one disk fails, the other takes over seamlessly.
Fast Read Operations: Reads can be served from either disk, improving read performance.
Weaknesses:
Slower Write Performance: Writing requires updates to multiple disks, resulting in slower write speeds.
Disk Space Inefficiency: Requires twice the amount of disk space as the amount of data stored.
Use Cases:
Critical Systems: Databases, servers, or systems where data loss is unacceptable.
High-Availability Applications: Where uninterrupted operation is essential, like financial systems
RAID 4 (Striping with Dedicated Parity Disk):
Concept: Data is striped across multiple disks, and a dedicated disk is used for parity information. The parity disk stores a parity block that allows for data recovery if a data disk fails.
Strengths:
Good Read Performance: Read operations are fast since the parity disk is not involved in reading.
Fault Tolerance: Can tolerate one disk failure.
Weaknesses:
Slower Write Performance: Write performance is generally slower than RAID 5 because all write operations involve the parity disk.
Bottleneck on the Parity Disk: The parity disk becomes a single point of failure, as it handles all parity operations.
Use Cases:
- Limited use: RAID 4 is generally less common than RAID 5. It might be used in situations where write performance is less critical than read performance.
RAID 5 (Striping with Distributed Parity):
Concept: Data is striped across multiple disks, and a parity block (calculated from the data) is distributed across all disks. The parity block enables data recovery if a disk fails.
Strengths:
Good Performance: Offers a good balance of performance and reliability.
Fault Tolerance: Can tolerate one disk failure.
Efficient Disk Utilization: Uses disk space more efficiently than RAID 1, with a smaller overhead for parity.
Weaknesses:
Slower Write Performance: The parity calculation adds overhead to write operations, making them slightly slower than RAID 0.
Slower Reconstruction: Rebuilding the RAID array after a disk failure can take significant time.
Use Cases:
General-Purpose Servers: Web servers, file servers, and applications that require a mix of speed and reliability.
Data Storage: Storing large amounts of data where some redundancy is necessary.
Step To Create A RAID


CABLES USE IN STORAGE ADMINISTRATION:
Fiber Optic: High bandwidth, used in SANs for long-distance connections.
Twisted Pair Cable: Commonly used in Ethernet networks, provides reliable, costeffective data transmission over short distances, often for NAS storage setups.
PURPOSE
1.Load Balancing : Load balancing in Linux storage administration refers to the distribution of I/O (input/output) operations across multiple storage devices or paths to ensure optimal utilization, redundancy, performance, and reliability. This is crucial in environments where there are multiple paths between the system and the storage devices, such as in SAN (Storage Area Networks) configurations. Without load balancing, certain paths could be over-utilized while others remain under-utilized, leading to bottlenecks and reduced performance.
2. Multipath I/O (MPIO): Multipath I/O (MPIO) is a technique that allows a Linux system to use multiple physical paths to access storage devices. It provides two main advantages: Redundancy: In case one path fails, others can take over to prevent downtime. Performance: Load balancing distributes I/O requests across multiple paths, optimizing bandwidth and reducing latency.
3. Components of Multipath I/O: Multipath Devices: These are logical devices that aggregate multiple physical paths to a storage device into a single device seen by the operating system. Path Groups: Paths are grouped based on their characteristics, and MPIO decides how to route I/O traffic within these groups. Path Checker: This component monitors the health of each path, ensuring that only functional paths are used.
4. Path Selection and Load Balancing Policies: The method used to distribute I/O across multiple paths is defined by the load balancing policy. Common policies include:Round-Robin: I/O is distributed evenly across all paths in a cyclical manner. This is simple and effective when paths have similar performance. Least Queue Depth: I/O is sent to the path with the fewest active requests, ensuring no single path becomes overloaded.Failover (Active/Passive): All I/O goes through a primary path unless it fails, at which point a backup path is used.
KEY FEATURES AND ADVANTAGES:
Support for Multiple File Systems.
LVM allows administrators to manage disk space more dynamically
Linux natively supports software RAID, enabling administrators to configure various RAID levels.
Automated Storage Management with udev Linux uses udev to dynamically manage device files for hardware components: Automatically detects and configures new storage devices.
Linux offers a variety of tools for backup and recovery.
Linux is ideal for scalable and high-availability storage setups
CONCLUSION:
The Linux Storage Administration project has provided valuable insights into the critical role of managing and configuring storage systems in a Linux environment. Throughout the project, we explored essential storage management techniques, including disk partitioning, Logical Volume Management (LVM), file system creation, and disk quota configuration. Each of these tasks demonstrated the practical application of administrative commands and best practices necessary for maintaining a reliable and efficient storage infrastructure. One of the key takeaways from this project is the versatility and power of LVM in managing disk space dynamically. By creating and managing physical volumes, volume groups, and logical volumes, we were able to efficiently allocate and resize storage as needed, without impacting system availability. Additionally, configuring file systems and ensuring persistent mounts through the /etc/fstab file further solidified our understanding of file system management. We also addressed the importance of disk quotas in a multi-user environment, where monitoring and controlling disk usage can prevent resource exhaustion and ensure fair usage. This project emphasized the need for proactive monitoring and the implementation of policies that safeguard against storage mismanagement. Throughout the project, we encountered several challenges, such as handling disk failures and optimizing RAID configurations. These challenges provided an opportunity to apply troubleshooting skills and understand the resilience and redundancy offered by different RAID levels.
Subscribe to my newsletter
Read articles from Aditya Gadhave directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Aditya Gadhave
Aditya Gadhave
👋 Hello! I'm Aditya Gadhave, an enthusiastic Computer Engineering Undergraduate Student. My passion for technology has led me on an exciting journey where I'm honing my skills and making meaningful contributions.