Understanding Activation Functions in GANs
 Arya M. Pathak
Arya M. Pathak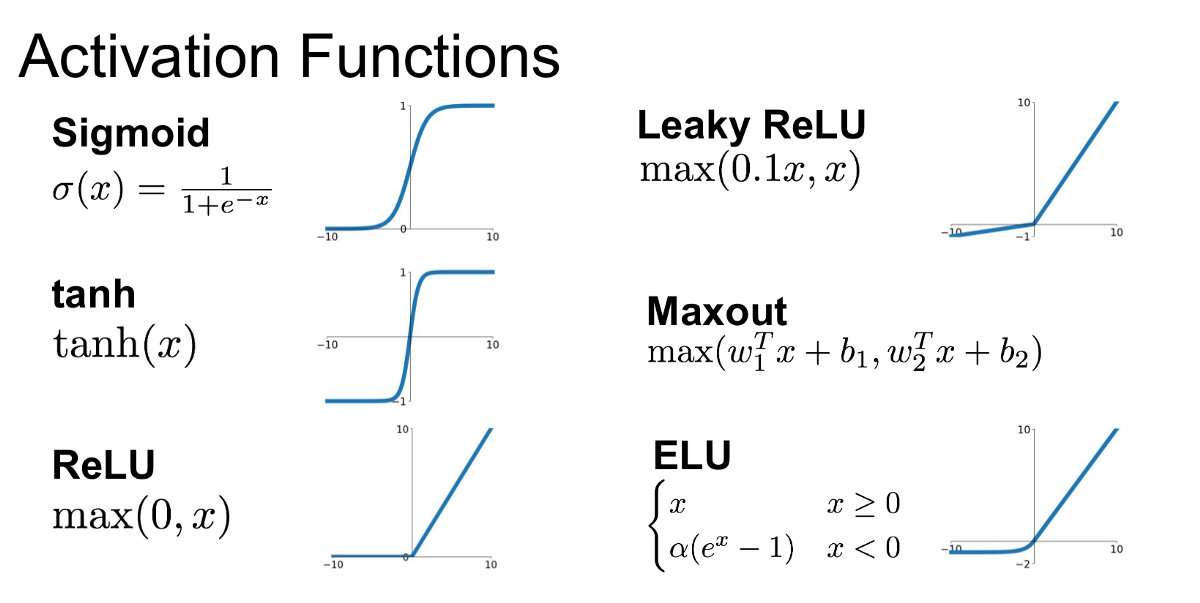
Generative Adversarial Networks (GANs) have gained significant traction in deep learning, largely due to their ability to generate data resembling real-world data. Central to the functionality and performance of GANs are activation functions, which introduce non-linear properties essential for learning complex patterns. Activation functions are non-linear and differentiable functions applied to neurons to determine whether they should be activated or not. These functions allow neural networks to represent more complex functions, making them crucial in GAN architectures, where realistic and diverse data generation is the goal. By analyzing the differentiability and non-linear nature of these functions, we can understand their role in enabling GANs to create intricate and high-quality data outputs. This article explores activation functions in GANs, discussing the importance of non-linearity, common functions used, their pros and cons, and provides practical PyTorch code examples for each.
(For further foundational insights on deep learning activations, refer to resources by deeplearning.ai.)
Why Activation Functions are Non-linear and Differentiable
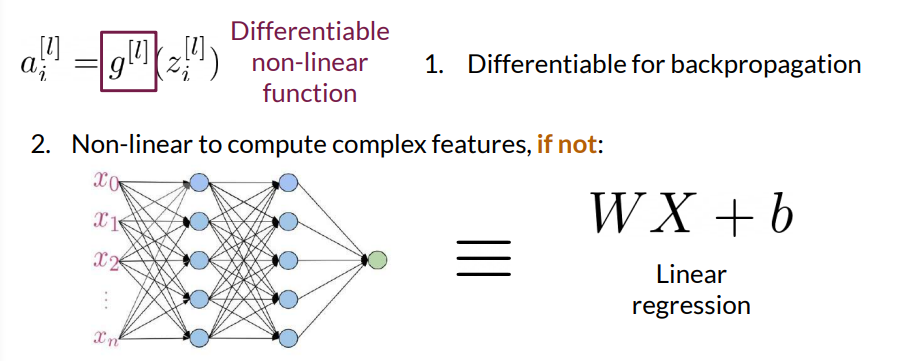
An activation function receives input (often denoted \(z \) ) and produces output \(a = g(z)\) , where \(g\) is the activation function. The role of these functions is twofold:
Non-linearity: If activation functions were linear, stacking multiple layers would yield a network that could be mathematically simplified to a single linear transformation, rendering the model incapable of learning complex patterns. By introducing non-linearity, networks can model intricate relationships in data.
Differentiability: For backpropagation to work efficiently, activation functions must be differentiable, as the gradient of the loss function with respect to the model parameters needs to be computed to update weights and biases.
In GANs, non-linear activation functions help both the generator and discriminator networks model complex mappings. Without non-linearity, the generator would struggle to create realistic data, and the discriminator would find it difficult to distinguish real data from generated data.
Common Activation Functions in GANs
Below are some widely used activation functions in GANs, each with its characteristics and limitations:
1. Rectified Linear Unit (ReLU)
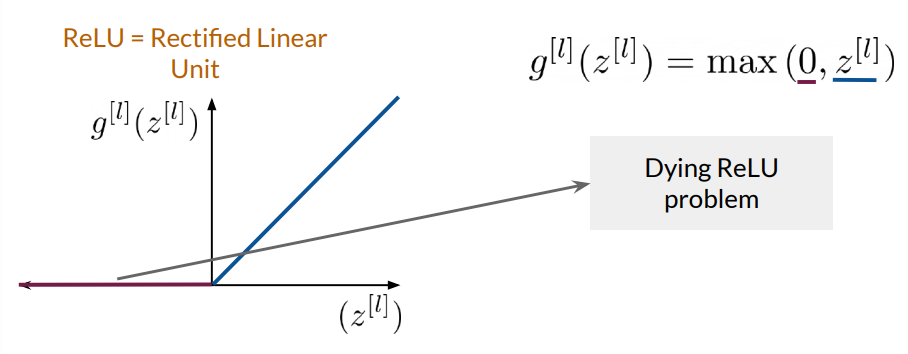
The ReLU function is straightforward and efficient, setting any negative input to zero and outputting the positive values as they are. Mathematically, it’s represented as:
$$g(z) = \max(0, z)$$
This non-linearity is computationally efficient and helps mitigate the vanishing gradient problem, making it ideal for hidden layers.
However, ReLU can suffer from the "dying ReLU" problem, where neurons get stuck outputting zero due to the derivative being zero for negative inputs.
PyTorch Implementation:
import torch
import torch.nn as nn
# ReLU Activation
relu = nn.ReLU()
# Example tensor input
z = torch.tensor([-1.0, 0.0, 2.0])
output = relu(z)
print(output)
2. Leaky ReLU
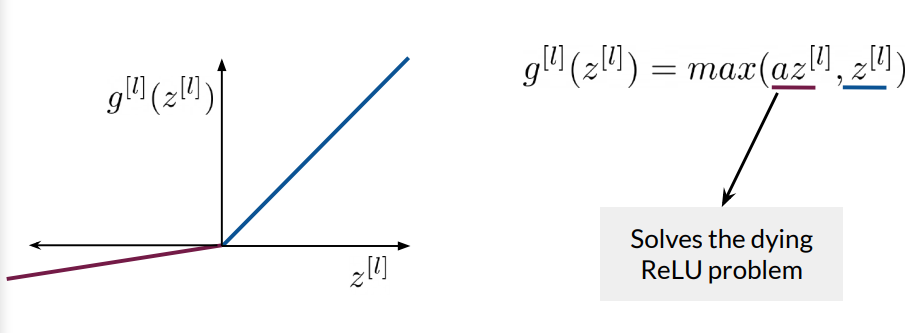
Leaky ReLU addresses the dying ReLU problem by introducing a small gradient (often 0.01) for negative inputs. The function is defined as:
$$g(z) = \begin{cases} z & \text{if } z > 0 \\ \ \alpha z & \text{if } z \leq 0 \end{cases}$$
This allows for a non-zero gradient even for negative inputs, reducing the risk of neuron death while maintaining non-linearity.
PyTorch Implementation:
# Leaky ReLU Activation
leaky_relu = nn.LeakyReLU(0.01)
# Example tensor input
output = leaky_relu(z)
print(output)
3. Sigmoid
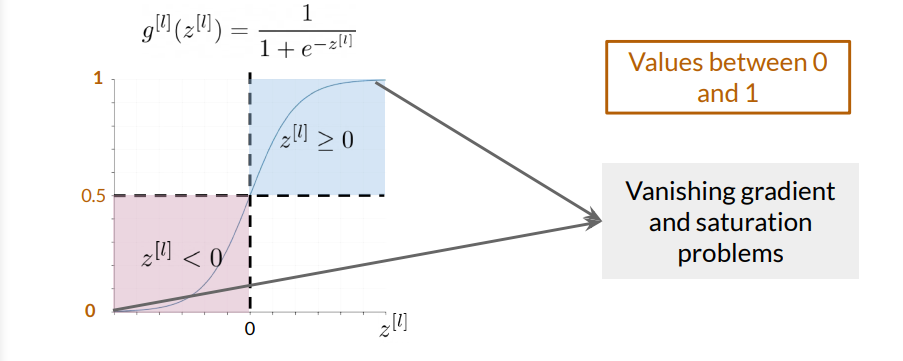
The Sigmoid function is commonly used in binary classification problems, as it outputs values between 0 and 1, representing probabilities. It is expressed as:
$$g(z) = \frac{1}{1 + e^{-z}}$$
However, Sigmoid functions can lead to vanishing gradients when the input \(z \) is very large or very small. This makes them less favorable in hidden layers but useful in the GAN’s discriminator output layer, where probability output is needed.
PyTorch Implementation:
# Sigmoid Activation
sigmoid = nn.Sigmoid()
# Example tensor input
output = sigmoid(z)
print(output)
4. Hyperbolic Tangent (Tanh)
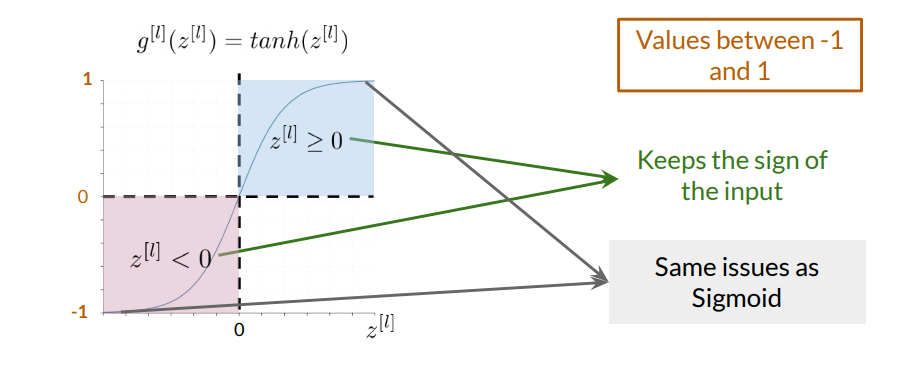
Tanh is similar to Sigmoid but outputs values between -1 and 1, which helps maintain the sign of the input. Its formula is:
$$g(z) = \frac{e^{z} - e^{-z}}{e^{z} + e^{-z}}$$
While Tanh also suffers from vanishing gradients, its output range can be useful in GANs, especially in the generator’s output layer to ensure diverse generation of features.
PyTorch Implementation:
# Tanh Activation
tanh = nn.Tanh()
# Example tensor input
output = tanh(z)
print(output)
Choosing the Right Activation for GAN Layers
In GANs, the generator and discriminator play distinct roles, influencing activation choice. Typical GAN configurations might look like this:
Generator: ReLU or Leaky ReLU is commonly used in hidden layers to prevent neuron saturation and to keep computation efficient, with Tanh often used in the output layer to create realistic data.
Discriminator: Sigmoid is often used in the output layer to signify the probability of data being real or fake, with ReLU or Leaky ReLU in hidden layers to avoid vanishing gradients.
Sample GAN Code with Activation Functions in PyTorch
Below is an example GAN architecture using ReLU and Sigmoid in PyTorch:
import torch
import torch.nn as nn
# Generator Network
class Generator(nn.Module):
def __init__(self, input_dim, output_dim):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(input_dim, 128),
nn.ReLU(),
nn.Linear(128, 256),
nn.ReLU(),
nn.Linear(256, 512),
nn.ReLU(),
nn.Linear(512, output_dim),
nn.Tanh() # Output layer for generated data
)
def forward(self, x):
return self.model(x)
# Discriminator Network
class Discriminator(nn.Module):
def __init__(self, input_dim):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(input_dim, 512),
nn.LeakyReLU(0.2),
nn.Linear(512, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 128),
nn.LeakyReLU(0.2),
nn.Linear(128, 1),
nn.Sigmoid() # Output layer for classification
)
def forward(self, x):
return self.model(x)
# Example usage
generator = Generator(input_dim=100, output_dim=784)
discriminator = Discriminator(input_dim=784)
# Example noise input for generator
z = torch.randn((1, 100))
generated_data = generator(z)
decision = discriminator(generated_data)
print(decision)
Conclusion
Activation functions are fundamental in GANs, enhancing their ability to learn complex patterns by introducing non-linear transformations and enabling efficient backpropagation through differentiability. The choice of activation functions, such as ReLU, Leaky ReLU, Sigmoid, and Tanh, significantly impacts GAN performance. Each function has its pros and cons, which can be leveraged based on the GAN layer type, enabling both generators and discriminators to converge toward realistic data generation.
For more on the technical underpinnings of activation functions, visit deeplearning.ai.
Subscribe to my newsletter
Read articles from Arya M. Pathak directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Arya M. Pathak
Arya M. Pathak
I am a Computer Engineering undergraduate at Vishwakarma Institute of Technology, Pune . With hands-on experience in software development and cloud-native applications, I specialize in Python, Go, C#, and full-stack web development using MERN, ASP.NET Core, and Angular. I have interned at Alemeno and CodingKraft, where I developed AI-driven compliance systems, Python execution engines, and secure web solutions. My projects include scalable microservices, machine learning pipelines, and secure banking APIs deployed on cloud platforms like Azure with Kubernetes and CI/CD automation. Adept in tools like Docker, Redis, RabbitMQ, and GitHub Actions, I am certified in Deep Learning and DevOps. I have a strong foundation in algorithms, having solved over 350 coding problems across platforms like Leetcode and Codeforces. Additionally, I actively contribute to open-source projects, mentoring initiatives, and hackathons.