Circular Buffers: The Smart Solution for Managing Data Streams
 Siddhartha S
Siddhartha S
Introduction
In the fast-paced world of finance, technology teams often encounter situations where they must handle an extraordinarily high flow of data. For instance, when processing real-time stock market feeds, every millisecond counts. Keeping systems within the permissible bounds of memory footprint and latency is essential, making efficient data structures critical. One such structure is the circular buffer. This concept, while not new, is often misunderstood, as many resources fail to address real-world caveats that arise when implementing it. Circular buffers are ideal when you need to maintain the latest n records of data from a feed rather than historical data, ensuring that you only keep what’s most relevant.
What is a Circular Buffer?
A circular buffer is a fixed-size data structure that uses a single, contiguous block of memory to maintain a dynamically changing dataset. When new data arrives, it overwrites the oldest data once the buffer is full, thereby ensuring that the buffer consistently contains the most recent entries.
Background
There are numerous implementations of circular buffers available, but I opted for a straightforward implementation that effectively served my purpose in the most elegant way. The requirement was to display market data on a C# GUI, while the data feed provider was delivering information at an extraordinarily high speed—like to a dragon breathing fire.
Fortunately, the user was only concerned with the last 10 feeds, rather than the historical data. This is the perfect scenario for using a circular buffer, which excels in scenarios where only the latest entries are relevant. Among the various implementations available, the most suitable one for our needs was a circular buffer implementation that supported the overwriting feature.
Real-world Applications
Circular buffers are not limited to finance; they find applications in various fields:
Networking: To handle incoming data packets without overwhelming the system.
Multimedia Streaming: For buffering audio and video streams to ensure smooth playback.
Sensor Data Management: In IoT devices, to keep track of the most recent sensor readings efficiently.
Implementation
Implementing a circular buffer is not overly complex and can be easily achieved using an array and two pointers, called head and tail. The head tracks the element that needs to be read, while the tail tracks the position where data will be added. Since it is a buffer, a fixed-size array is the best data structure for this purpose.
+---------------------+
| |
| Circular Buffer |
| |
+---------------------+
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
+---+---+---+---+---+---+---+---+---+
| x | x | x | | | | | | | <- Existing data
+---+---+---+---+---+---+---+---+---+
^(head) ^(tail)
Where:
- 'x' indicates filled slots (buffer elements).
- an empty slot is indicated by a blank space.
- 'head' indicates where data is read from.
- 'tail' indicates where new data will be added/overwritten.
As the tail moves to the end of the array, the new item overwrites the first element, as this is now the oldest. Since we care only about the latest n elements, overwriting the oldest data is acceptable.
+---------------------+
| |
| Circular Buffer |
| |
+---------------------+
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
+---+---+---+---+---+---+---+---+---+
| y | x | x | x | x | x | x | x | x | <- After adding new data
+---+---+---+---+---+---+---+---+---+
^(head) ^(tail)
Where:
- The pointer `tail` has moved to overwrite the oldest data (index 0 now contains 'y').
- Similar operations can continue as new data is added, overwriting older data in a circular fashion.
Caveats
One important consideration is that, instead of simply overwriting the reference of the first element, we could optimize our implementation by overwriting the properties of the first element. You may argue that reading and writing properties takes time, but the same can be said for garbage collection.
Additionally, some caveats to consider include:
Buffer Size: Choosing an inappropriate buffer size can lead to data loss if the buffer fills up too quickly.
Concurrent Access: In multi-threaded situations, care must be taken to synchronize access to the buffer to prevent data corruption.
Here is a screenshot of a comparative run conducted with 1 million objects in a buffer of size 5:
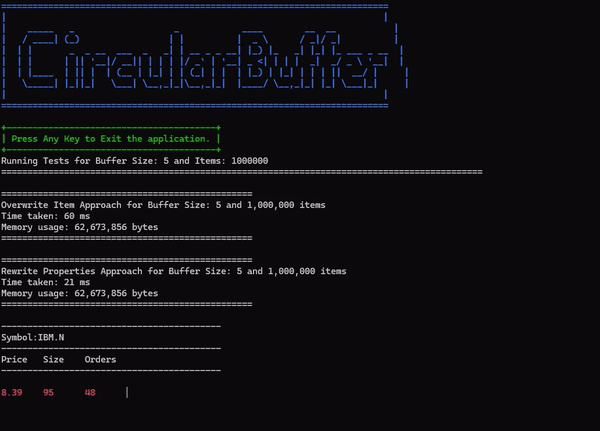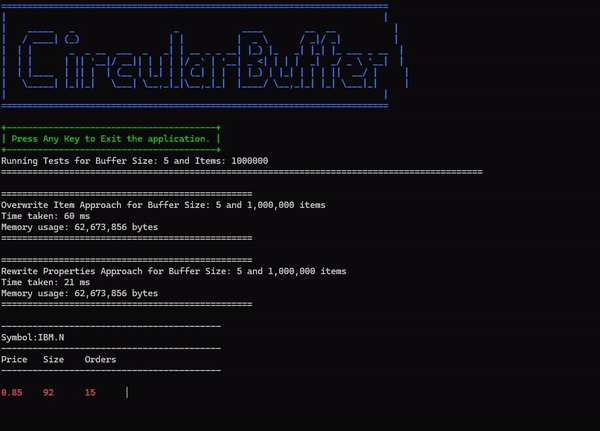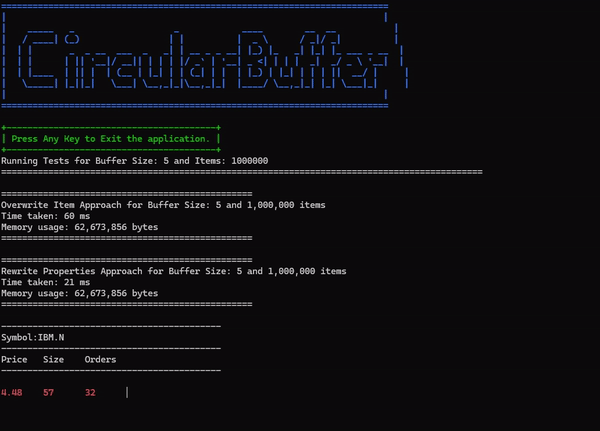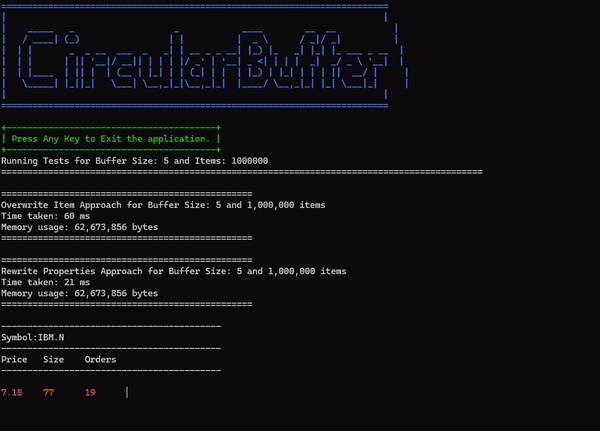
The circular buffer implementation and test code is available at the following location:
https://github.com/OxyProgrammer/circular-buffer
Performance Metrics
In my implementation, I found that using a circular buffer significantly improved performance in terms of memory usage and processing speed when compared to traditional array methods, which require shifting elements on every insertion.
Conclusion
Circular buffers are the default go-to data structure for scenarios with a heavy inflow of data when we only need to care about the last n items. They optimize memory usage and enhance processing efficiency, particularly useful in real-time applications. For smaller objects, overwriting properties is often more beneficial than overwriting the reference of an object, as it helps to avoid unnecessary garbage collection cycles.
Subscribe to my newsletter
Read articles from Siddhartha S directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Siddhartha S
Siddhartha S
With over 18 years of experience in IT, I specialize in designing and building powerful, scalable solutions using a wide range of technologies like JavaScript, .NET, C#, React, Next.js, Golang, AWS, Networking, Databases, DevOps, Kubernetes, and Docker. My career has taken me through various industries, including Manufacturing and Media, but for the last 10 years, I’ve focused on delivering cutting-edge solutions in the Finance sector. As an application architect, I combine cloud expertise with a deep understanding of systems to create solutions that are not only built for today but prepared for tomorrow. My diverse technical background allows me to connect development and infrastructure seamlessly, ensuring businesses can innovate and scale effectively. I’m passionate about creating architectures that are secure, resilient, and efficient—solutions that help businesses turn ideas into reality while staying future-ready.