Automating Fabric: Kickstart your Fabric Data Platform setup
 Peer Grønnerup
Peer GrønnerupSetting up and managing workspaces in Microsoft Fabric can be a time-consuming task, especially when you need multiple workspaces for various stages of the data lifecycle across different environments. This blog post demonstrates how to streamline your Fabric setup using Python and Fabric REST APIs and automate the creation, configuration, and if required clean up of Fabric workspaces etc.
My approach to workspace setup and configuration
I will introduce a recipe-based setup approach, where I define essential parameters like workspace naming pattern, environment-specific settings, stages, Git configurations, and more.
Using Python scripts I will demonstrate how quickly and efficiently you can perform the following tasks:
Configure environments (Development, Test, Production) using environment-specific parameters.
Set up workspaces for different data lifecycle stages (Ingest, Prepare, Serve, and Consume) and for each of the configured environments.
Automate workspace assignments to Fabric capacities.
Manage access and permissions for secure, compliant collaboration.
Integrate workspaces with Git for seamless CI/CD workflows.
Prerequisites
There are a few prerequisites to this approach. These include:
Python Environment: Ensure you have Python 3.x installed with essential libraries (
requestsandazure-identity) which is needed for interacting with REST APIs and authenticating to Azure.
You can install the required Python libraries by using the command:
pip install requests azure-identity —-userFabric API Access: Access to Fabric REST APIs via service principal, configured with necessary permissions.
Git Access: Access to integrate Fabric workspaces with a Git repository.
Python functions file and setup sample scripts: Clone or download the Python scripts from my GitHub repo to get started. You can find a link to the repository at the bottom of this blog post.
Tips:
A Fabric administrator will need to enable API permissions and workspace creation rights for your service principal.
Workspace structure
Before jumping into action, let’s discuss how to structure your Fabric workspaces effectively. My recommendation is to separate workspaces by stages and environments, as shown below.

In a typical end-to-end data platform setup, we have distinct components for each stage of the data lifecycle: pipelines and notebooks for data ingestion, notebooks for data preparation, lakehouses for storage, semantic models for serving data and reports for data consumption. Separating these stages into individual workspaces, then multiplying them by environments (such as dev, tst, prd), allows you to assign security at the stage level and provides flexibility in allocating different Fabric capacities for each stage and environment.
For enhanced governance and security, consider further dividing the storage workspace into separate workspaces for each layer of the medallion architecture. This approach simplifies permission management and supports a more scalable, secure setup across the data platform. On the other hand this approach will increase complexity and it add management overhead .
Recipe-Based Setup
My automation approach is built around variables and recipes, defining details for each environment and stage, including:
Naming: A generic pattern for defining how workspaces are named.
Environments: Details for Dev, Test, and Production environments. This also includes Fabric capacity details and permissions.
Stages: The purpose (Ingest, Prepare, Serve, Consume) and definition of Fabric items such as lakehouses.
Git Setup Information: Definition of Git repository information and branch details for each workspace.
Script and setup configuration
To streamline the setup of a Fabric data platform solution, I’ve created two Python scripts: init_fabric_solution.py and fabric_functions.py. These scripts automate the creation and configuration of workspaces, capacities, and permissions across various stages and environments using Fabric and Power BI REST APIs.
The init_fabric_solution.py script manages the main setup process, leveraging helper functions in fabric_functions.py. These helper functions encapsulate the necessary Fabric and Power BI REST API calls, keeping the code clean, reusable, and easy to maintain. This approach makes it simple to add or adjust functions as setup needs evolve.
Together, these scripts provide a fully automated, scalable method for configuring your Fabric solution with minimal manual effort.
Let me walk you through the key steps in the setup process, covering the creation of Fabric workspaces, items, and the initialization of Git integration.
Step 1: Authenticating with Fabric REST APIs
Workspaces and lakehouses are created using a service principal, following best practices to ensure that ownership is assigned to the service principal rather than an individual user account.
The Tenant ID, App ID, and App Secret for the service principal can be stored in a credentials.json file or directly in the init_fabric_solution.py script, depending on your preference.
Example of credentials.json file
{
"tenant_id": "00000000-0000-0000-0000-000000000000",
"app_id": "00000000-0000-0000-0000-000000000000",
"app_secret": "YourAppSecret"
}
The wrapper function get_access_token is then called, passing in the service principal credentials and scope.
# Load the credentials from the credentials.json file. Remove this and use hardcoded values if credentials file is not used.
credentials = fabfunc.get_credentials_from_file("credentials.json")
tenant_id = credentials["tenant_id"]
app_id = credentials["app_id"]
app_secret = credentials["app_secret"]
fabric_access_token = fabfunc.get_access_token(tenant_id, app_id, app_secret, 'https://api.fabric.microsoft.com')
#endregion
Step 2: Naming pattern, environments and stages
After authentication, the setup process follows a structured naming convention defined by the fabric_solution_name variable. This variable uses string interpolation to generate the names of each workspace, incorporating the specified stage and environment names.
Key Configuration Variables
fabric_solution_name: Sets the base naming pattern for the workspaces. For example:fabric_solution_name = 'MyDataPlatform - {stage} [{environment}]'This pattern ensures consistency in naming by automatically incorporating each workspace's stage and environment into its name.
fabric_environments: This JSON-like variable defines each environment to be created, including:capacity_id: Specifies the Fabric capacity to which each workspace in the environment will be assigned.permissions: Lists the user or group permissions for each environment. Supports Admin, Contributor, Member and Viewer and Group, User and App identities. For example:fabric_environments = { "dev": { "capacity_id": "79CF9D57-8F75-4879-B906-691A0D85A36B", "permissions": { "Admin": [ {"type": "Group", "id": "a9327fc3-a6a0-4b82-8087-6b0d698323d7"}, {"type": "User", "id": "pg@kapacity.dk"} ] } }, "tst": { # Additional environment configurations }, }
fabric_stages: This variable defines the stages and resources to be created within each environment, specifying different stages of data processing. For instance:fabric_stages = { "Store": { "lakehouses": ["Bronze", "Silver", "Gold"] }, "Ingest": {}, "Prepare": {}, "Serve": {} }In this configuration, lakehouses are created within the “Store” area, segmented into Bronze, Silver, and Gold layers to align with data lifecycle management.
Together, these variables enable a scalable and automated setup that generates workspaces, assigns capacities, and configures permissions across environments with minimal manual intervention.
Automating Workspace Setup
With the naming pattern, environments, stages, and Git integration configured, you’re ready to execute the script to set up your Fabric workspaces and lakehouses.
The script will automatically output the results of the setup process, as shown below:
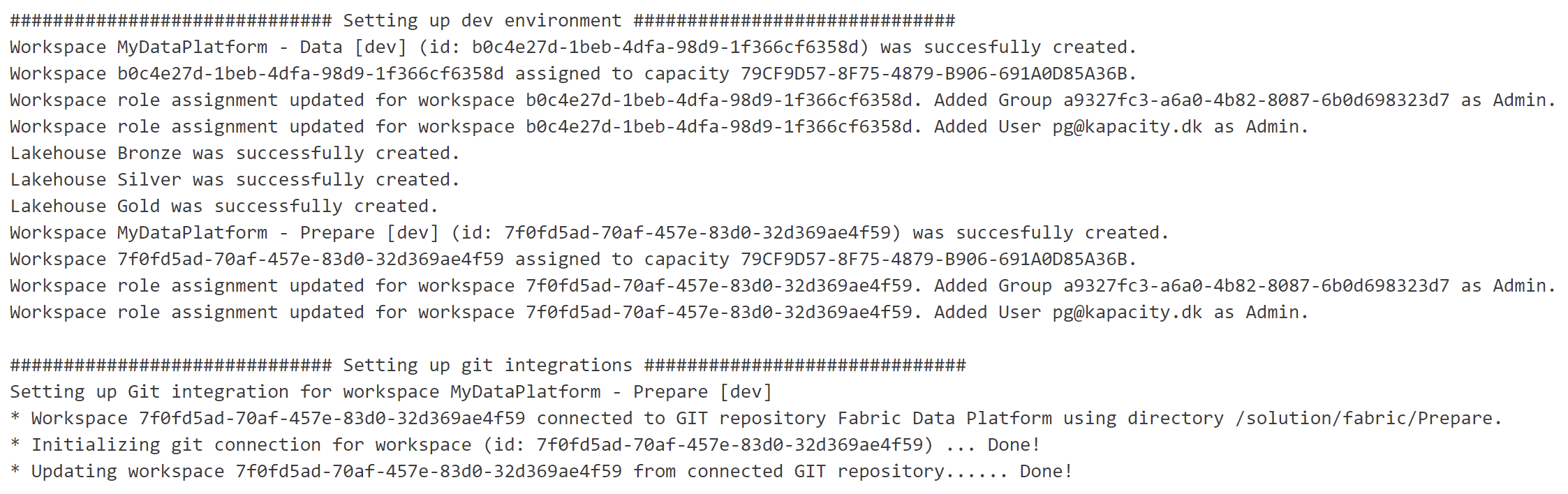
Cleaning Up: Automating workspace deletion
In scenarios where workspaces need to be decommissioned, the python script cleanup_fabric_solution.py can be used to batch-deleting Fabric workspaces based on naming pattern, environments and stages.
Simply specify the naming pattern of you Fabric solution, environments and stages.
#region Fabric solution setup
fabric_solution_name = 'MyDataPlatform - {stage} [{environment}]'
fabric_environments = ['dev', 'tst', 'prd']
fabric_stages = ['Data', 'Ingest', 'Prepare', 'Serve']
#endregion
Conclusion
This approach to automating workspace creation in Microsoft Fabric accelerates setup, ensures consistency, and simplifies the integration of workspaces with Git for CI/CD. By leveraging Fabric REST APIs and Python, you’ll be able to manage and maintain your Fabric data platform workspaces efficiently across all environments.
In the near future, I’ll also be looking into using the Terraform Provider for Fabric which is currently in preview. And also though upon a lot of other topic related to automating Fabric. So stay tuned for more Peer insights!
You can download the notebooks and credentials.json file used in this post here:
https://github.com/gronnerup/Fabric/tree/main/FabricSolutionInit
Subscribe to my newsletter
Read articles from Peer Grønnerup directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Peer Grønnerup
Peer Grønnerup
Principal Architect | Microsoft Fabric Expert | Data & AI Enthusiast With over 15 years of experience in Data and BI, I specialize in Microsoft Fabric, helping organizations build scalable data platforms with cutting-edge technologies. As a Principal Architect at twoday, I focus on automating data workflows, optimizing CI/CD pipelines, and leveraging Fabric REST APIs to drive efficiency and innovation. I share my insights and knowledge through my blog, Peer Insights, where I explore how to leverage Microsoft Fabric REST APIs to automate platform management, manage CI/CD pipelines, and kickstart Fabric journeys.