The Hype vs. Reality of AI: Rethinking Temperature and Creativity
 Gerard Sans
Gerard Sans
In the rapidly evolving world of artificial intelligence, particularly in the realm of large language models (LLMs), a significant disconnect exists between technical accuracy and the aspirational language that permeates the discourse. Terms like "deterministic" and "creative" are often used to describe the effects of the temperature hyperparameter, creating a misleading narrative that can obscure the true functioning of these models. This piece aims to clarify this issue using the simple example of generating a random number between 1 and 10.
Understanding Temperature in AI
To illustrate our point, let's consider generating a random number between 1 and 10. Assume we have a pre-trained distribution where the probabilities for selecting each number are as follows:
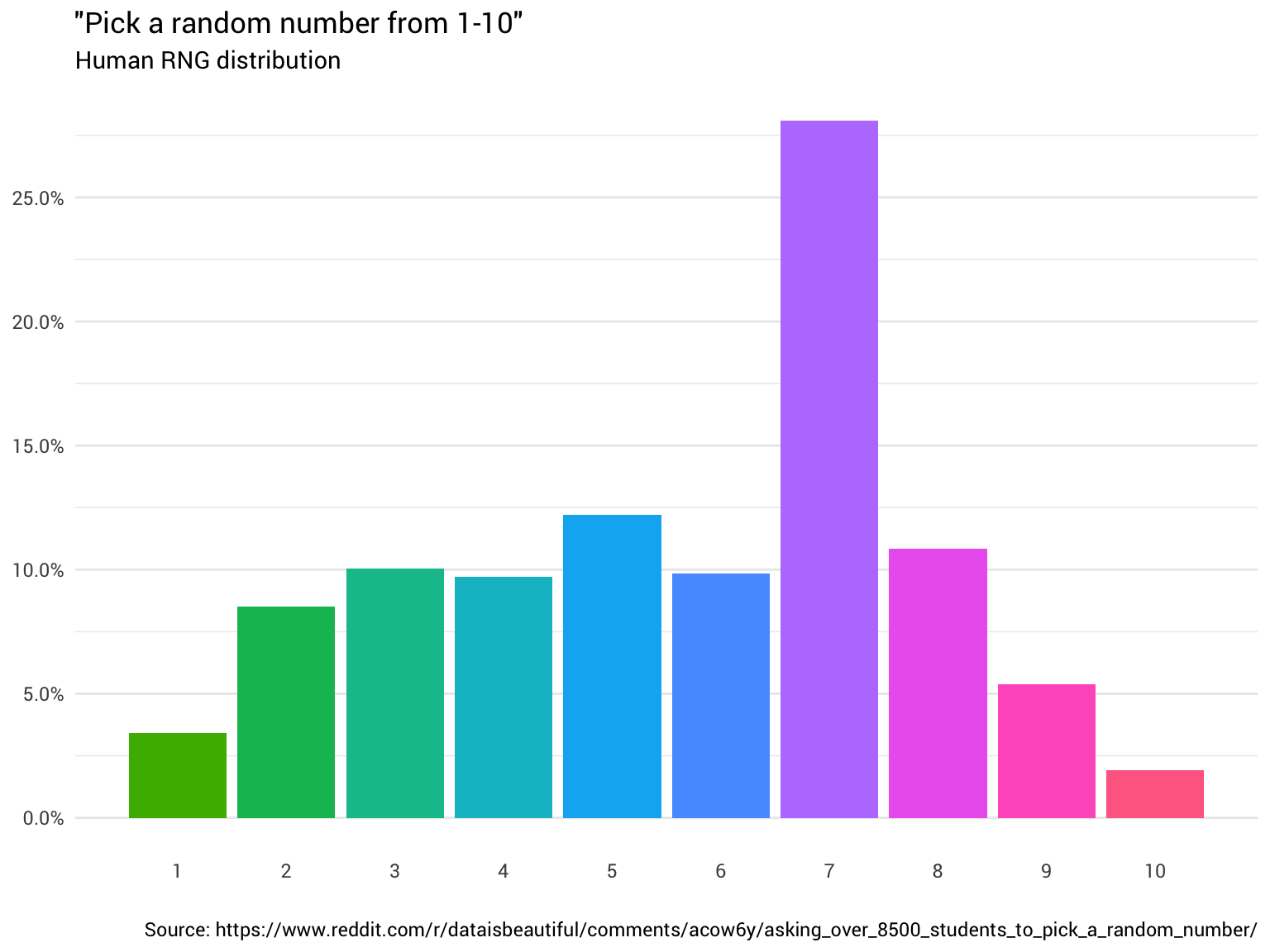
At a temperature of zero, the model is programmed to select the highest probability option, which in this case is 7 (with a probability of 99%, originally 28%), every time. This output is deterministic because it strictly adheres to the pre-trained distribution without introducing any variability.
As we increase the temperature to 0.5, the model begins to dampen the probabilities. In this scenario, the outputs would not be as skewed towards the highest probability, and the model might produce a more moderate selection. The probabilities might adjust to something like:
Number 1: 2% (0.02)
Number 7: 43% (0.43)
In this case, while number 7 is still the highest probability, the distribution is dampened, allowing for slightly more diversity in outputs without drastically altering the original probabilities.
Increasing the temperature to 1 allows the model to maintain the original distribution, where the chance of selecting the other numbers increases slightly, but the overall ranking remains intact.
Pushing the temperature beyond 1 begins to flatten the distribution, allowing less probable numbers to have a better chance of being chosen. For example, as the temperature rises to 2, the probability of selecting number 1 (initially only a 3% chance) increases significantly to 8%, while the probability of selecting number 7 decreases to (12%), leading to a more uniform distribution of outputs. Here is where the narrative often shifts to suggest that the model is being "creative" in its selection. However, this interpretation is misleading. While it may seem that the model is generating more diverse outputs, it is still fundamentally sampling from the same distribution established during training.
The Math Behind Temperature
To better understand how temperature influences the model's output, we can look at the mathematics involved, particularly the softmax function, which converts logits (the raw scores) into probabilities that determine what token the model selects next.
The probability p(xi) of selecting a particular token xi is calculated using the softmax function:
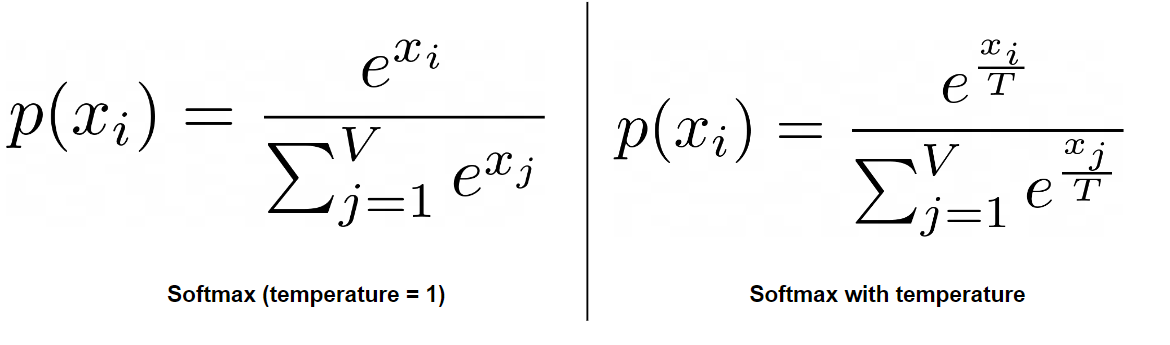
where:
xi are the logits (scores assigned to each possible token),
T is the temperature parameter that controls randomness.
At Temperature = 0: The model sampling becomes narrower, selecting only the tokens with the highest logit score if present. In our example, number 7 is selected 99% of the time, with all other options having negligible probabilities, resulting in consistent but narrower output.
At Temperature = 0.5: The softmax function begins redistributing probabilities while maintaining a strong preference for higher-scored tokens. Lower probabilities increase modestly (number 1 to 2%) while higher probabilities decrease moderately (number 7 to 43%), enabling controlled variation in outputs.
At Temperature = 1: The softmax function applies the model's original learned distribution without modification. Number 7 appears with its natural 28% probability, while other numbers maintain their learned relative frequencies from training.
At Temperature > 1: Higher temperatures increasingly flatten the probability distribution broaden the options explored. Number 1's probability rises to around 8%, while number 7 decreases to 15%. This broader distribution allows selection from more options, producing more varied outputs while still following the underlying learned patterns.
Thus, while temperature might appear to control creativity versus consistency, it's more accurately understood as a mechanism for adjusting how concentrated or spread out the token selection probabilities become, rather than changing the fundamental relationships learned during training.
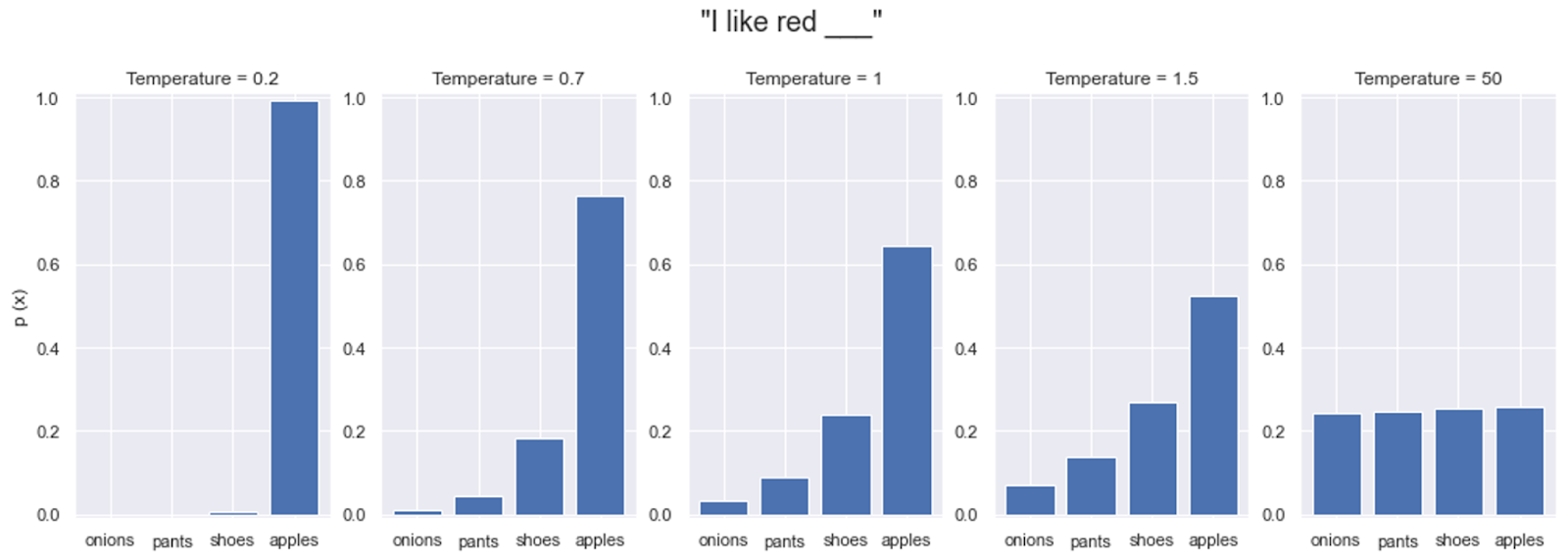
Example using a next token generation
Below a full spectrum across a generation "I like red" below, resulting in "apples" but decreasing from 99% (temp 0.2), 78% (temp 0.7), 62% (original distribution at temperature 1), 50% (temp 1.5) down to 20% (temp 50) as temperature increases, first allowing "shoes" and gradually enabling less common completions like "pants" (12%) and "onions" (2%) that appear less frequently in the training data.
The Misleading Narrative of Creativity
The terms "deterministic" and "creative" imply a kind of agency or cognitive capacity that these models simply do not possess. Higher temperature settings might lead to more varied outputs, but they do not equate to genuine creativity. The use of aspirational language without the necessary qualifications can lead to misconceptions about AI capabilities. It is essential to recognize that while outputs may appear more diverse, they remain constrained by the learned probabilities of the model.
This problem is not isolated to discussions surrounding temperature; it extends to various aspects of AI documentation and pedagogy. Terms like "learning," "understanding," and "intelligence" are often employed without sufficient context. While these terms resonate with a wider audience, they can contribute to a profound misunderstanding of the underlying principles that govern these technologies.
Implications of Hype in AI
The implications of this hype are significant. When AI is portrayed as capable of thinking, reasoning, or creating, it raises unrealistic expectations and may ultimately lead to disillusionment. This concern grows as AI technologies become increasingly integrated into our daily lives. Clear, accurate documentation and pedagogy can help foster a more informed understanding of AI, emphasizing its strengths and limitations without resorting to misleading analogies.
Conclusion
As we continue to navigate the complexities of AI, it is essential to prioritise clarity over hype. The temperature parameter in LLMs serves as a critical example of how terminology can shape our understanding of technology. By grounding our discussions in the actual mechanics of these systems, we can bridge the gap between technical accuracy and user expectations. The conversation about AI should reflect its true nature—powerful yet ultimately bound by the data it was trained on and the algorithms that govern its behavior. Only through precise language and clear explanations can we foster a more nuanced understanding of artificial intelligence and its capabilities.
Subscribe to my newsletter
Read articles from Gerard Sans directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Gerard Sans
Gerard Sans
I help developers succeed in Artificial Intelligence and Web3; Former AWS Amplify Developer Advocate. I am very excited about the future of the Web and JavaScript. Always happy Computer Science Engineer and humble Google Developer Expert. I love sharing my knowledge by speaking, training and writing about cool technologies. I love running communities and meetups such as Web3 London, GraphQL London, GraphQL San Francisco, mentoring students and giving back to the community.