Reactive Programming in Kotlin (Mono/Flux)
 Akash Tiwari
Akash TiwariTable of contents
- Problem Statement 🔍
- Challenge ⚔️
- Architecture Overview 🏛️
- How Reactive Streams Work: Breaking Down the Publisher-Subscriber Dance 🕺🏼💃
- Working of Thread under reactive programming (Publisher-Subscriber Model) 𓍼
- Publisher Interface (Mono/Flux)
- Performance Test (Synchronous, Mono, Flux) 🚀
- Results and Observations 📊
- Conclusion
- Key Takeaways 📌
- Socials 🤝

Problem Statement 🔍
In software development, it’s crucial to first understand the problem at hand before exploring potential solutions. Recently, I was working on an application structured into three layers: the Platform Layer, the Orchestrator Layer, and the UI Layer.
Challenge ⚔️
One significant challenge I encountered was the handling of multiple API calls from the Orchestrator to the Platform Layer in a synchronous manner. This approach proved to be quite difficult when trying to compile a response for the UI, which relies on data from various sources. The synchronous calls resulted in longer response times, as the Orchestrator had to wait for each API call to complete before proceeding to the next. This not only created bottlenecks in data retrieval but also effected the overall responsiveness of the application.
Understanding this problem led me to consider more efficient methods for managing API calls and aggregating data, ultimately tending towards reactive programming to enhance performance and responsiveness.
Architecture Overview 🏛️
Platform Layer: This layer consists of various APIs that provide essential data services.
Orchestrator Layer: The role of the Orchestrator is to aggregate information from the Platform Layer, handle the data as needed, and deliver it efficiently to the UI Layer.
UI Layer: This layer presents the aggregated data to the user in an interactive and responsive manner.
How Reactive Streams Work: Breaking Down the Publisher-Subscriber Dance 🕺🏼💃
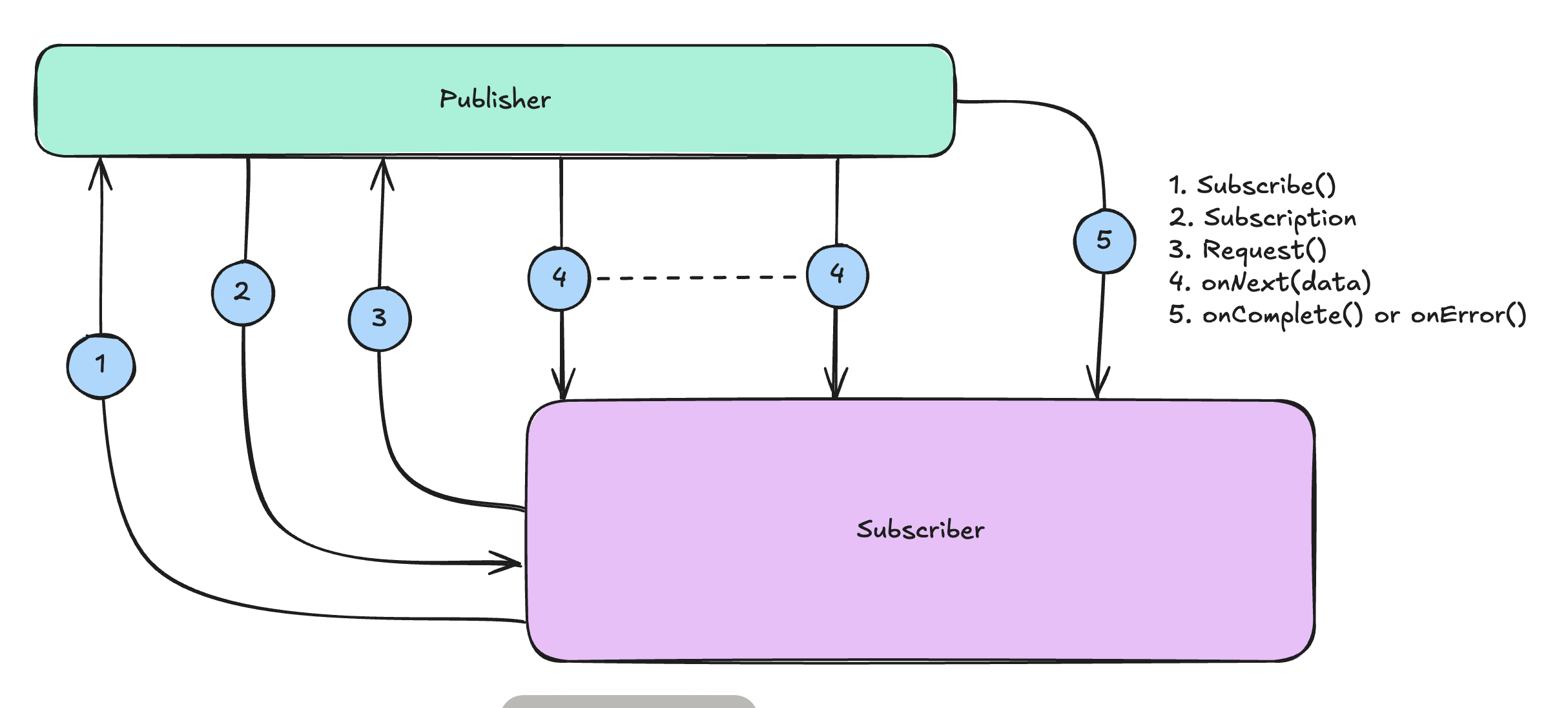
Reactive programming revolves around the Publisher-Subscriber model, where the data flows in the coordinated manner something like a request response model.
Subscribe() : By subscribing to the publisher, the subscriber let the publisher know that it wants data by calling subscribe().
Subscription : The publisher then sends a subscription (like an ACK) to the subscriber.
Request() : Then the subscriber request the kind of data that has been published by the publisher to consume
onNext(data) : The Publisher starts sending data items one at a time with onNext(), and the Subscriber processes each item as it arrives. This back-and-forth continues until all requested data is sent.
onComplete() : When all data has been sent, the Publisher sends an onComplete() signal to indicate that it’s finished. If there’s an error, it sends onError() instead so the Subscriber can handle it.
Working of Thread under reactive programming (Publisher-Subscriber Model) 𓍼
Traditional way of request handling in Java/Kotlin
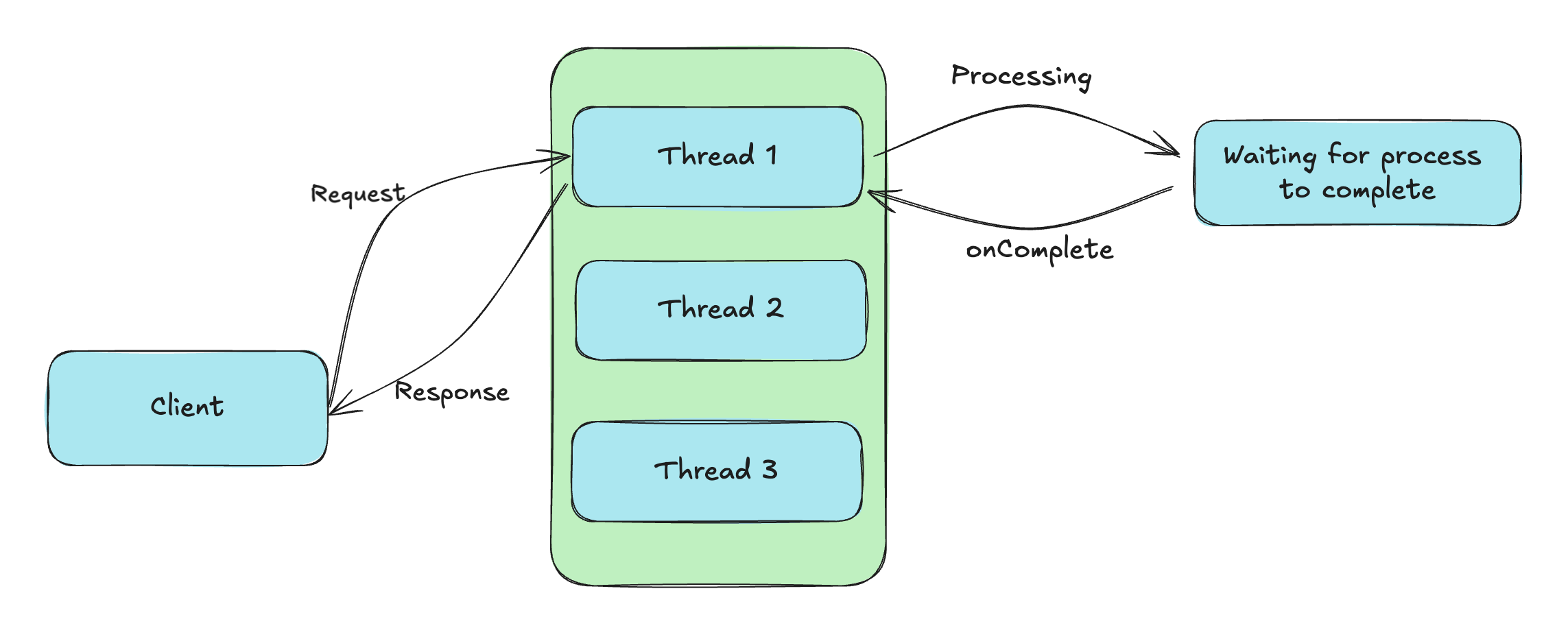
Problem:
For every request java/kotlin creates a new thread to execute it, and wait for the response (But thread count is limited in the pool), so as the thread count exceeds the limit, then incoming requests have to wait until a thread executes the previous request. This becomes a bottleneck as the system scales.
Now lets check what happens if we use Reactive Programming instead of traditional way of request handling.
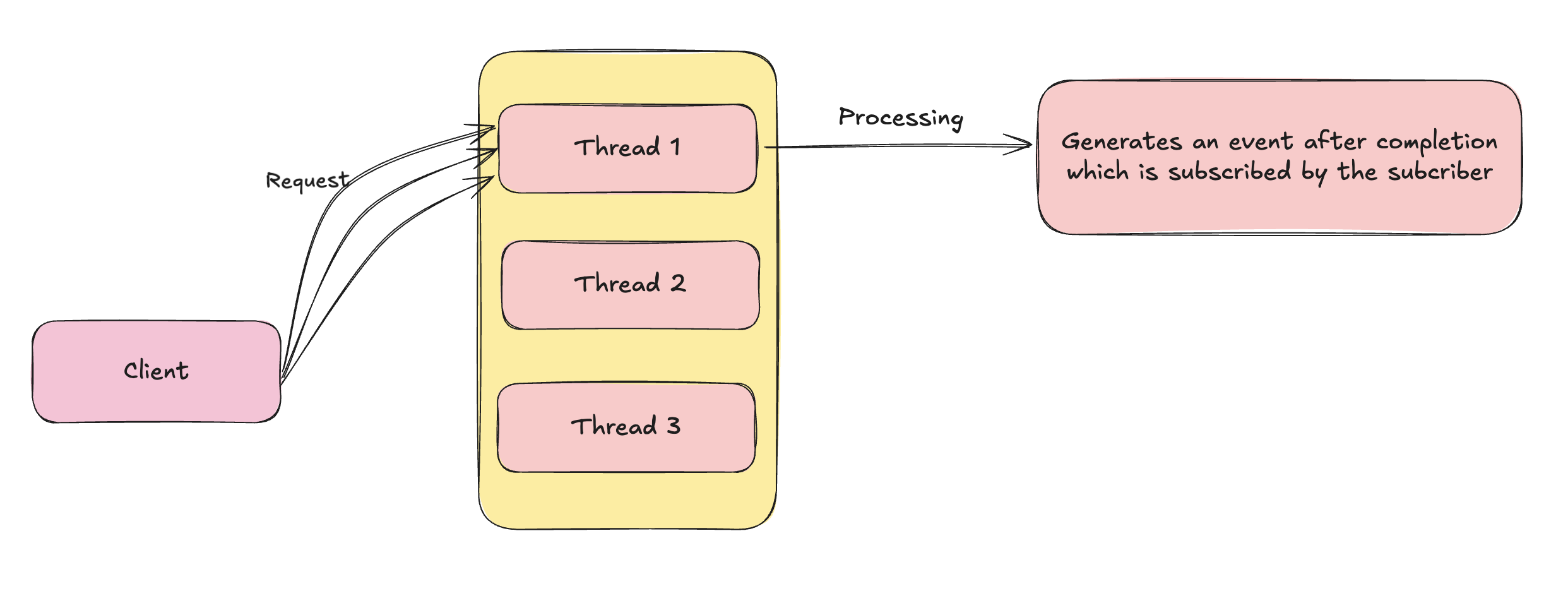
When a request arrives, it’s assigned to an available thread.
Thread 1 pushes the request for further processing.
Thread 1 immediately becomes free to handle other incoming requests, rather than waiting for the processing to complete.
Once processing is complete, an event is generated, which is already subscribed to by the Subscriber.
The Publisher sends the processed data to the Subscriber without occupying the thread throughout the entire processing time.
Publisher Interface (Mono/Flux)
Lets get to some implementation of what we are talking about till now.
Mono and Flux are two implementations of the Publisher interfaces.
Mono is generally used if we want a single object out of the request we made to the databases or the external services while
Flux is generally used when we expect a stream of data from the request made to the databases or external services.
package com.example
import org.junit.jupiter.api.Test
import reactor.core.publisher.Flux
import reactor.core.publisher.Mono
enum class Gender {
MALE, FEMALE
}
data class People(
val name: String,
val gender: Gender
)
class ReactiveTest {
@Test
fun `logging for mono stream`() {
val peopleList = Mono.just(listOf(
People("Akash", Gender.MALE),
People("Aditi", Gender.FEMALE),
People("Rohan", Gender.MALE),
People("Sara", Gender.FEMALE)
)).log()
peopleList.subscribe(System.out::println)
}
@Test
fun `logging for flux stream`() {
val peopleList : Flux<People> = Flux.just(
People("Akash", Gender.MALE),
People("Aditi", Gender.FEMALE),
People("Rohan", Gender.MALE),
People("Sara", Gender.FEMALE)
).log()
peopleList.subscribe(System.out::println)
}
}
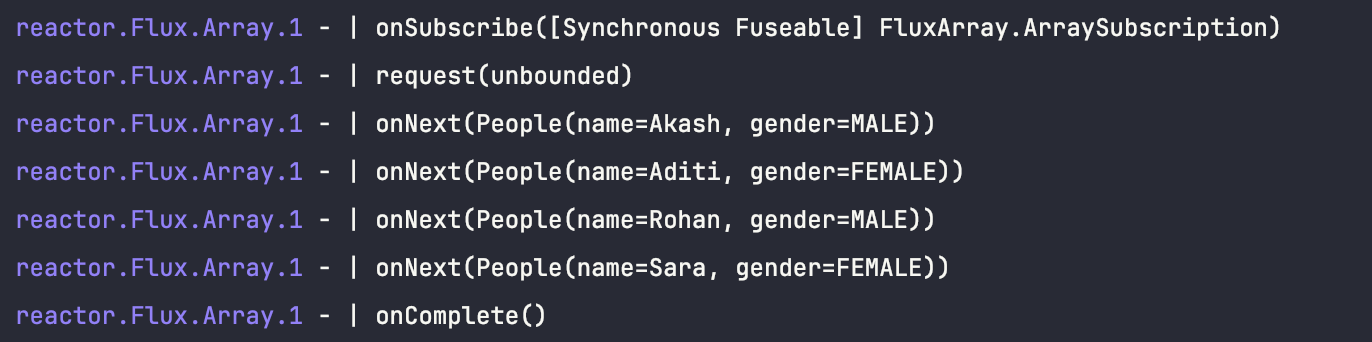
Logging will help here to know whats happening behind the mono and flux wall
Below image shows the working of a Flux, and show how the objects has been sent one by one and got the onComplete() status when publisher sent all the objects to the subscriber.
Below image shows the working of a Mono, and show how the objects has been sent in one go and got the onComplete() status when publisher sent the object to the subscriber.

Performance Test (Synchronous, Mono, Flux) 🚀
The core of our comparison is the PerformanceTest class, which contains three methods to measure processing times for each approach:
Synchronous Processing
Mono Processing
Flux Processing
package com.example
import org.junit.jupiter.api.Test
import reactor.core.publisher.Flux
import reactor.core.publisher.Mono
import reactor.core.scheduler.Schedulers
import kotlin.system.measureTimeMillis
enum class Gender {
MALE, FEMALE
}
data class People(
val name: String,
val gender: Gender
)
class PerformanceTest {
@Test
fun `measure time for traditional synchronous processing`() {
val peopleList = listOf(
People("Akash", Gender.MALE),
People("Aditi", Gender.FEMALE),
People("Rohan", Gender.MALE),
People("Sara", Gender.FEMALE)
)
val timeTaken = measureTimeMillis {
peopleList.forEach { process(it) }
println("Thread: ${Thread.currentThread().name}")
}
println("Traditional synchronous processing took: $timeTaken ms")
}
@Test
fun `measure time for Mono processing with parallel scheduler`() {
val peopleMono = Mono.just(People("Akash", Gender.MALE))
val timeTaken = measureTimeMillis {
peopleMono
.flatMap { person ->
Mono.fromCallable {
process(person)
}
.subscribeOn(Schedulers.parallel())
.doOnNext { println("Processed on thread: ${Thread.currentThread().name}") }
}
.block()
}
println("Mono processing took: $timeTaken ms")
}
@Test
fun `measure time for Flux processing with parallel scheduler`() {
val peopleFlux = Flux.just(
People("Akash", Gender.MALE),
People("Aditi", Gender.FEMALE),
People("Rohan", Gender.MALE),
People("Sara", Gender.FEMALE)
)
val timeTaken = measureTimeMillis {
peopleFlux
.flatMap { person ->
Mono.fromCallable {
process(person)
}
.subscribeOn(Schedulers.parallel())
.doOnNext { println("Processed ${person.name} on thread: ${Thread.currentThread().name}") }
}
.collectList()
.block()
}
println("Flux processing took: $timeTaken ms")
}
private fun process(person: People) {
Thread.sleep(100)
println("Processing ${person.name} on thread: ${Thread.currentThread().name}")
}
}
When we run these tests, we measure the time taken for each processing method:
Traditional Synchronous Processing: This method processes each person one after the other, leading to a cumulative wait time.
Mono Processing: This method uses a parallel scheduler to process a single person reactively, showing the benefits of reactive programming in a single instance.
Flux Processing: This method uses
Fluxto process a collection of people concurrently, allowing multiple tasks to run simultaneously on different threads.
Results and Observations 📊
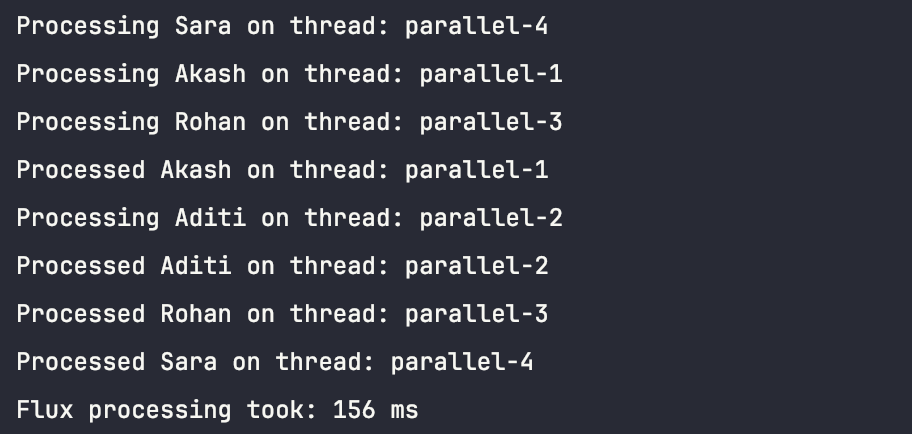
Synchronous processing took : 415ms
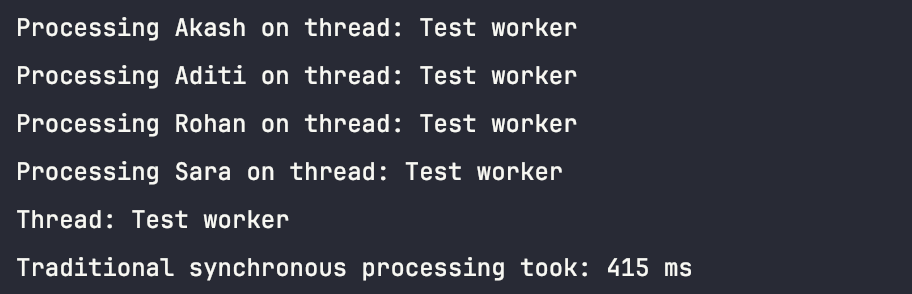
Mono processing took : 108ms

Flux processing took : 156ms
Conclusion
The comparison of synchronous versus reactive processing in Kotlin highlights the performance benefits of using reactive programming. By leveraging non-blocking operations, developers can build applications that are more responsive and scalable.
In conclusion, the choice between these processing models should be based on the specific needs of your application. For tasks that can benefit from concurrency, reactive programming may offer substantial advantages.
Key Takeaways 📌
Understanding the Problem is Key: Before jumping into solutions, thoroughly understanding the challenges in your application architecture—like handling multiple API calls efficiently—is crucial for selecting the right approach.
Reactive Programming improves Responsiveness: Switching from a synchronous to a reactive model can significantly improve application responsiveness and performance by allowing multiple operations to be processed concurrently.
Efficient Resource Utilisation: Reactive programming enables better resource management by freeing up threads during I/O operations, allowing them to handle other requests instead of blocking while waiting for data.
Mono vs. Flux: Knowing when to use
Mono(for single data object) andFlux(for multiple data objects) helps in structuring your reactive streams appropriately and effectively managing the expected data.Performance Benefits: As demonstrated in the performance tests, reactive processing can lead to substantial performance improvements over traditional synchronous processing. The measured time differences indicate the potential for greater throughput and reduced latency.
Socials 🤝
Subscribe to my newsletter
Read articles from Akash Tiwari directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Akash Tiwari
Akash Tiwari
Full Stack Web Developer | 👀 my ways to Devops