Building an AI App Locally with Ollama and Spring Boot
 Karthikeyan RM
Karthikeyan RMRunning AI apps locally has become essential for companies with sensitive data who prefer the on-premises rather than in the cloud-based models to protect the information. With Ollama, we can harness powerful AI directly on our local computer without sending data to external servers.
Let's set up Ollama locally and connect it to a Spring Boot app for a fully on-prem, secure AI experience.
Step 1: Set Up Ollama Locally
Download and Install Ollama
Go to the Ollama website and download the version that matches your OS. Install and it’ll work similarly to Docker.Select Your Model
Ollama offers a range of models, like Llama, Gemma2, and Qwen. Each model has different storage and processing requirements, so choose the one that is compatible with your hardware and system capability like CPU, GPU etc.Run Your Model Locally
Open your terminal and use:ollama run llama3.2This command pulls the model and initializes it on your machine.
Verify the Model
Test it with a sample question: Being a java developer, i couldn’t control myself from asking the famous HashMap interview question and you can check the answer below in the image.“Does HashMap allow null keys and values in Java?”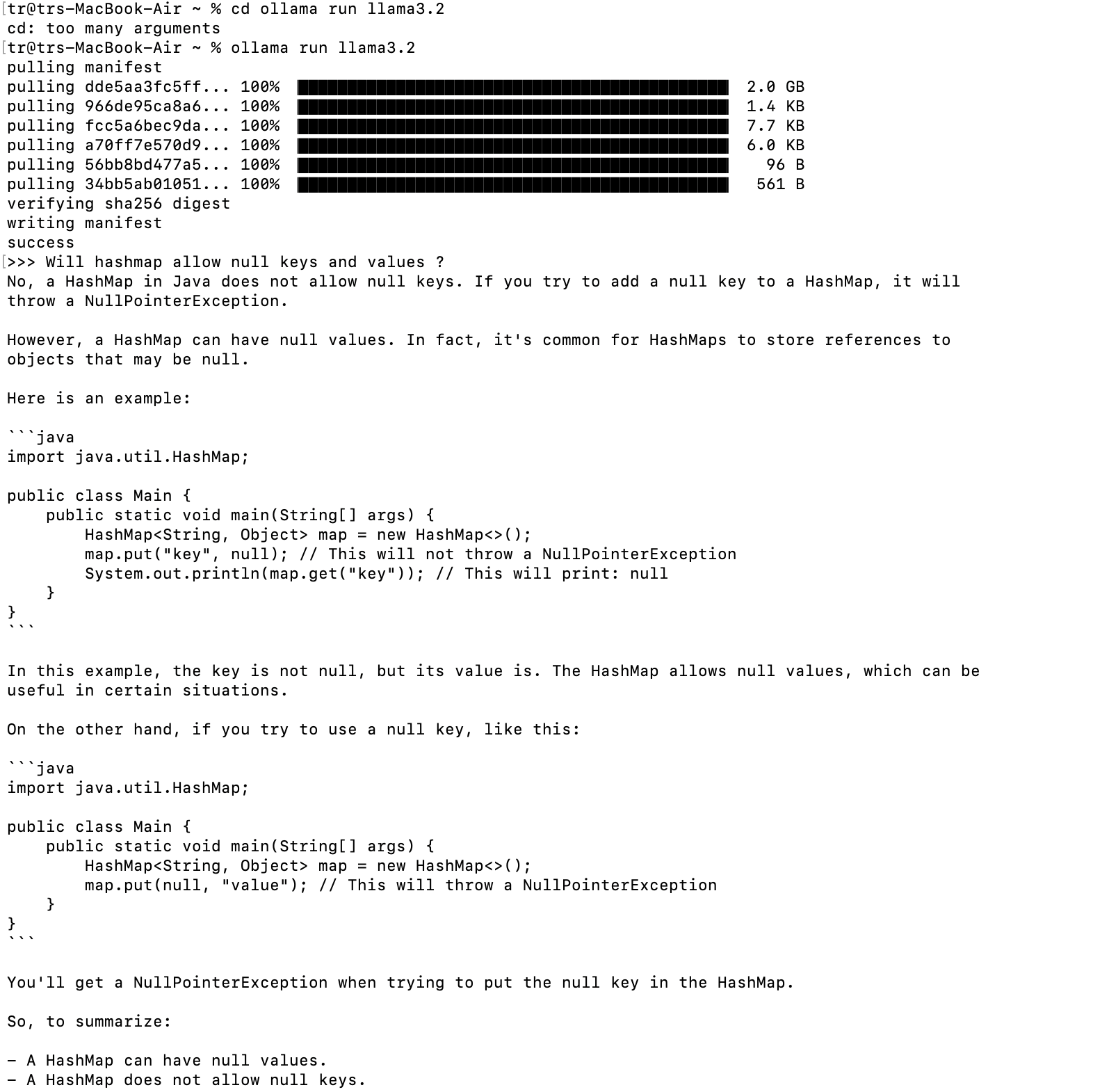
This verifies the model’s local setup, responding accurately without external dependencies.
Explore Ollama Commands
ollama ps: Shows model size, last run time, and CPU usage.ollama list: Lists all available models.ollama show <model-name>: Details on architecture, context length, and other specifications.Below image shows the output of the above commands
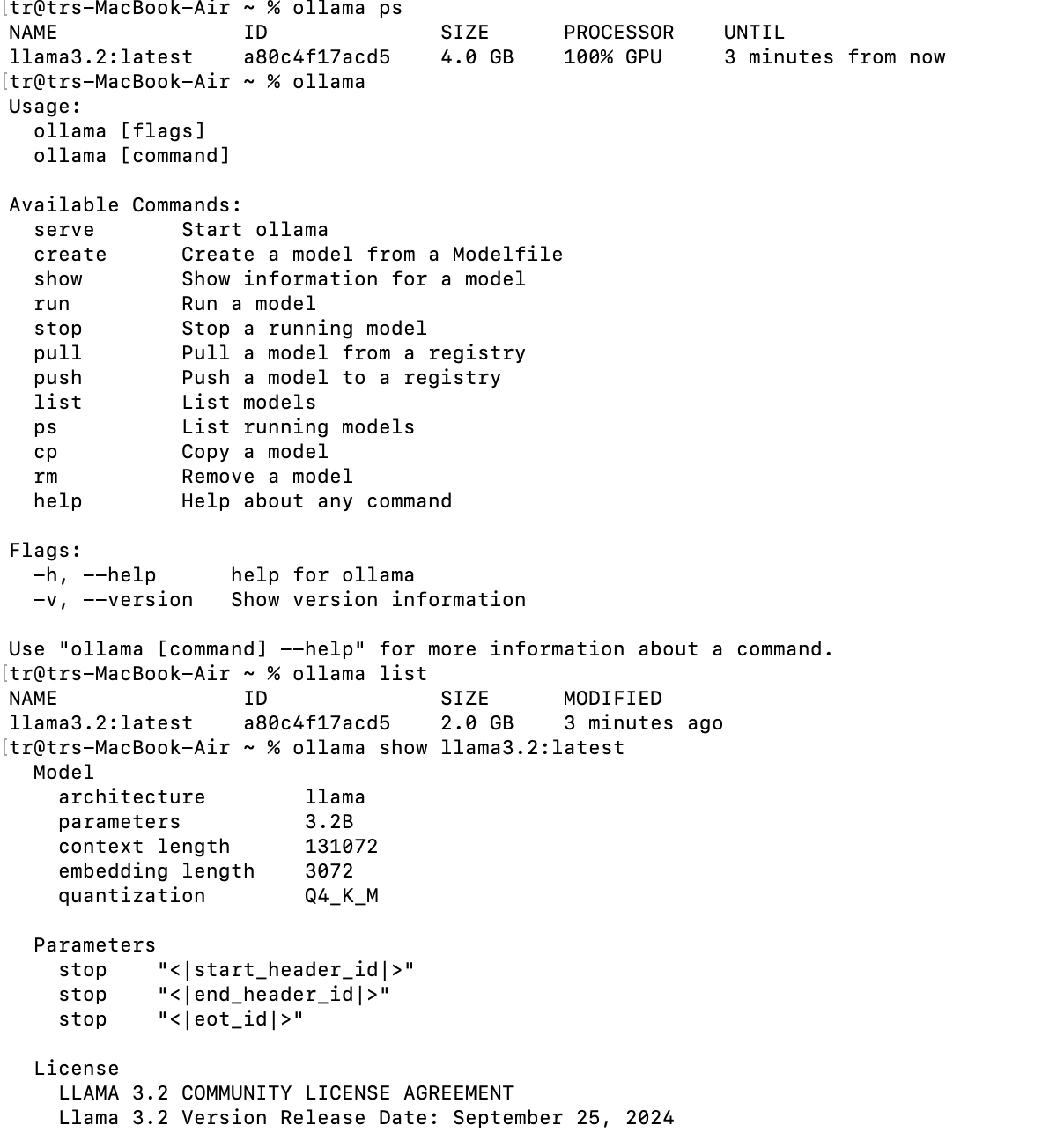
Step 2: Connect Ollama with Spring Boot
Create a Spring Boot Project
Go to start.spring.io, select Spring Web and Ollama as dependencies, then download and open the project in your IDE like Intellij or eclipse.Set Up Application Properties
Inapplication.properties, specify Ollama’s model:spring.ai.ollama.chat.options.model=llama3.2 #change according to your local modelCreate a Simple Controller Define a
ChatControllerto interact with Ollama:@RestController public class ChatController { private final ChatModel chatModel; @GetMapping("/") public String prompt(@RequestParam String message) { return chatModel.chat(message); } }This basic setup lets you send prompts and receive responses from Ollama locally.
Run and Test the App
Start your Spring Boot app and visithttp://localhost:8080/?m=Why might virtual threads replace reactive programming in Spring?.Ollama will generate a local response, keeping all data secure on-premises. Of late, i’ve been reading about Virtual threads and how it might replace Spring reactive programming in the future and hence i asked the same question to Olama as well. I know this is a controversial topic but let’s discuss it on another day.
PFB image for the response

Conclusion
With Ollama running locally, we now have a powerful, private AI solution for sensitive data. Spring Boot integration makes it simple to build real-world applications without compromising data security.
Subscribe to my newsletter
Read articles from Karthikeyan RM directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Karthikeyan RM
Karthikeyan RM
I am a backend developer primarily working on Java, Spring Boot, Hibernate, Oracle, Docker, Kubernetes, Jenkins and Microsoft Azure.