Day 2 : End to End Generative AI Pipeline | Part 1
 Manav Paul
Manav Paul
👋🏻 Welcome back to my blog! On Day 1, we explored the fundamentals of generative AI and its potential applications. Today, we'll dive deeper into the exciting process of building end-to-end generative AI pipelines.
Full Playlist : ▶ Master GenAI Series
If you're new here, I'm Manav Paul, a 24-year-young spiritual developer on a mission to understand and leverage the power of generative AI. This blog serves as a roadmap, guiding you through my 30-day journey of discovering the fascinating world of generative AI. Let's continue our exploration together!
Steps for Generative AI Pipeline
This pipeline serves as a roadmap, guiding us through the process of building and deploying generative AI models. It involves a series of interconnected steps, each playing a crucial role in the overall success of the project.
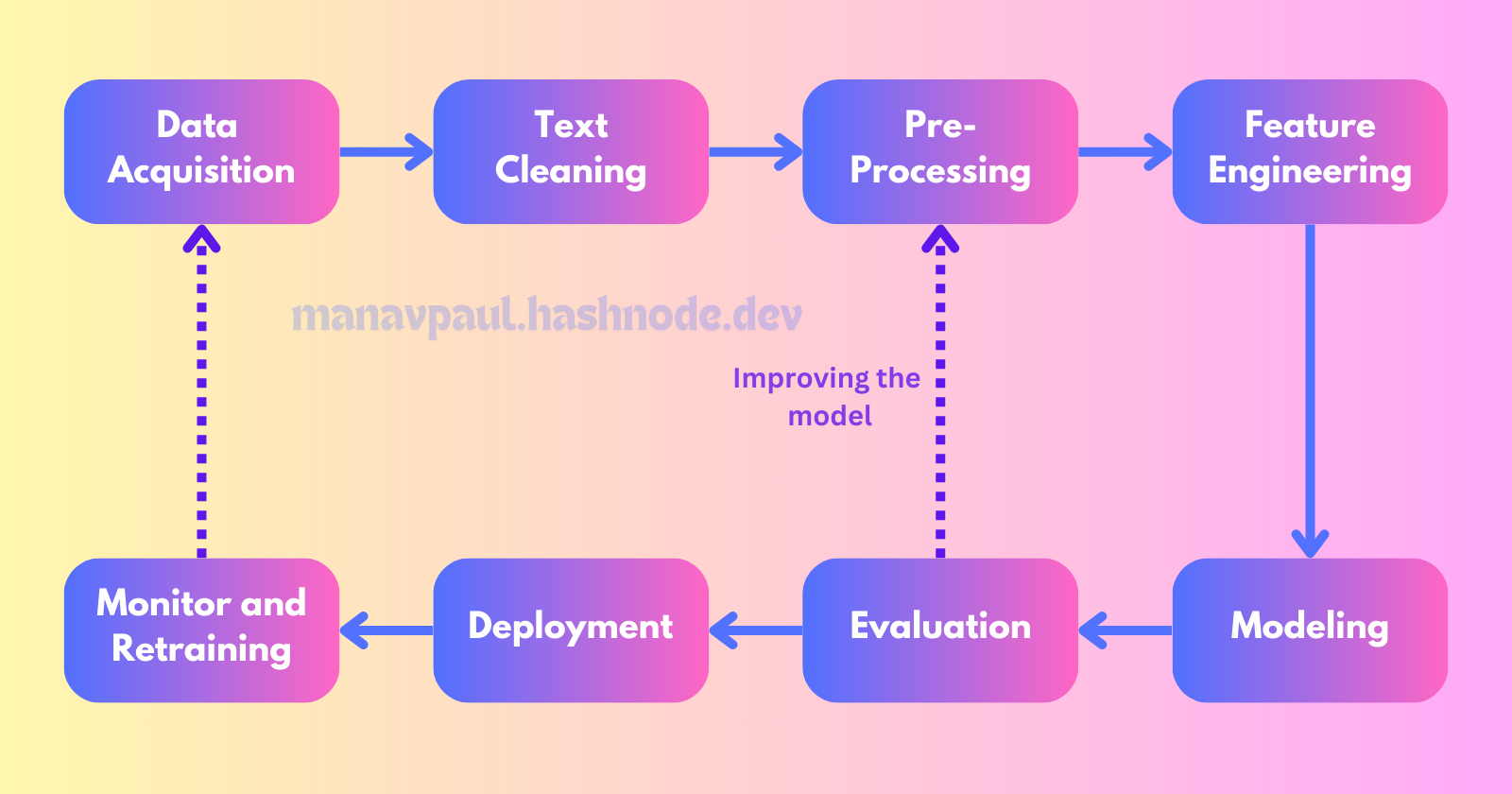
Let's delve into the seven fundamental stages of the generative AI pipeline:
Data Acquisition: Gathering the raw materials that will fuel our generative models.
Data Preparation: Cleaning, preprocessing, and transforming the data to make it suitable for training.
Feature Engineering: Extracting meaningful information from the data to enhance model performance.
Modeling: Selecting and training appropriate generative AI models to learn patterns and generate new content.
Evaluation: Assessing the quality and effectiveness of the generated content.
Deployment: Integrating the trained model into real-world applications.
Monitoring and Model Updating: Continuously evaluating and refining the model to ensure optimal performance.
Great! Now let’s understand each step in detail.
1. Data Acquisition : Building Foundation
The first and foremost step in the generative AI pipeline is data acquisition. This involves collecting a suitable dataset that will serve as the foundation for training your model. The quality and quantity of your data will significantly impact the performance and capabilities of your generative AI model.
1.1 Checking for Available Data
Before embarking on data collection, it's essential to check for existing datasets that align with your project's goals. Common data formats include:
CSV: Comma-Separated Values
TXT: Plain Text
PDF: Portable Document Format
DOCS: Microsoft Word Documents
XLSX: Microsoft Excel Files
1.2 Acquiring Data from Other Sources
If you can't find a suitable dataset readily available, consider these alternative sources:
Databases: Accessing existing databases that contain relevant information.
Internet: Searching for publicly available datasets online or through academic repositories.
APIs: Fetching data from external APIs that provide access to specific datasets.
Web Scraping: Extracting data from websites using automated tools.
1.3 Creating Your Own Data
In cases where existing datasets are insufficient or unavailable, you may need to generate your own data. This can be achieved through:
Manual Creation: Manually inputting or collecting data based on your specific requirements.
LLM-Generated Data: Utilizing large language models like OpenAI's GPT-3 to generate synthetic data.
Data Augmentation Techniques
Data augmentation involves creating new data samples from existing ones by applying various transformations. Here are some common methods:
Synonym Replacement: Replacing words with synonyms to create variations of the original text.
Example:Original sentence: "The book is interesting."Augmented sentence: "The book is captivating."
Image Transformations: Applying transformations to images, such as horizontal flipping, vertical flipping, rotation, brightness adjustments, noise addition, and cropping.
Example:Original image: A photo of a cat sitting on a couch.Augmented images: The same photo flipped horizontally, rotated 45 degrees, brightened, with added noise, and cropped.
Bigram Flipping: Swapping word pairs within a sentence to create new sentence structures.
Example:Original sentence: "The cat is sleeping."Augmented sentence: "Is the cat sleeping?"
Backtranslation: Translating text into another language and then back into the original language to introduce linguistic variations.
Example:Original sentence: "I love to read books."Augmented sentence: "I enjoy perusing literature." (Translated into Spanish and then back into English)
Adding Additional Data or Noise: Incorporating additional information or random noise to increase diversity.
Example:Original sentence: "The weather is sunny."Augmented sentence: "The weather is sunny today, and the sky is blue. There are clouds in the distance."
2. Data Preprocessing : Preparing Your Data for Generative AI
Once you've acquired your dataset, the next crucial step is data preprocessing. This involves cleaning, transforming, and preparing your data to make it suitable for training your generative AI model. Effective data preprocessing can significantly improve the quality and accuracy of your model's output.
2.1 Cleaning Up Your Data
Remove HTML tags: If your data contains HTML elements, remove them to ensure clean text.
Remove emojis: Emojis can introduce noise into your data, so it's often beneficial to remove them.
import emoji text = emoji.emojize("Python is fun :red_heart:") print(text)Python is fun ❤Text = text.encode("utf-8") print(Text)b'Python is fun \xe2\x9d\xa4'Perform spell check and correction: Correct any spelling errors or typos to improve data accuracy.
2.2 Basic Preprocessing
2.2.1 Tokenization
Sentence tokenization: Break the text into individual sentences.
Word tokenization: Break each sentence into individual words.
Example:
Sentence tokenization: "My name is Manav. I am a developer."
["My name is Manav.", "I am a developer."]
Word tokenization: "My name is Manav."
["my", "name", "is", "Manav"]
2.2.2 Optional Preprocessing
Stop word removal: Remove common words that don't carry significant meaning (e.g., "the," "and," "a").
Stemming: Reduce words to their root form (e.g., "played" becomes "play").
Lemmatization: Reduce words to their dictionary form (e.g., "better" becomes "good").
| Stemming | Lemmatization |
| Process that stems or removes last few characters from a word, often leading to incorrect meanings and spelling. | Considers the context and converts the word to its meaningful base form, which is called Lemma. |
| stemming the word ‘Caring‘ would return ‘Car‘ or ‘Running’ to ‘Run’. | lemmatizing the word ‘Caring‘ would return ‘Care‘. |
| Stemming is used in case of large dataset where performance is an issue. | Lemmatization is computationally expensive since it involves look-up tables and what not. |
| Faster, but may create unrecognizable words and lose meaning. This is known as “over stemming.” | More accurate, preserves meaning and grammatical function, but slower. |
Punctuation removal: Remove punctuation marks (e.g., commas, periods, exclamation points).
Lowercasing: Convert all text to lowercase to standardize the data.
Language detection: Identify the language of the text to ensure appropriate preprocessing techniques are applied.
2.3 Advanced Preprocessing (Optional)
Parts of speech tagging: Assign grammatical tags to each word (e.g., noun, verb, adjective).
Implementation of Parts-of-Speech tagging using Spacy in Python# Installing Packages !pip install spacy !python -m spacy download en_core_web_sm#importing libraries import spacy # Load the English language model nlp = spacy.load("en_core_web_sm") # Sample text text = "The quick brown fox jumps over the lazy dog." # Process the text with SpaCy doc = nlp(text) # Display the PoS tagged result print("Original Text: ", text) print("PoS Tagging Result:") for token in doc: print(f"{token.text}: {token.pos_}") # Ouptut for the Code Original Text : The quick brown fox jumps over the lazy dog. POS Tagging Result: The : determiner (DT) quick : adjective (JJ) brown : adjective (JJ) fox : noun (NN) jumps : verb (VBZ) over : preposition (IN) the : determiner (DT) lazy : adjective (JJ) dog : noun (NN) . : punctuation (PUNCT)Parsing Tree: Analyze the syntactic structure of the text to understand relationships between words.
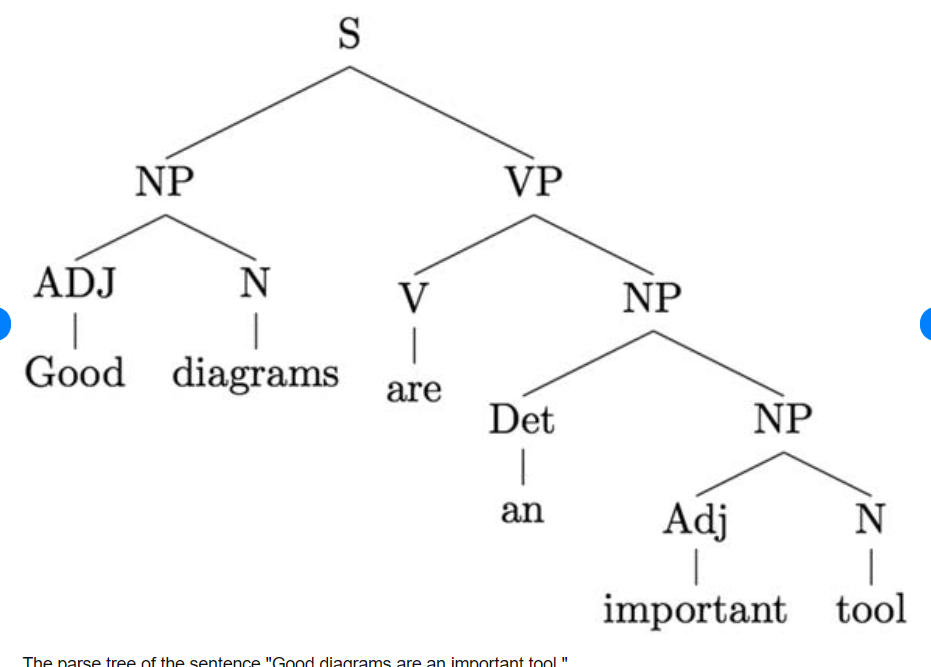
Coreference resolution: Identify entities that refer to the same object (e.g., Manav is a Yoga Instructor and he loves to do yoga everyday. "Manav" and "he").
By carefully preprocessing your data, you can ensure that your generative AI model is trained on high-quality, consistent information, leading to improved performance and accuracy.
🎉That's a wrap for Day 2! If you've reached this far, you've shown incredible dedication and determination. We've covered the first two crucial steps of the generative AI pipeline: data acquisition and data preparation. These are the building blocks that will set the foundation for your generative AI model.
In our next post, we'll delve into the third step: feature engineering. This involves extracting meaningful information from your data to enhance model performance. Stay tuned for more insights and exciting experiments!
▶ Next → Day 3: End-to-End Generative AI Pipeline | Part 2
⭐Github Repo : Journey Roadmap
Subscribe to my newsletter
Read articles from Manav Paul directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Manav Paul
Manav Paul
24, Documenting my journey of DevOps | GenAI | Blockchain | NFTs