A Beginner’s Guide to Kafka with Python: Real-Time Data Processing and Applications
 keshav dk
keshav dk
Introduction to Kafka
Kafka is an open-source distributed event streaming platform developed by Apache.
Originally created by LinkedIn, it was designed to handle high throughput, fault-tolerant, and real-time data streaming.
Kafka allows systems to publish and subscribe to streams of records (messages), process them, and store them efficiently.
Why is Kafka Used?
High Throughput: Kafka can handle millions of messages per second.
Fault Tolerance: Kafka is distributed, meaning it can replicate data across multiple nodes to ensure reliability.
Durability: Kafka persists data to disk and can replay messages, ensuring reliability in message delivery.
Real-time Processing: Kafka can process streams of data in real-time, ideal for applications like monitoring, analytics, or event-driven systems.
Scalability: Kafka can easily scale by adding more brokers to handle large volumes of data.
Decoupling Systems: Kafka acts as a middle layer for messaging, allowing different systems to communicate asynchronously.
Kafka Architecture
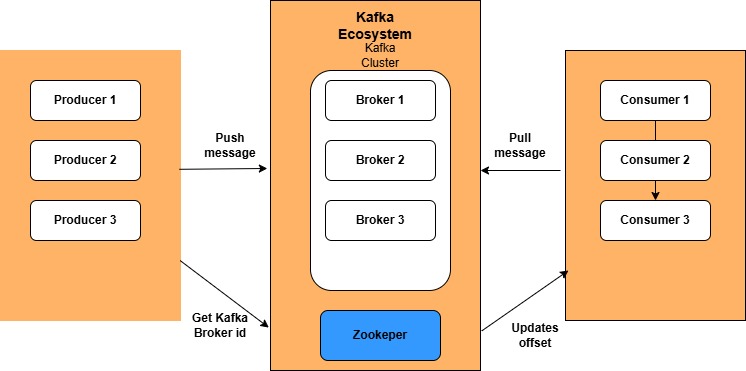
Components:
Producers: These are the applications or services that send data/messages to Kafka. Producers push messages to specific Topics within Kafka.
Topics: A Topic is a category or feed name to which records are published. Topics are partitioned to allow for scalability and parallelism.
Partitions:
Each Topic is divided into one or more Partitions.
Partitions enable Kafka to handle more messages and support parallel processing.
Each Partition has a unique ID and can store a subset of the topic’s data.
4. Brokers:
Kafka runs as a cluster of Brokers (servers), each handling data for multiple topics and partitions.
Brokers store and manage partitions, handling read and write requests from Producers and Consumers.
Each Broker is identified by a unique ID.
5. Consumers:
Consumers are applications or services that read messages from topics.
Consumers subscribe to topics, pulling data from Kafka brokers.
6. Consumer Groups:
Consumers are organized into Consumer Groups.
Each message within a partition is delivered to only one consumer within the group, which enables load balancing across multiple consumers.
7. ZooKeeper (optional in newer versions):
ZooKeeper manages and coordinates Kafka brokers, keeping track of brokers, topics, and partitions.
It helps manage the leader election for partitions and monitors cluster health.
Use Cases of Kafka
Real-time Analytics: Companies use Kafka to process and analyze streams of data in real-time for monitoring systems, like financial transaction analysis.
Log Aggregation: Kafka consolidates logs from multiple services or applications for processing, alerting, or storing.
Data Pipelines: Kafka is used as a backbone for transferring large amounts of data between different systems or services (ETL pipelines).
IoT Applications: Kafka can handle the data streams from IoT sensors, allowing real-time analysis and responses.
Microservices Communication: Kafka serves as a reliable messaging platform for microservices architectures, enabling asynchronous, decoupled communication.
Real-Time Vehicle Tracking: The following example illustrates how Kafka is used to track vehicles in real-time.
Example using Python to demonstrate how Kafka can be used in a real-time scenario :
Location tracking for a ride-sharing app.
For simplicity, we’ll use the kafka-python library to create both a producer (to simulate a driver sending location updates) and a consumer (to simulate a service that processes these location updates).
1. Setup Kafka
Make sure you have Kafka running locally or use a cloud provider. You can download and run Kafka locally by following the Kafka Quickstart Guide.
2. Install Kafka Python Library
You can install the Kafka Python library using pip:
pip install kafka-python
3. Python Kafka Producer (Simulating Driver Location Updates)
The producer simulates a driver sending location updates to a Kafka topic (driver-location).
from kafka import KafkaProducer
import json
import time
import random
# Kafka Producer
producer = KafkaProducer(
bootstrap_servers=['localhost:9092'],
value_serializer=lambda v: json.dumps(v).encode('utf-8') # Serialize data to JSON
)
def send_location_updates(driver_id):
while True:
# Simulating random GPS coordinates (latitude, longitude)
location = {
"driver_id": driver_id,
"latitude": round(random.uniform(40.0, 41.0), 6),
"longitude": round(random.uniform(-74.0, -73.0), 6),
"timestamp": time.time()
}
# Send location data to Kafka
producer.send('driver-location', location)
print(f"Sent: {location}")
time.sleep(5) # Sleep for 5 seconds to simulate real-time updates
# Start sending updates for driver_id = 101
send_location_updates(driver_id=101)
4. Python Kafka Consumer (Simulating Ride Matching Service)
The consumer reads the location updates from the driver-location topic and processes them.
from kafka import KafkaConsumer
import json
# Kafka Consumer
consumer = KafkaConsumer(
'driver-location',
bootstrap_servers=['localhost:9092'],
auto_offset_reset='earliest', # Start from the earliest message
enable_auto_commit=True,
group_id='location-group',
value_deserializer=lambda x: json.loads(x.decode('utf-8')) # Deserialize data from JSON
)
def process_location_updates():
print("Waiting for location updates...")
for message in consumer:
location = message.value
driver_id = location['driver_id']
latitude = location['latitude']
longitude = location['longitude']
timestamp = location['timestamp']
print(f"Received location update for Driver {driver_id}: ({latitude}, {longitude}) at {timestamp}")
# Start consuming location updates
process_location_updates()
Explanation:
Producer (Driver sending location updates):
The producer sends a JSON object to the Kafka topic
driver-locationwith fields likedriver_id,latitude,longitude, andtimestamp.The producer simulates real-time GPS updates by sending location data every 5 seconds.
Consumer (Ride-matching service):
The consumer subscribes to the
driver-locationtopic, listening for updates.Each time a location update is published to Kafka, the consumer processes and prints it, simulating a service that uses this data to match drivers and riders.
Running the Example (I am running on windows machine):
Start the Zookeeper
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties
2. Start your local Kafka server.
.\bin\windows\kafka-server-start.bat .\config\server.properties
Now Run the producer and Consumer in 2 seperate terminal windows using python.
3. Run the producer script to simulate the driver sending location updates.
4. Run the consumer script to see the ride-matching service processing the location updates in real-time.
Conclusion
Apache Kafka provides an exceptional platform for managing real-time data streams. By combining Kafka with Python, developers can build powerful data pipelines and real-time analytics solutions.
Whether it’s vehicle tracking, IoT data, or real-time dashboards, Kafka with Python is highly scalable and can be adapted to various use cases. So, start experimenting with Kafka, and you’ll be amazed by its potential in real-world applications!
Subscribe to my newsletter
Read articles from keshav dk directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
keshav dk
keshav dk
Python developer with expertise in web development and data science. Experienced in building scalable applications using FastAPI, Streamlit, Django,Flask, PostgreSQL and SQLite. Enthusiast of real-time messaging systems and decentralized applications. Committed to leveraging cutting-edge technology to solve complex problems and enhance user experiences.