Mastering GANs: The Roles of Generator and Discriminator
 Arya M. Pathak
Arya M. Pathak
Generative Adversarial Networks (GANs) have become a cornerstone in generative modeling within machine learning. GANs operate by pitting two neural networks—the Generator and the Discriminator—against each other, creating a feedback loop that allows the Generator to produce data closely resembling real-world data. In this blog, we’ll explore the intricate roles of the Generator and Discriminator, focusing on how they function individually, how they interact, and the theoretical foundations behind their adversarial relationship. This in-depth analysis includes classifiers, probability modeling, cost functions, and noise vectors, all essential components that contribute to the unique mechanism of GANs.
GANs were introduced by Ian Goodfellow and his team in 2014 and have since seen applications in creating realistic images, generating high-quality audio, and even assisting in data augmentation for various machine learning tasks. By understanding the distinct functions and collaborative process of the Generator and Discriminator, we can gain insight into why GANs are so effective and how they continue to push the boundaries of what machine learning models can achieve.
Learn more about deep learning at deeplearning.ai.
Discriminator: The GAN’s Classifier
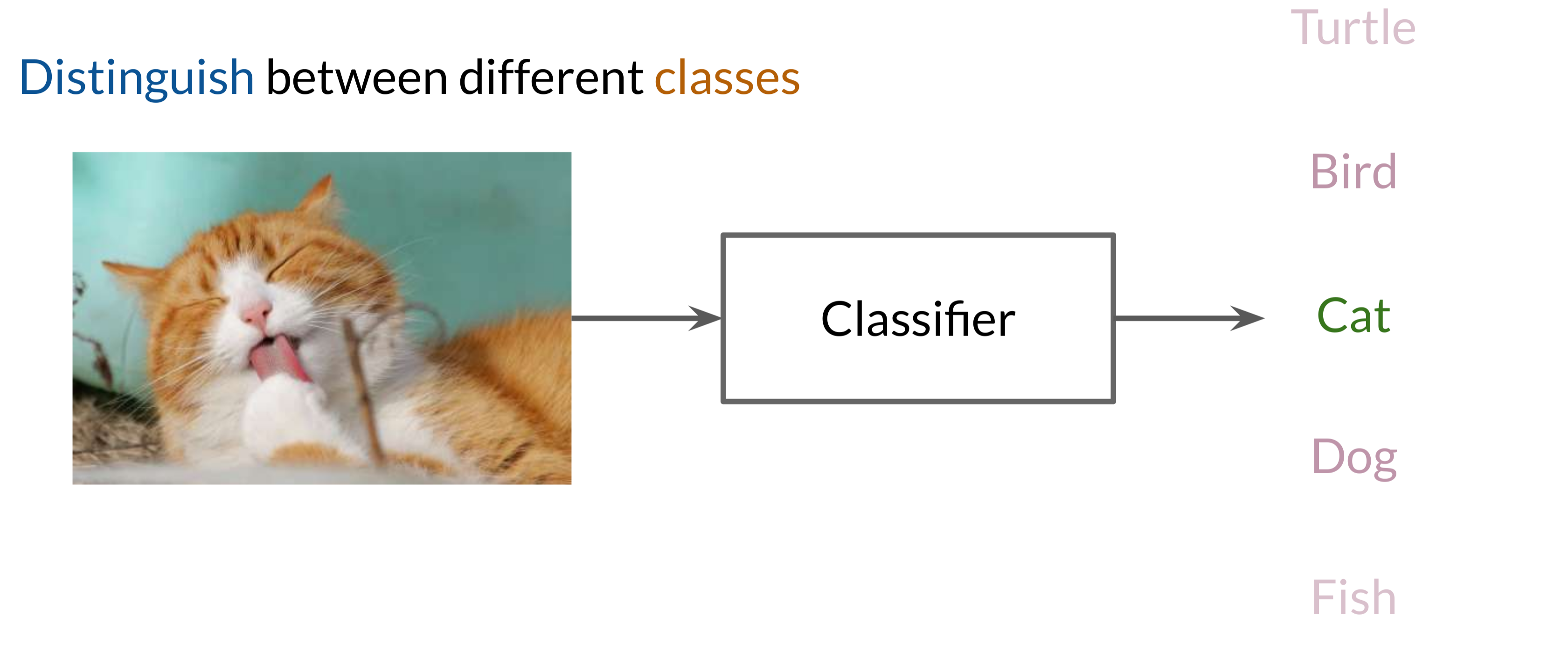
The Discriminator in a GAN framework functions as a classifier, tasked with determining whether a given input is from the real data distribution or if it’s a fake, generated by the Generator. Its role parallels that of traditional classifiers, which learn to categorize inputs into distinct classes, but in GANs, this classifier distinguishes only between real and fake classes. Here’s an overview of the Discriminator’s structure and functionality:
1. Classifiers in Machine Learning: A Refresher
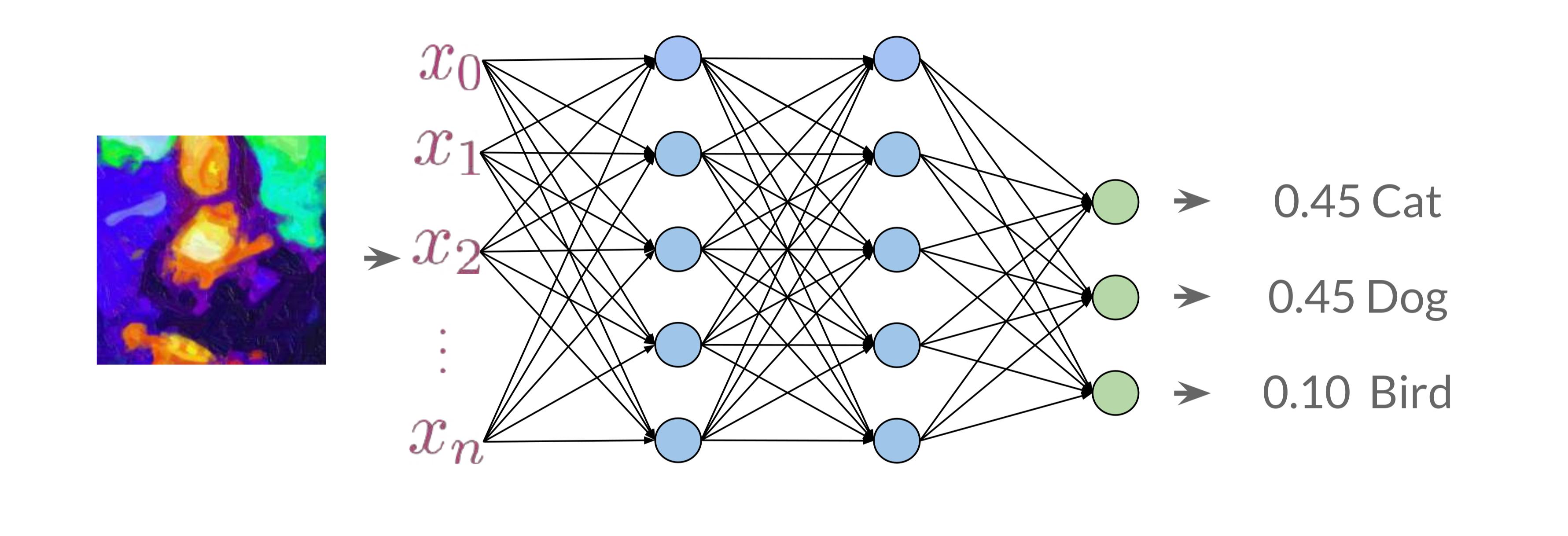
A classifier is designed to categorize data into predefined classes based on features. In a GAN, the Discriminator operates as a binary classifier, labeling inputs as either real (originating from the training data) or fake (generated by the Generator). For instance, if the input is an image of a cat, the Discriminator should accurately classify it as real or fake based on learned features associated with real-world cat images.
- The Discriminator analyzes multiple input features (e.g., pixel values, textures) and assigns a probability score indicating the likelihood of the sample belonging to a particular class. During early training stages, the Discriminator might struggle to classify data correctly, but it improves over time as it optimizes its weights and biases through gradient-based learning.
2. Discriminator as a Probability Model
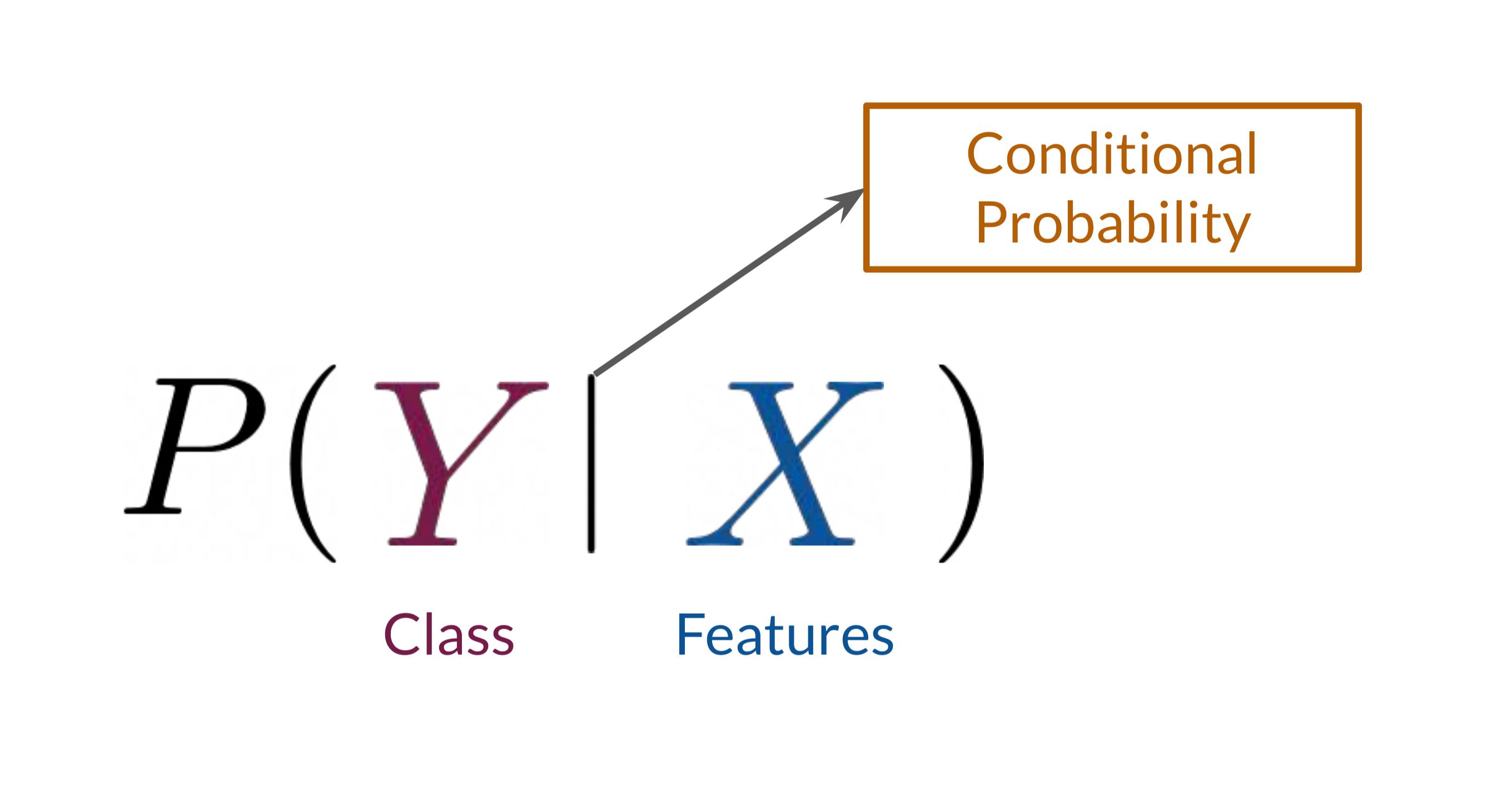
The Discriminator in GANs attempts to model the probability of each class (real or fake) conditioned on the input features. This is represented as \(P(Y∣X)\), where \(Y\) is the class (real or fake), and \(X\) represents the image’s features. This probability modeling allows the Discriminator to make probabilistic predictions based on each input's attributes, quantifying the likelihood that a sample belongs to the real data distribution.
In simpler terms, when presented with an input image, the Discriminator calculates how likely it is that the image is real based on learned features like color, shape, and texture distributions from the training set. For example, if the Discriminator analyzes an image and assigns it an 85% probability of being real, it categorizes the image as real with a high degree of confidence.
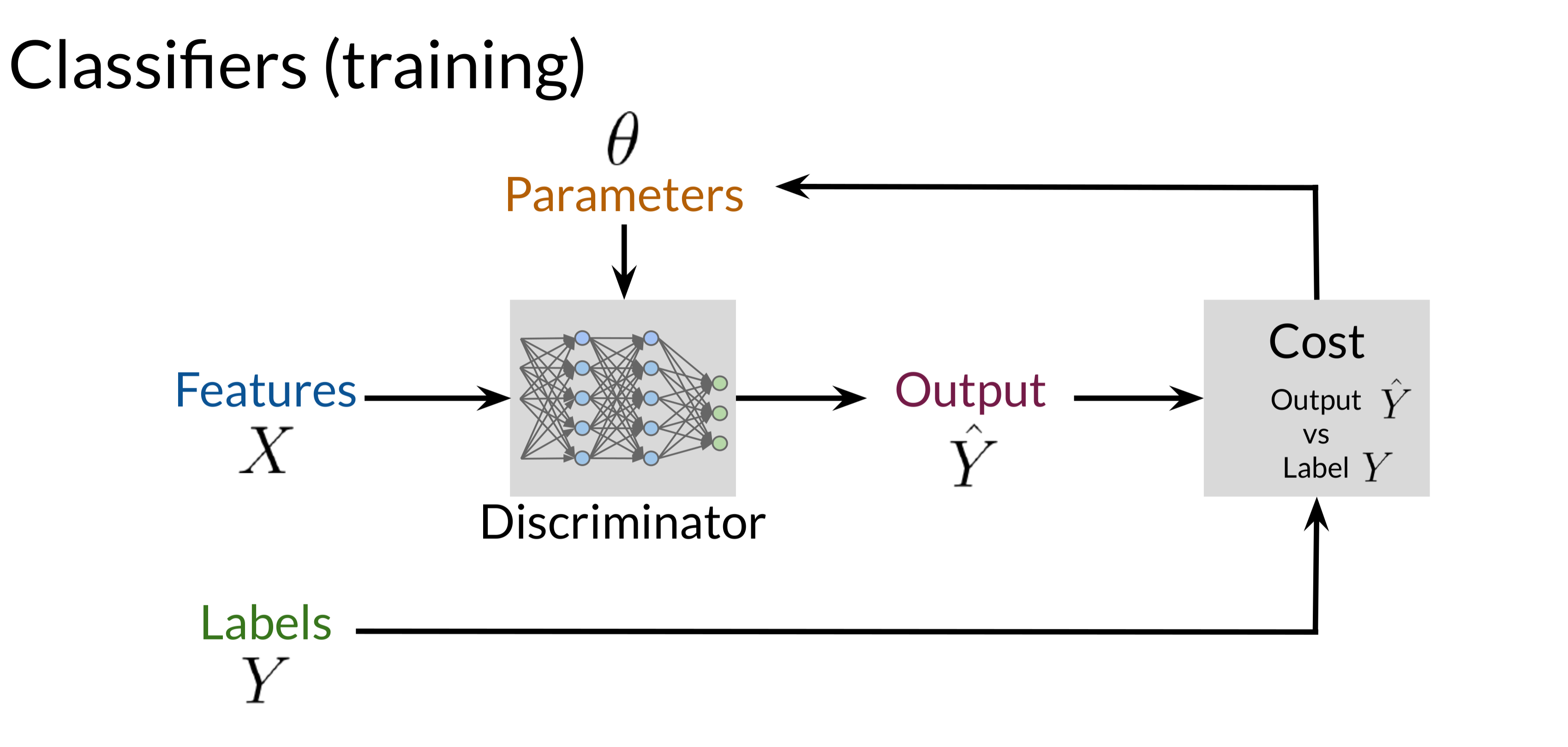
3. Cost Function and Learning Process
The Discriminator uses a cost function to measure how close its predictions \((\hat{Y})\) are to the true labels \(Y\). This cost function plays a pivotal role in updating the Discriminator’s parameters, adjusting its weights based on the prediction errors to minimize the difference between \((\hat{Y})\) and \(Y\). The most common cost function for binary classification is cross-entropy, which quantifies the difference between predicted probabilities and the actual labels.
The Discriminator’s weights are updated through backpropagation, a gradient-based optimization method. This process involves calculating the gradient of the cost function with respect to each weight and adjusting the weights in the direction that minimizes the error. Over time, the Discriminator becomes adept at identifying real data from generated data, providing essential feedback to the Generator.
4. Feedback Loop to the Generator
After each classification, the Discriminator’s output is used as feedback for the Generator. When the Discriminator correctly identifies an input as fake, the Generator is informed that it needs to improve. This feedback loop is central to GAN training: the Discriminator’s role is not just to classify but also to guide the Generator’s learning by providing constructive feedback on how "real" its outputs appear.
Mathematical View: Probability Distribution of Classes
The Discriminator operates based on conditional probability. When given an input, it computes the likelihood that the input is real, effectively modeling P(Y∣X)P(Y | X)P(Y∣X). This probabilistic approach, using conditional distributions, enables the Discriminator to make decisions about each input based on the likelihood that it belongs to the real data distribution.
For instance, when presented with an image of a cat, the Discriminator predicts the likelihood of it being real by analyzing features such as texture, color, and patterns. This probability modeling, \(P(Y∣X)\), allows the Discriminator to quantify how real the image is based on specific visual cues, offering feedback to the Generator accordingly.
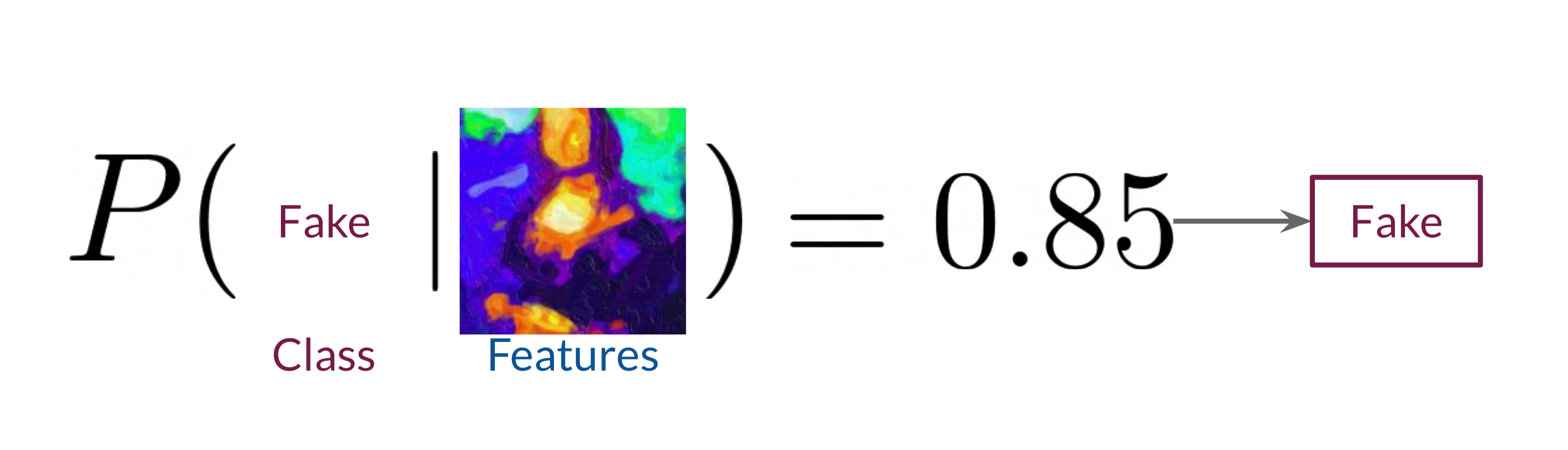
Generator: The Data Creator
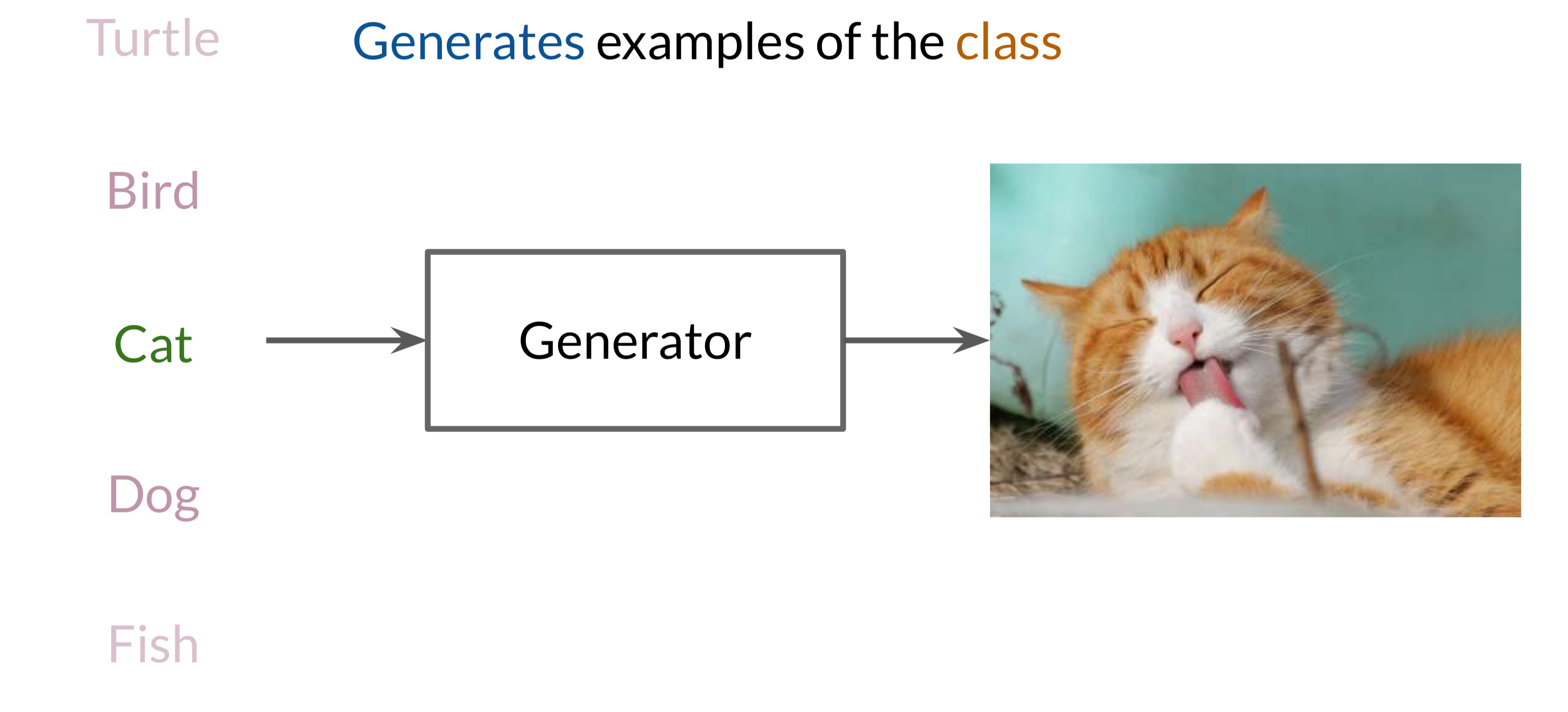
The Generator is responsible for creating synthetic data that mimics the real data as closely as possible. In GANs, the Generator acts as an artist, drawing inspiration from random noise and shaping it into structured outputs. The goal of the Generator is to produce samples that are so realistic that they can “fool” the Discriminator.
1. Noise Vector: The Foundation of Creativity
The Generator starts with a noise vector, a random array of numbers, as its input. This noise vector introduces randomness, ensuring that each generated sample is unique and preventing the Generator from simply recreating a single fixed output. The noise vector allows the Generator to produce diverse outputs, creating various examples within the target class, such as different cat breeds or orientations.
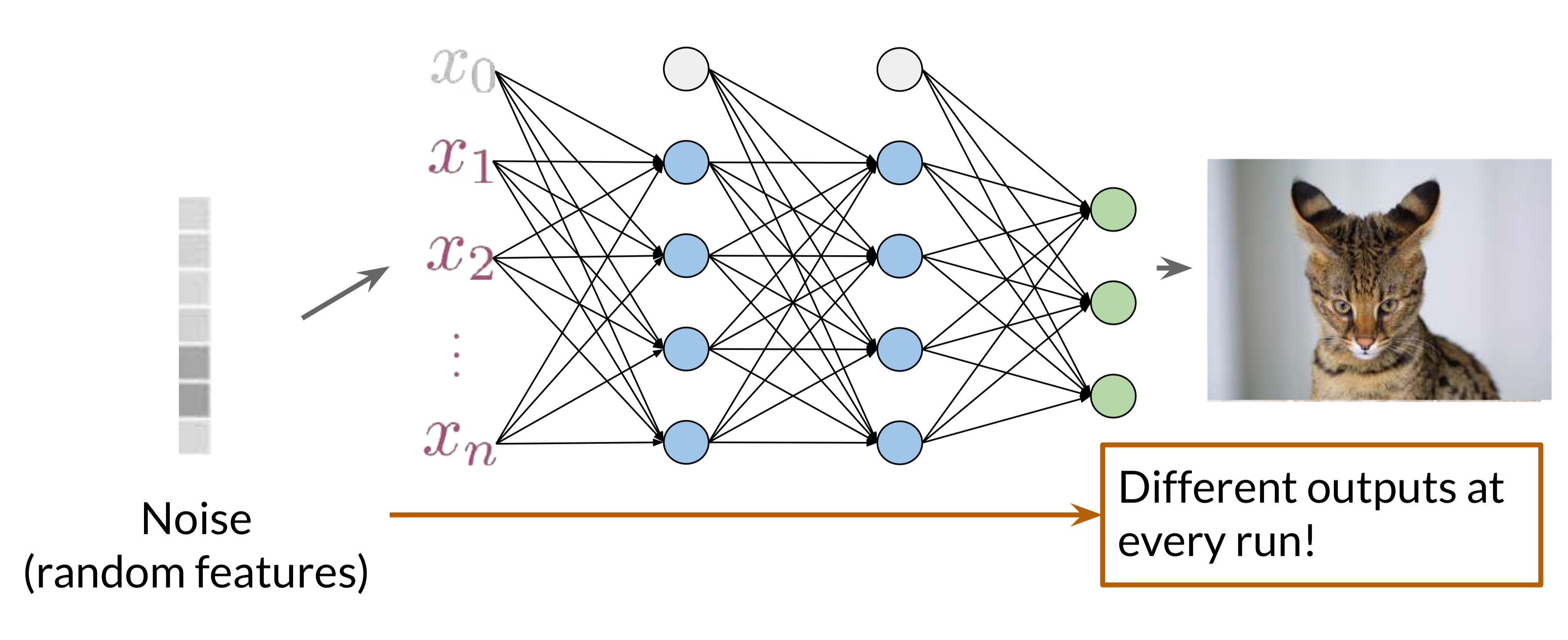
Incorporating random noise enables the Generator to produce diverse samples, essential for generating a wide variety of outputs rather than repeating the same sample each time.
2. Modeling Features of the Target Class
The Generator learns to model the distribution of features in the target class, such as the appearance of a cat. By understanding the probability distribution of these features, the Generator can create outputs that statistically align with the real data. This modeling is represented as \(P(X)\), where \(X\) represents the data features, like color patterns, textures, and shapes.
For example, if tasked with generating cat images, the Generator learns to replicate common cat characteristics, like pointy ears, fur textures, and whiskers, which align with the actual data distribution of cats. Over time, it becomes skilled at producing realistic images that reflect the attributes of the real-world data.
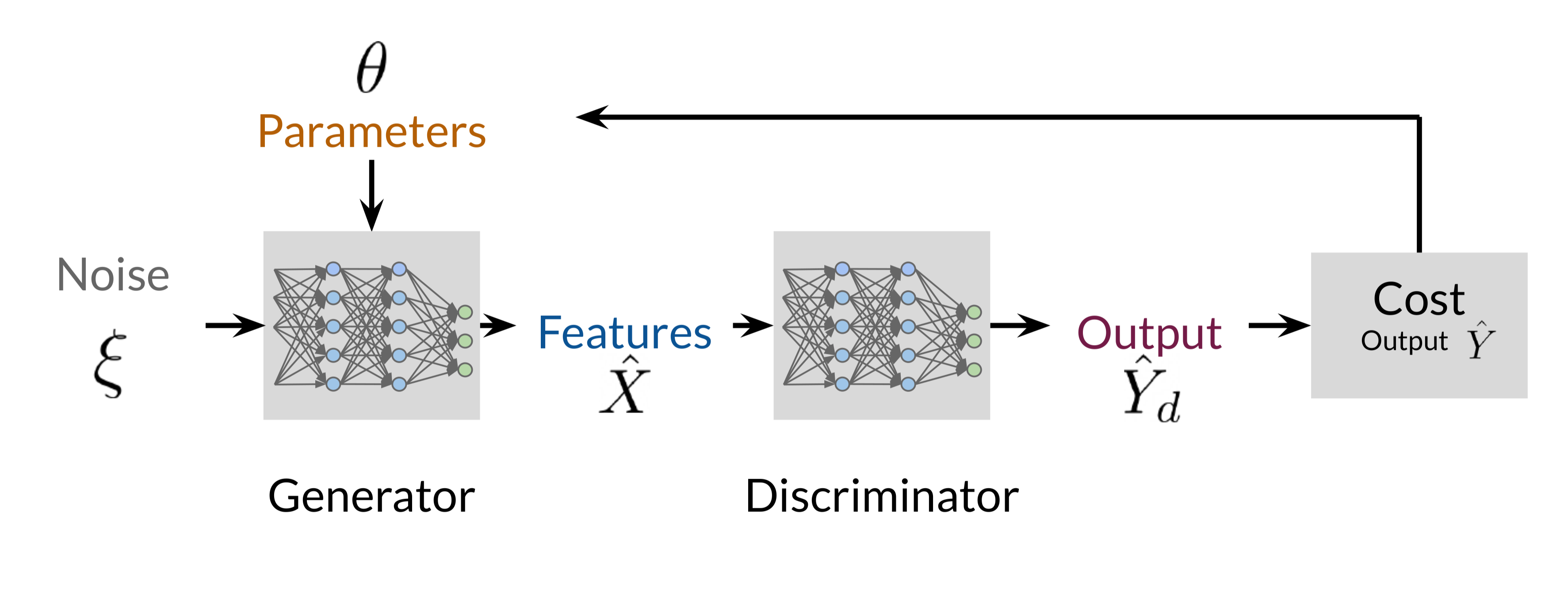
3. Adversarial Training with the Discriminator
During GAN training, the Generator and Discriminator engage in a continuous adversarial loop:
The Generator produces a synthetic sample from a noise vector.
This sample is evaluated by the Discriminator, which classifies it as real or fake.
Based on the Discriminator’s feedback, the Generator adjusts its parameters to produce better outputs in future iterations.
This adversarial process helps the Generator to “learn” from its mistakes, gradually refining its output to produce data that increasingly resembles the real data.
4. Cost Function and Gradient Descent in Generator Training
The Generator is trained to “fool” the Discriminator, aiming to maximize the probability that the Discriminator classifies its output as real. This objective is achieved by minimizing a cost function that reflects the discrepancy between the Discriminator’s prediction (fake) and the Generator’s desired output (real). The cost function for the Generator is the reverse of the Discriminator’s: instead of minimizing the error between prediction and true label, the Generator tries to maximize the Discriminator’s error on its outputs.
This optimization is achieved through gradient descent, where the Generator updates its weights in a direction that reduces the likelihood of its samples being identified as fake. By repeating this process, the Generator improves its capacity to generate realistic outputs.
Probabilistic Modeling of the Generator
The Generator is designed to model the probability of features \(P(X)\) within the target class. Unlike the Discriminator, which calculates conditional probability \(P(Y∣X)\), the Generator models the unconditional probability distribution of the data, \(P(X)\). For instance, if it is generating images of cats, the Generator will learn to create outputs that approximate the distribution of pixel values seen in real cat images.
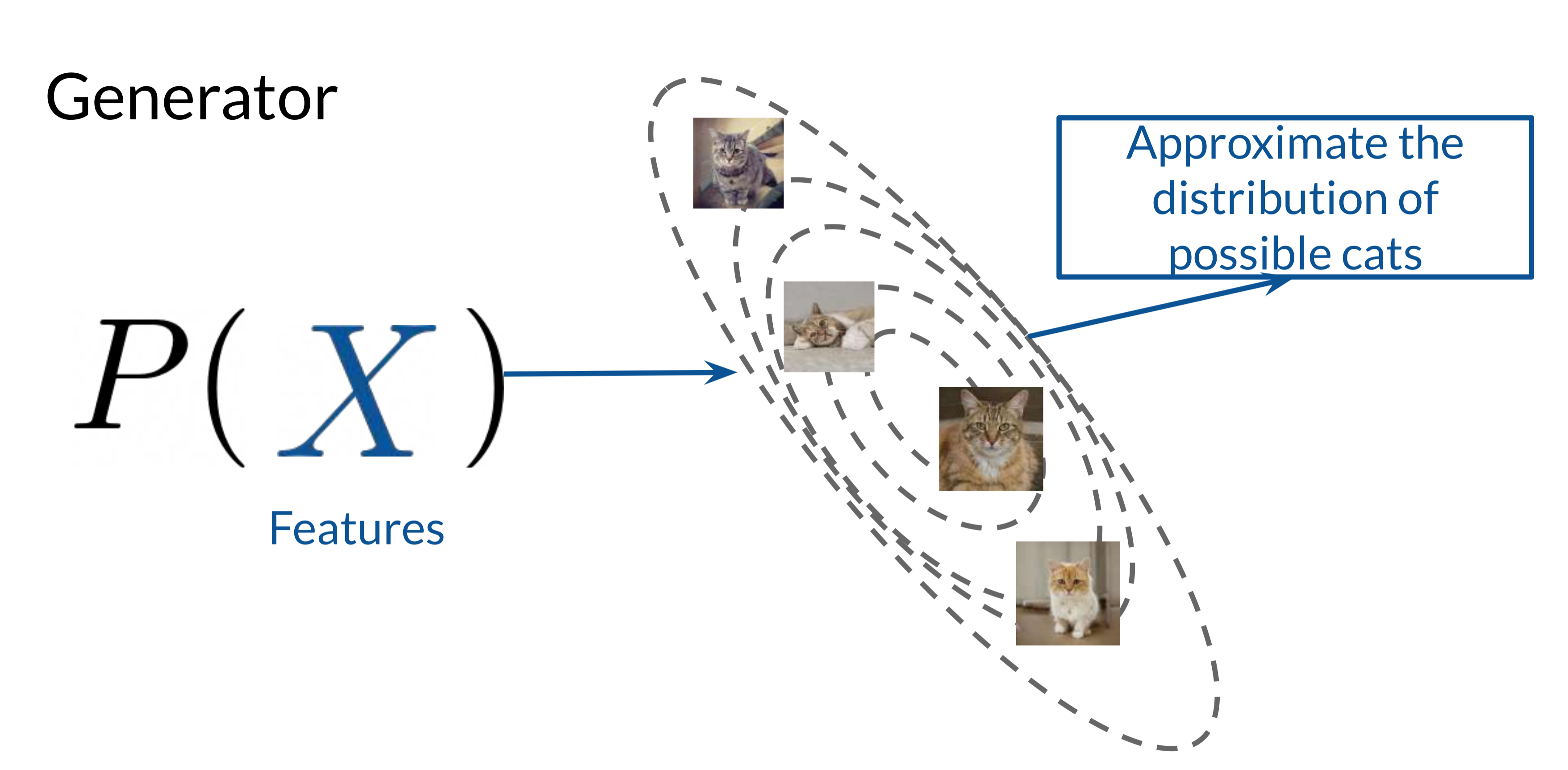
The Generator aims to approximate the real data distribution by learning from the feedback loop with the Discriminator. As it refines its distribution modeling, it produces samples that better mimic real-world data, achieving the goal of generating convincing synthetic data.
Conclusion
The Generator and Discriminator in GANs operate in a finely tuned adversarial relationship. The Discriminator, as a classifier, distinguishes real data from synthetic, providing critical feedback that drives the Generator’s learning process. Meanwhile, the Generator leverages random noise and feedback from the Discriminator to generate increasingly realistic data that eventually “fools” the Discriminator. This adversarial dynamic allows GANs to produce remarkably realistic images, sounds, and other data forms, with applications extending across fields like visual art, synthetic voice generation, and video game development.
By iteratively refining their performances, the Generator and Discriminator push each other toward an equilibrium, where the Generator’s outputs are virtually indistinguishable from real data. GANs embody the power of adversarial training and have opened up exciting possibilities in the field of artificial intelligence.
For further reading on deep learning, visit deeplearning.ai.
Subscribe to my newsletter
Read articles from Arya M. Pathak directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Arya M. Pathak
Arya M. Pathak
I am a Computer Engineering undergraduate at Vishwakarma Institute of Technology, Pune . With hands-on experience in software development and cloud-native applications, I specialize in Python, Go, C#, and full-stack web development using MERN, ASP.NET Core, and Angular. I have interned at Alemeno and CodingKraft, where I developed AI-driven compliance systems, Python execution engines, and secure web solutions. My projects include scalable microservices, machine learning pipelines, and secure banking APIs deployed on cloud platforms like Azure with Kubernetes and CI/CD automation. Adept in tools like Docker, Redis, RabbitMQ, and GitHub Actions, I am certified in Deep Learning and DevOps. I have a strong foundation in algorithms, having solved over 350 coding problems across platforms like Leetcode and Codeforces. Additionally, I actively contribute to open-source projects, mentoring initiatives, and hackathons.