Building event driven application using Fast API, Django, and Kafka
 Gaurav Jaiswal
Gaurav Jaiswal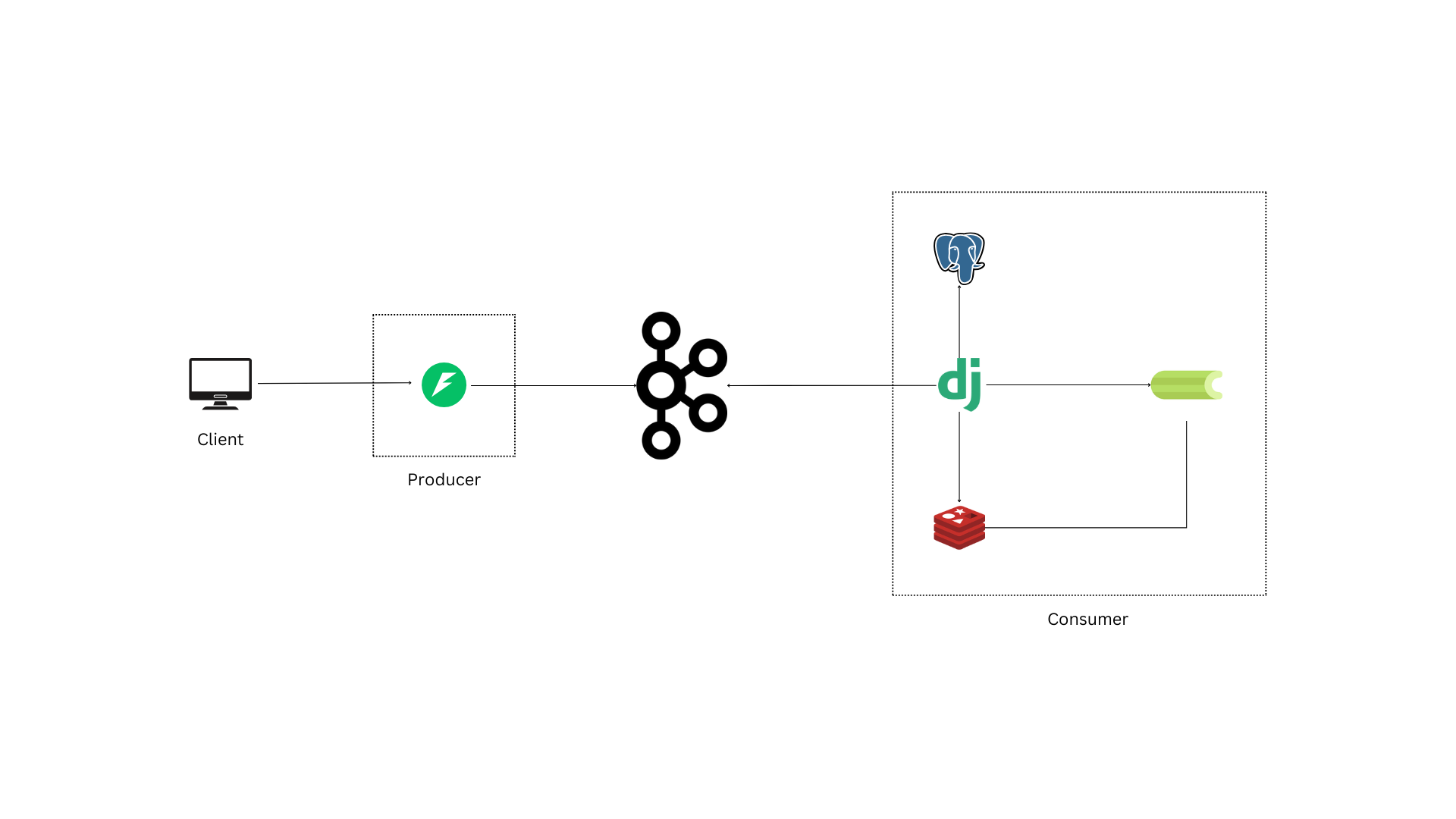
In this article, I’ll walk through how to build a basic to-do app using event-driven architecture principles. This system is designed to handle high traffic workloads and achieve scalability.
Prerequisites
This article will focus on using Kafka with Django and FastAPI, so readers should have a clear understanding of these tools and optionally be familiar with running cron jobs (potentially with Celery and Celery Beat).
GitHub Repository
For a clearer understanding of this project, please refer to the GitHub repository.
Project Setup
To set up the project seamlessly, ensure Docker is installed on your system. Follow the instructions in the readme.md file for detailed setup steps.
Project Structure
The project is organized as follows:
Within the root directory, navigate to services/ where you’ll find two sub-projects:
Producer: A FastAPI service responsible for publishing new to-dos to Kafka topics.
Consumer: A Django service that consumes to-dos from Kafka and saves them to the database.
Since the services communicate only through Kafka without direct connections, they can easily scale independently.
Producer, and Consumer services work together as a to-do application. This article is divided into two sections, focusing on each component.
1. Producing New To-Dos
When a request to add a new to-do is received, it is processed by the Producer first. Since the Producer service is not directly connected to a database, it cannot save records permanently. Instead, it validates the data and sends it to a Kafka topic (todo-create) for the Consumer to process and store.
Within the Producer service, the method get_kafka_producer() in services/producer/src/config/kafka_producer.py connects the app to a Kafka instance. Requests to add new to-dos hit the /new API endpoint (created in services/producer/src/api.py). Kafka, built for high-throughput workloads, helps ensure that the Consumer remains highly available, supporting scalability through replication and load balancing.
2. Consuming New To-Dos
One critical design decision is determining how new to-dos should be fetched from Kafka. Different approaches have their trade-offs, and I’ve opted for a long polling strategy that periodically retrieves new to-dos in bulk, minimizing the number of database operations.
The Consumer’s configuration, located in services/consumer/config/kafka_provider.py, includes a connection to Kafka. Note that the KafkaConsumer() constructor’s topic parameter is set to todo-create, which matches the Producer's output topic.
Key Concepts in This Setup
Preventing Duplicate Message Consumption
With multiple consumer instances running, there's a risk of the same message being consumed by multiple instances. Kafka addresses this with consumer groups, allowing only one instance within a group to process each message. By setting a unique group_id for our consumers, Kafka ensures that each message is processed only once by a single instance within the group.
For added reliability, you can disable auto_commit and commit manually after each successful processing. In this implementation, I kept auto_commit enabled to reduce complexity. However, the downside is that Kafka assumes successful processing once a consumer picks up a to-do, regardless of processing status.
To mitigate data loss, the auto_offset_reset setting is configured as “earliest,” which reprocesses messages from the beginning if logs are lost. Note that this setting can result in duplicate data if logs are lost, though this is rare.
These configurations are done at services/consumer/config/kafka_provider.py as shown below:
def get_kafka_consumer(topic: str, **kwargs)
return KafkaConsumer(
topic,
bootstrap_servers=["kafka:9093"],
group_id="todo",
auto_offset_reset="earliest",
enable_auto_commit=True,
value_deserializer=lambda x: json.loads(x.decode("utf-8")),
**kwargs
)
Avoiding Empty Lookups
The Consumer periodically polls for new to-dos using Celery Beat. However, if no new to-dos are produced, this can lead to empty database lookups. To prevent this, long polling is implemented, so each lookup waits briefly before concluding. If no messages are received within the polling interval, it returns an empty result, allowing the application to continue without unnecessary database access.
The function populate_todos() in services/consumer/todo/tasks.py handles two major tasks: pulling new to-dos and saving them to the database using Django’s bulk_create() method.
Look at the below code snippet from the same function, two highlights are timeout_ms, and max_records parameters:
new_todos = consumer.poll(
timeout_ms=10000, # for long polling
max_records=5000 # limits the maximum number of to-dos fetched
)
The timeout_ms parameter enables long polling, ensuring a waiting period for new messages. The max_records parameter limits the number of records fetched in high-traffic scenarios, so no more than 5000 to-dos are processed at once.
Since the Consumer is built with Django, it’s configured to save incoming data directly to the database.
Conclusion
This article has outlined how to create a scalable to-do application using Kafka, Django, and FastAPI by following event-driven architecture principles. With these concepts, you can expand this basic architecture to build more complex, scalable event-driven systems.
Subscribe to my newsletter
Read articles from Gaurav Jaiswal directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Gaurav Jaiswal
Gaurav Jaiswal
Software Engineer