Exploring Unconditional, Conditional, and Controllable Generation
 Arya M. Pathak
Arya M. PathakTable of contents
Generative Adversarial Networks (GANs) have evolved significantly since their inception, allowing developers to produce highly specific and realistic images based on controlled inputs. In this article, we’ll explore how GANs generate images in various ways, including unconditional, conditional, and controllable generation, delving into the underlying mechanisms and mathematical principles that make these methods possible.

We'll also address challenges such as feature correlation and Z-space entanglement, illustrating how these issues impact the control over specific features in generated images. Understanding these concepts is essential to achieving fine-tuned generation results in real-world applications, where control over classes and features becomes crucial.
For foundational GAN insights, refer to DeepLearning.AI.
Unconditional Generation: The Foundation of GANs
Unconditional generation is the most basic approach in GANs, where images are generated without any class constraints. In this setup, a GAN consists of a generator ( G ) and a discriminator ( D ) that compete in a minimax game to generate realistic samples.
Mathematical Overview of Unconditional GANs
Noise Vector and Generation Process:
The generator \(G\) receives a noise vector \(\mathbf{z}\) as input, typically sampled from a multivariate normal distribution \( \mathcal{N}(0, I)\) or a uniform distribution \(\mathcal{U}(-1, 1)\).
This noise vector \( \mathbf{z}\) is transformed by \(G\) into an output image \(x' = G(\mathbf{z})\).
Objective of GAN Training:
- The generator and discriminator are trained in an adversarial manner, where \(G\) tries to generate images that resemble real data, and \( D\) attempts to distinguish between real images (from the training set) and fake images (generated by \(G \) ).
Mathematically, the objective is to solve the following minimax game:
$$\min_G \max_D V(D, G) = \mathbb{E}{x \sim p{\text{data}}}[\log D(x)] + \mathbb{E}{\mathbf{z} \sim p{\mathbf{z}}}[\log (1 - D(G(\mathbf{z})))]$$
where \( p_{\text{data}}\) is the distribution of real data, and \(p_{\mathbf{z}}\) is the distribution of the noise vector.
Outcome:
- With enough training, the generator \(G\) produces images from a mixture of classes, analogous to a “gumball machine” that outputs random colors. Here, the generator does not discriminate between classes, and images are drawn from a general distribution similar to the training data.
Since this method relies purely on the data distribution, it’s well-suited for applications where class distinctions aren’t critical, but it lacks control over specific image attributes, such as category or style.
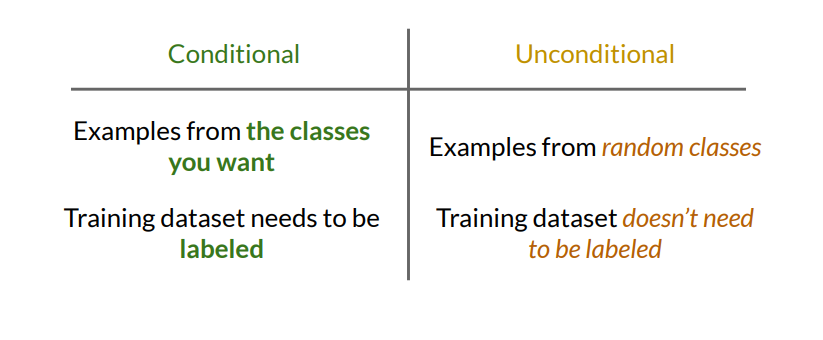
Conditional Generation: Control Over Class-Based Outputs
To generate images from specific classes, conditional generation modifies the GAN by introducing class information as an additional input. This method is essential in scenarios where precise control over image classes is needed, such as generating specific types of animals, vehicles, or other identifiable objects.
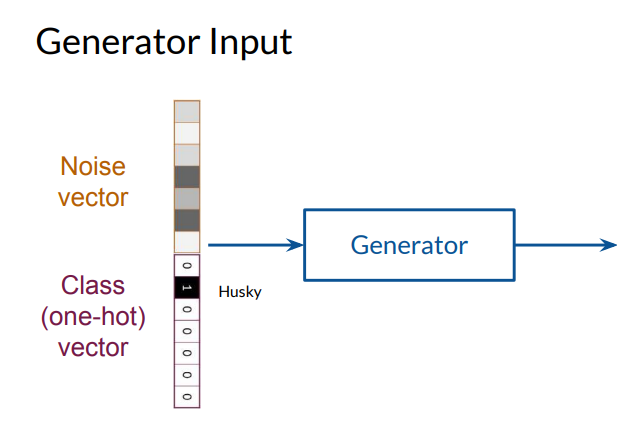
Mathematical Structure of Conditional GANs
In a conditional GAN, both the generator \(G\) and discriminator \(D\) receive additional information about the desired class of the generated image. This class information is typically encoded as a one-hot vector \( \mathbf{y}\), where:
\(\mathbf{y} \in {0,1}^k \) represents the class label, with \(k\) being the number of classes.
The vector \( \mathbf{y}\) has only one non-zero element, which specifies the target class.
The generator receives a concatenated vector \([\mathbf{z}, \mathbf{y}] \) where:
$$[\mathbf{z}, \mathbf{y}] = \begin{bmatrix} z_1 \ z_2 \ \vdots \ z_n \ y_1 \ y_2 \ \vdots \ y_k \end{bmatrix}$$
with \(\mathbf{z} \) being the noise vector and \(\mathbf{y}\) the class information.
- Objective of Conditional GAN Training:
The objective function for a conditional GAN modifies the unconditional GAN loss by conditioning both the generator and discriminator on \(\mathbf{y} \) :
$$\min_G \max_D V(D, G) = \mathbb{E}{x, y \sim p{\text{data}}}[\log D(x | y)] + \mathbb{E}{\mathbf{z} \sim p{\mathbf{z}}, y \sim p_{\text{label}}}[\log (1 - D(G(\mathbf{z}, y) | y))]$$
where \(p_{\text{label}}\) is the distribution of class labels.
Training Dynamics:
The discriminator \(D\) is trained to recognize not just the realism of the image but also its class consistency with \(\mathbf{y}\).
The generator, therefore, learns to produce realistic images specific to the given class label, minimizing the probability that \(D\) detects any mismatch between the generated image and the specified class.
Analogies and Control:
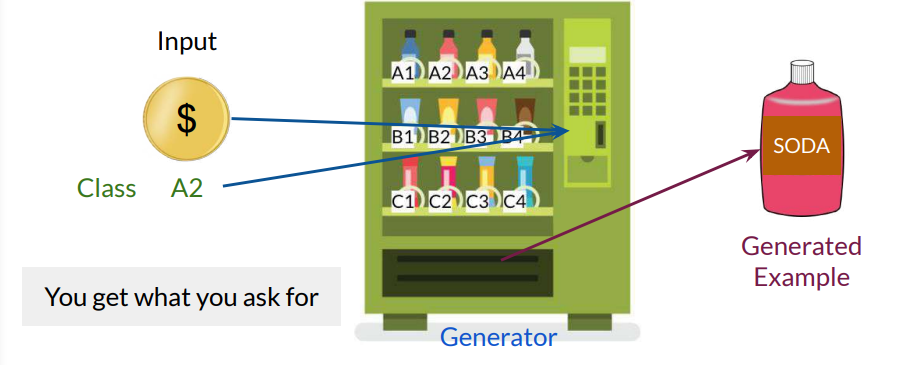
- Compared to the gumball machine analogy of unconditional GANs, conditional GANs resemble a vending machine. With conditional GANs, we can specify the class (e.g., a specific drink) but cannot fine-tune individual features, like whether the drink bottle is exactly filled to the top.
Conditional generation proves highly effective in applications that require class-specific outputs. However, it still lacks control over individual features, such as hairstyle or facial expression in human images, which brings us to controllable generation.
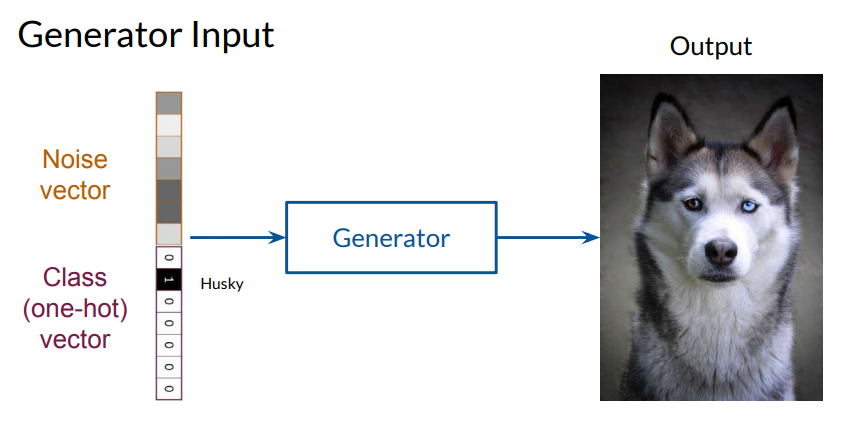
Controllable Generation: Fine-Tuning Features in Outputs
Controllable generation enables manipulation of specific features in generated images, allowing for post-training adjustments. Unlike conditional generation, which relies on labeled datasets for each class, controllable generation leverages the latent space (Z-space) to alter certain aspects, like age, hairstyle, or other non-discrete features.
Mathematics of Controllable Generation and Z-Space Manipulation
Noise Vector Manipulation:
Given a noise vector \(\mathbf{z}\) that generates an image ( x = \(G(\mathbf{z})\) ), controllable generation identifies directions in Z-space that correspond to specific feature changes. For example, altering hair color or facial expression.
If \(\mathbf{d}\) is the direction vector associated with a feature (e.g., hair color), we can generate a modified image by inputting \( \mathbf{z}' = \mathbf{z} + \alpha \mathbf{d}\) into the generator, where \(\alpha \) controls the intensity of the feature.
Interpolation:
- A related concept, interpolation, allows generation of transitional images between two points \(\mathbf{z}_1 \) and \(\mathbf{z}_2\) in the Z-space:
$$\mathbf{z}_t = (1 - t)\mathbf{z}_1 + t\mathbf{z}_2, \quad t \in [0, 1]$$
- Feeding \( \mathbf{z}_t \) into the generator produces images that gradually morph from \( G(\mathbf{z}_1) \) to \( G(\mathbf{z}_2)\), useful for generating intermediate states or “interpolated” images between different feature settings.
Challenges in Finding Directions \(\mathbf{d}\):
- Identifying exact directions \(\mathbf{d} \) in Z-space for feature control remains a challenge. Methods such as principal component analysis (PCA) or supervised approaches (e.g., training auxiliary models) can help discover the directions that correspond to features like “age” or “beard presence.”
With controllable generation, the generator can be manipulated to produce images reflecting the desired feature adjustments by moving in specific directions in the Z-space. This method offers flexibility, as no new training labels are required post-training, though it is limited by the latent space structure.
Challenges in Controllable Generation: Feature Correlation and Entanglement
Despite its flexibility, controllable generation faces significant challenges that limit its effectiveness in producing isolated feature changes.
Feature Correlation:
- Often, features in a dataset are correlated (e.g., beard presence may be correlated with masculinity). This correlation can interfere with controllable generation, making it difficult to isolate features for manipulation. For instance, modifying the beard feature in an image might also alter other aspects, like the apparent masculinity of the face.
Z-Space Entanglement:
In some cases, movement along certain directions in Z-space affects multiple features, even if they are not correlated in the training data. This is known as Z-space entanglement, where latent space dimensions are “tangled,” causing unintended modifications to multiple features.
For example, adding glasses to a generated face might unintentionally alter hair color or skin tone. This entanglement is particularly common when the Z-space dimensionality is insufficient for the number of features or when training data lacks diversity in feature representation.
Addressing Z-Space Entanglement
Various methods are used to counteract Z-space entanglement, including:
Increasing Dimensionality: Adding dimensions to the Z-space to better separate features.
Disentangled Representations : Leveraging disentangled representation learning, which aims to create latent spaces where each dimension controls a distinct feature.
Feature-Specific Projections: Utilizing techniques like StyleGAN’s adaptive instance normalization (AdaIN), which projects features independently, thus reducing entanglement.
Summary: From Class Control to Feature Control in GANs
GANs have progressed from generating random samples (unconditional generation) to class-specific images (conditional generation) and further to feature-adjusted images (controllable generation). Unconditional GANs rely solely on noise vectors, while conditional GANs incorporate class labels for more targeted outputs. Controllable generation, by contrast, enables post-training feature adjustments through Z-space manipulation.
Each approach offers distinct benefits and limitations, from requiring labeled datasets in conditional generation to addressing entanglement in controllable generation. Future advancements in GANs will likely focus on disentangling Z-space, enhancing feature separation, and refining methods for class-specific and feature-specific generation.
To explore more about GANs and their applications, refer to DeepLearning.AI for comprehensive insights into this rapidly advancing field.
Subscribe to my newsletter
Read articles from Arya M. Pathak directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Arya M. Pathak
Arya M. Pathak
I am a Computer Engineering undergraduate at Vishwakarma Institute of Technology, Pune . With hands-on experience in software development and cloud-native applications, I specialize in Python, Go, C#, and full-stack web development using MERN, ASP.NET Core, and Angular. I have interned at Alemeno and CodingKraft, where I developed AI-driven compliance systems, Python execution engines, and secure web solutions. My projects include scalable microservices, machine learning pipelines, and secure banking APIs deployed on cloud platforms like Azure with Kubernetes and CI/CD automation. Adept in tools like Docker, Redis, RabbitMQ, and GitHub Actions, I am certified in Deep Learning and DevOps. I have a strong foundation in algorithms, having solved over 350 coding problems across platforms like Leetcode and Codeforces. Additionally, I actively contribute to open-source projects, mentoring initiatives, and hackathons.