PostgreSQL DOXXED: Pages Layout & Optimizations
 Eyad Youssef
Eyad Youssef
In the previous article, we have talked about how our data is structured and stored in PostgreSQL, talking about how rows behave in the MVCC Architecture, how Tables and Indexes are stored, and the role of System Catalog, Schemas and Tablespaces.
We have also discussed how each table is divided and stored in 3 different Forks: The Main Fork, the Free Space Map, and the Visibility Map.
These forks/files then get logically split into what’s called pages (also known as blocks). A page represents the smallest amount of data that can be read from or written to disk at a time.
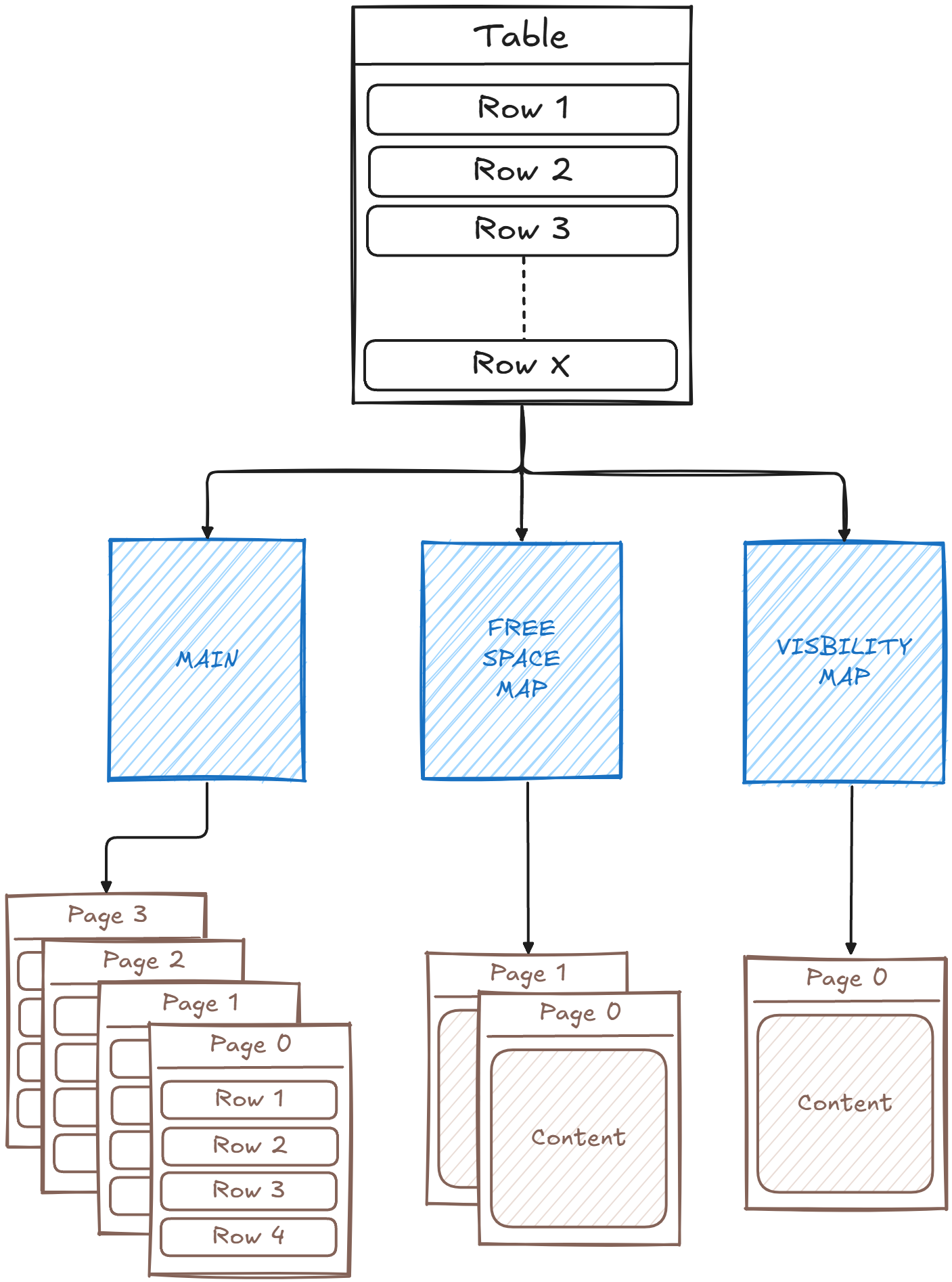
Pages as a concept helps facilitating several processes, such as I/O operations from and to disk as it does not fetch individual rows but whole pages, performing internal maintenance tasks such as vacuuming and pruning for clean up, and handling disaster recovery upon crashes.
The default size of a page is 8 KB, which can be changed to be up to 32 KB. Having larger page sizes can result in less I/O overhead when it comes to reading large amounts of data, but it could also cause over-fetching data and bloating the buffer pool (memory cache) when it’s not utilized.
Smaller page sizes are often better for random access, where we only need to access to small pieces of data at a time. The page size choice depends on our specific use case(s).
Each table is represented as an array of pages, all of the same size, stored sequentially on disk, one after the other. Therefore, pages of a table do not need to store pointers inside each page to link them to the next and previous ones.
So in order to access a specific page, PostgreSQL simply adds an offset of (page size * the required page number) and skips directly to that page.
Indexes situation is a bit different, as when it comes to B-Trees indexes for example, they need to maintain an order and be aware of the sibling pages. Therefore, each page contains pointers to the previous and next page.
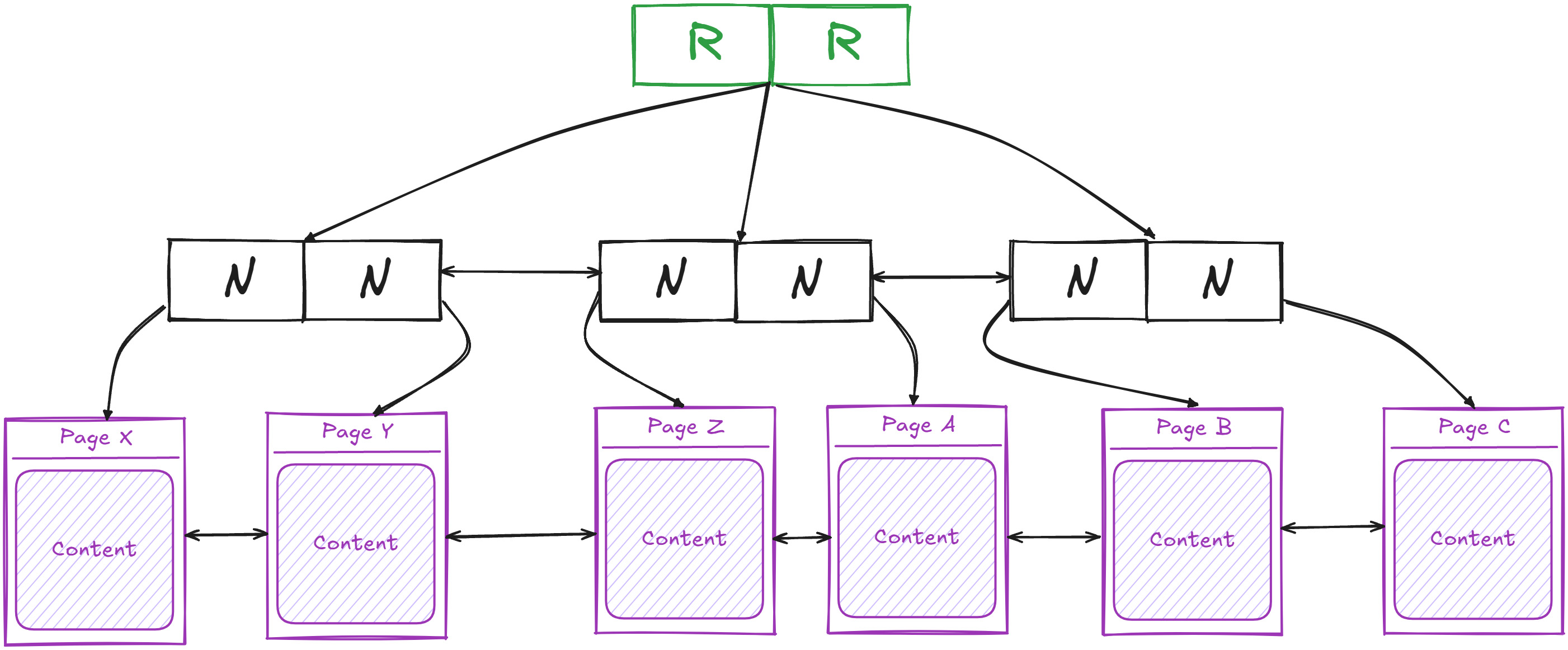
Each page can store one row or multiple rows, depending on the size of the rows. So, when we have multiple small rows, which may contain small integers and booleans, they may be able to fit into a single page, while if a row is large, which may contain long texts, it could take the whole page space (theoretically).
Layout
Pages have inner layout that consists of multiple parts, which helps with optimizing how data is stored, accessed, and managed.
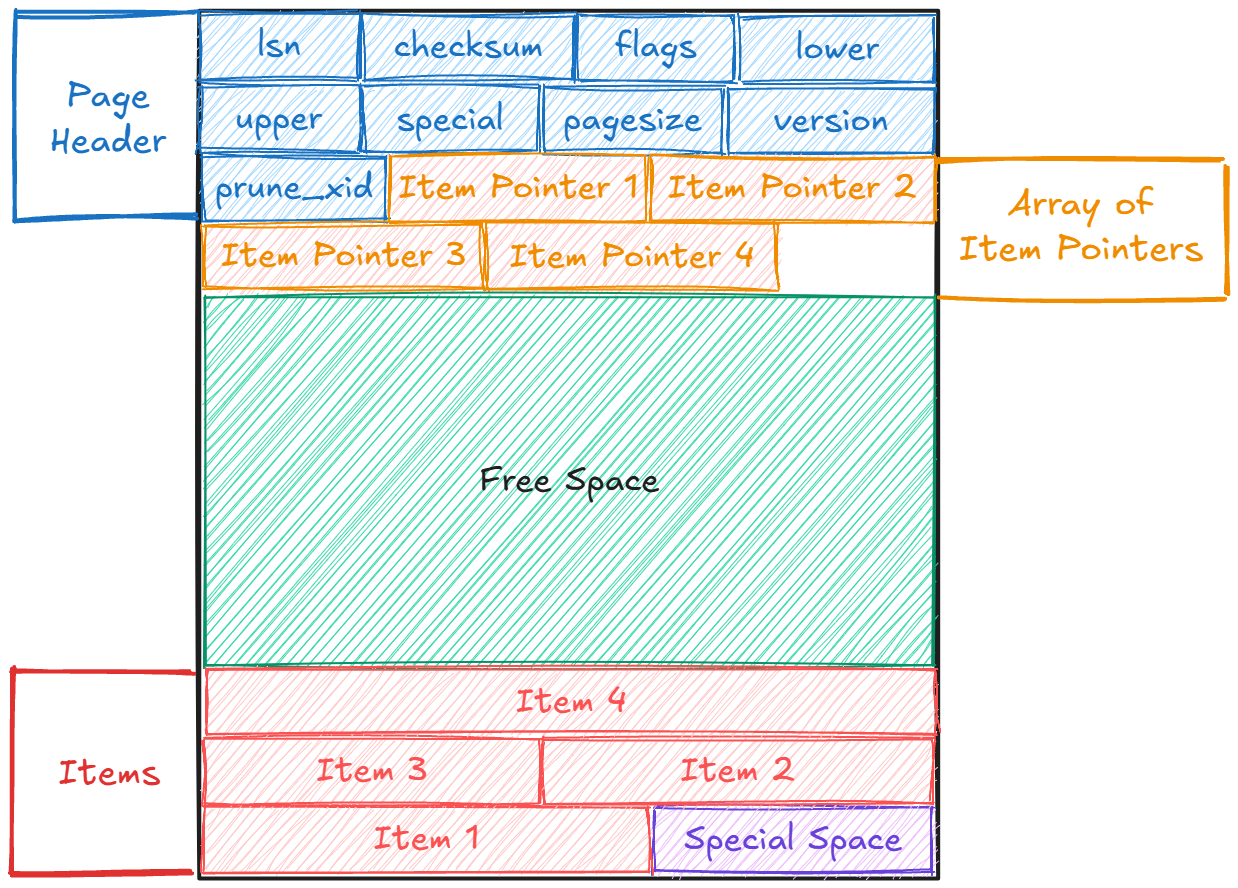
The inner layout usually consists of these parts:
Page Header holds metadata about the current page and occupies the first 24 bytes of the page.
Array of Item Pointers contains pointers to the rows, serves as the page’s table of content, and each item pointer has values that occupy 4 bytes.
Free Space is the unallocated area that does not contain rows. It is treated as single chunk, there is no fragmentation within the page. The free space within the page is always aggregated, and it is reflected in the Free Space Map Fork after a
vacuumoperation.Items are the actual rows.
Special Space contains additional information needed by the object stored.
For example, B-Tree Indexes store pointers to the left and right siblings, along with some data relevant to the index.
Regular tables do not use this section.
Let’s have an example inspecting the pages of a table:
/*
Create a table with id and a content column which reserves
2000 bytes just to simplify the example
*/
CREATE TABLE messages (
id SMALLINT PRIMARY KEY,
content CHAR(2000));
INSERT INTO messages (id, content) VALUES (1, repeat('A', 2000));
-- Use the extension to be able to inspect pages
CREATE EXTENSION pageinspect;
-- Inspect page header
SELECT * FROM page_header(get_raw_page('messages', 0));
| lsn | lower | upper | pagesize | special | checksum | flags | version | prune_xid |
| 0/1A27E38 | 28 | 6160 | 8192 | 8192 | 0 | 0 | 4 | 0 |
lsnstands for log sequence number, which tracks the position of the last WAL (Write Ahead Log) entry that modified the page. That could help with recovering from a crash by comparing the WAL entry number with the page LSN to determine if the page is up to date with the WAL or not.loweranduppercontain offsets of the unallocated free space, points to where it starts and where it ends.- Page header occupies the first 24 bytes, and there is an item pointer for the row inserted which takes 4 bytes, so the free space starts from the 28th byte, and occupies around 6 KB, and the remaining 2 KB are occupied by the inserted row.
specialpoints to the start of the special space. We can see that it’s at the very end of the page and does not occupy any space as this section is not used with regular tables.checksumtracks the page checksum to help detect corruption.flagscontains flag bits that indicate the page state:Has Free Lines (value = 1) means that the page has unused item pointers, which signals that there is room for new rows to be inserted. This usually happens after a pruning operation.
Page Full (value = 2) means the page is full and cannot fit any more new rows. It is set if an
UPDATEdoesn't find enough free space in the page for its new row version.All Visible (value = 4) means that all the rows are active and the page does not contain any dead rows. It’s usually set after a
VACCUMoperation being completed.value = 0 means that the page was not affected by any operation yet.
versionstores the page version, which is 4 starting from PostgreSQL v8.3.prune_xidit hints to if pruning is going to useful for this page, meaning that there might be expired rows that can be cleaned up and free some space. The value is set to the oldest Transaction ID that deleted a row.
This page should be able to store 3 more rows to be at fully stacked, as each row takes 2 KB and it has 6 KB of free space left, so let’s extend this example by adding more data and inspect the Item Pointers Array content as well:
INSERT INTO messages (id,content) VALUES (2, repeat('B', 2000));
INSERT INTO messages (id,content) VALUES (3, repeat('C', 2000));
INSERT INTO messages (id,content) VALUES (4, repeat('D', 2000));
/*
Inspect item pointers along with message content.
The rows data inside the page is in binary format, so we did this
JOIN operation with the original table to view it in a readable format.
*/
SELECT (0,lp)::text::tid as ctid, messages.content, lp, lp_len, lp_off,
CASE lp_flags
WHEN 0 THEN 'unused'
WHEN 1 THEN 'normal'
WHEN 2 THEN 'redirect to '|| lp_off
WHEN 3 THEN 'dead'
END AS lp_status
FROM heap_page_items(get_raw_page('messages',0))
LEFT JOIN messages ON CTID = (0,lp)::text::tid;
| ctid | content | lp | lp_len | lp_off | lp_status |
| (0,1) | AAAAA……AAAAA | 1 | 2032 | 6160 | normal |
| (0,2) | BBBBB……BBBBBB | 2 | 2032 | 4128 | normal |
| (0,3) | CCCCC……CCCCC | 3 | 2032 | 2096 | normal |
| (0,4) | DDDDD……DDDDD | 4 | 2032 | 64 | normal |
Each Item pointer contains the following information:
lpstands for line pointer which points to the row position inside a page, which is also used in the second part of theCTIDvalue.lp_lenis the row length.lp_offis an offset to the row from the start of the page.lp_flagsare several bits that define the row status:Normal is the default flag for an active accessible row.
Unused indicates that this slot in the array is not used and can be reused as new rows are added to the page. This usually happens after a cleanup operation on the page.
Dead means that the row is marked as obsolete and there might be a newer version.
Redirect to means that the current
lpnow points to anotherlp, indicating that the row has moved to another position, which usually happens after having a HOT Update.
SELECT lower, upper FROM page_header(get_raw_page('messages', 0));
| lower | upper |
| 40 | 64 |
This page is considered full now, so any new rows inserted or updated will be put in a newly created page.
INSERT INTO messages (id,content) VALUES (5, repeat('E', 2000));
UPDATE messages SET content = repeat('Z', 2000) WHERE id = 1;
-- Inspect page 1
SELECT (1,lp)::text::tid as ctid, messages.content, lp, lp_len, lp_off,
CASE lp_flags
WHEN 0 THEN 'unused'
WHEN 1 THEN 'normal'
WHEN 2 THEN 'redirect to '|| lp_off
WHEN 3 THEN 'dead'
END AS lp_status
FROM heap_page_items(get_raw_page('messages',1))
LEFT JOIN messages ON CTID = (1,lp)::text::tid;
| ctid | content | lp | lp_len | lp_off | lp_status |
| (1,1) | EEEEE……EEEEEE | 1 | 2032 | 6160 | normal |
| (1,2) | ZZZZZ……ZZZZZZ | 2 | 2032 | 4128 | normal |
When it comes to inspecting B-Tree index pages, the first page is reserved for metadata about the index, and the actual data are stored after that.
We can inspect the content of an index’s leaf page using this function:
SELECT data AS indexed_key, ctid FROM bt_page_items('messages_pkey', 1);
| indexed_key | ctid |
| 01 00 00 00 00 00 00 00 | (0,1) |
| 01 00 00 00 00 00 00 00 | (1,2) |
| 02 00 00 00 00 00 00 00 | (0,2) |
| 03 00 00 00 00 00 00 00 | (0,3) |
| 04 00 00 00 00 00 00 00 | (0,4) |
| 05 00 00 00 00 00 00 00 | (1,1) |
HOT Updates
Heap-Only Tuples Update is an optimization where row updates can happen without adding new index entries.
Each update makes a new version of the row with a new CTID value, so this triggers updates of all the indexes created on the table, as each index must include a reference to this new row.
But this can be avoided if we can satisfy some conditions:
The updated row can be placed on the same page as the old row.
Indexed columns aren't changed or affected by the
UPDATEoperation.
If that’s the case, then it can simply update the Item Pointer of the old row to point/redirect to the new row, then follow the t_ctid chain in case of having multiple updates on the same row to reach the latest version of it.
We can see in the previous example that we have 2 index entries for the indexed_key = 1, as the updated row of id = 1 could not fit on the same page, thus not utilizing HOT Updates.
Later in this article we will see how to have more control over the page to make use of this feature.
Splitting
Sometimes the database runs into a case where it needs to add a row inside a fully stacked page so it can maintain the order of the rows. To do that, it will need to split this full page into 2 pages, then add the new row where it belongs.
Splitting is not an issue when it comes to tables, because they are heap-organized, but it’s not the case for B-Tree indexes, where they must maintain an order for the rows.
Page splits lead to gradual degradation in the index's efficiency, which often happens in heavily updated tables. To mitigate this process, we can utilize the fill factor.
Fill Factor
Fill Factor determines the percentage of how full a page can be, a value of 100 means that PostgreSQL will fill the page to its full capacity, where any less percentage used will leave some free space inside every page that can be used later for updates happening on rows of that page.
For tables case, setting a value less than the default value of 100 will give update operations a chance to place the updated copy of a row on the same page as the original, which is more efficient than placing it on a different page, as this can help PostgreSQL with HOT Updates.
Let’s reuse the previous example and see how different the storage is when setting a fill factor:
CREATE TABLE messages (
id SMALLINT PRIMARY KEY,
content CHAR(2000))
WITH (FILLFACTOR = 75);
INSERT INTO messages (id,content) VALUES (1, repeat('A', 2000));
INSERT INTO messages (id,content) VALUES (2, repeat('B', 2000));
INSERT INTO messages (id,content) VALUES (3, repeat('C', 2000));
INSERT INTO messages (id,content) VALUES (4, repeat('D', 2000));
SELECT CTID, * from messages;
SELECT lower, upper FROM page_header(get_raw_page('messages', 0));
| CTID | id | content |
| (0,1) | 1 | AAAAA……AAAAA |
| (0,2) | 2 | BBBBB……BBBBBB |
| (0,3) | 3 | CCCCC……CCCCC |
| (1,1) | 4 | DDDDD……DDDDD |
| lower | upper |
| 36 | 2096 |
We can observe from the CTID value that the first 3 rows were stored on page 0 and the last one was inserted on page 1 even though there are around 2 KB (upper - lower) of free space left on page 0.
Now if we try to update any row that exists on the first page, the newer version will be placed on the same page, utilizing the reserved free space by the fill factor set:
UPDATE messages SET content = repeat('Z', 2000) WHERE id = 1;
SELECT (0,lp)::text::tid as ctid, messages.content, lp,
CASE lp_flags
WHEN 0 THEN 'unused'
WHEN 1 THEN 'normal'
WHEN 2 THEN 'redirect to '|| lp_off
WHEN 3 THEN 'dead'
END AS lp_status
FROM heap_page_items(get_raw_page('messages',0))
LEFT JOIN messages ON CTID = (0,lp)::text::tid;
| CTID | content | lp | lp_status |
| (0,1) | NULL | 1 | redirect to 4 |
| (0,2) | BBBBB……BBBBBB | 2 | normal |
| (0,3) | CCCCC……CCCCC | 3 | normal |
| (0,4) | ZZZZZZ……ZZZZZZ | 4 | normal |
The updated version with CTID = (0,4) was placed on the same first page, utilizing the free space reserved by the fill factor. The lp_status of the old row now redirects to lp = 4.
This allowed PostgreSQL to utilize HOT Updates by updating the old item pointer, which will result in better performance as it will not need to go to the index to add a new entry, as opposite to the previous example.
SELECT data AS indexed_key, ctid FROM bt_page_items('messages_pkey', 1);
| indexed_key | ctid |
| 01 00 00 00 00 00 00 00 | (0,1) |
| 02 00 00 00 00 00 00 00 | (0,2) |
| 03 00 00 00 00 00 00 00 | (0,3) |
| 04 00 00 00 00 00 00 00 | (1,1) |
For the B-Tree indexes case, the fill factor will minimize the need for page splits in heavily updated tables, leading to a better performance overall.
By default, B-Tree Indexes has a fill factor set to 90, we can still adjust this percentage to suit our needs:
CREATE INDEX messages_content ON messages(content)
WITH (FILLFACTOR = 75);
Setting a fill factor is situational, in case of having a table where it never gets updated, there is no need to set fill factor for the table or the index, as it will hinder the physical storage for no purpose.
References
Subscribe to my newsletter
Read articles from Eyad Youssef directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Eyad Youssef
Eyad Youssef
A regular everyday normal software developer