Building Authorization in AI Apps
 Keith Casey
Keith Casey
When we look at the current state of generative AI, we think of products like ChatGPT, Google Gemini, Claude, and similar. Those are all publicly available tools trained on public data and useful for general topics for a general audience. But if we expect these tools to be useful within the enterprise, we need to build models unique to our organization, our domains, and our operations.
And that puts us into a different world.
Instead of public data, we’re working with information from specific departments and systems. Some of that information will still be public - like product docs and whitepapers - but the vast majority will relate to sensitive matters like department budgets, future product plans, and even personnel decisions. If we only consider filtering sensitive information at response time, we’ve already failed. We ingested the data, built our models, and created a response completely detached from the data’s source and ownership, making authorization effectively impossible.
Establishing an Authorization Provenance
Years ago, I worked at the Library of Congress and learned the concept of “provenance” or understanding where an item came from and how. In the library world, this lets us establish attribution and ownership - and therefore rights - all of which become the foundation of authorization policy. We need to build an Authorization Provenance to track the data back to its sources to understand and describe the who, where, and how for each item.
In practical terms, we can split this into three tightly coupled steps:
Collecting sources
Ingesting data
Building our response
Collecting Authorization from Sources
When we think about data inside our organization, it’s likely stored in places like Google Docs, Confluence, Box, and other systems that require authentication. Luckily, that makes our first step exceptionally easy.
For the ingestion pipeline to access these items, we have to provide it with a credential scoped to read the relevant files. You could approach this three different ways:
Many of these systems will use OAuth so you can perform a user-based OAuth flow to grant access to your files. With Pangea’s AuthN, this is handled via the Social Auth capabilities and the output is an access token scoped to your user and the permissions you’ve granted.
Alternatively, with the OAuth Client Credential flow, you may be able to generate a machine to machine connection to enable the ingestion pipeline to create and use its own tokens.
Finally, you may have a generic API key generated by that system.
Regardless of your approach, the resulting access token, client id and secret, or even API key is a credential which you must store and use safely. In our model, we would store that in the Pangea Vault.
Overall, this process looks something like this where an Admin has to register sources with the ingestion tool:
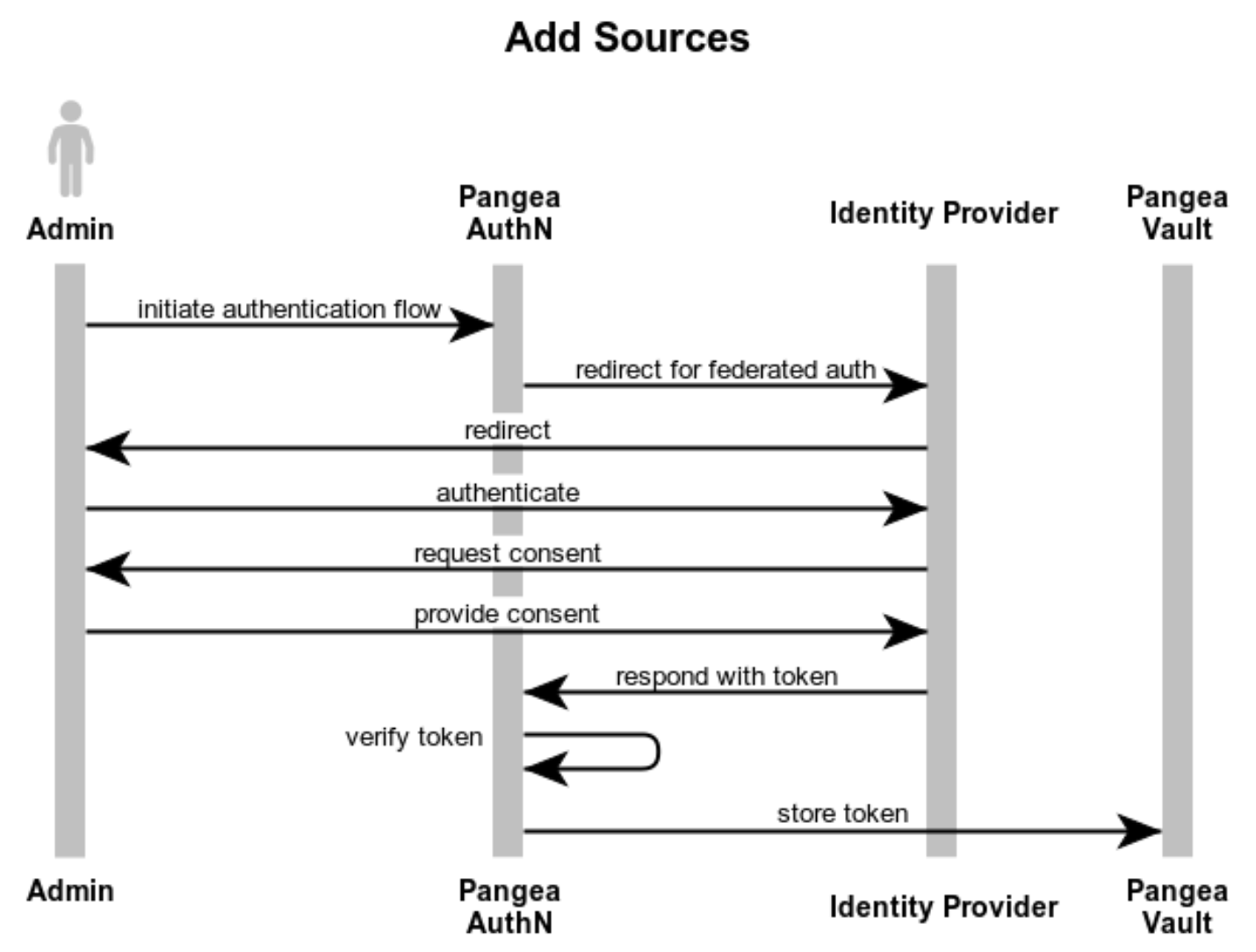
By the end of this, the ingestion tool has a number of sources available along with credentials for each. This gives us everything we need to begin ingesting both the data and our authorization policy.
Adding Authorization to our Ingestion Pipeline
Now that we have access to the data, we can ingest it.
First, we retrieve the credentials from our Vault and then retrieve the objects from our data store.
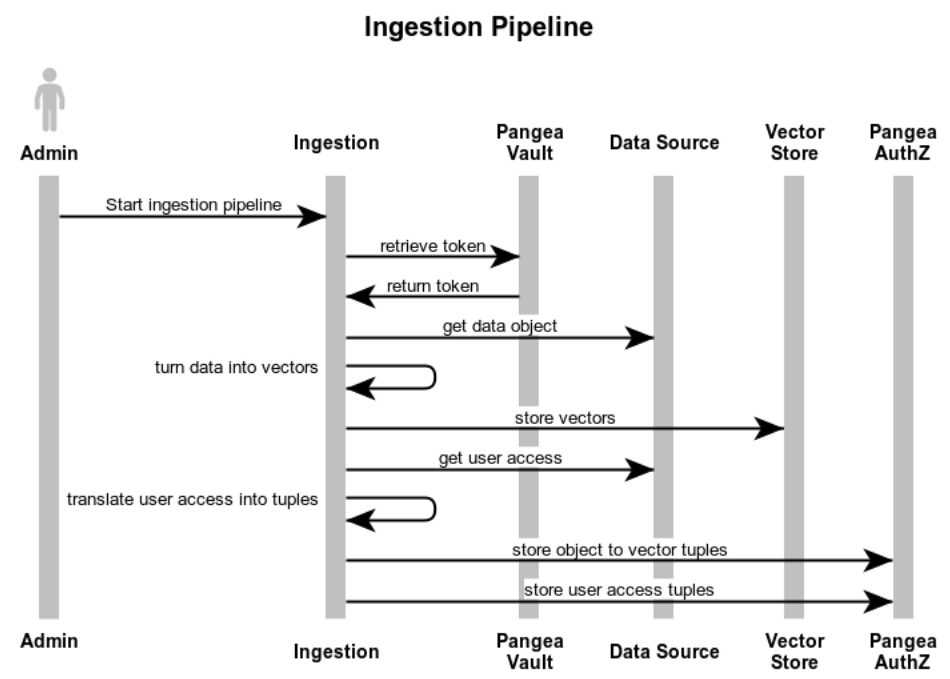
Then - just as with a non-authorization-aware system - we transform those objects into their individual vectors and store them in our vector database. Then instead of moving onto the next object, we query the original source to understand the object and understand its relationships.
To turn those relationships into authorization policy, we need to understand the object’s source and its users. For the source, it could be a logical source such as “Google Docs” or “Confluence” or an organization source such as Engineering, Marketing, or HR. In this case, they both reduce to a simple authorization schema:
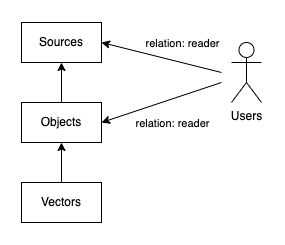
When we examine the object's users, some of our logical sources - like Google Docs - have robust authorization schemas expressed by roles and permissions queryable via API. Because we’re only extracting information and not granting write access to the original source, we can collapse numerous relationships (editor, owner, commenter, reader) to a simple read access.
By the end of this process, we have vectors which we can map to objects which we can map to sources. Further, we have objects which we can map to users. All of these can be expressed in a simple AuthZ schema as shown where read access to a source grants access to its objects and their vectors - or alternatively - read access of an object grants access to its vectors.
While this is mostly laid out with the perspective that Google Docs is our source, we can use the same approach by declaring the “HR Folder” a source and inherit permissions downward for users.
Applying Authorization to our Inference Pipeline
Finally, we get to our end user facing component: the inference pipeline.
Just as with a non-authorization-aware system, we accept the user’s prompt, apply our redaction and sanitization, and collect the vectors to build our response. At this point, we have a unique opportunity: we can examine our vectors both before and after applying our AuthZ policy. Why is this important?
For example, imagine a user asks “Which planet has the most moons?”
The correct answer is “Saturn” which has over 140 moons.
But if your authorization policy blocks the user’s access to information on Saturn, they will get a wrong answer (aka hallucination).
Alternatively, if we collected the resulting vectors, filtered them based on AuthZ policy, and compared the input vectors against the output vectors, we would see the large difference and detect authorization-based differences.
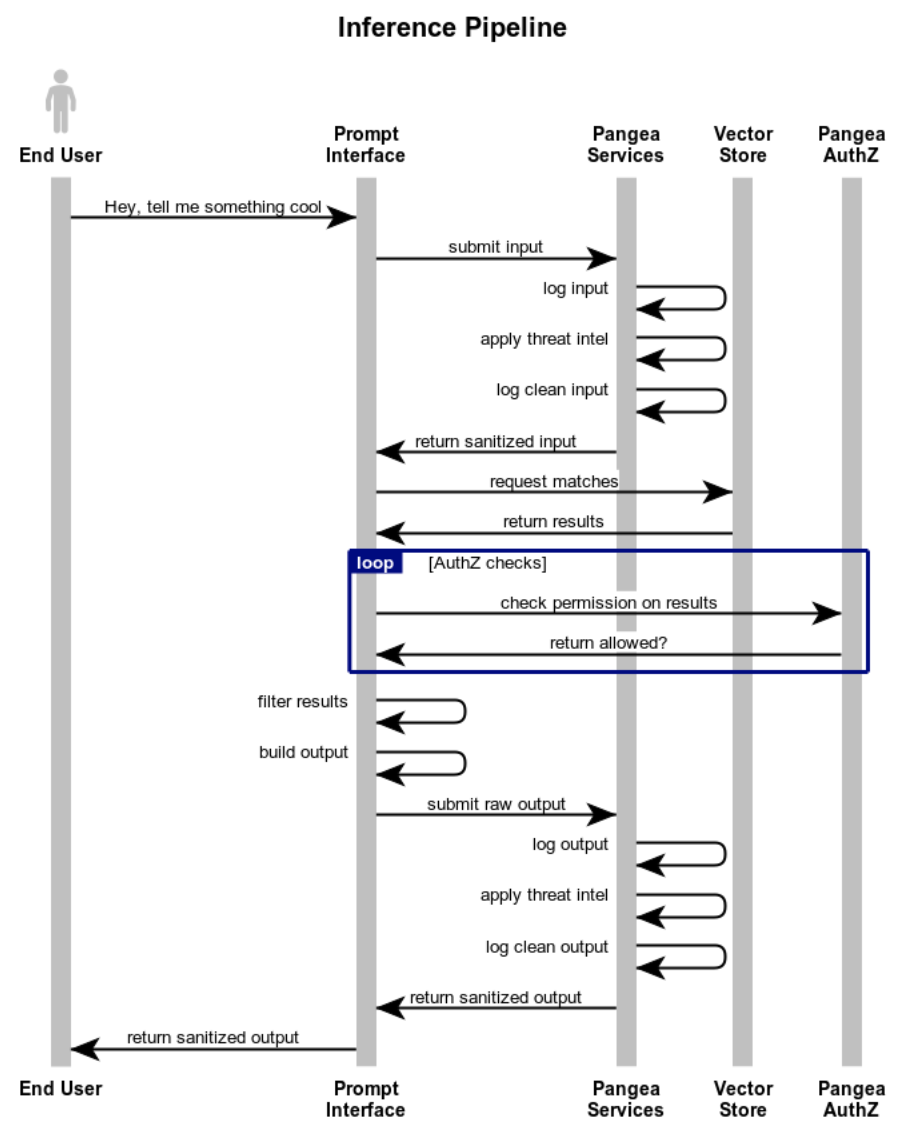
Note: This is where we need to be careful. In the Saturn example, we would correctly call this a hallucination. Rather if the removed information was salary or other sensitive information, we would call this data protection.
Now when we generate the response, we can determine “is this the best answer we have?” vs “is this the best answer you have access to?” and express that to the user. For bonus points, we may want to log users asking for information outside their normal access. We can use that to detect potential security threats or flag authorization policies slowing legitimate users.
Next Steps for Authorization in AI Apps
While we have an end to end model, there are still a few weaknesses in this system.
First, this example assumes our initial data sources are queryable for users and their relationships. If we can’t query that model, we can’t apply authorization. If you still need authorization policy, you may want to preload source-level policies into Pangea AuthZ.
Next, authorization policies change over time. Therefore, we should assume every user relationship with sources and objects has an expiration or Time To Live (TTL). Then we treat this as an authorization cache and refresh it based on policy or make “just in time” (JIT) checks at inference time. Using a JIT-approach will be more accurate but a TTL approach will have less latency. Choose the best based on your use case.
Finally, the vectors themselves may be sensitive. It’s common for internal documents to include sales data, customer notes, or even PII that is subject to more stringent requirements. If we apply Pangea Redact, we can detect and redact or mask this data at ingestion time and offer even more fine-grained AuthZ controls.
If you’d like to learn more and see these principles in action, check out our Tutorial on “Identity and Access Management in Python with LangChain and Pangea.”
Thanks to https://www.websequencediagrams.com/ for great diagramming tools.
Subscribe to my newsletter
Read articles from Keith Casey directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Keith Casey
Keith Casey
Keith “Danger” Casey currently serves on the Product Team at Pangea helping teams launch their systems faster and easier than ever before. Previously, he served on the Product Teams at ngrok launching GTM efforts, Okta working on Identity and Authentication APIs, as an early Developer Evangelist at Twilio, and worked to answer the Ultimate Geek Question at the Library of Congress. His underlying goal is to get good technology into the hands of good people to do great things. In his spare time, he writes at CaseySoftware.com, lives in the woods, and has recorded numerous API courses with LinkedIn Learning.