O1 Models vs. Simple Chain of Thought: What’s the Difference?
 Manthan Surkar
Manthan Surkar
OpenAI recently released the O1 model series, which has outperformed on multiple benchmarks (more on this here). But what exactly is going on with these models? Aren’t they just doing basic chain-of-thought reasoning? We’ll try to understand(in very brief) how models are trained, and the fundamental difference between a chain of thought prompt vs a model like O1.
Let’s start with how Openai describes the model on the model list page:
| Model | Description |
| GPT-4o | Our high-intelligence flagship model for complex, multi-step tasks |
| GPT-4o mini | Our affordable and intelligent small model for fast, lightweight tasks |
| o1-preview and o1-mini | Language models trained with reinforcement learning to perform complex reasoning. |
Let’s break the description for o1-preview and o1-mini by a bit- so the models are trained with “reinforcement” learning, and perform complex reasoning tasks. Let’s understand Reinforcement learning and how a model learns anyway.
What is a model and how does it learn?
A machine learning model is a program that learns patterns and makes decisions based on new data, guided by various training methods tailored to different types of tasks. For example, in speech recognition, models can be trained to interpret spoken words, while in medical imaging, they might learn to detect anomalies like tumors. In the case of generative models, they can be trained to generate the next token for an existing set of tokens, etc.
A model “learning” means identifying patterns or rules from data to make predictions on new unseen data or generate new data. This learning process involves optimizing parameters so the model can effectively map inputs to outputs, detect structures, or generate insights without needing specific instructions for each situation. We won’t be going deep into are model parameters in this blog post. How a model is trained determines its strengths and applications, with different techniques suited for different goals.
Unsupervised Learning
Purpose: Identifies patterns, clusters, or structures within data without labeled outputs.
Method: The model processes large volumes of unlabeled data, learning to predict or cluster based on inherent patterns.
Example: Clustering customer data to find natural groupings based on purchasing habits.
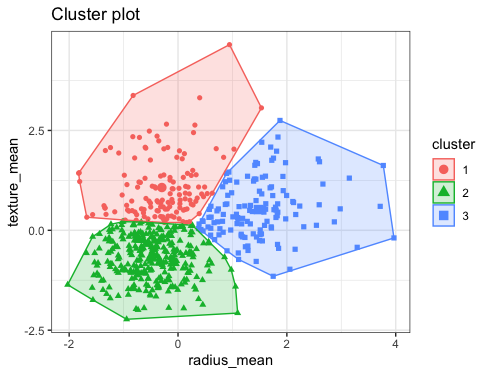
Source of image: https://bookdown.org/tpinto_home/Unsupervised-learning/k-means-clustering.html
Supervised Learning
Purpose: Enables the model to learn specific tasks with clear input-output relationships.
Method: Trains on labeled datasets, where each input has an associated output.
Example (General): Classifying emails as spam or not spam based on labeled examples.
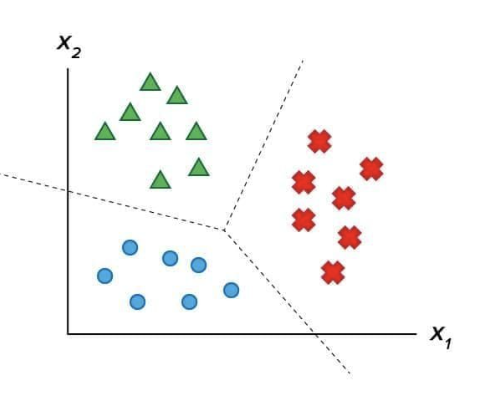
Reinforcement Learning
Purpose: Trains an agent to maximize rewards by interacting with an environment.
Method: Uses a trial-and-error approach, where the agent receives rewards or penalties based on its actions.
Example: Teaching a robot to navigate a maze by rewarding it for moves that bring it closer to the exit.
How are LLMs trained?
In training large language models, multiple approaches, including supervised and unsupervised learning, play key roles in creating a well-rounded and versatile model. Here’s how these techniques are typically used in the LLM training pipeline:
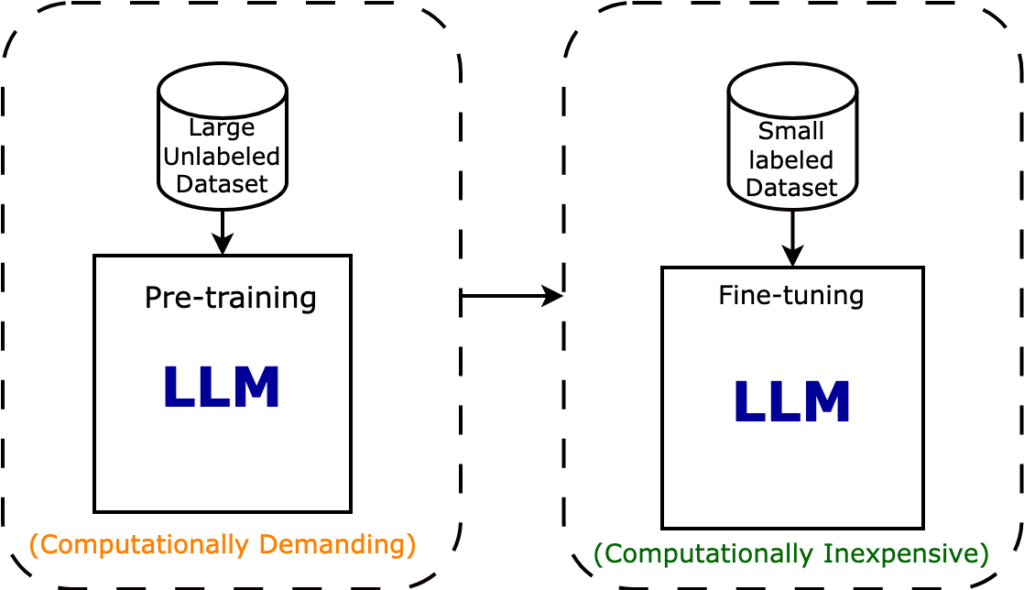
Source: https://intuitivetutorial.com/2023/06/18/large-language-models-in-deep-learning/
1. Unsupervised Learning: The backbone of LLM training relies heavily on unsupervised learning, particularly during pretraining. Here, the model is fed massive amounts of text data, often scraped from various sources like websites, books, articles, and forums. The model learns language patterns, relationships between words, grammar, and general knowledge without explicit labels by predicting the next word or sentence fragment in a given context. This unsupervised approach allows the model to build a robust understanding of language and is crucial for developing its ability to generalize across various tasks.
2. Supervised Learning: Fine-tuning often involves supervised learning to improve model accuracy on specific tasks after pretraining. For instance, when training the model for question-answering or summarization, labeled examples—pairs of prompts and correct answers—are provided. This step helps refine the model’s ability to generate contextually relevant responses and improves its performance on structured tasks, where a correct output is crucial.
3. Reinforcement Learning: More advanced LLMs, particularly those trained to align with human preferences, use reinforcement learning techniques. A prominent example is reinforcement learning from human feedback (RLHF), where human annotators rank model outputs based on quality or relevance. The model then adjusts its responses to maximize positive feedback in similar scenarios. This approach refines its responses to align more closely with human expectations and enhances its ability to generate meaningful, helpful answers.
Wait, so LLMs already were trained using reinforcement learning?
Yes, the models have always used reinforcement learning, to make the model safer, better, and more helpful. You may have also contributed to this, if you have used ChatGPT you might see a thumbs up and a thumbs down button on each response. This information could have been used as an input to the reinforcement learning pipeline for future releases.
O1 Models, how do they differ from the previous generation of models?
OpenAI's O1 models represent a shift in how we approach reasoning with LLMs. Unlike traditional models that rely heavily on immediate, token-by-token predictions as the final output, O1 models are designed to incorporate a form of structured reasoning, mimicking a more human-like thought process. This doesn't mean the models are sentient or conscious reasoning; rather, they simulate a chain of thought, breaking down complex problems into smaller, manageable steps before arriving at an answer(which is the final output). They still are only generating the next token in the reasoning step, which you do not consider as part of the answer.
This approach helps address one of the core limitations of earlier LLMs: the tendency to jump to conclusions without intermediate reflection. By integrating this step-by-step process, O1 models can better handle tasks that require deeper reasoning, such as solving multi-step math problems or understanding intricate logical puzzles. The difference is not just in the output, but in the model's ability to internally generate and follow through with an ordered sequence of thoughts, leading to more accurate and reliable outcomes. This is the classic “think step by step”, but you don’t need to explicitly ask for it.
Wait but we could do it using a chain of thought prompt anyway?
But couldn’t we already achieve this using chain-of-thought prompting? In a way, yes. Chain-of-thought (CoT) prompting has been a method for guiding traditional LLMs to break down their answers into logical steps. By including prompts like “Think step-by-step” or “Break down your answer,” we could encourage models like GPT or Claude to simulate reasoning paths. CoT prompting was a workaround that helped push LLMs toward better responses in multi-step tasks and reasoning challenges.
However, there are fundamental limitations to relying on prompt-based CoT alone. Traditional LLMs still lack a native mechanism for systematically planning out each step. While they can simulate CoT when explicitly prompted, they tend to drift back to surface-level responses without it, and they can struggle with complex tasks requiring more than shallow, sequential reasoning. In contrast, O1 models are trained to internalize this structured reasoning process as a default behavior rather than as an afterthought to the prompt. This makes O1 models inherently better at tasks demanding consistent, in-depth reasoning.
How does one train a model to reason?
OpenAI’s approach to training models for reasoning tasks could involve two main steps. Though these methods are inferred possibilities without official documentation (Publically guessing, what could go wrong? There is limited information in few of the blogs)
1. Supervised Learning for reasoning: This begins by constructing a comprehensive dataset of reasoning examples across diverse problem domains. Each example includes a problem and structured reasoning steps that lead to correct answers, serving as a foundational “training ground.” By fine-tuning this curated dataset, the model learns specific patterns and strategies for reasoning. Through this structured training process, the model could progressively become better at replicating similar reasoning sequences.
2. Reinforcement Learning for reasoning: This method refines the model’s reasoning abilities through an iterative feedback loop. The model initially attempts to solve a variety of problems, generating reasoning steps for each. Human/algorithmic evaluators then review and rate these attempts, scoring them based on accuracy and reasoning quality. This feedback guides the model to recognize correct reasoning patterns and adjust its strategies accordingly. Through repeated cycles of generating, evaluating, and fine-tuning, the model learns to optimize its reasoning process
Two excerpts from Openai’s blog talk about reinforcement learning:
“Our large-scale reinforcement learning algorithm teaches the model how to think productively using its chain of thought in a highly data-efficient training process. We have found that the performance of o1 consistently improves with more reinforcement learning (train-time compute) and with more time spent thinking (test-time compute). The constraints on scaling this approach differ substantially from those of LLM pretraining, and we are continuing to investigate them.”
&&
“Similar to how a human may think for a long time before responding to a difficult question, o1 uses a chain of thought when attempting to solve a problem. Through reinforcement learning, o1 learns to hone its chain of thought and refine the strategies it uses. It learns to recognize and correct its mistakes. It learns to break down tricky steps into simpler ones. It learns to try a different approach when the current one isn’t working. This process dramatically improves the model’s ability to reason. To illustrate this leap forward, we showcase the chain of thought from o1-preview of several difficult problems below.”
Conclusion
In summary, while traditional chain-of-thought prompting encourages models to break down their reasoning through explicit instructions in the prompt, this approach has limitations. It relies on surface-level guidance and doesn't fundamentally change how the model processes information. The O1 models, on the other hand, represent a significant advancement by internalizing the chain-of-thought process through reinforcement learning. This means they don't just simulate step-by-step reasoning when prompted—they naturally engage in structured thinking as a core part of their operation.
By training with reinforcement learning, O1 models learn to refine their reasoning strategies, recognize and correct mistakes, and adapt their approach when facing complex problems. This leads to more accurate and reliable outcomes, especially in tasks requiring deep reasoning. The key difference is that O1's chain of thought is an inherent feature, not an externally applied technique. This shift enables the models to handle intricate tasks more effectively, marking a substantial leap forward in the capabilities of language models.
Subscribe to my newsletter
Read articles from Manthan Surkar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by