GAN Disadvantages. VAEs and Bias: A Detailed Exploration
 Arya M. Pathak
Arya M. Pathak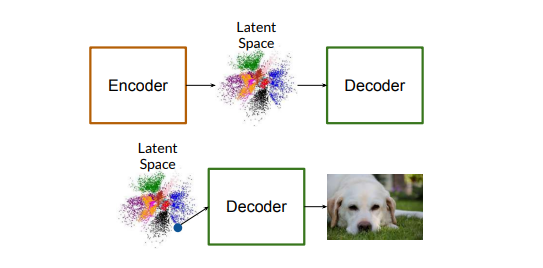
Generative Adversarial Networks (GANs) have become one of the most popular and effective models for generating high-quality synthetic data, excelling in applications like image synthesis, data augmentation, and video generation. However, understanding the limitations and biases within GANs is crucial for any practitioner or researcher, as these models come with inherent disadvantages that affect both their performance and fairness. This article will provide an in-depth analysis of the key technical disadvantages of GANs—such as instability in training, lack of evaluation metrics, challenges in density estimation, and invertibility issues. Additionally, we will explore how bias manifests in GANs and discuss its ethical implications, particularly in sensitive domains where it can reinforce societal inequalities.

For this overview, images and visual aids are sourced from DeepLearning.AI.
The Core Disadvantages of GANs
1. Lack of Concrete Evaluation Metrics
A primary disadvantage of GANs is the lack of robust, intrinsic evaluation metrics. In most machine learning models, evaluating model quality can be straightforward. However, in GANs, evaluation often relies on qualitative assessments or indirect metrics. For example, common GAN evaluation methods include:
Fréchet Inception Distance (FID): This metric measures the similarity between the generated images and real images by evaluating the differences between their feature distributions. While FID is effective, it relies heavily on pretrained Inception models that are often trained on biased datasets, potentially skewing evaluations.
Inception Score (IS): Inception Score assesses the diversity and quality of images by checking whether the generated samples produce strong predictions for a single class (indicating quality) while maintaining diversity across classes. This, too, relies on Inception models and may not capture subtle quality differences that humans notice.
While FID and IS provide some measure of performance, they fall short in capturing nuances such as fine-grained realism, distributional consistency, or application-specific requirements. Additionally, their dependence on pretrained models and approximate metrics means they cannot serve as definitive benchmarks for quality, leaving GAN evaluation a somewhat subjective and inconsistent process.
2. Training Instability
GAN training is notoriously unstable due to its adversarial structure, where two networks—the generator and the discriminator—compete against each other. This structure often leads to issues like:
Mode Collapse: A phenomenon where the generator produces limited or repetitive samples, ignoring the diversity of real data. Mode collapse occurs when the generator finds a "safe zone" that the discriminator struggles to challenge. For instance, when trained on MNIST, a GAN might produce only one digit, like repeated "sevens," failing to capture the variety of other digits in the dataset.
Gradient Instability: In GAN training, if gradients become unstable or vanishing, the adversarial loss oscillates or diverges, which can make optimization difficult. Techniques like Wasserstein loss and one-Lipschitz continuity have been introduced to stabilize gradients, reducing gradient instability by controlling the discriminator’s learning process.
Training GANs often requires tuning parameters, adjusting loss functions, and monitoring output quality continuously, making it resource-intensive and time-consuming. Although techniques like W-GANs and Gradient Penalty methods have improved stability, the need for extensive trial-and-error in training remains a significant drawback.
3. No Formal Density Estimation
GANs lack explicit density estimation, which limits their utility in applications that require probabilistic modeling. Density estimation is critical for calculating the likelihood of features in a dataset, as in anomaly detection, where unusual features could be flagged. Without a defined probability density, GANs approximate data distributions but do not assign specific likelihood values to generated outputs. This can hinder applications like anomaly detection, where knowing how likely certain features or combinations are (e.g., how often golden fur or floppy ears are associated with a “dog”) would aid in identifying outliers.
While GANs can approximate density indirectly by generating varied samples, they cannot directly compute probability densities, making them suboptimal for tasks requiring explicit probability distributions, such as modeling rare or atypical data patterns.
4. Invertibility Limitations
Invertibility refers to the ability to map generated images back to their original latent noise vectors. This ability is useful for applications like image editing, where identifying the latent representation of a real image allows specific features to be modified. Traditional GANs lack this invertibility because they do not learn bidirectional mappings between the noise vector and output space. Although methods such as Bidirectional GANs (BiGANs) and Invertible GANs (iGANs) attempt to remedy this, achieving high-quality, one-to-one invertibility remains challenging.
Without invertibility, it is difficult to conduct fine-grained editing of features in images generated by GANs. This limitation constrains the use of GANs in tasks where bidirectional mappings are essential, such as real-world image manipulation and refinement applications.
Variational Autoencoders (VAEs): Addressing GAN Disadvantages with Probabilistic Modeling
An alternative model architecture, the Variational Autoencoder (VAE), addresses several GAN disadvantages. VAEs are particularly valuable for applications that require density estimation, latent space modeling, and smoother training. Unlike GANs, VAEs are grounded in probabilistic theory and provide an explicit density function, making them suitable for tasks that GANs struggle with.
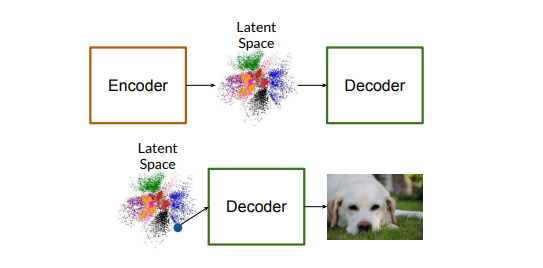
VAE Architecture and Mathematical Foundations
VAEs consist of two neural networks: an encoder and a decoder. The encoder learns a probability distribution over a latent space, mapping each input \(x\) to a distribution \(q(z|x)\) over latent variables \(z \) . The decoder then samples from this distribution to reconstruct the input. Mathematically, VAEs maximize the likelihood \( p(x|z)\) of generating data points similar to the input \(x\), while also minimizing the divergence between the approximate posterior \(q(z|x)\) and the prior \(p(z) \) through the following objective function:
$$\mathcal{L}{VAE} = - \text{KL}(q(z|x) || p(z)) + \mathbb{E}{q(z|x)} [\log p(x|z)]$$
The KL-divergence term \(- \text{KL}(q(z|x) || p(z)) \) minimizes the difference between the encoded distribution and the prior distribution, usually a Gaussian. The second term maximizes the log-likelihood of reconstructing the original data. The balance between these terms enables VAEs to provide meaningful density estimations, and the encoder-decoder structure facilitates invertibility.
Advantages of VAEs Over GANs
Density Estimation and Likelihood Calculation: The explicit density function provided by VAEs makes them ideal for anomaly detection, probabilistic reasoning, and any application requiring likelihood estimation.
Invertibility: The encoder in a VAE naturally provides a bidirectional mapping, which GANs lack. This makes VAEs suitable for tasks requiring reconstruction and editing of images based on latent space representations.
Training Stability: The VAE optimization objective ensures more stable training by directly minimizing reconstruction error, which helps avoid issues like mode collapse.

Despite these advantages, VAEs often produce lower-fidelity images than GANs, due to the Gaussian priors used in their latent spaces, which constrain image quality. However, advancements in VAE architecture, such as the Vector Quantized VAE (VQ-VAE2), have introduced autoregressive components that improve output quality, bridging the gap between VAEs and GANs.
Bias in GANs and Machine Learning: Ethical and Technical Challenges
Bias is a pervasive issue in machine learning and a particular concern in GANs, which can amplify societal inequalities. Biases arise from the data, model architecture, and evaluation methods, often affecting GAN performance on diverse demographic groups. Let’s examine several high-impact cases and sources of bias in GANs.
1. Bias in Criminal Justice Algorithms
Bias in machine learning, as demonstrated by the COMPAS algorithm, has revealed deep ethical concerns in criminal justice applications. The COMPAS algorithm, designed to predict recidivism, was found by ProPublica to display significant racial biases. Black defendants were disproportionately rated as high risk compared to white defendants, even when their records showed less severe criminal histories.

The COMPAS case highlights the limitations of proprietary, black-box algorithms, where bias can be hidden within unexposed model features or functions, limiting public scrutiny. This example underscores the ethical implications of model bias, especially in life-altering domains like criminal justice

2. Defining Fairness in Machine Learning
Fairness is notoriously difficult to define, with various interpretations used across machine learning research. Common definitions include:
Demographic Parity: Outcomes should be independent of sensitive attributes such as race or gender.
Equality of Odds: The probability of correct and incorrect predictions should be equal across different demographic groups.
Proportional Representation: Model outputs should match the demographics of the target population, such as generating representative faces across all ethnic groups.
Selecting fairness definitions and benchmarks is critical for bias mitigation, as different definitions address different dimensions of fairness. In GAN applications, fairness often requires balancing quality with demographic representativeness, especially when generating content intended to reflect human diversity.
3. Bias in GAN-Generated Images: The Case of Pulse
The Pulse system, which uses StyleGAN for upsampling, provides a clear example of bias in GAN-generated images. Pulse has been shown to generate biased outputs when synthesizing images of individuals from underrepresented demographic groups. For instance, when presented with a pixelated image of former President Barack Obama, Pulse produced an upsampled image that resembled a distinctly white man. This bias likely results from the demographic skew in StyleGAN’s training data, which contained a disproportionate number of lighter-skinned faces.

This case reveals the critical impact of training data bias in GANs and highlights the need
for diversity in training sets. It also underscores the complexities in evaluating GAN fairness, as biases can be hidden within datasets, model architectures, or training techniques.
4. Mitigating Bias in GANs
Addressing bias in GANs involves multiple strategies, including:
Adversarial Loss Adjustments: Introducing adversarial loss functions penalizing models for biased outputs, encouraging diversity in generated samples.
Diverse Data Collection: Ensuring balanced representation in training data to mitigate biases emerging from demographic imbalances.
Ethical Evaluation Metrics: Developing evaluation methods that measure performance across demographic groups to identify biases in model outputs.
Bias mitigation in GANs is an active research area, with new methods continuously emerging. Addressing bias in GANs is especially challenging given the subjective nature of image quality assessments, but recent developments in adversarial loss functions and diversity-driven evaluation offer promising directions.
Conclusion
GANs have redefined possibilities in image generation, offering unparalleled realism and variety in synthetic outputs. However, they also come with significant technical limitations—such as unstable training, lack of concrete evaluation metrics, limitations in density estimation, and difficulties with invertibility. Moreover, bias in GANs underscores the ethical challenges inherent in generative models, as biased outputs can perpetuate societal inequalities and reinforce existing prejudices.
Understanding these limitations is essential for anyone developing or deploying GANs, especially in applications requiring fairness and ethical considerations. By acknowledging and addressing both the technical disadvantages and biases within GANs, we can foster a more inclusive and responsible approach to generative modeling.
Images in this article are sourced from DeepLearning.AI.
Subscribe to my newsletter
Read articles from Arya M. Pathak directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Arya M. Pathak
Arya M. Pathak
I am a Computer Engineering undergraduate at Vishwakarma Institute of Technology, Pune . With hands-on experience in software development and cloud-native applications, I specialize in Python, Go, C#, and full-stack web development using MERN, ASP.NET Core, and Angular. I have interned at Alemeno and CodingKraft, where I developed AI-driven compliance systems, Python execution engines, and secure web solutions. My projects include scalable microservices, machine learning pipelines, and secure banking APIs deployed on cloud platforms like Azure with Kubernetes and CI/CD automation. Adept in tools like Docker, Redis, RabbitMQ, and GitHub Actions, I am certified in Deep Learning and DevOps. I have a strong foundation in algorithms, having solved over 350 coding problems across platforms like Leetcode and Codeforces. Additionally, I actively contribute to open-source projects, mentoring initiatives, and hackathons.