Mutable vs Immutable Fabric Spark Properties
 Sandeep Pawar
Sandeep PawarIn Microsoft Fabric, you can define spark configurations at three different levels:
Environment : This can be used at the workspace or notebook/job level by creating Environment item. All notebooks and jobs using the environment will inherit spark & compute properties from the environment.
Session : You can define properties with session scope using
%%configuremagic in a notebook which are applicable to all sessions shared by that cluster. You can also change individual configurations by usingspark.conf.set(…)which will dynamically override global session configurations, if applicable.Operation : Certain configurations can be changed in each cell for each operation, e.g. the
vorderas shown here.
However, not all spark properties can be modified during the session. In this blog, I will show which properties can be changed, why it matters and some considerations. Let’s dive in.
Mutable vs Immutable Configurations
Spark properties are divided into mutable and immutable configurations based on whether they can be safely modified during runtime after the spark session is created.
Mutable properties can be changed dynamically using spark.conf.set() without requiring a restart of the Spark application - these typically include performance tuning parameters like shuffle partitions, broadcast thresholds, AQE etc.
Immutable properties, on the other hand, are global configurations that affect core spark behavior and cluster setup and these must be set before/at session initialization as they require a fresh session to take effect.
We can check if a property is mutable by using spark.conf.isModifiable(). Let’s get all the spark properties in Fabric Runtime 1.3 and see :
from pyspark import SparkConf
import pandas as pd
conf = SparkConf()
spark_configs_df = pd.DataFrame(conf.getAll(), columns=['Property Name', 'value'])
spark_configs_df['modifiable'] = [spark.conf.isModifiable(x['Property Name']) for x in spark_configs_df.to_dict('records')]
display(spark_configs_df)
For example, I randomly sampled some configurations below. optimizeWrite is mutable and can be changed anytime during the session whereas minExecutors is immutable has to be set for the spark pool or using %%configure .
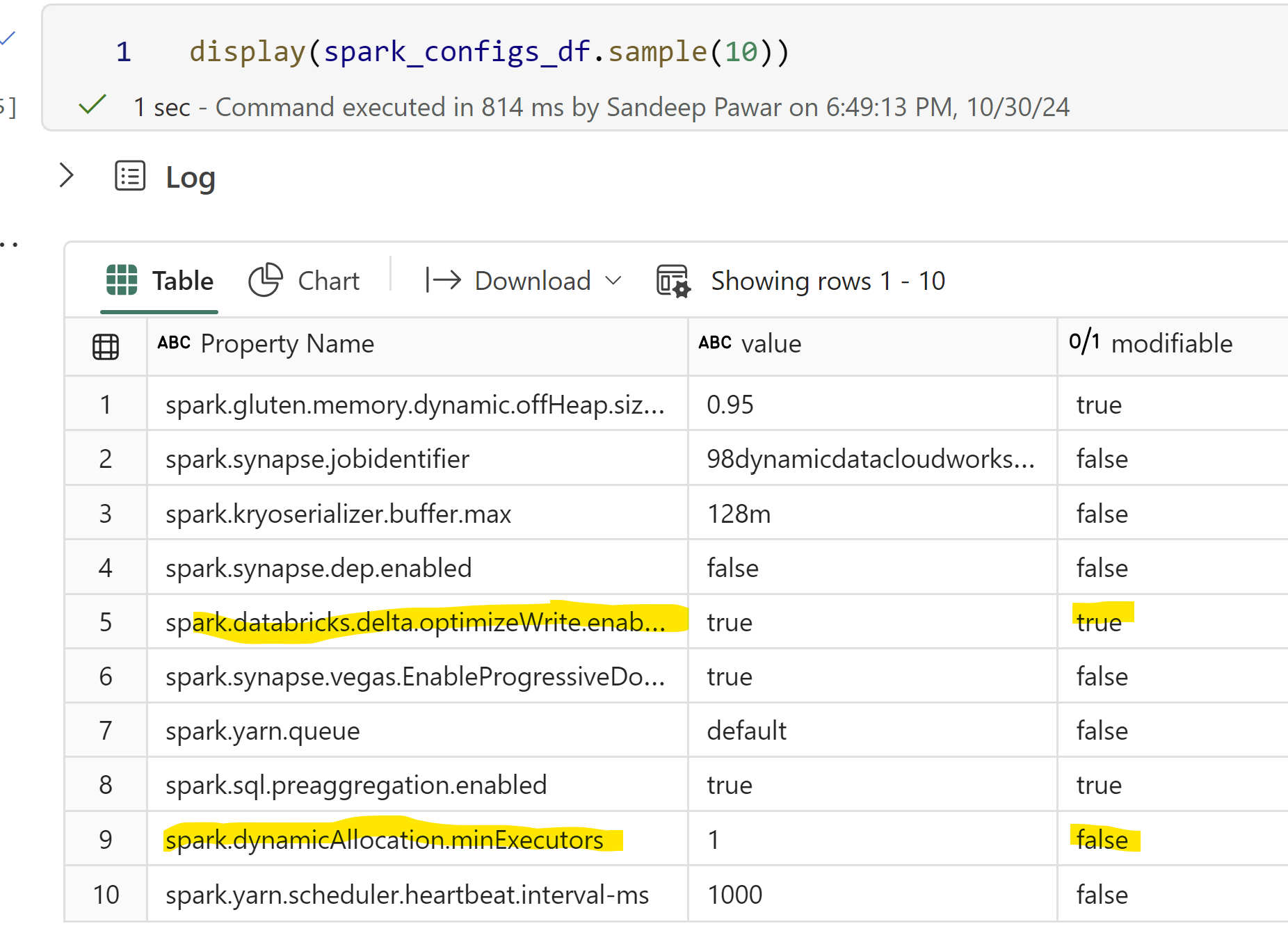
Technically some immutable properties might still be changeable at runtime but it’s not recommended to avoid unexpected behavior.
Ok, all good but why does this matter? Because :
if you configure your session with custom spark properties, it can lead to longer session start-up time. But it’s only the immutable properties that will affect the start-up time. Hence, knowing which properties are mutable vs immutable helps!
just because you can change certain mutable properties dynamically during runtime doesn’t mean you should.
Let’s look at a simple example:
%%configure -f
{
"conf": {
"spark.sql.autoBroadcastJoinThreshold": "102400000",
"spark.native.enabled": "true",
"spark.shuffle.manager": "org.apache.spark.shuffle.sort.ColumnarShuffleManager"
}
}
In the above spark configuration taken from the NEE documentation, I am setting:
Broadcast Join Threshold to be 100MB, instead of the 25.6MB (MS documentation incorrectly states it’s 10MB). (side note: considering the size of the starter pool cluster, I think the default value is too low and could easily be changed to 1GB in most cases. But, if you use auto-tuning in Fabric, it will automatically set it for you. More on that in another blog)
Enabling native execution engine
Setting how the data should be shuffled
If I start the session with above config, the start-up time is ~4min instead of 5s.
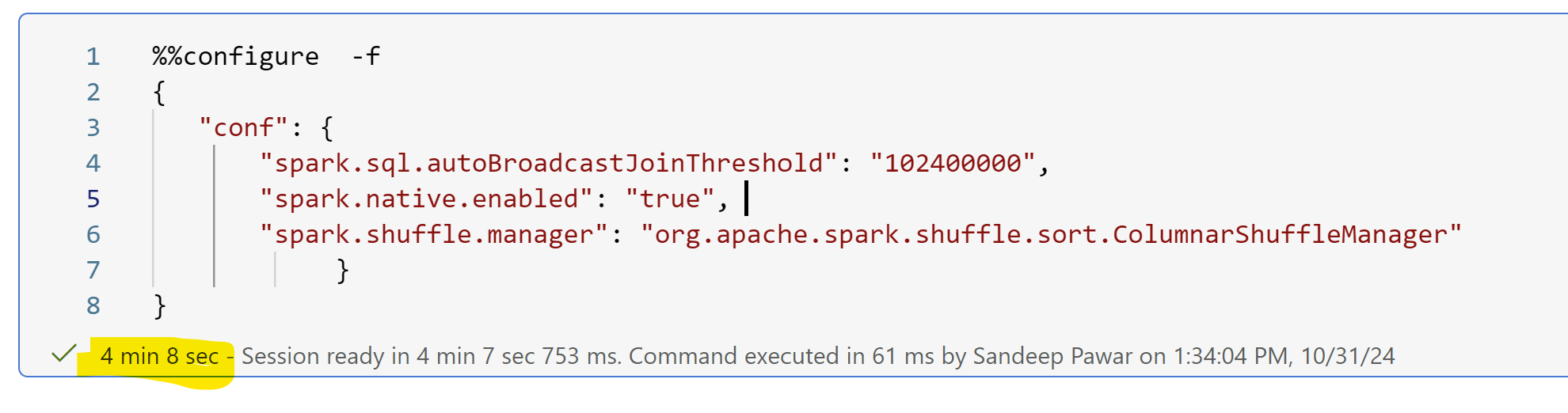
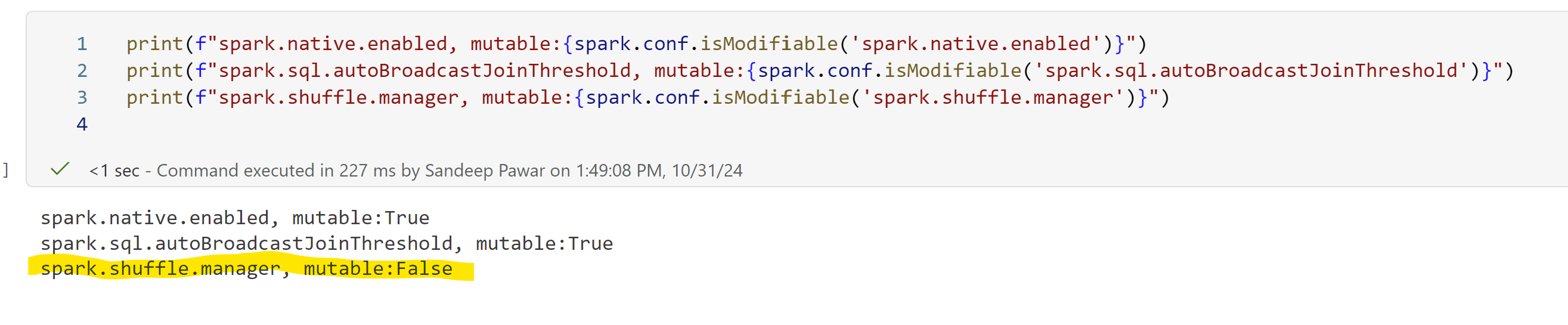
This is because the spark.shuffle.manager property is immutable while the other two are mutable.
If I remove the shuffle manager from the configuration for demo purposes, the session starts in 7s.

Now, the second point I raised above, just because you can, should you ?
spark.native.enabled is a modifiable property so you can change it dynamically in a cell.

But you shouldn't make changes without understanding what the configuration does. In the example above, I enable the Native Execution Engine, which changes the engine used to process data and affects how queries are planned and executed. This has broader implications. It's a modifiable property because it's a special configuration defined in the Fabric runtime, not part of standard Spark.
On the other hand, spark.sql.autoBroadcastJoinThreshold defines the threshold used for broadcast joins and can be & should be optimized during development. However, for scheduled jobs, best to minimize changing configuration dynamically and instead define it with environments or by using %%configure. Isolate jobs that require special configurations.
If you try to change "spark.shuffle.manager" (which is immutable) after starting the session, you will get an error:

Defining %%configure:
A couple of notes. These are mentioned in the documentation as well but I wanted to provide examples:
Standard Spark configurations must always be defined within
conf:// THIS IS CORRECT // %%configure -f { "conf": { "spark.sql.autoBroadcastJoinThreshold": "102400000", "spark.native.enabled": "true", "spark.shuffle.manager": "org.apache.spark.shuffle.sort.ColumnarShuffleManager" } } // THIS IS INCORRECT // %%configure -f { "spark.sql.autoBroadcastJoinThreshold": "102400000", "spark.native.enabled": "true", "spark.shuffle.manager": "org.apache.spark.shuffle.sort.ColumnarShuffleManager" }
Some special properties: spark.driver.cores, spark.executor.cores, spark.driver.memory, spark.executor.memory, spark.executor.instances , jars must always be defined at the root level and not in the conf body.
// THIS IS CORRECT //
%%configure -f
{
"driverMemory": "56g",
"driverCores": 32,
"executorMemory": "28g",
"executorCores": 4,
"conf": {
"spark.sql.autoBroadcastJoinThreshold": "102400000",
"spark.native.enabled": "true",
"spark.shuffle.manager": "org.apache.spark.shuffle.sort.ColumnarShuffleManager"
}
}
// THIS IS INCORRECT //
%%configure -f
{
"conf": {
"driverMemory": "56g",
"driverCores": 32,
"executorMemory": "28g",
"executorCores": 4,
"spark.sql.autoBroadcastJoinThreshold": "102400000",
"spark.native.enabled": "true",
"spark.shuffle.manager": "org.apache.spark.shuffle.sort.ColumnarShuffleManager"
}
}
You can always check the configured properties in the spark UI during the job execution or for an executed notebook/job.
Today is Diwali, Happy Diwali to everyone!

Subscribe to my newsletter
Read articles from Sandeep Pawar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Sandeep Pawar
Sandeep Pawar
Principal Program Manager, Microsoft Fabric CAT helping users and organizations build scalable, insightful, secure solutions. Blogs, opinions are my own and do not represent my employer.