Exploring Web Scraping in Go: A Personal Experience
 Shainil P S
Shainil P S
Well if you search for web scraping in go, you can get tons of result in the Google. Why should you read mine you may ask ? well the answer is i don’t know, well this blog isn’t about a tutorial on web scraping with go. This is my personal experience of scraping web.
I’m a Javascript/Typescript main devloper, Then why did i used golang right ? The thing is I’m not using golang for it’s concurrent execution and all (did used concurrency in this), I simply enjoy this language .That’s it. Well i never tried scraping web with node js even though I’m using it from long time. come to think of it i never tried to do that right lol. without further wining we can get into business that is writing code .

Ok!! Keep in mind that I’m not using any external library execept the net/html for scraping the web. This just make use of the statndard library and other boring stuff to scrape the site. The site that i took here is called https://www.politifact.com and yeah its a server side rendered site. so this scraping doesnt include any cool headless browser for scraping
package main
import (
"fmt"
"log"
"net/http"
"golang.org/x/net/html"
)
func main() {
fmt.Println("web scrapper up and running")
resp, err := http.Get("https://www.politifact.com/") //sending the get request
if err != nil {
log.Fatal("Error occured while fetching the url:", err)
}
//resp.Body is reader.
defer resp.Body.Close() //its a good practice to close the reader
doc, err := html.Parse(resp.Body)
if err != nil {
log.Fatal("Error occured while parsing the html:", err)
}
//doc is the parse data
}
First thing first we need to set up the project , which i did. then I started searching all over internet to know little about html parsing. why that huhh ? cause i knew how to send a get request in go. You can just make use of http.Get() function to send a http get request. after you send the request you get body of response , well in go you get a reader , what exactly is reader huh ?? okay let me explain that in next paragraph. feel free to skip if you already know.
So what is reader ? well i dont know exactly cause my knowledge of reader may wrong feel free to correct it. I imagine that as a pointer which points to a particular line or point in a document. so when you use method like Read() it make use of that reader to read the file or document. why this is helpful huh? well its helpful in streaming data. the body of a response is large so we make use of reader and stream concept to read through it
Then i found out that you can parse the body using the html.Parse() function by the "golang.org/x/net/html" package. it takes a reader and give back a *html.Node. In order to iterate thurogh the parsed html data we need to understand about html node type. what is that right my next paragraph will explain about that. feel free to skip this also if yo know this already.
The parsed data will be represented in a tree liike structure or you can say graph. html.Node is a type of struct which have properties like Type, Data, Attr, Firstchild , NextSibling and many moret. These are all I have used so I will cover these. Type just tells what is the current node’s type it can be a TextNode, DocumentNode, ElementNode, CommentNode, DoctypeNode . Then data just gives you value inside the tags or node you may say. Attr gives a list of struct with key and value. and then Firstchild gives the next tag node on same parent node, and nextsibling gives the next node on the same parent node. Every node have same structure if you didnt understnd this lets just look at the diagram .
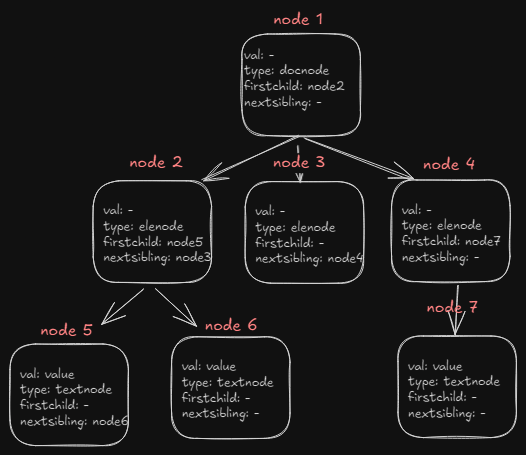
Now after you have understand the structure the parsed data , you can right hop onto iterating through it using DFS like traversal (it’s obivous that we may need to implement this kind of traversal cause of the graph like structure). We make use of recursion to recursively go into the depth of each node. and check if the current node is of the type anchor tag and go into the anchor tag attribute and extract the url from there and make a get request. we determine the result by statuscode of the response.
import (
"fmt"
"log"
"net/http"
"net/url" //the isValidUrl function making use of this
"golang.org/x/net/html"
)
func traverse(node *html.Node) {
if node == nil {
return
}
if node.Type == html.ElementNode && node.Data == "a" {
for _, attr := range node.Attr {
if attr.Key == "href" {
if isValidURL(attr.Val) {
resp, err := http.Get(attr.Val)
if err != nil {
fmt.Println("Error occured:", attr.Val)
return
}
if resp.StatusCode != http.StatusOK {
fmt.Println("dead link url:", attr.Val)
}
}
}
}
}
for c := node.FirstChild; c != nil; c = c.NextSibling {
traverse(c, w)
}
}
//function for not validating the link
func isValidURL(link string) bool {
parsedURL, err := url.Parse(link)
if err != nil {
return false
}
return parsedURL.Scheme != "" && parsedURL.Host != ""
}
There you have it that’s it . was easy right. but I forgot to add the concurreny right ? cause that’s what golang famous for IMO. okay lets make the traversal a goroutine. we can keep track of the go routine by sync.WaitGroups by the sync package. After adding the waitgroup and goroutine the final code will look like
package main
import (
"fmt"
"log"
"net/http"
"net/url"
"sync"
"golang.org/x/net/html"
)
func main() {
fmt.Println("web scrapper up and running")
resp, err := http.Get("https://www.politifact.com/")
if err != nil {
log.Fatal("Error occured while fetching the url:", err)
}
defer resp.Body.Close()
doc, err := html.Parse(resp.Body)
if err != nil {
log.Fatal("Error occured while parsing the html:", err)
}
var w sync.WaitGroup //intializing the waitgroup
w.Add(1) //adding the first goroutine
go traverse(doc, &w) //first goroutine
w.Wait() //waiting for every goroutines to complete
}
func traverse(node *html.Node, w *sync.WaitGroup) {
if node == nil {
return
}
if node.Type == html.ElementNode && node.Data == "a" {
for _, attr := range node.Attr {
if attr.Key == "href" {
if isValidURL(attr.Val) {
resp, err := http.Get(attr.Val)
if err != nil {
fmt.Println("Error occured:", attr.Val)
return
}
if resp.StatusCode != http.StatusOK {
fmt.Println("dead link url:", attr.Val)
}
}
}
}
}
for c := node.FirstChild; c != nil; c = c.NextSibling {
w.Add(1) // adding for every go routine
go traverse(c, w) //more goroutines
}
defer w.Done() //calling Done method in defer so that it will execute after each function execution
}
func isValidURL(link string) bool {
parsedURL, err := url.Parse(link)
if err != nil {
return false
}
return parsedURL.Scheme != "" && parsedURL.Host != ""
}
Easy peasy right !! Super easy to implement the concurrency right. I’m not gonna explain that cause I’m bored lol. If you are reading this then I would like to Thankyou for bearing with me for entire article. See you on next blog if i wrote one!!
Subscribe to my newsletter
Read articles from Shainil P S directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Shainil P S
Shainil P S
Hey, This is shainil. I m learning backend development along with dsa in cpp<3