Testing Recommendation Models in Production: A Deep Dive into Interleaving Experiments
 Juan Carlos Olamendy
Juan Carlos Olamendy
Imagine losing $2.5 million in revenue because your newly deployed recommendation model, which performed brilliantly in testing, suddenly fails to engage real users.
This nightmare scenario haunts e-commerce giants and streaming platforms alike.
While your model might boast impressive accuracy metrics in the lab, the harsh reality is that 76% of users ignore recommendations that don't immediately resonate with their interests.
But what if you could safely test new recommendation models in production without risking user experience or revenue?
Enter interleaving experiments – a battle-tested technique that giants like Netflix and Amazon use to validate their recommendation systems.
By cleverly mixing recommendations from both current and new models, this approach lets you measure real user engagement while minimizing risk.
In this guide, you'll discover how to implement interleaving experiments to evaluate recommendation models in production, protect your revenue, and ensure your recommendations actually drive user engagement.
Whether you're a data scientist, ML engineer, or technical lead, you'll learn the exact steps to validate your models with real users before full deployment.
If you want to hear the audiobook for this post:
The Challenge of Evaluating Recommendation Systems
In the world of machine learning, recommendation systems present a unique challenge.
These systems must not only predict user preferences accurately but also generate recommendations that drive real user engagement.
Traditional offline evaluation metrics like precision, recall, and RMSE (Root Mean Square Error) tell only part of the story.
The real test comes when users interact with these recommendations in production.
Consider this sobering reality: a model achieving 95% accuracy in offline tests might generate recommendations that users completely ignore.
This disconnect between offline performance and real-world effectiveness creates a critical need for better evaluation methods.
Enter interleaving experiments – a powerful technique for testing recommendation models in production environments.
Understanding Interleaving Experiments
Interleaving experiments represent a sophisticated approach to comparing recommendation models in live environments.
At its core, this technique involves simultaneously testing two versions of a recommendation model: the current production model (Legacy) and a new candidate model.
The system sends each user request to both models and combines their recommendations in the final response.
This approach allows for direct comparison while minimizing risk.
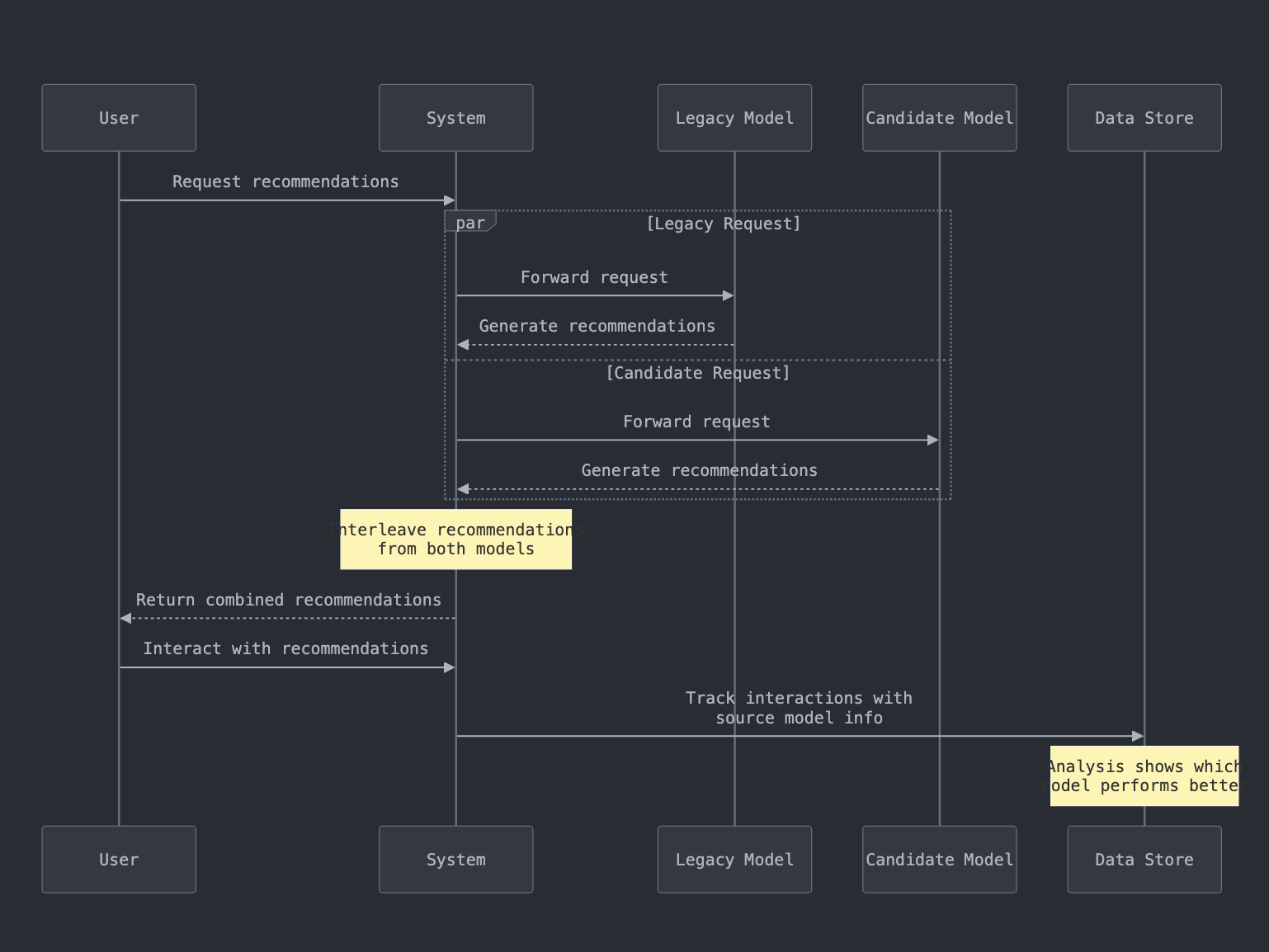
How Interleaving Works
The process follows a straightforward yet effective workflow:
A user requests recommendations from your system.
The request is simultaneously sent to both the Legacy and Candidate models.
Each model generates its set of recommendations.
The system interleaves recommendations from both models in the response.
User interactions with these recommendations are tracked and analyzed.
This methodology creates a controlled experiment where users unknowingly interact with recommendations from both models.
The beauty of this approach lies in its ability to provide real-world feedback while maintaining system stability.
Implementation Details: Building an Interleaving System
Architecture Overview
The implementation of an interleaving system requires careful consideration of several components:
- Request Handler:
Receives incoming user requests
Duplicates requests for both models
Manages response timing and aggregation
- Model Interface:
Maintains consistent API for both Legacy and Candidate models
Handles model-specific preprocessing requirements
Manages response formats
- Interleaving Logic:
Implements randomization strategies
Handles position bias mitigation
Maintains tracking information for later analysis
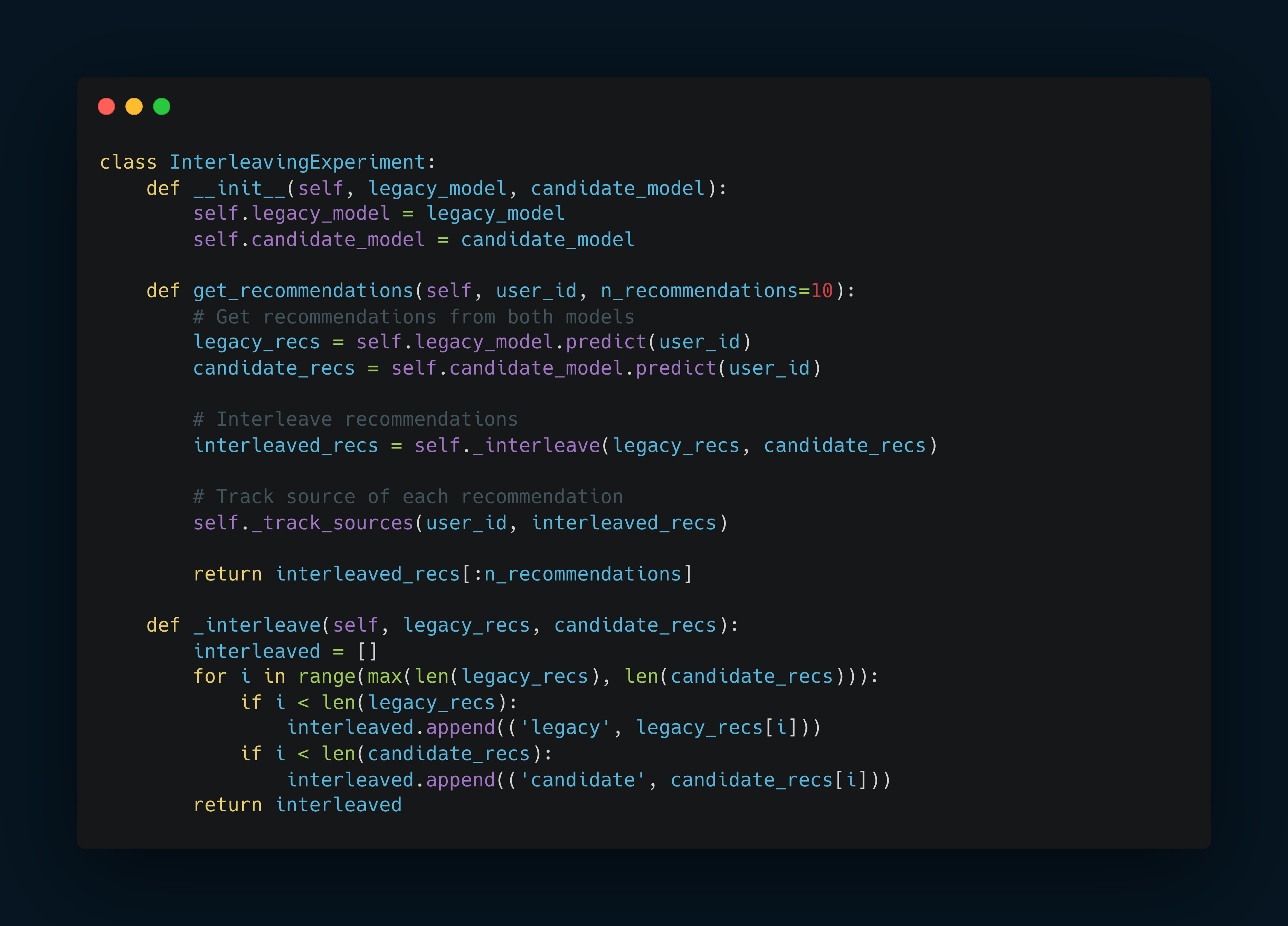
Code Example: Basic Interleaving Implementation
Measuring Success: Analytics and Metrics
If you like this article, share it with others ♻️
Would help a lot ❤️
And feel free to follow me for articles more like this.
Key Performance Indicators (KPIs)
When evaluating model performance through interleaving experiments, several metrics prove crucial:
- Click-Through Rate (CTR):
Measures user engagement with recommendations
Calculated separately for each model's recommendations
Provides immediate feedback on recommendation quality
- Conversion Rate:
Tracks successful transactions from recommendations
Indicates recommendation relevance and value
Often weighted more heavily than CTR
- Position-Adjusted Metrics:
Accounts for position bias in recommendation lists
Normalizes engagement rates based on position
Provides fairer model comparison
Data Collection and Analysis
The success of interleaving experiments heavily depends on proper data collection:
- Track essential information for each recommendation:
Source model (Legacy or Candidate)
Position in recommendation list
User interaction details
Timestamp and context
- Maintain detailed experiment logs:
Duration of experiment
Traffic allocation
System performance metrics
Any external factors affecting results
Addressing Common Challenges
Position Bias
Position bias represents one of the most significant challenges in recommendation systems.
Users tend to interact more with items at the top of a list, regardless of relevance.
This bias can skew experiment results if not properly addressed.
Implementing randomization and position-weighted metrics helps mitigate this issue.
Traffic Requirements
Successful interleaving experiments require sufficient traffic volume for statistical significance.
Most experiments need to run for at least two weeks to gather meaningful data.
Traffic volume requirements vary based on:
Desired confidence level
Expected effect size
Baseline conversion rates
Technical Implementation Challenges
Several technical challenges require careful consideration:
- Response Time Management:
Both models must return recommendations quickly
System needs to handle timeout scenarios
Latency impact should be minimized
- Error Handling:
Graceful degradation when one model fails
Consistent logging of errors and exceptions
Fallback mechanisms for system stability
- Data Consistency:
Maintaining consistent user profiles
Handling real-time updates
Managing recommendation pools
Best Practices and Recommendations
Planning Your Experiment
- Define Clear Success Criteria:
Set specific performance targets
Establish statistical significance thresholds
Define experiment duration upfront
- Monitor System Health:
Track system performance metrics
Monitor error rates and latency
Establish automated alerts
- Document Everything:
Maintain detailed experiment logs
Record all configuration changes
Document decision-making process
Implementation Guidelines
Follow these guidelines for successful implementation:
- Start Small:
Begin with a small percentage of traffic
Gradually increase exposure
Monitor system stability closely
- Use Consistent Evaluation:
Maintain consistent metrics throughout
Use the same evaluation period for both models
Account for seasonal variations
- Plan for Scalability:
Design systems to handle increased load
Implement efficient data storage
Consider future experiment requirements
Conclusion
Interleaving experiments represent a powerful tool for evaluating recommendation models in production.
This approach combines scientific rigor with practical risk management.
By following the guidelines and best practices outlined in this article, you can implement effective interleaving experiments in your own systems.
The future of recommendation system evaluation lies in these real-world testing methodologies.
As systems become more complex, the importance of practical evaluation techniques will only grow.
Interleaving experiments provide a robust framework for making data-driven decisions about model deployment and improvement.
If you like this article, share it with others ♻️
Would help a lot ❤️
And feel free to follow me for articles more like this.
Subscribe to my newsletter
Read articles from Juan Carlos Olamendy directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Juan Carlos Olamendy
Juan Carlos Olamendy
🤖 Talk about AI/ML · AI-preneur 🛠️ Build AI tools 🚀 Share my journey 𓀙 🔗 http://pixela.io