ML Classification: Support Vector Machine (SVM)
 Fatima Jannet
Fatima Jannet
Support Vector Machines (SVMs) were initially developed in the 1960s and refined in the 1990s. Currently, they are becoming very popular in machine learning because they have demonstrating that they are very powerful and somewhat different from other machine learning algorithms. We will find what makes them special.
Let’s start!
SVM Intuition
Suppose we have two columns on data. Now how do we separate them in a way that it prevents a new data from entering into the wrong region? We can draw a horizontal line between them, or a vertical line. Or a slightly tilted line. The possibilities are unlimited but which one is the right approach? SVM will help you here finding the best divider cause that’s all SVM is all about.
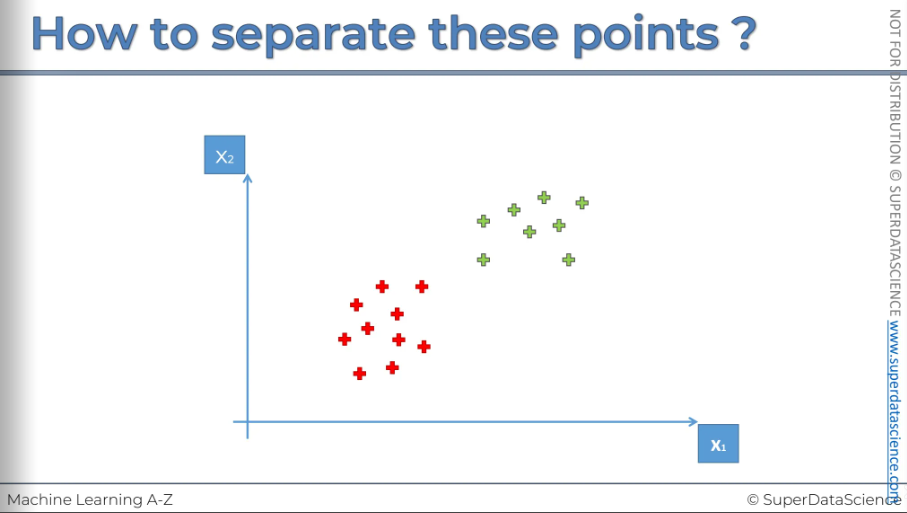
How SVM searches for the appropriate line? It finds the line through maximum margin. Here you can see a blue line, this a line SVM will draw in a way that the line will separate the two regions also it will be the maximum margin at a same time meaning the distance from the red point and the green point (marked in the plot) will be equidistance. The two point are called the support vectors, they are supporting the whole algorithm. Even if you eliminate rest of the points, nothing will change in the algorithm. The other points don’t contribute in the algorithm at all.
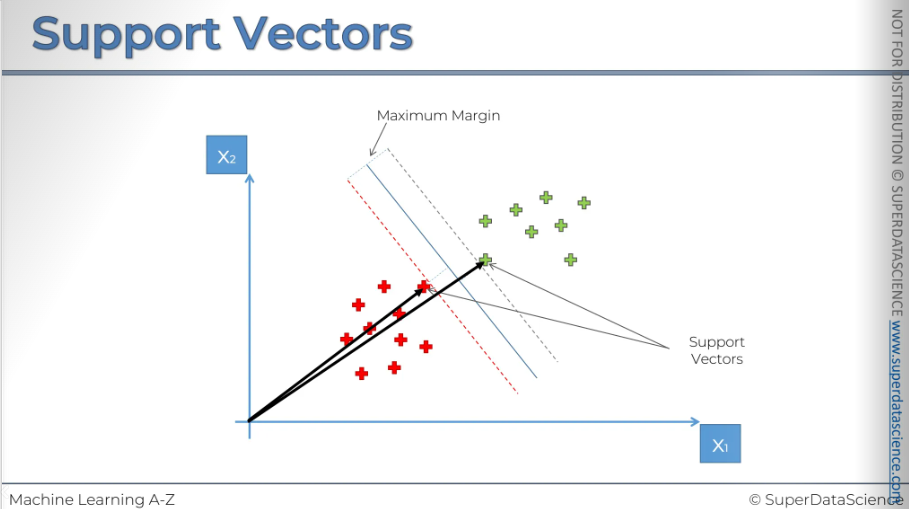
Let’s look at what else we have here.
We got a line in the middle which is called Maximum Margin Hyperplane. In a 2D space, it’s a classifier but in multi dimensional space - it’s a hyperplane. Then we got a red and green line, the green one is called a positive hyperplane and the red one is called a negative hyperplane. The order doesn’t matter here.
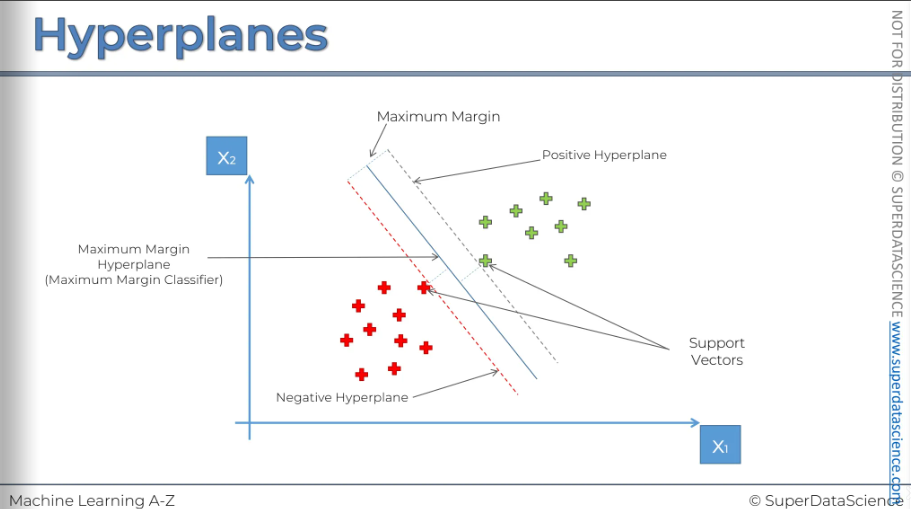
Now why are they so popular?
Imagine you're trying to teach a machine to tell the difference between apples and oranges, to classify a fruit as either an apple or an orange. You tell the machine, "I'm going to give you some test data. Look at all these apples and oranges. Analyze them, see what features they have. Then, next time, I'll give you a fruit, and you'll need to classify it and tell me whether it's an apple or an orange." This is a typical machine learning problem.

Now in our case here you can see let's say on the right we have oranges on the left we have apples. A machine would try to learn from apples that are very similar to apples so it would know what an apple is. It would also learn from oranges to understand what an orange is. This is how most machine learning algorithms work. Based on this learning, the machine can make predictions and classify new data elements and variables. But-
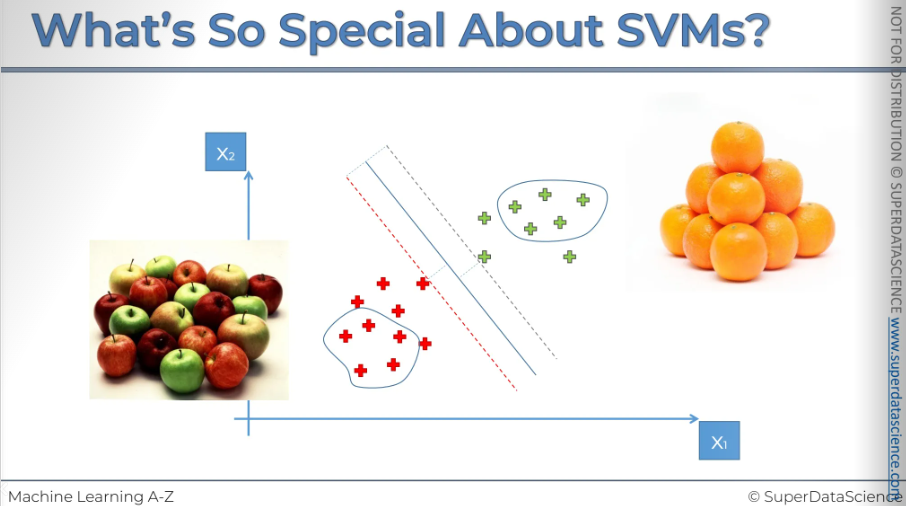
In the case of a support vector machine, it's a bit different. Instead of looking at the most stock standard apple like apples and orange like oranges, this machine will look at the apples that looks like an orange.
Look at the picture here. This is not your standard apple, this is an orange color apple. It’s a very confusing apple!
As for the oranges (ignore the lemon here), it will look for the orange which doesn’t have an orange like feature, for example the green orange over here. We have a green orange. It's not normal to have a green orange. when you think of orange you think of orange orange. And so what that is is.
These are the support vectors.
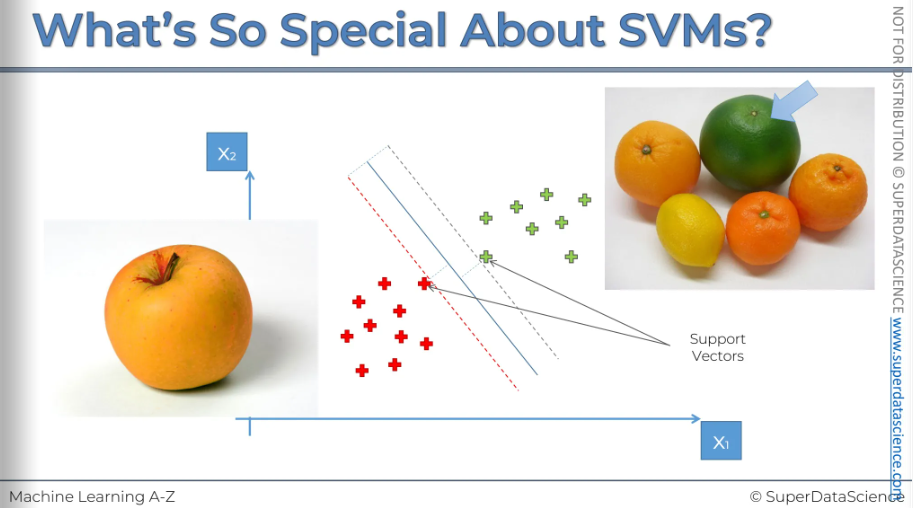
Those are the support vectors. You can see that they are very close to the boundary. The red apple is very close to the green ones, and the green orange is very close to the red ones. In this way, the support vector machine is like a more extreme, rebellious, and risky algorithm because it focuses on these edge cases near the boundary to make its analysis.
This approach makes support vector machine algorithms very unique and different from most other machine learning algorithms. That's why they sometimes perform much better than non-support vector machine algorithms.
I hope this explanation and intuition about support vector machines was helpful.
SVM in python
Resources:
Colab file: https://colab.research.google.com/drive/1vUn0Yb58j4vjq99hnYv-ul91FHySIKtD (save a copy in drive)
Data sheet: https://drive.google.com/file/d/1G1QLiNndysY8kZDnqHQTiTpw6sqoDxbq/view (upload this file in your colab copy)
[From scikit learn]
Training the SVM model on the Training set
We are starting from Training the SVM model on the Training set cause everything before this is similar with logistic regression and K-NN. So there’s no need to reintroduce them here again.
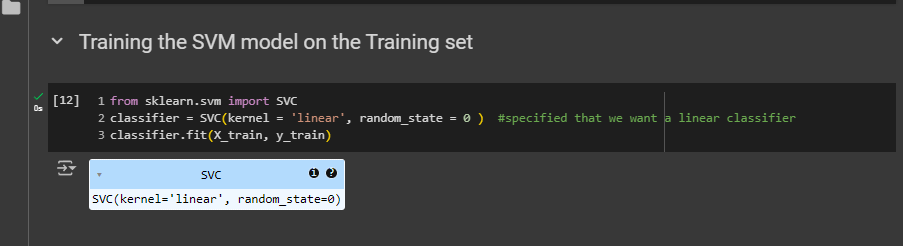
I haven’t described it much, as we have done this in every single code. This should be a native language to you by now (I hope). And i looked what i needed to put in the param from the scikit learn website.
Making the Confusion Matrix
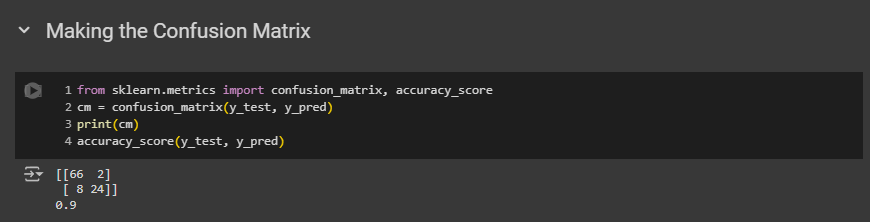
Okay, the accuracy is quite good. Logistic regression had 0.89, and SVM beats logistic by 1%. However, it did not surpass the K-NN model. K-NN had 0.9 accuracy.
Why it didn’t beat it?
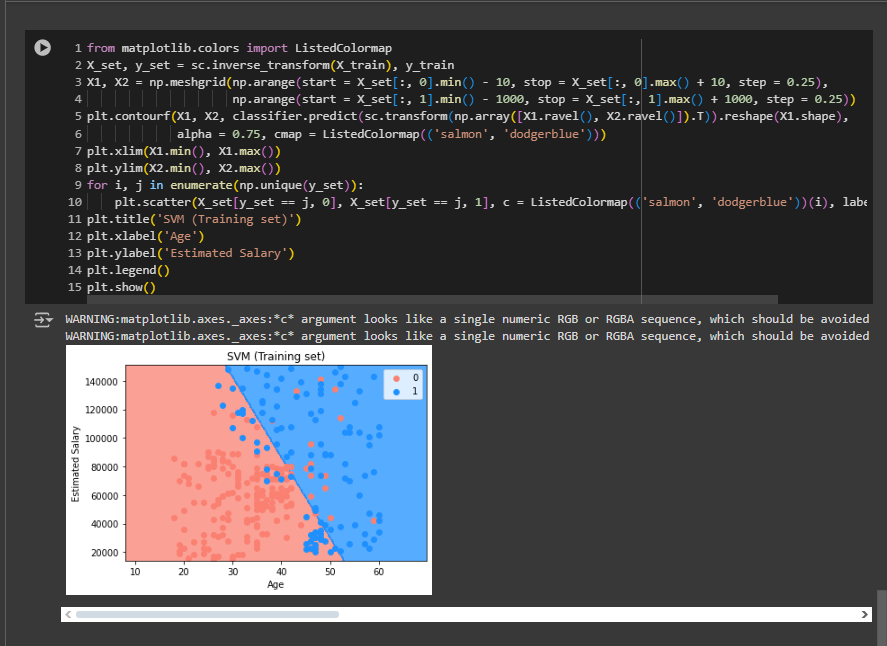
Well, as you can see the as boundary is linear, it failed to catch a lot of errors. On the other hand, K-NN had a curve like boundary. This is the reason SVM couldn’t beat K-NN.
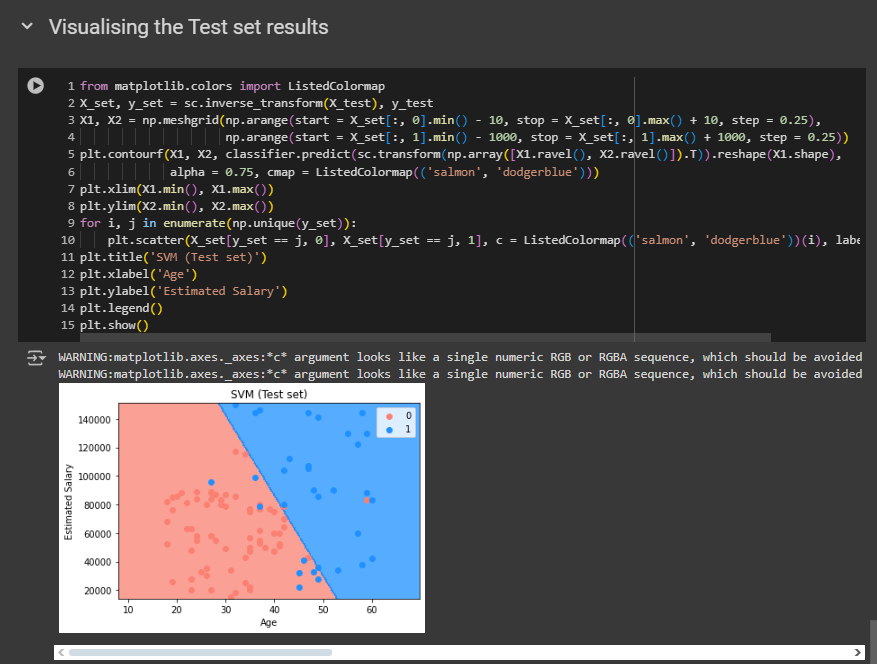
Same goes for the test result too! This problem will be solved if we choose non-linear model for kernel.
SVM Quiz




Answer:
Optimal line or decision boundary to separate the classes.
Yes
Support vectors
Maximum margin classifier
Yes
Subscribe to my newsletter
Read articles from Fatima Jannet directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by