Certified Kubernetes Administrator (CKA) - Phần 2: Scheduling
 Phan Văn Hoàng
Phan Văn HoàngManual Scheduling
Bạn có thể không muốn dựa vào scheduler tích hợp sẵn và thay vào đó muốn tự mình lên lịch cho pod. Vậy chính xác thì scheduler hoạt động như thế nào.
Hãy bắt đầu với một tệp định nghĩa pod đơn giản:
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
name: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 8080
#nodeName: node02
Mỗi pod có một trường tên là nodeName theo mặc định nó không được đặt, bạn thường không chỉ định trường này khi tạo tệp khai báo pod, Kubernetes tự động thêm nó.
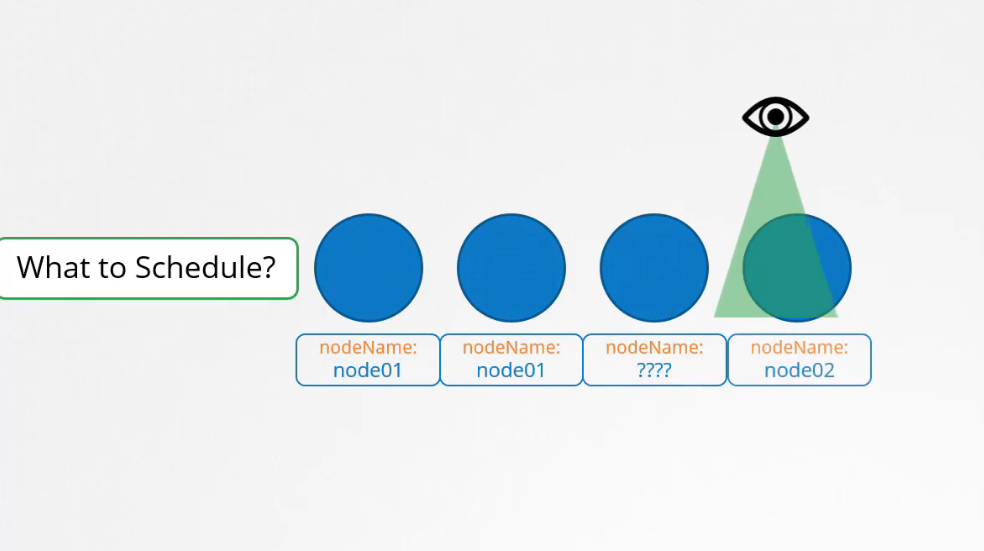
Scheduler đi qua tất cả các pod và tìm kiếm những pod không có set thuộc tính nodeName, đó là ứng viên để lên lịch. Sau đó nó xác định node bên phải cho pod bằng cách chạy thuật toán scheduling.
Sau khi xác định, nó sẽ lên lịch cho pod trên node bằng cách đặt thuộc tính nodeName:node02 bằng cách tạo một đối tượng binding. Vì vậy, nếu không có scheduler để theo dõi và lập lịch cho các node, chuyển gì sẽ xảy ra?.
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx 0/1 Pending 0 3s
Các nhóm tiếp tục ở trạng thái pending, bạn có thể tự gán pod cho node theo cách thủ công.
$ kubectl get pods
NAME READY STATUS RESTARTS AGE IP NODE
nginx 1/1 Running 0 9s 10.40.0.4 node02
Không có scheduler cách dễ nhất để lên lịch cho pod là chỉ đơn giản là đặt nodeName thành tên node mà bạn muốn pod nằm trên node đó trong tệp YAML trước khi bạn tạo pod, nhóm sau đó được gán cho node được chỉ định.
Kubernetes sẽ không có phép bạn sửa đổi thuộc tính nodeName cho pod, vậy một cách khác để gán một node cho pod hiện có là tạo một binding object và gửi yêu cầu POST với API binding của pod. Làm theo nhưng gì mà scheduler thực tế thực hiện:
apiVersion: v1
kind: Binding
metadata:
name: nginx
targe:
apiVersion: v1
kind: Node
name: node02
Trong object binding, bạn chỉ định target node với tên của node sau đó gửi yêu cầu POST tới API binding pod với tệp dữ liệu cho đối tương liên kết ở định dạng JSON.
{
"apiVersion": "v1",
"kind": "Binding",
"metadata": {
"name": "nginx"
},
"target": {
"apiVersion": "v1",
"kind": "Node",
"name": "node02"
}
}
Vì vậy bạn phải chuyển đổi file YAML sang dạng JSON tương đương của nó.
curl --header "Content-Type:application/json" --request POST --data {
"apiVersion": "v1",
"kind": "Binding",
"metadata": {
"name": "nginx"
},
"target": {
"apiVersion": "v1",
"kind": "Node",
"name": "node02"
}
}
http://$SERVER/api/v1/namespaces/default/pods/$PODNAME/binding/
Labels & Selectors
Labels & Selectors là một standard method để nhóm các thứ lại với nhau.

Giả sử bạn có một tập hợp các loài khác nhau, người dùng muốn có thể lọc chúng dựa trên các tiêu chí khác nhau.

Chẳng hạn như dựa trên loài của chúng, nếu chúng là ở dưới nước (wild) hoặc hoang dã (Domestic) hoặc bởi màu sắc của chúng và không chỉ group mà bạn còn có thể lọc chúng dựa trên một tiêu chí.
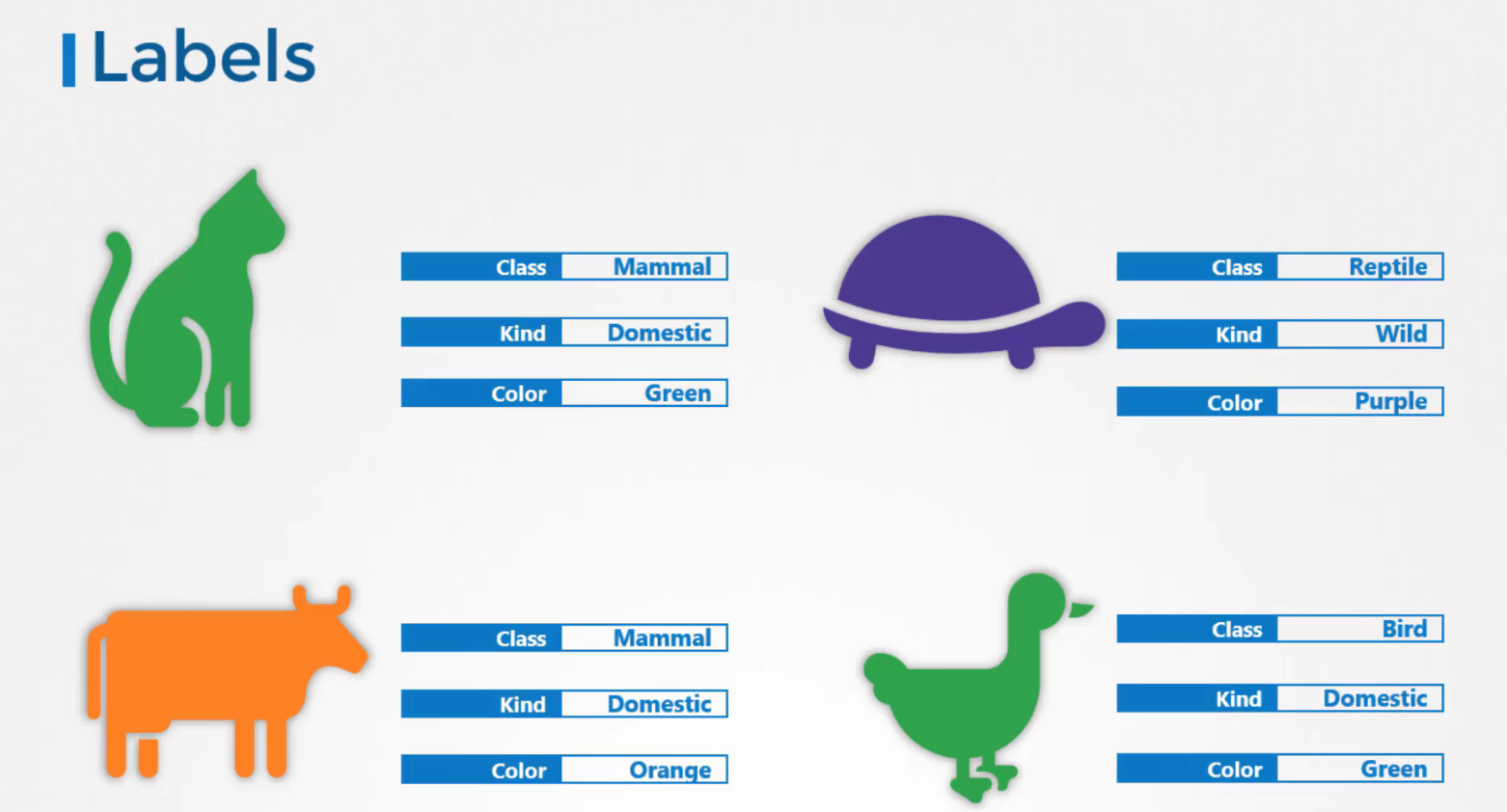
Labels là thuộc tính gắn liền với mỗi item vì vậy bạn thêm thuộc tính cho từng item về class, kind, color của chúng. Selectors giúp bạn lọc ra các mục này.

Chúng tôi tạo ra rất nhiều loại đối tượng khác nhau như pods, services, replicaset, deployments, v.v. Đối với Kubernetes tất cả là những đối tượng khác nhau, theo thời gian cuối cùng bạn có thể gặp phải hàng trăm, hàng nghìn đối tượng như này trong cluster, sau đó bạn sẽ cần một cách để lọc và xem các đối tượng khác nhau theo các danh mục khác nhau.

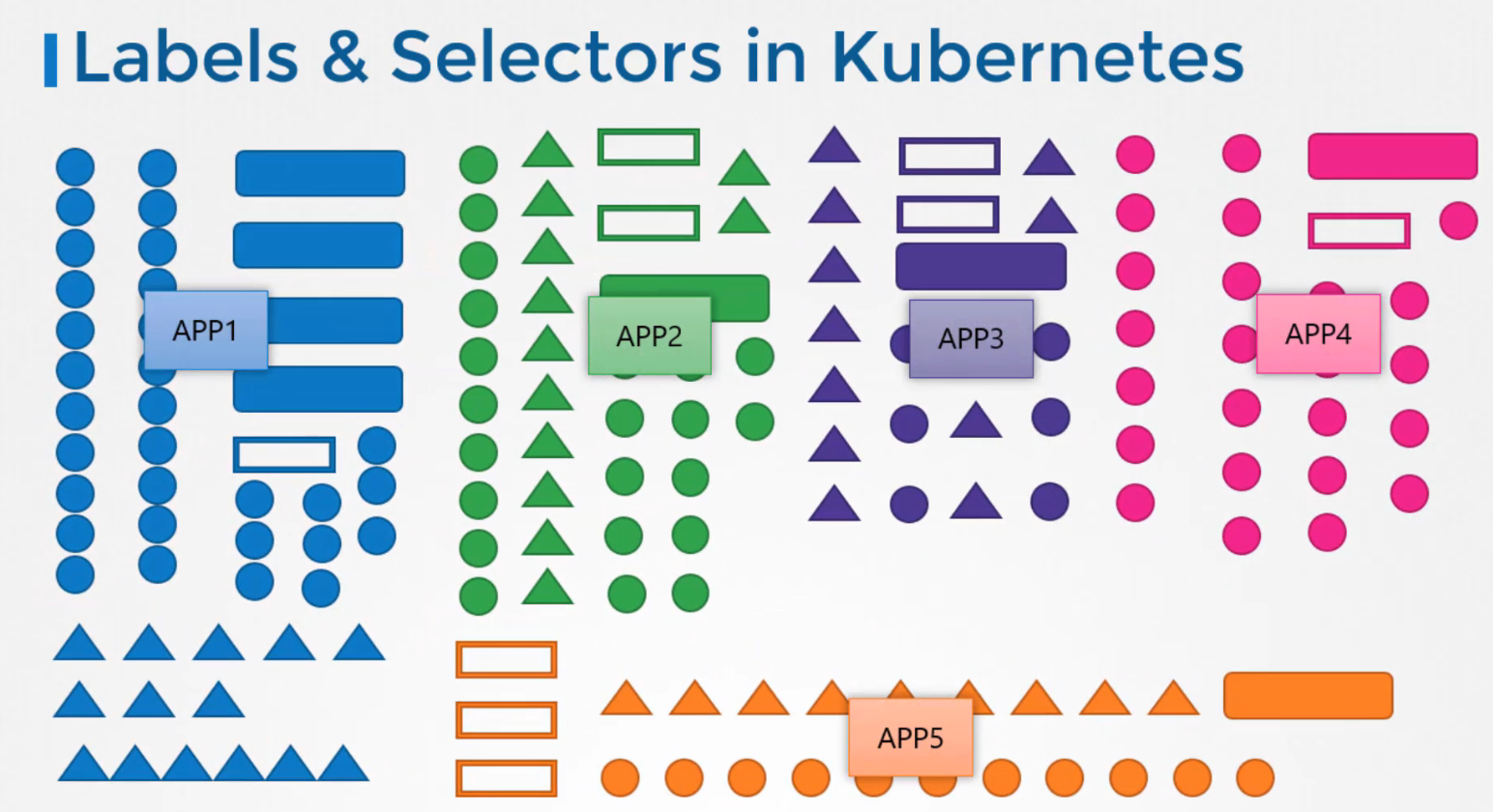
Chẳng hạn như nhóm các đối tượng theo type của chúng hoặc xem các đối tượng theo ứng dụng. Bạn có thể nhóm và chọn các đối tượng sử dụng labels & selectors.
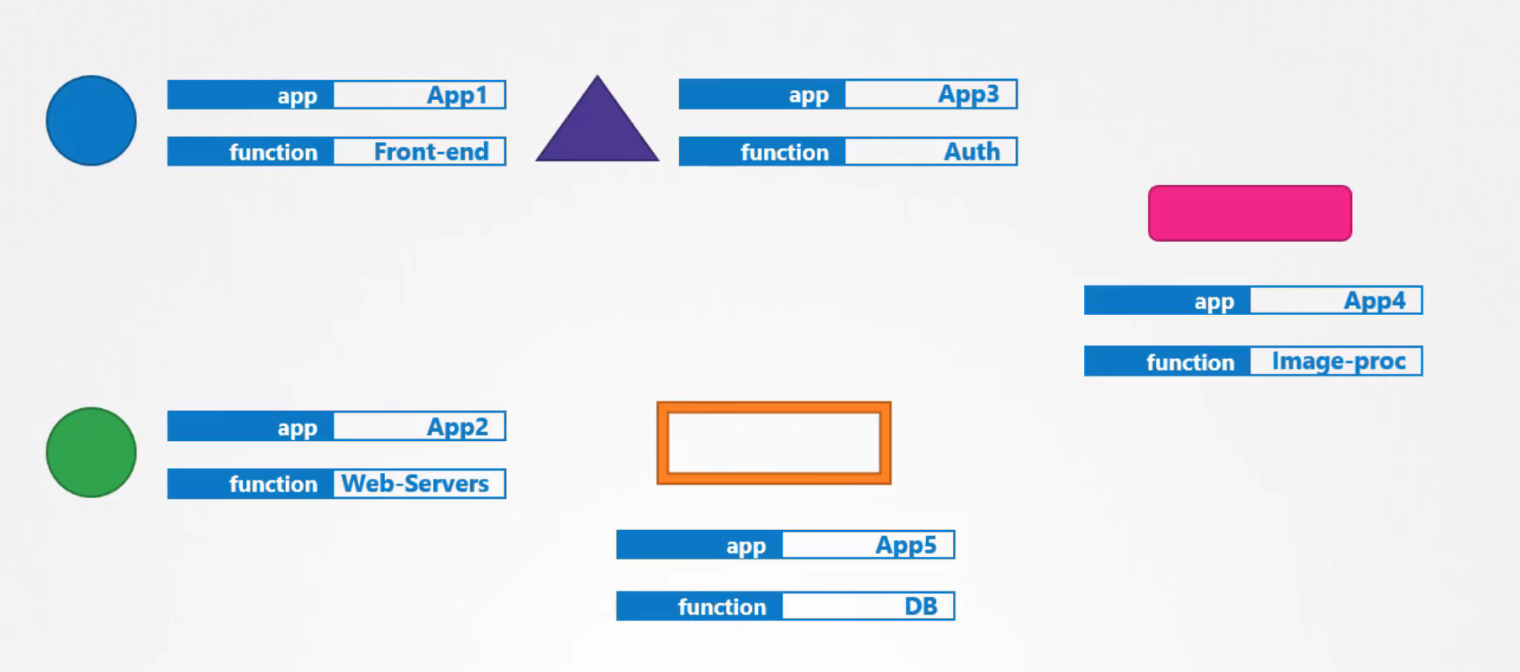
Đối với mỗi đối tượng, hãy gán labels theo nhu cầu của bạn như app, function,v.v. Sau đó trong khi chọn hãy chỉ định một điều kiện để lọc các đối tượng cụ thể.
Ví dụ: app = App1
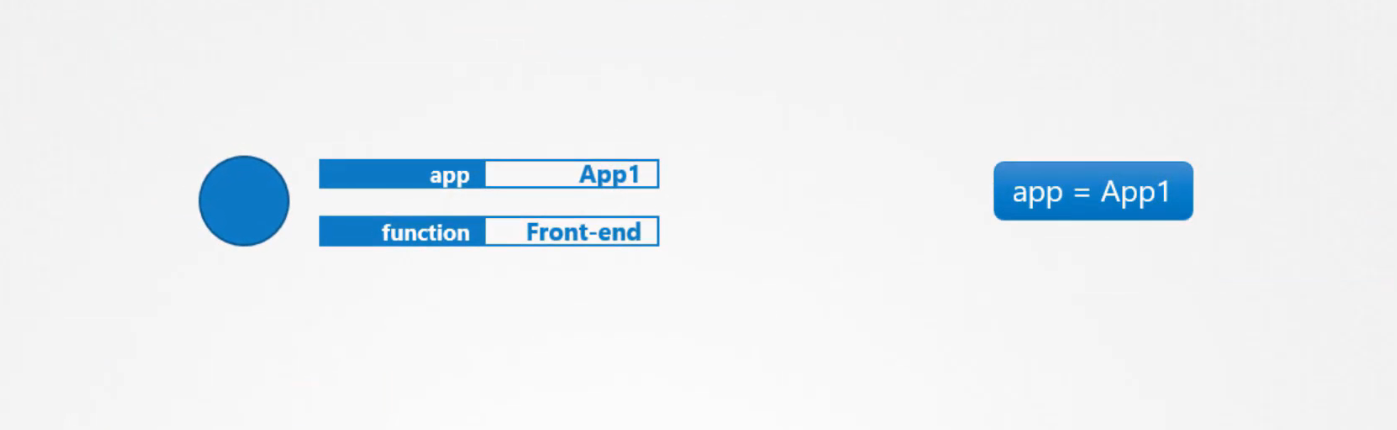
Vậy bạn chỉ định label trong Kubernetes chính như thế nào, trong tệp định nghĩa pod, trong metadata tạo một phần được gọi là labels. Theo đó hãy thêm labels ở định dạng key:value, bạn có thể thêm bao nhiêu labels tùy thích:
apiVersion: v1
kind: Pod
metadata:
name: sinple-webapp
labels:
app: App1
function: Front-end
spec:
containers:
- name: sinple-webapp
image: sinple-webapp
ports:
- containerPort: 8080
Sau khi pod được tạo, để chọn pod có labels sử dụng lệnh get pod với tùy chọn selector và chỉ định điều kiện theo yêu cầu:
$ kubectl get pods --selector app=App1
NAME READY STATUS RESTARTS AGE
simple-webapp 0/1 Completed 0 1d
Bây giờ, đây như là một trường hợp sử dụng labels & selector. Các đối tượng Kubernetes sử dụng labels & selectors trong nội bộ để kết nối các đối tượng khác nhau lại với nhau.
Ví dụ:
Để tạo một replicaset bao gồm 3 pod khác nhau, trước tiên hãy gắn labels cho pod và sử dụng selector trong một replicaset để nhóm các pod.
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: simple-webapp
labels:
app: App1
function: Front-end
spec:
replicas: 3
selector:
matchLabels:
app: App1
template:
metadata:
labels:
app: App1
function: Front-end
spec:
containers:
- name: simple-webapp
image: simple-webapp
Bạn thấy labels được xác định ở hai nơi, lưu ý đây là người dùng mới có xu hướng mắc sai lầm, các nhãn được xác định trong template là các labels được cấu hình trên pod, các labels trên cùng là các labels của replicaset.
Chúng tôi không thực sự quan tâm đến label của replicaset hiện tại bởi vì chúng tôi đang cố gắng có được bộ bản sau để khám phá các pod, các labels của replicaset sẽ được sử dụng nếu bạn định cấu hình một số đối tượng khác để khám phá replicaset.
selector:
matchLabels:
app: App1
Để kết nối replicaset với pod, chúng tôi cấu hình trường matchLabels trong selector để khớp với các label được gán cho pod. Một label duy nhất sẽ làm được nếu nó khớp chính xác, tuy nhiên nếu bạn cảm thấy có thể có những pod khác có cùng label nhưng không có cùng chức năng, bạn có thể chỉ định cả 2 label:
selector:
matchLabels:
app: App1
function: Front-end
Khi tạo, nếu các labels khớp với nhau replicaset sẽ được tạo thành công. Nó hoạt động tương tự đối với các đối tượng khác như service. Khi một service được tạo ra, nó sử dụng selector được xác định trong tệp định nghĩa service để khớp với các labels được đặt trên pod.
Taints And Tolerations
Ví dụ:

Một con bọ tiếp cận một người, để ngăn chặn con bọ đậu vào người chúng tôi xịt thuốc chống côn trùng vào người hoặc như taint.

Nó không chịu được mùi, cứ thế tiếp cận người đó sẽ khiến con bọ biến mất. Tuy nhiên sẽ có những con bọ khác chịu được mùi này, do đó taint không thực sự ảnh hưởng đến nó và cuối cùng nó đáp xuống người đó:

Vì vậy, có hai điều quyết định nếu một con bọ đậu vào người:
Đầu tiên là taint trên người
Thứ hai là tolerant (mức độ chịu đựng được) đến taint đó.
Quay trở lại Kubernetes, con người là một node và bọ là các pod. Giờ đây tains & tolenrations chẳng liên quan gì bảo mật hoặc xâm nhập vào cluster, nó được sử dụng để đặt ra những hạn chế về những pod có thể được lên lịch trên một node.
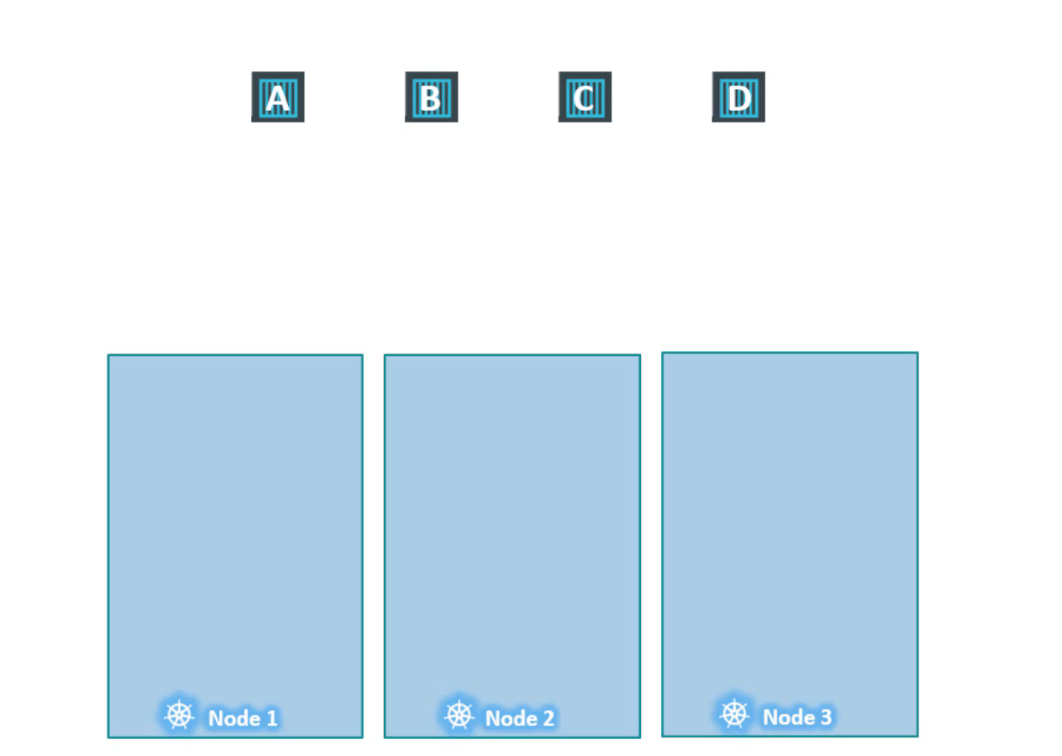
Các node được đặt trên node1, node2, node3 và cũng có các pod sẽ được triển khai trên các node này hãy gọi chúng là A, B, C, D. Khi pod được tạo ra, scheduler sẽ cố gắng đặt các pod này trên các worker node có sẵn.
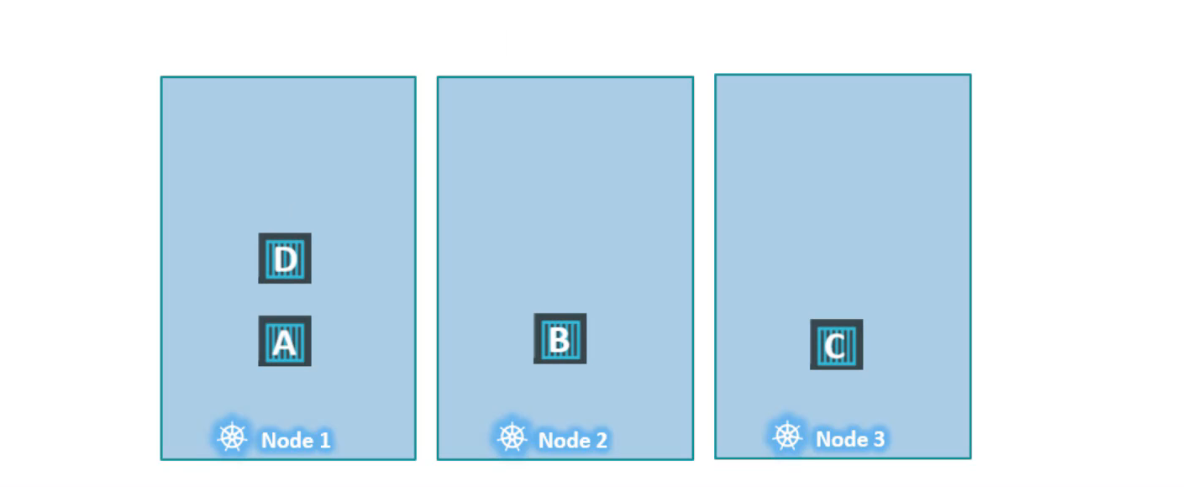
Tính đến thời điểm hiện tại, không có hạn chế hoặc giới hạn nào và như vậy scheduler sẽ đặt các pod trên tất cả các node để cân bằng tải.
Bây giờ giả sử rằng chúng ta đã có các tài nguyên dành riêng trên node1 cho một trường hợp sử dụng hoặc ứng dụng cụ thể. Vì vậy, chúng tôi chỉ muốn những pod thuộc về ứng dụng này được đặt trên node1.
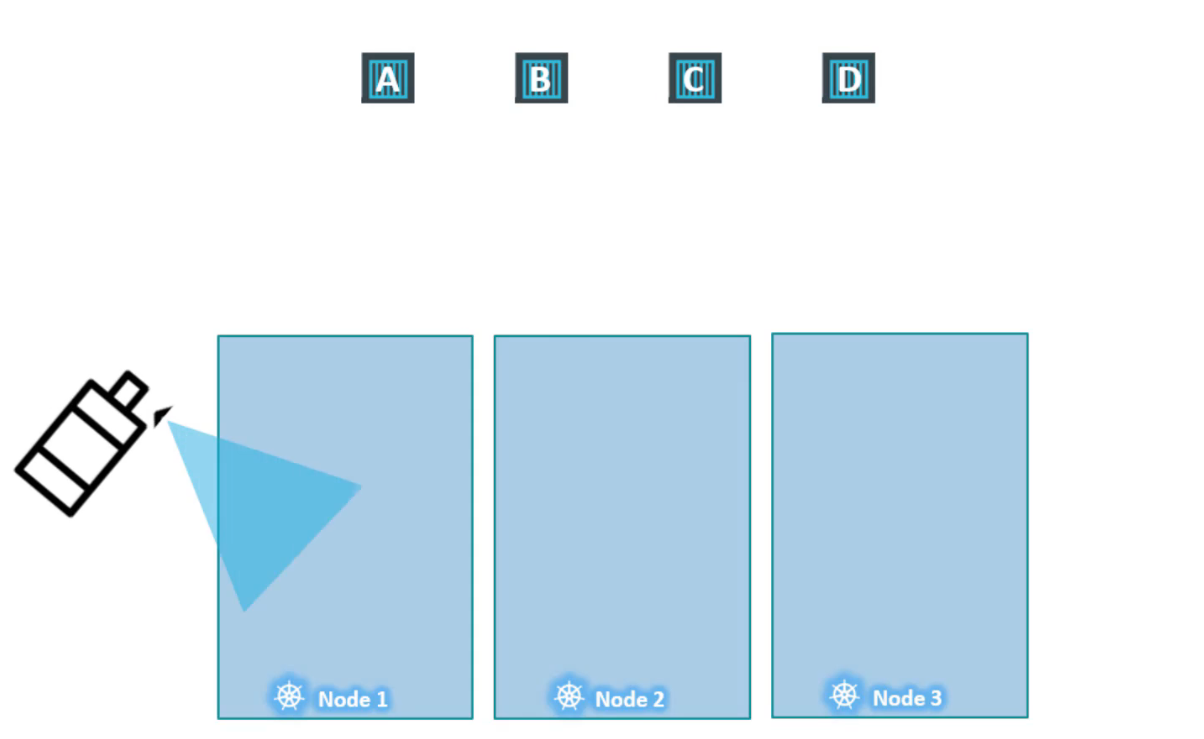
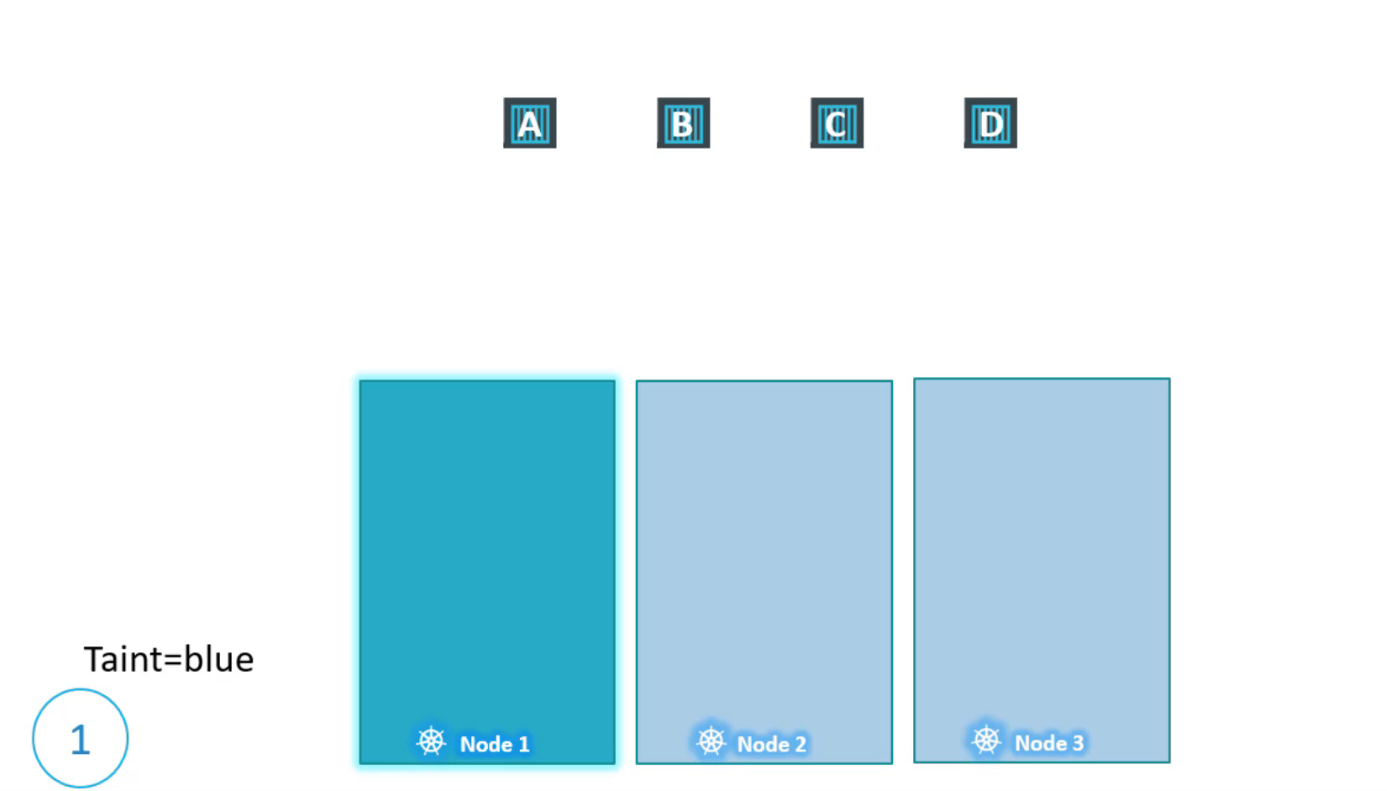
Đầu tiên, chúng tôi ngăn chặn việc đặt tất cả các pod trên node bằng các đặt taint lên node hãy gọi nó Taint=blue. Theo mặc định, pod không có tolerations có nghĩa là trừ khi có quy định khác thì không có pod nào có thể chịu được bất kỳ taint nào.
Trong trường hợp này, không có pod nào có thể được đặt trên node1 vì không có pod nào chịu đựng được Taint=blue. Sẽ không có pod không mong muốn nào được đặt trên node này, nửa còn lại là kích hoạt một số pod nhất định được đặt trên node này.
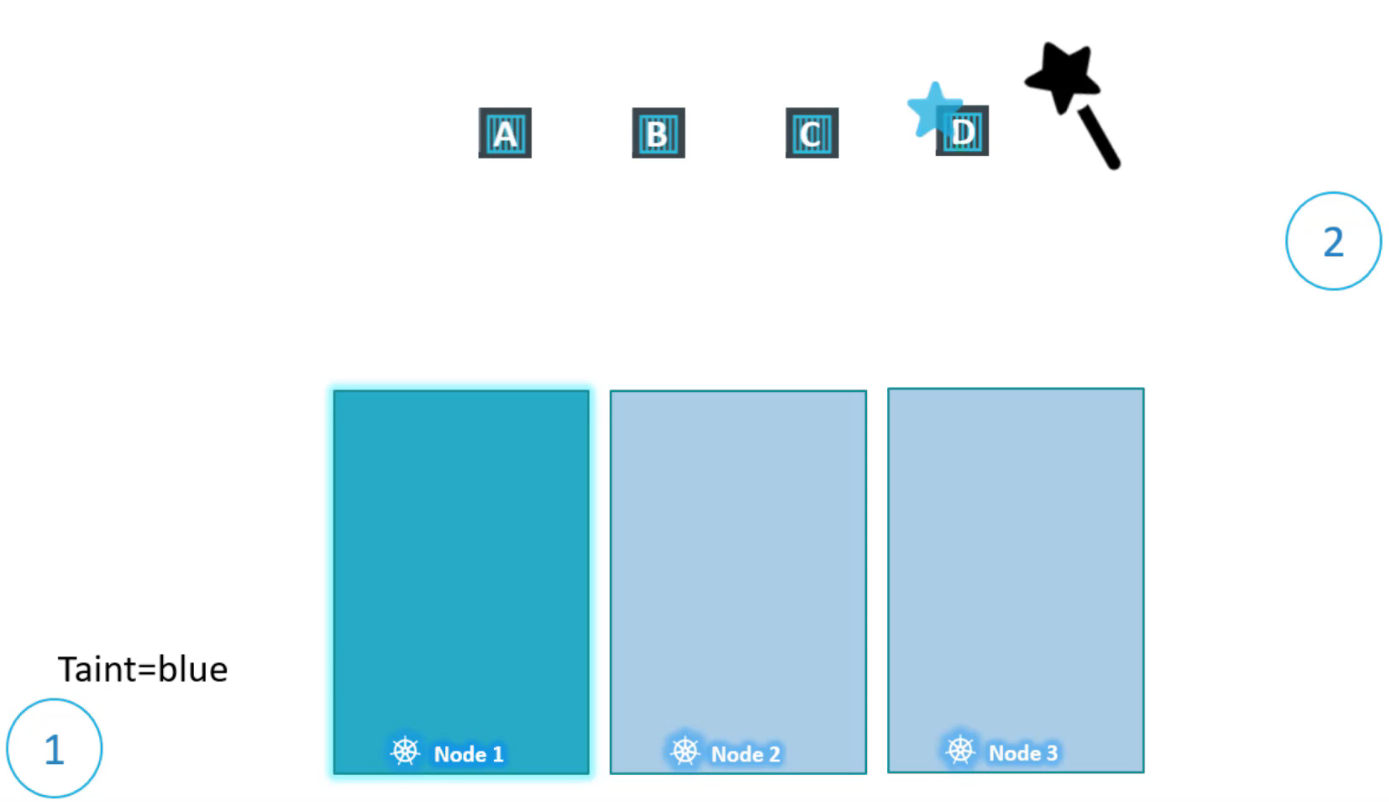
Để làm được điều này, chúng ta phải chỉ định những pod nào có tolerant đến taint đặc biệt này. Chúng tôi chỉ muốn cho phép pod D được đặt trên node này, vì vậy chúng tôi thêm toleration vào pod D. Pod D bây giờ có khả năng chịu đựng được taint=blue.
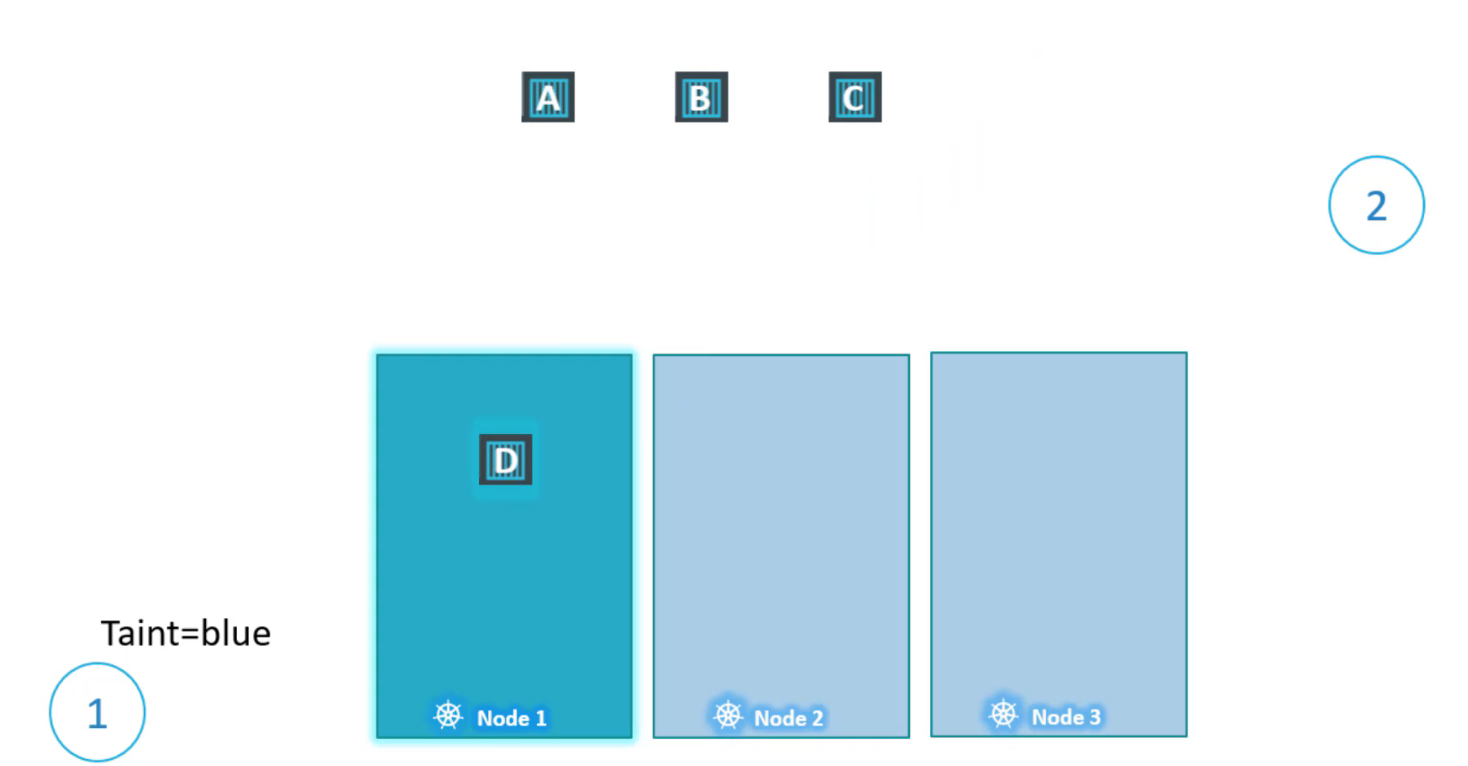
Vì vậy, khi scheduler cố gắng đặt pod này lên node1, nó sẽ đi qua. Node1 bây giờ chỉ có thể chấp nhận pods có thể chịu đựng được (tolerate) taint=blue. Vì vậy những taints & tolerations đã được thiết lập, đây là cách các pod sẽ được lên lịch.
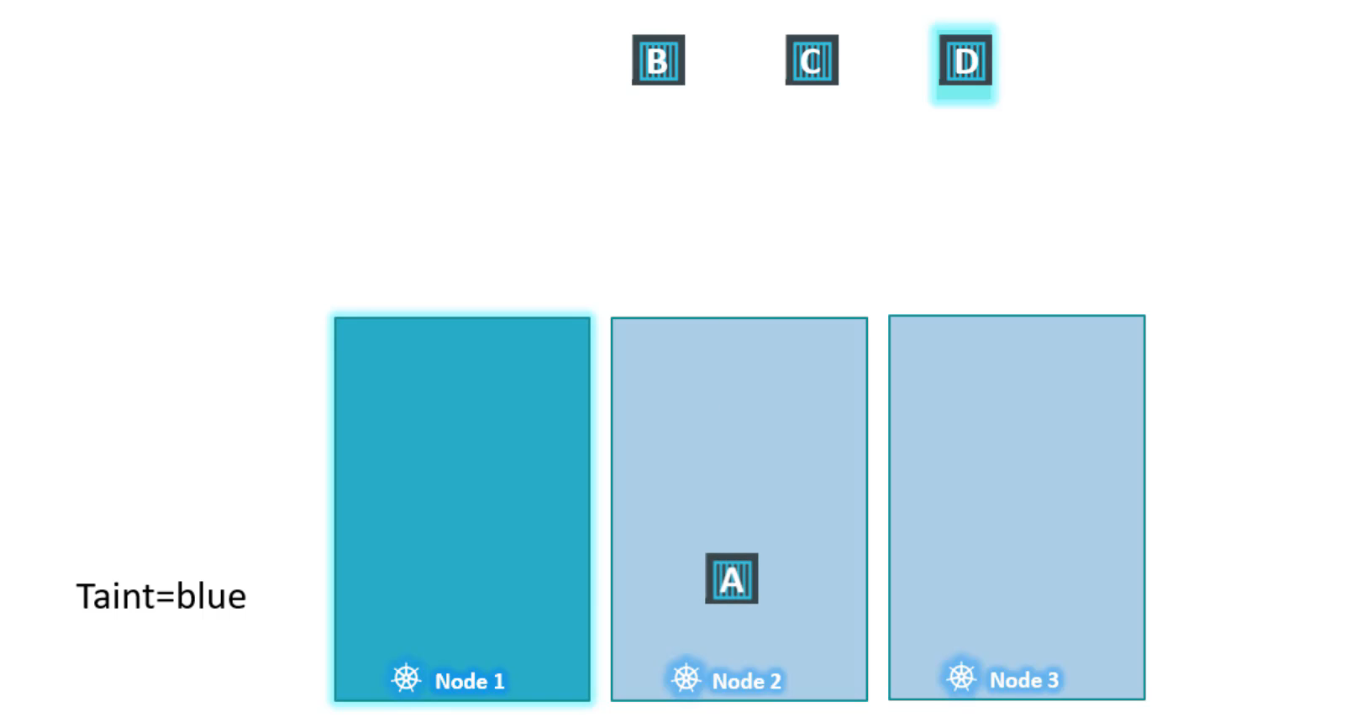
Scheduler cố gắng đặt pod A trên node1 nhưng do có taint nên nó bỏ qua và nó đi đến node2.
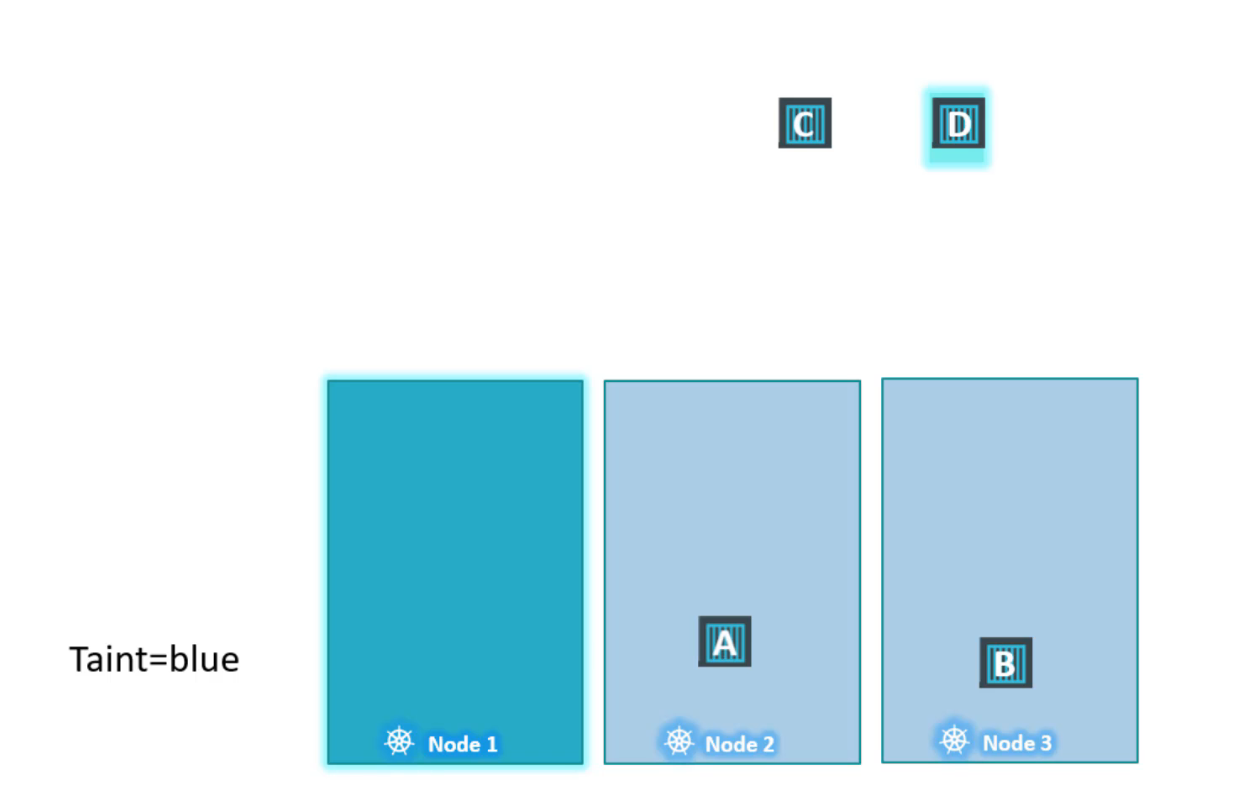
Scheduler sau đó cố gắng đưa pod B trên node1 nhưng một lần nữa do taint nó bị loại bỏ và được đặt ở node3.
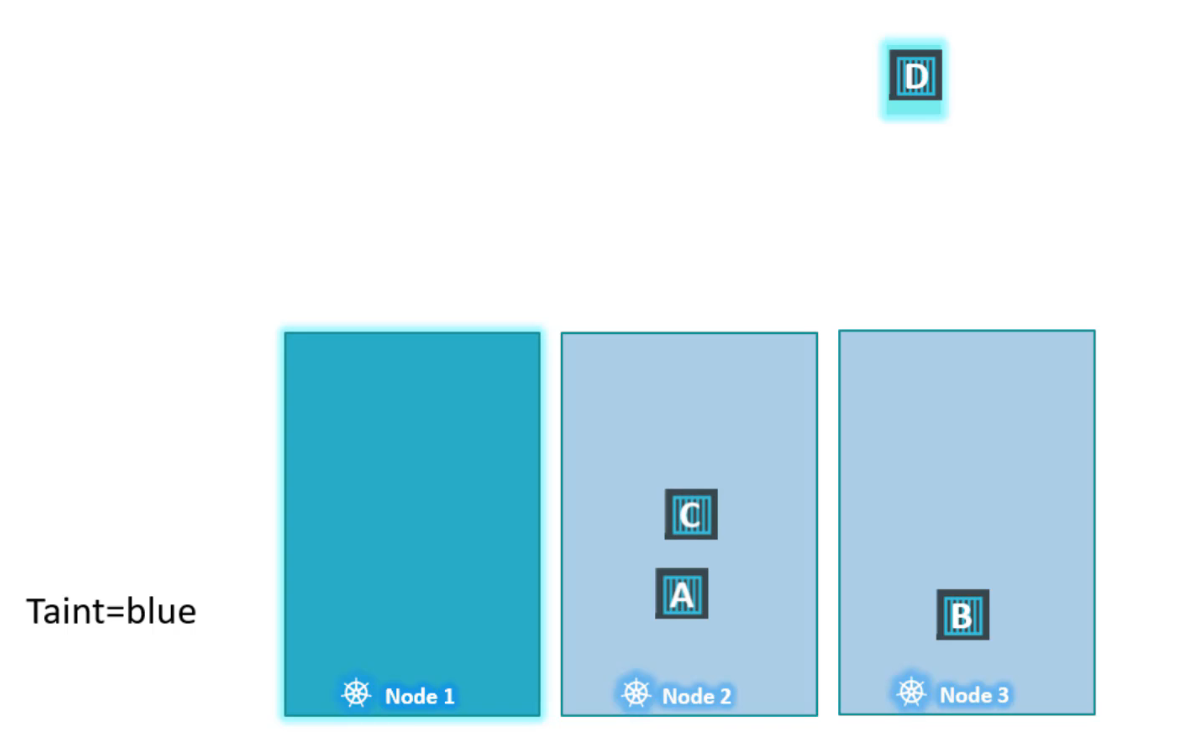
Scheduler sau đó cố gắng đưa pod C trên node1 nhưng một lần nữa do taint nó bị loại bỏ và được đặt ở node2.
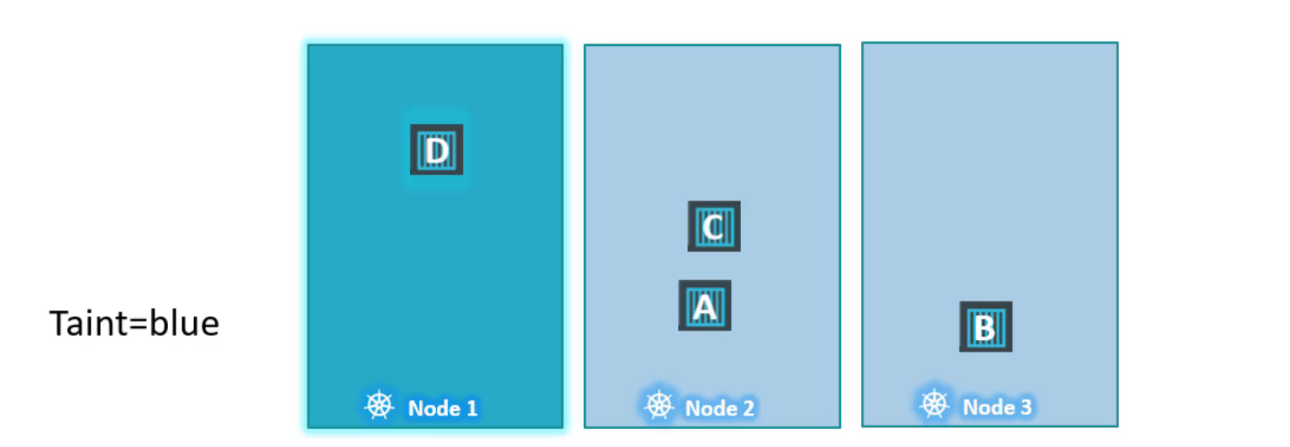
Và cuối cùng, scheduler cố gắng đưa pod D trên node1 vì pod có khả năng chịu được (tolerant) trên node1 nên nó sẽ vượt qua.
Sử dụng lệnh kubectl để làm taint cho một node:
kubectl taint nodes node-name key=value:taint-effect
Ví dụ: Bạn muốn dành riêng node này cho các pod trong ứng dụng blue thì cặp giá trị khóa sẽ là app=blue.
Taint-effect xác định điều gì sẽ xảy ra với các pod nếu chúng không chấp nhận taint đó. Có 3 loại taint-effect:
NoSchedule: có nghĩa là các pod sẽ không được lên lịch trên node.
PreferNoSchedule: có nghĩa là hệ thống sẽ cố gắng tránh đặt một pod trên node nhưng điều đó không được đảm bảo.
NoExecute: có nghĩa là các pod mới sẽ không được scheduled lên node. Các pod hiện có trên node sẽ bị loại bỏ nếu không chịu đựng được taint, những pod này có thể đã được lên lịch trên node trước khi taint được áp dụng cho node.
Ví dụ: Một lệnh sẽ làm hỏng node1 với cặp khóa key value app=blue:NoSchedule
kubectl taint nodes node1 app=blue:NoSchedule
Để thêm toleration cho 1 pod, trong phần spec của định nghĩa pod hãy thêm 1 section có tên là tolerations. Di chuyển các giá trị tương tự được sử dụng khi tạo taint.
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
spec:
containers:
- name: nginx-container
image: nginx
tolerations:
- key: "app"
operator: "Equal"
value: "blue"
effect: "NoSchedule"
Tất cả những giá trị này cần được mã hóa bằng double codes, khi pod được tạo hoặc cập nhật với những tolerations, chúng không được lên lịch trên các node hoặc bị loại bỏ khỏi các node hiện có tùy thuộc vào effect.
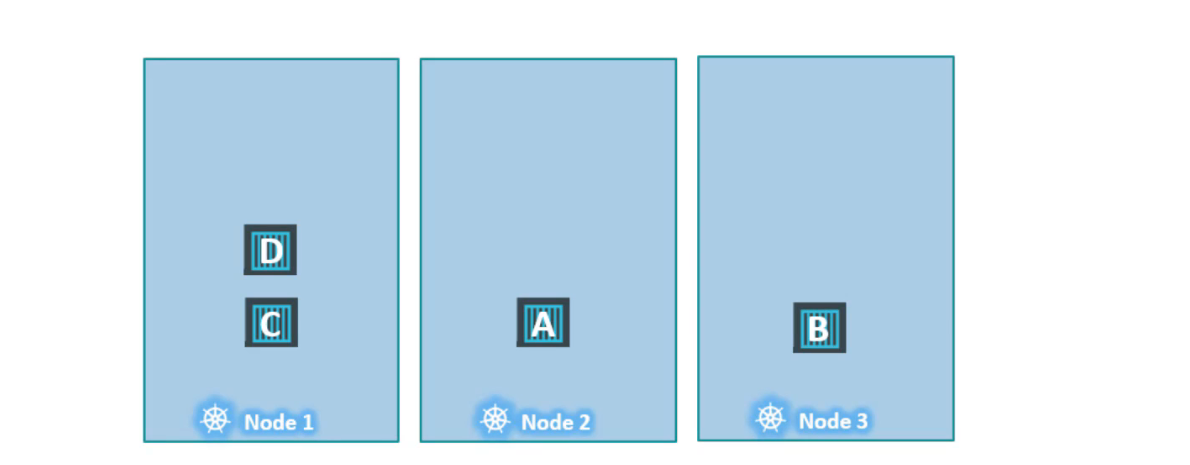
Trong ví dụ này, chúng tôi có 3 node đang chạy một số pod,không có bất kỳ taint hay toleration nào tại thời điểm này.
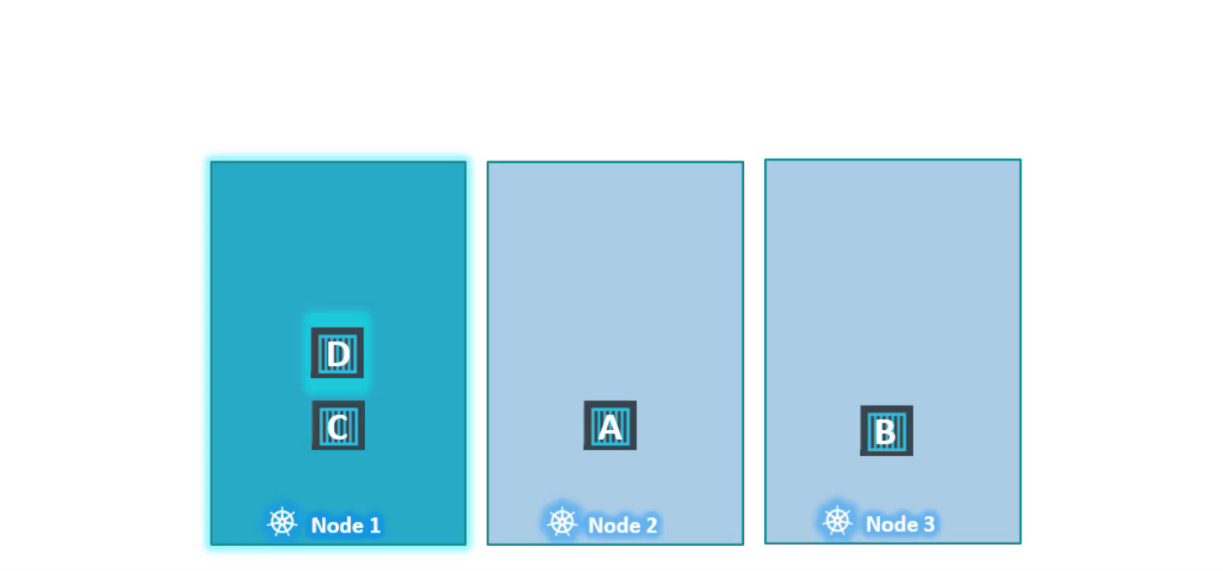
Sau đó chúng tôi quyết dịnh dành node1 cho một ứng dụng đặc biệt và như vậy chúng tôi thêm taint cho node bằng tên ứng dụng và thêm tolerations cho pod thuộc về ứng dụng điều này xảy ra với pod D trong trường hợp này.
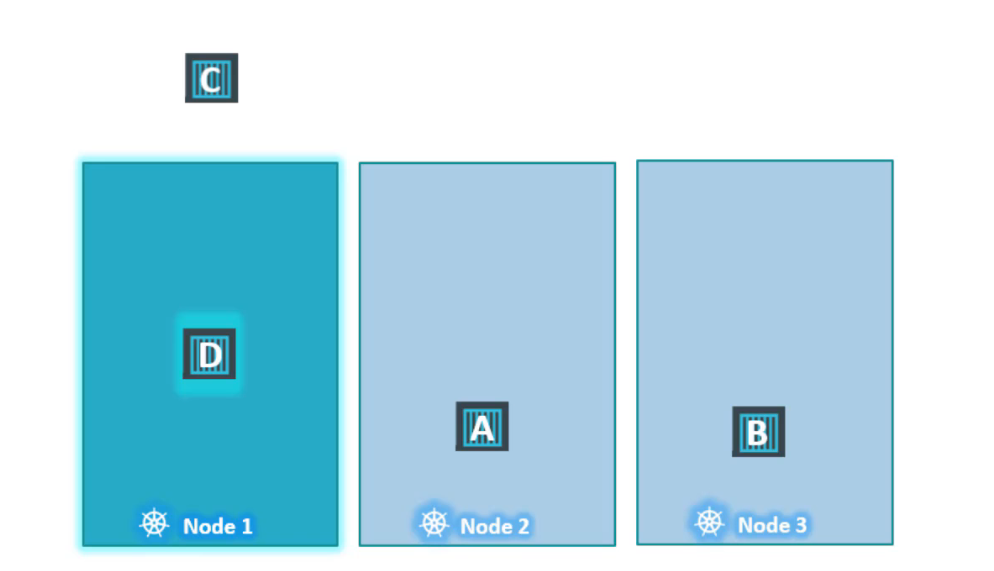
Trong khi gán taint cho node, chúng tôi đặt effect=NoExecute, như vậy một khi taint trên node có hiệu lực thì nó sẽ trục xuất pod C khỏi node, điều đó có nghĩa là pod bị killed. Pod D tiếp tục chạy trên node vì nó có khả năng chịu được taint.
Hãy nhớ rằng taints & tolerations chỉ có ý nghĩa để hạn chế các node chấp nhận một số pod nhất định.
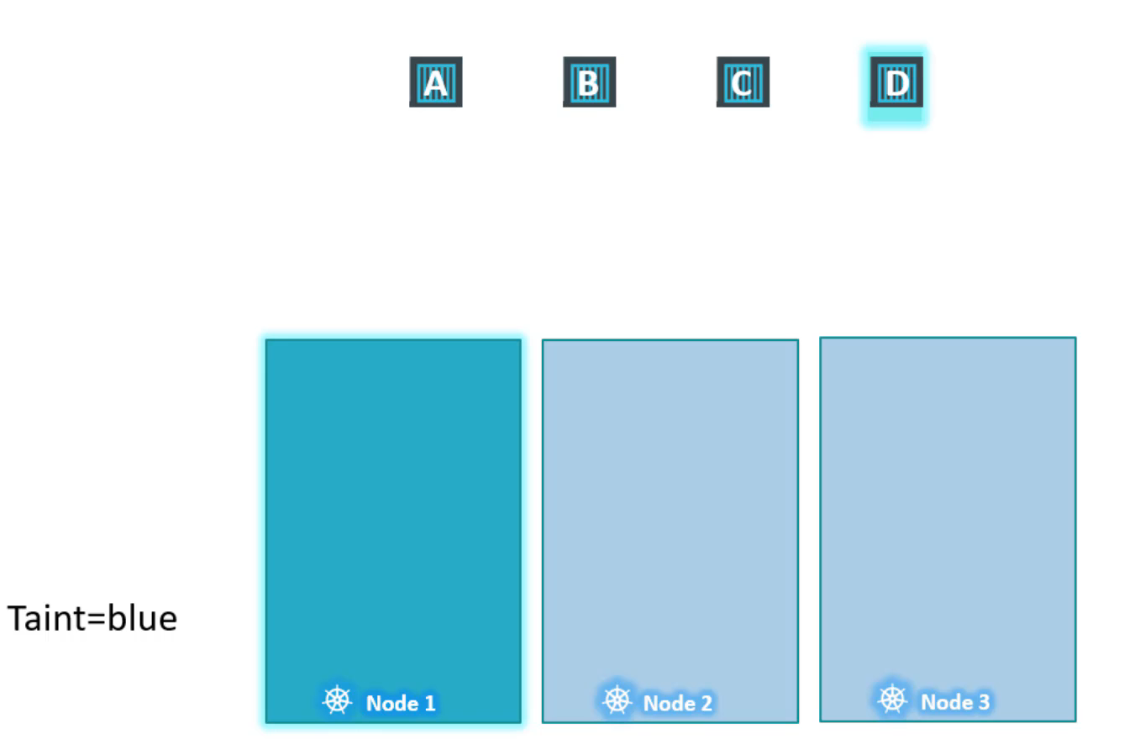
Trong trường hợp này, node1 chỉ có thể chấp nhận pod D nhưng nó không đảm bảo pod D sẽ luôn được đặt trên node1. Vì không có taints nào được áp dụng trên hai node còn lại, pod D có thể được đặt trên bất kỳ 1 trong 2 node còn lại. Hãy nhớ rằng Taints & Tolerations không yêu cầu pod đi đến 1 node cụ thể.
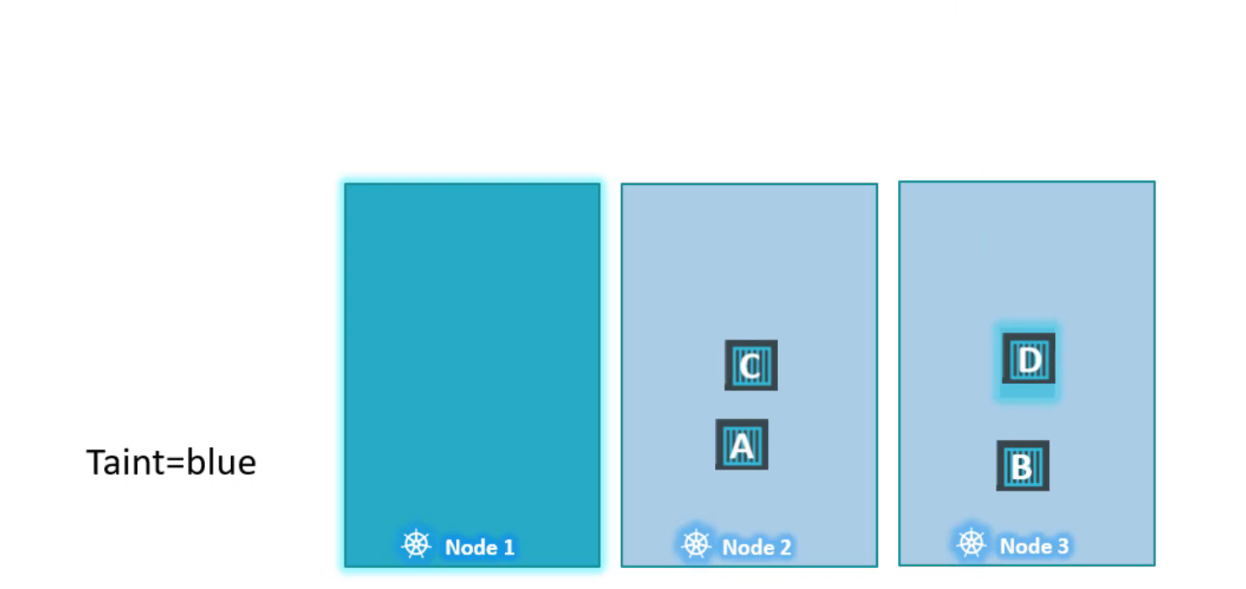
Thay vào đó, nó báo cho node chỉ chấp nhận những pod có tolerations nhất định, nếu yêu cầu của bạn là hạn chế 1 pod ở một số node nhất định, node đạt được thông qua một khái niệm khác gọi là node affinity.
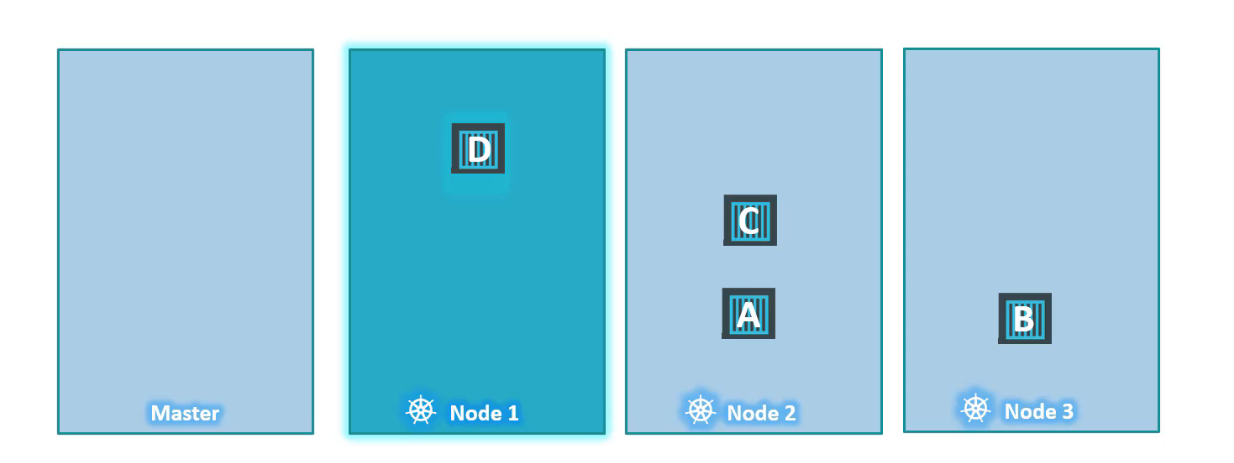
Cho đến nay, chúng ta chỉ đề cập đến các worker nodes nhưng chúng tôi cũng có các master nodes trong cluster. Về mặt kỹ thuật chỉ là một node khác, có tất cả khả năng như woker nodes.
Scheduler không lập lịch cho cho bất kỳ pod nào trên master node. Khi cụm Kubernetes được thiết lập lần đầu tiên, một taint được thiết lập tự động cho master node, ngăn không có bất kỳ pod nào được lên lịch trên node này. Bạn có thể sửa đổi nếu được yêu cầu. Tuy nhiên, cách tốt nhất là không triển khai ứng dụng lên master node.
Để xem taint trên node, hãy chạy lệnh kubectl:
$ kubectl describe node kubemaster | grep Taint
Taints: node-role.kubernetes.io/master:NoSchedule
Node Selectors
Giả sử bạn có một cụm gồm ba node, trong đó có hai node nhỏ hơn với tài nguyên phần cứng thấp hơn, và một node lớn hơn được cấu hình với tài nguyên cao hơn. Bạn có nhiều loại workload khác nhau đang chạy trong cụm của mình. Bạn muốn dành riêng các workload xử lý dữ liệu, yêu cầu tài nguyên cao, cho node lớn hơn, vì đó là node duy nhất không hết tài nguyên trong trường hợp công việc yêu cầu thêm tài nguyên.
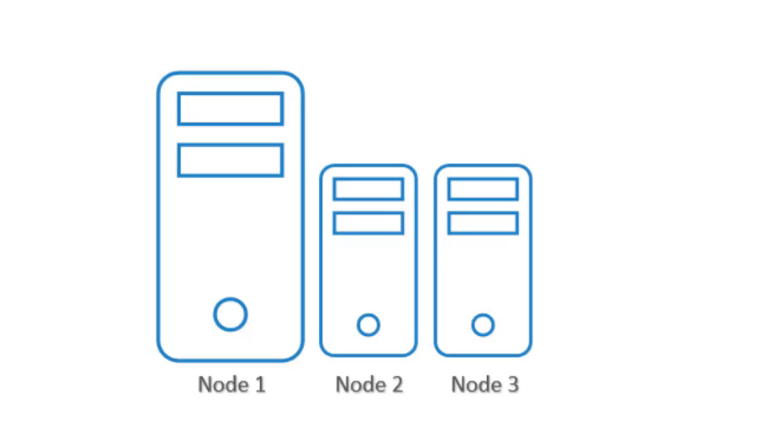
Tuy nhiên, trong cấu hình mặc định hiện tại, bất kỳ pod nào cũng có thể được đặt trên bất kỳ node nào. Vì vậy, pod C trong trường hợp này có thể rất dễ dàng kết thúc trên node hai hoặc ba, điều này là không mong muốn.
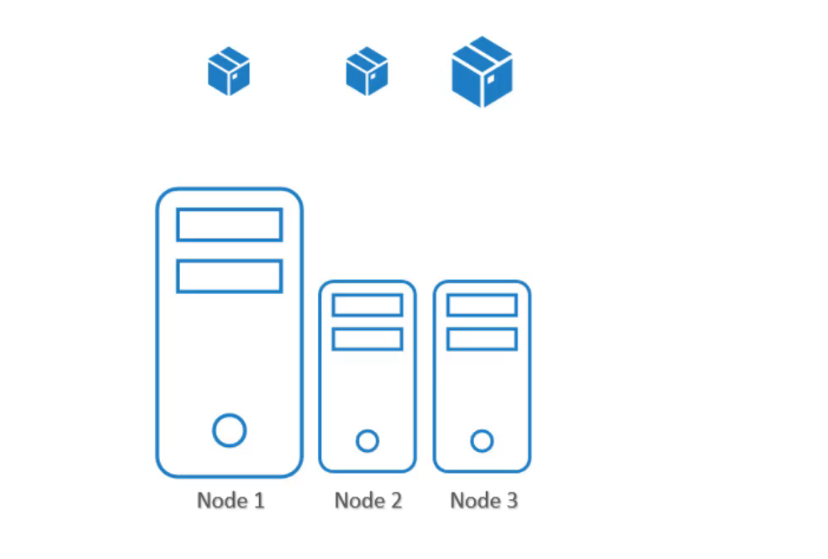
Để giải quyết vấn đề này, chúng ta có thể đặt một giới hạn cho các pod để chúng chỉ chạy trên các node cụ thể. Có hai cách để làm điều này:
Cách đầu tiên là sử dụng node selectors, một phương pháp đơn giản và dễ thực hiện. Để làm điều này, chúng ta xem xét tệp định nghĩa pod mà chúng ta đã tạo trước đó. Tệp này có định nghĩa đơn giản để tạo một pod với một hình ảnh xử lý dữ liệu.
apiVersion: 1
kind: Pod
metadata:
name: myapp-pod
spec:
containers:
- name: data-processor
image: data-processor
nodeSelector:
size: Large
Để giới hạn pod này chạy trên node lớn hơn, chúng ta thêm một thuộc tính mới gọi là node selector vào phần spec và chỉ định kích thước là Large.
Nhưng khoan đã, kích thước Largeđến từ đâu và làm thế nào Kubernetes biết node nào là node lớn?
kubectl label nodes node1 size=Large
Cặp key-value của kích thước và Largethực chất là các labels được gán cho các node. Bộ lập lịch (scheduler) sử dụng các label này để khớp và xác định node phù hợp để đặt các pod.
Node selectors đã phục vụ mục đích của chúng ta, nhưng nó có những hạn chế. Chúng ta đã sử dụng một label và selector đơn để đạt được mục tiêu ở đây. Nhưng nếu yêu cầu của chúng ta phức tạp hơn? Ví dụ, chúng ta muốn nói điều gì đó như "Large or Medium" hoặc "not Small".Bạn không thể đạt được điều này bằng cách sử dụng node selectors.
Để giải quyết những yêu cầu phức tạp hơn, chúng ta sẽ cần sử dụng các tính năng node affinity và anti-affinity. Các tính năng này cho phép bạn thiết lập các quy tắc phức tạp hơn cho việc phân phối pod lên các node trong cụm Kubernetes.
Node Affinity
Tính năng chính của node affinity là đảm bảo rằng các pod được đặt trên các node cụ thể.
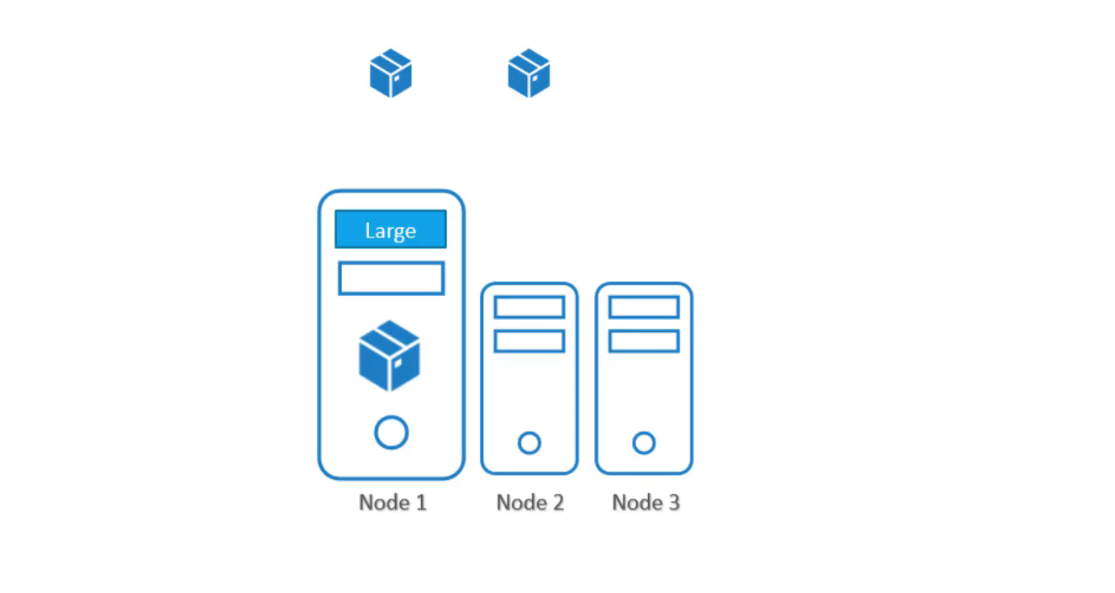
Trong trường hợp này để đảm bảo pod data processing được đặt ở trên node1. Trong phần trước, chúng ta đã thực hiện điều này một cách dễ dàng bằng cách sử dụng node selectors. Chúng ta đã thảo luận rằng node selectors không cho phép sử dụng các biểu thức phức tạp như “hoặc” (or) hay “không” (not). Node affinity cung cấp khả năng nâng cao để giới hạn vị trí của pod trên các node cụ thể.
apiVersion: 1
kind: Pod
metadata:
name: data-processing
spec:
containers:
- name: data-processing
image: data-processing
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoreDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: size
operator: In
values:
- Large
Với sức mạnh lớn thì cũng đi kèm sự phức tạp cao, nên cấu hình node selector đơn giản giờ đây sẽ trông phức tạp hơn khi dùng node affinity, mặc dù cả hai đều có cùng chức năng là đặt pod trên node lớn.
Dưới thuộc tính spec, bạn có affinity, và sau đó là node affinity. Ở đây có một thuộc tính dạng câu gọi là requiredDuringSchedulingIgnoreDuringExecution. Sau đó, bạn có nodeSelectorTerms, nơi bạn chỉ định cặp key và value. Cặp key-value có dạng key, operator, value, với operator là in. Operator in đảm bảo rằng pod sẽ được đặt trên một node có nhãn size với bất kỳ giá trị nào trong danh sách giá trị được chỉ định. Trong trường hợp này, chỉ có một giá trị là Large.
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoreDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: size
operator: In
values:
- Large
- Medium
Nếu bạn muốn pod có thể đặt trên node Large hoặc Medium, bạn chỉ cần thêm giá trị vào danh sách giá trị.
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoreDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: size
operator: NotIn
values:
- Small
Bạn có thể dùng operator NotIn để loại trừ các node có size = Small.
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoreDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: size
operator: Exists
Operator Exists đơn giản kiểm tra sự tồn tại của nhãn trên node mà không so sánh giá trị.
Khi các pod mới được tạo ra, những rules này sẽ được xem xét và đặt lên các node phù hợp.
Trong trường hợp này, nếu không node nào phù hợp với label là size. Giả sử, đã có label và pod đã được lên lịch.
Hiện có hai loại node affinity:
requiredDuringSchedulingIgnoredDuringExecution
preferredDuringSchedulingIgnoredDuringExecution.
Tùy chọn requiredDuringScheduling bắt buộc pod phải được đặt trên một node có các quy tắc affinity nhất định, và nếu không tìm thấy node phù hợp, pod sẽ không được lên lịch. Trong khi đó, preferred sẽ cố gắng đặt pod lên node phù hợp nhưng sẽ đặt pod trên bất kỳ node nào có sẵn nếu không có node phù hợp.
Có hai trạng thái trong vòng đời của một pod khi xem xét node affinity:
| DuringScheduling | DuringExecution | |
| Type 1 | Required | Ignore |
| Type 2 | Preferred | Ignore |
DuringScheduling là trạng thái không tồn tại trong pod và được tạo ra đầu tiên.
Với requiredDuringScheduling pod sẽ không được lên lịch, nếu không node nào phù hợp pod sẽ không được lên lịch.
Với preferredDuringScheduling pod sẽ được lên lịch, nếu không tìm được node nào phù hợp, scheduler sẽ bỏ qua các rules node affinity và đặt pod trên một node bất kỳ.
DuringExecution là trạng thái mà một pod đã chạy và có sự thay đổi trên các node ảnh hưởng đến các rules trong node affinity.
Với ignoreDuringExecution thì các pod sẽ tiếp tục chạy, bỏ qua bất kỳ sự thay đổi nào trên node đó.
Node Affinity vs Taints and Tolerations
Chúng ta có 3 node và 3 pod với ba mùa blue,green,red.
Mục đích cuối cùng là đặt pod blue vào node blue tương tự với green, red. Ở đây sẽ có thêm các pod và node khác.
Chúng ta không muốn bất kỳ pod other nào được đặt trên node green, blue, red và không muốn các pod green, blue, red đặt trên các node other.
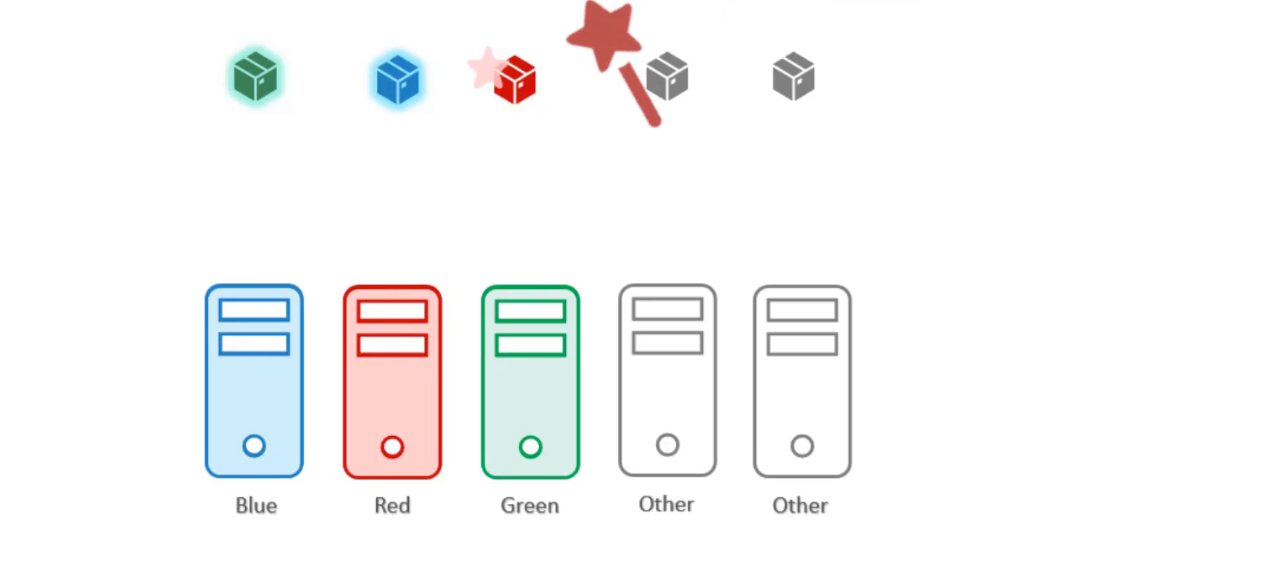
Trước tiên, hãy giải quyết vấn đề này bằng taints & tolerations. Chúng ta áp dụng một taint cho các node đánh dấu bằng color:blue, color:red, color:green:
Sau đó thêm tolerations cho các pods để tolerate(chịu đựng) được các màu sắc tương ứng:
Khi các pod được tạo, các node đảm bảo chỉ chấp nhận cho các pod với đúng toleration.
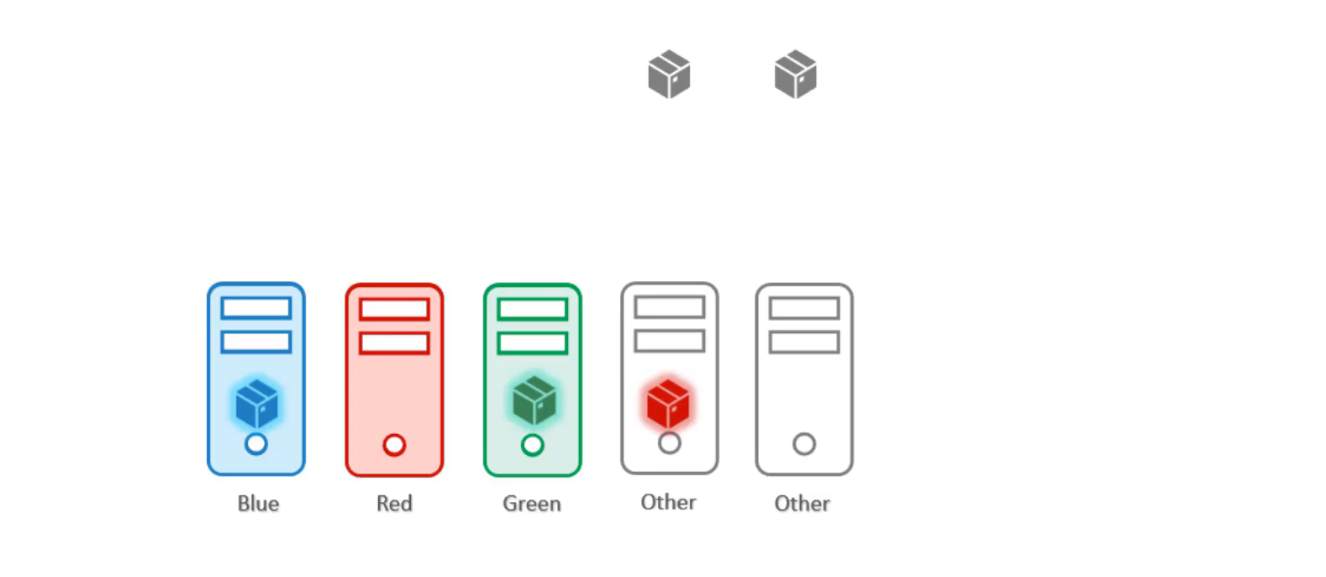
Vì vậy pod green được đặt ở node green, pod blue được đặt ở node blue. Tuy nhiên Taint & tolerations không đảm bảo các pod sẽ đi đúng node này vì vậy pod red có thể được đặt ở node other không có taint nào được thêm. Đây là điều chúng ta không mong muốn.
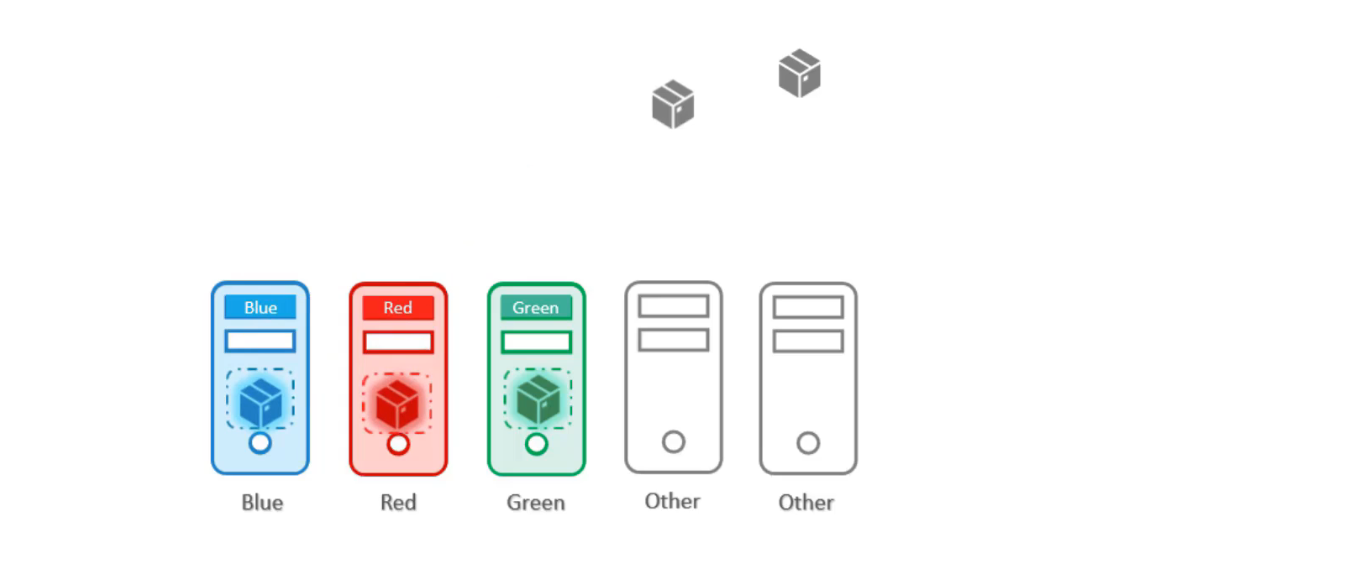
Bây giờ thử giải quyết vấn đề với node affnity, trước tiên gắn các label cho các node với các màu sắc tương ứng.
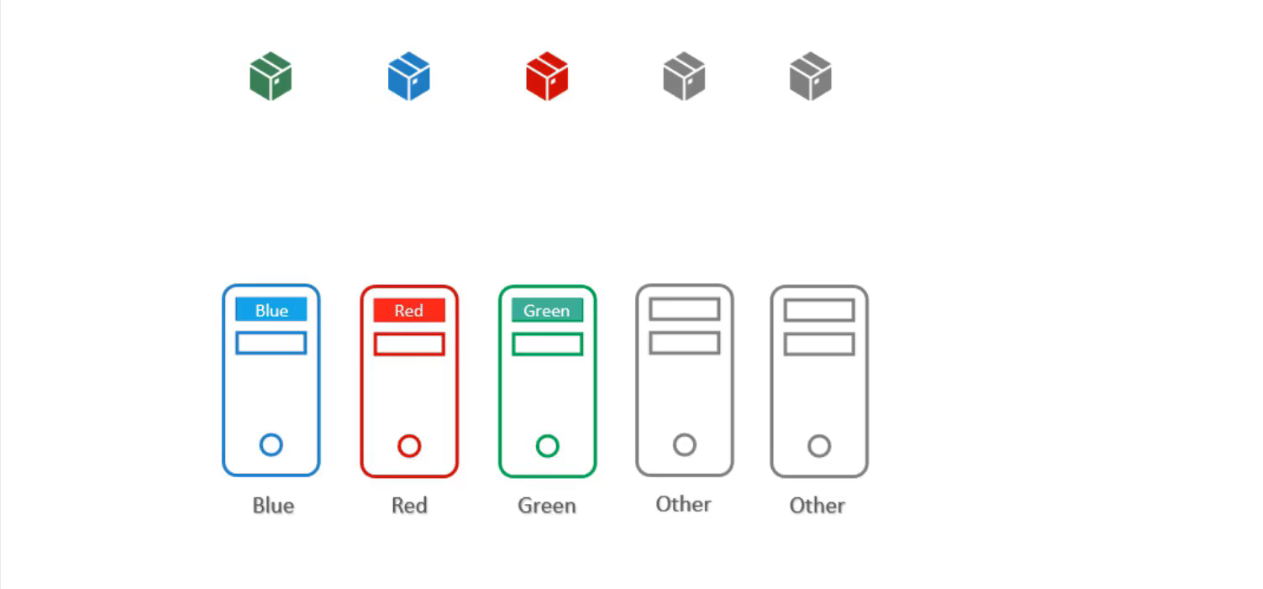
Sau đó đặt node selector trên các pod, để buộc các pod vào đúng node.
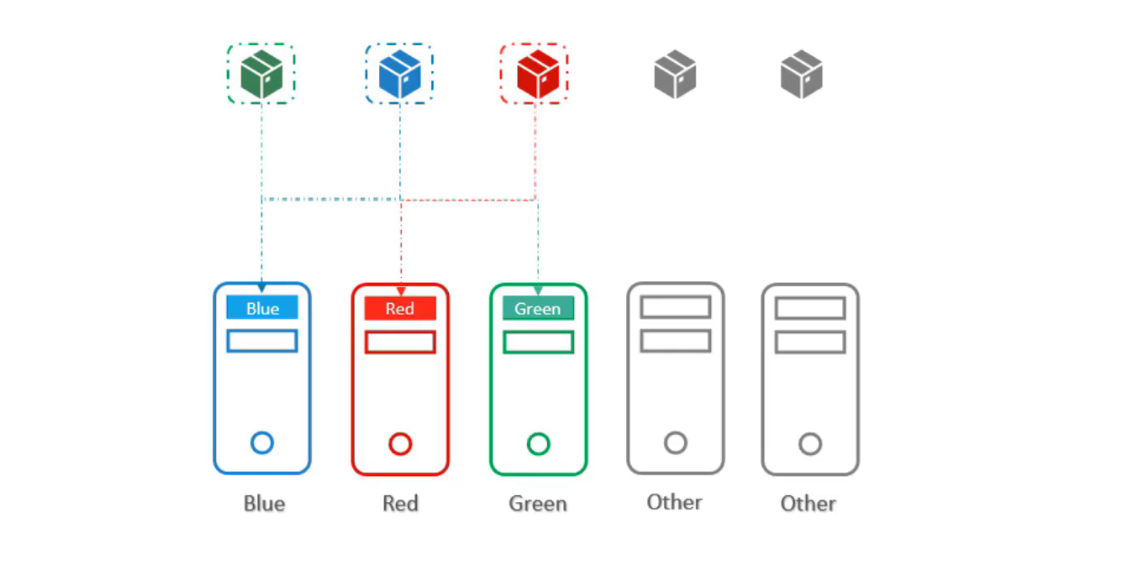
Như vậy, các pod đã được đặt đúng vào node như yêu cầu. Tuy nhiên điều đó không đảm bảo được rằng các pod other không được đặt trên các node này, đây là điều không mong muốn.
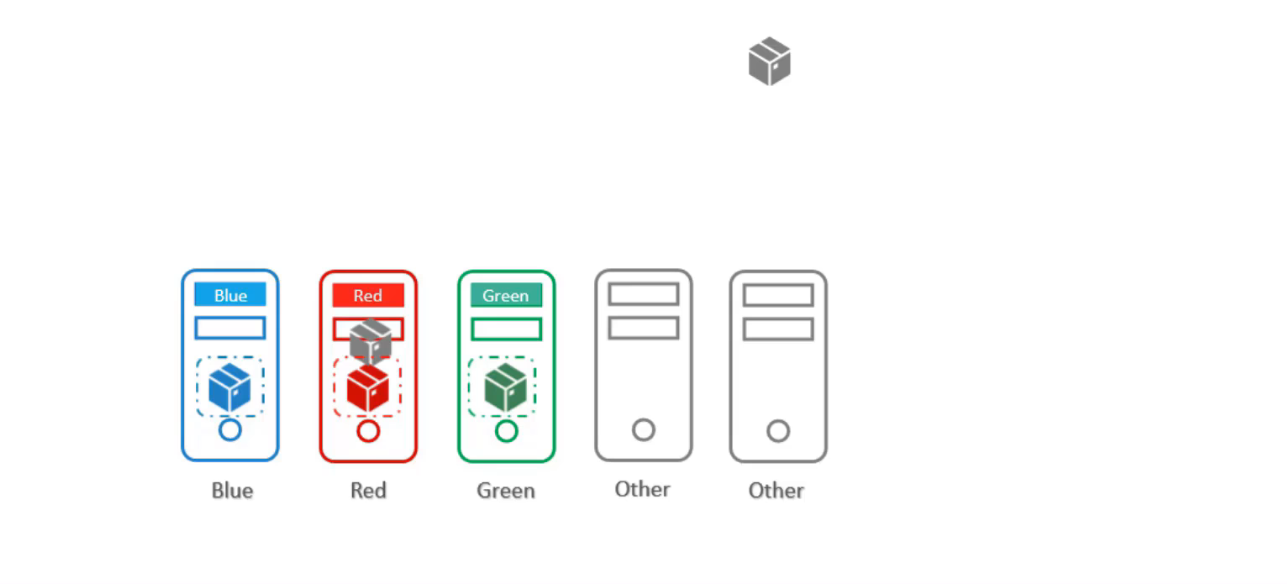
Như vậy, sự kết hợp của taints & tolerations and node affnity có thể được sử dụng cùng nhau để dành các node cho các pod cụ thể.
Đầu tiên, sử dụng taints & tolerations để ngăn chặn các pod other có thể đặt trên các node này.
Sau đó sử dụng node affinity để ngăn các pod blue, red, green được đặt trên node other.
DaemonSets
Chúng ta đã triển khai nhiều pod khác nhau trên các node khác nhau trong cluster. Với sự trợ giúp của ReplicaSets và Deployments đảm bảo có nhiều bản sao được phân phối các worker node khác nhau.
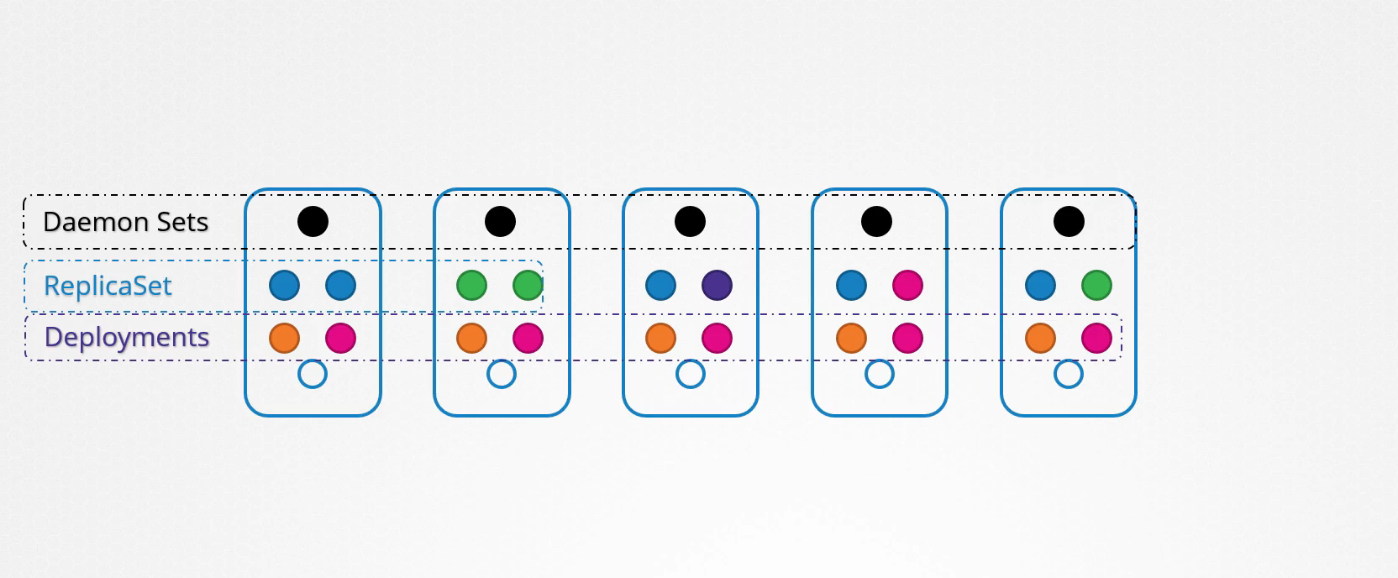
DaemonSets giống như ReplicaSets vì nó giúp bạn triển khai nhiều bản sao của các pod, tuy nhiên DaemonSet đảm bảo rằng luôn có một bản sao của pod trên tất cả các node trong cụm.
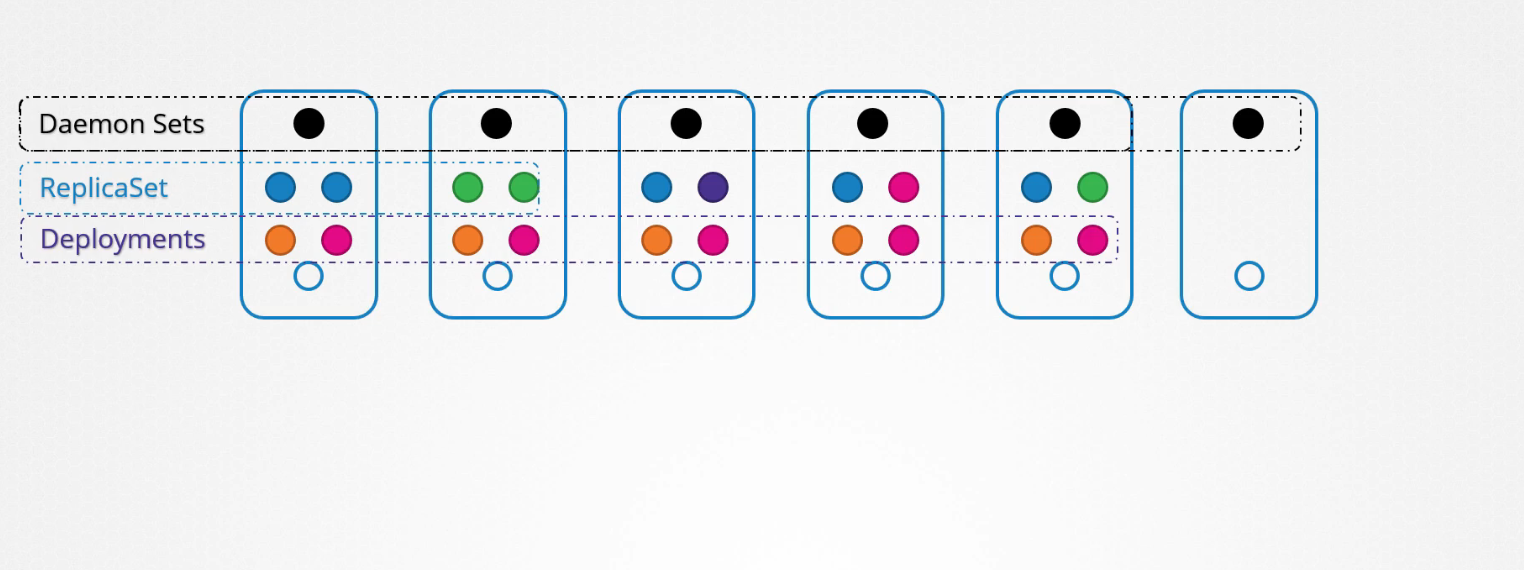
Bất cứ khi nào bạn thêm một node mới vào cluster, một bản sao của pod sẽ tự động thêm vào node đó và khi một node bị loại bỏ thì pod sẽ tự động bị xóa. DaemonSet đảm bỏa rằng có 1 bản sao của pod luôn hiện diện ở tất cả các node trong cluster.
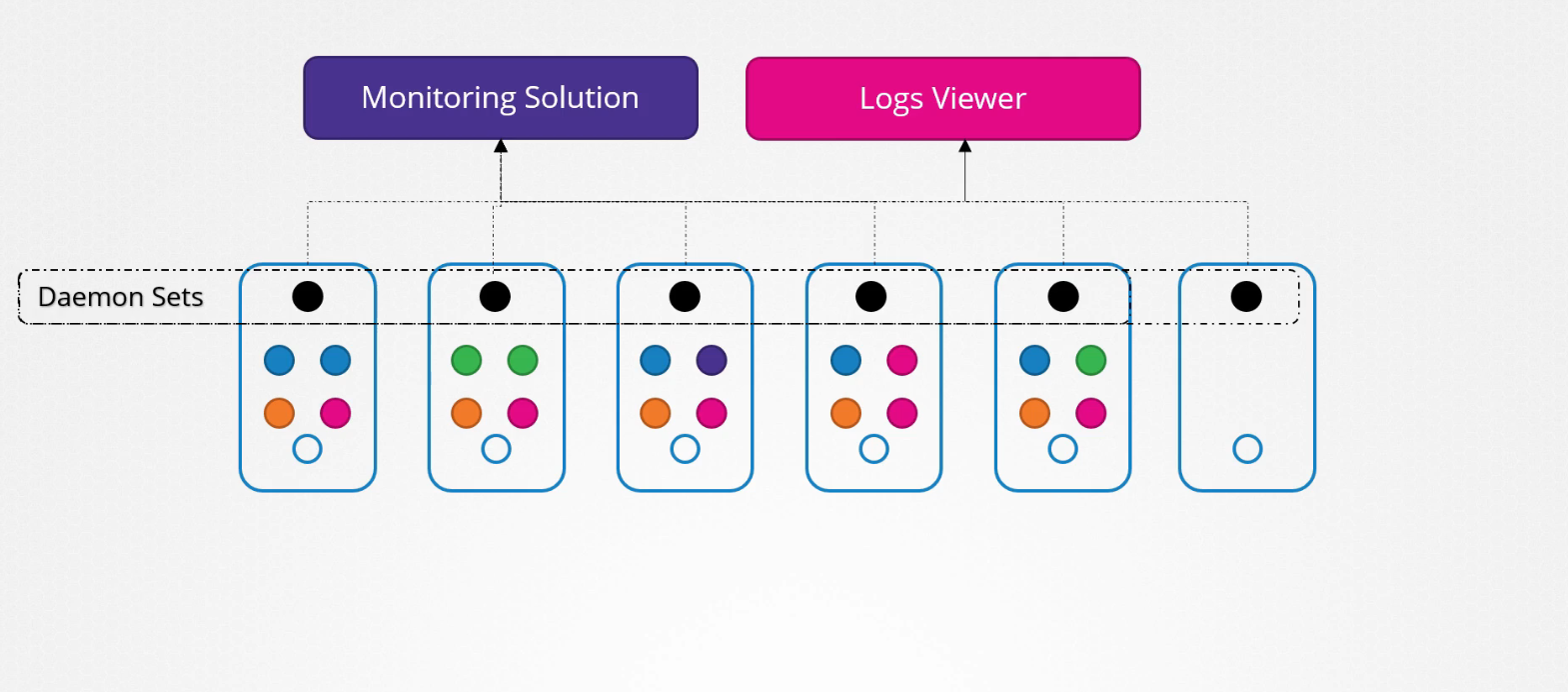
Giả sử bạn muốn triển khai một monitoring solution hoặc logs viewer trên mỗi node trong cluster của bạn để có thể giám sát cluster tốt hơn. DaemonSet là sự lựa chọn hoàn hảo cho việc đó vì nó có thể triển khai monitoring agent ở dạng pod trên tất cả các node trong cluster.
Sau đó bạn không phải lo lắng về việc thêm hoạc xóa các monitoring agent trên các node khi có sự thay đổi trong cluster vì DaemonSet sẽ lo việc đó cho bạn.
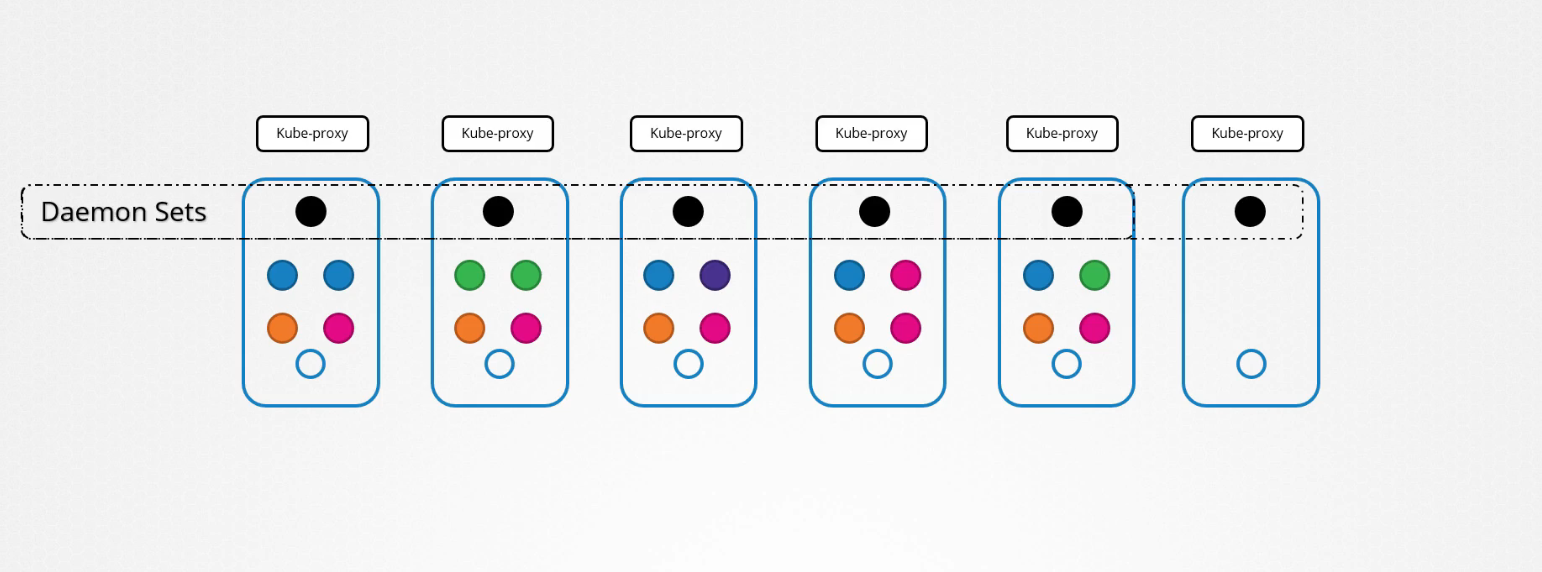
Trước đây, khi thảo luận về kiến trúc Kubernetes, chúng ta đã biết rằng một trong những thành phần cần thiết trên mỗi node là kube-proxy. Đây là một ví dụ tuyệt vời cho việc sử dụng DaemonSet. Thành phần kube-proxy có thể được triển khai dưới dạng DaemonSet trong cụm.
Việc tạo DaemonSet cũng tương tự như quá trình tạo ReplicaSet. Nó có phần khai báo pod trong phần template và selector để liên kết DaemonSet với các pod. Tệp cấu hình DaemonSet có cấu trúc tương tự.
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: monitoring-daemon
spec:
selector:
matchLabels:
app: monitoring-daemon
template:
metadata:
labels:
app: monitoring-daemon
spec:
containers:
- name: monitoring-daemon
image: monitoring-daemon
Để xem DaemonSet được tạo, chạy lệnh:
$ kubectl get daemonsets
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE AGE
monitoring-daemon 1 1 1 1 1 3s
Từ phiên bản Kubernetes v1.12 trở đi, DaemonSet sử dụng scheduler mặc định và rules node affinity để lên lịch pod trên các node.
Static PODS
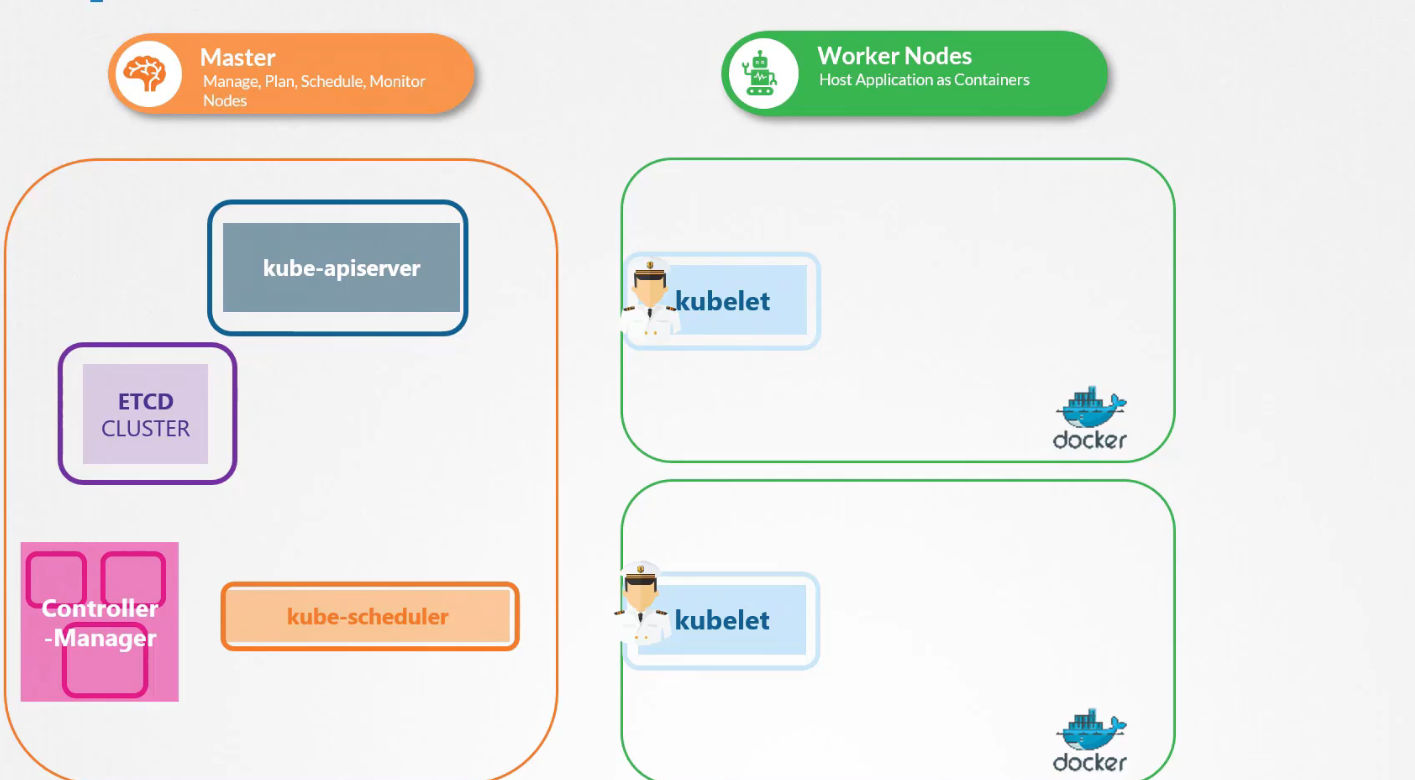
Trước đó, chúng ta đã đề cập đến kiến trúc của Kubernetes và cách kubelet hoạt động như là một trong nhiều thành phần của control plane. Kubelet thường dựa vào kube-apiserver để lấy hướng dẫn về việc tải các Pod trên Node của nó, dựa trên quyết định từ kube-scheduler và lưu trữ trong ETCD.
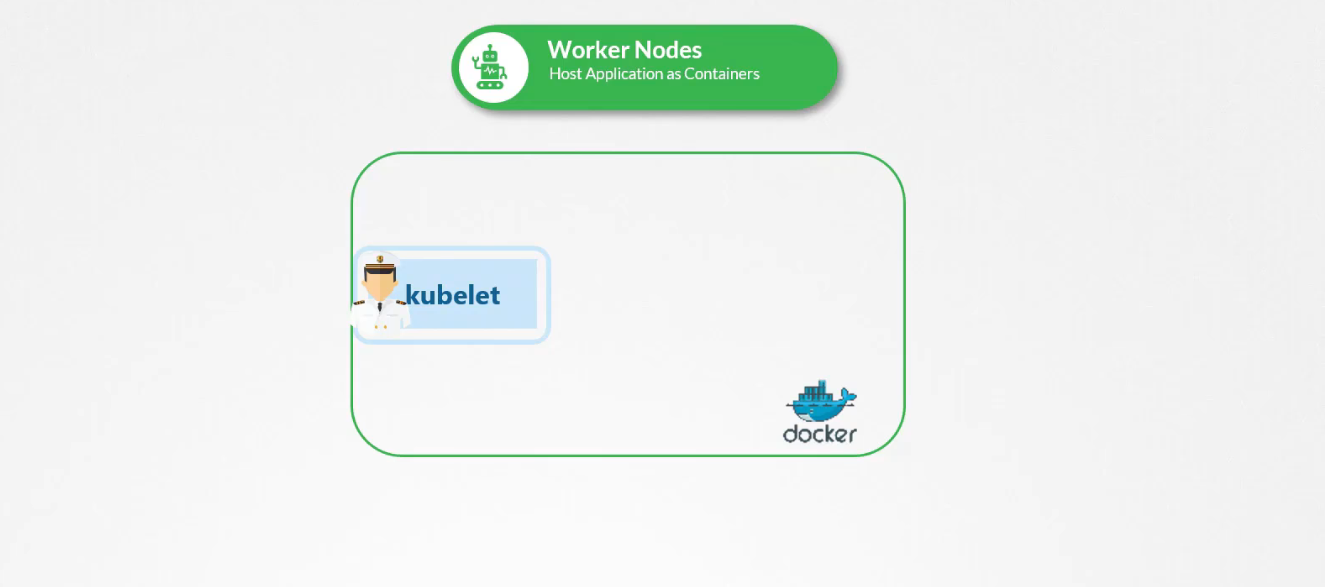
Nhưng nếu không có kube-apiserver, kube-scheduler, controller, hay ETCD thì sao? Nếu không có cả master và không có Node nào khác, chỉ có một Node độc lập duy nhất, kubelet vẫn có thể hoạt động như một Node độc lập. Lúc này, ai sẽ cung cấp hướng dẫn để tạo các Pod?
Kubelet có thể quản lý node một cách độc lập, có cài đặt kubelet và containerd để chạy các containers. Một điều mà kubelet biết làm là tạo pod nhưng chúng ta không có kube-apiserver để cung cấp thông tin chi tiết về pod. Chúng ta biết rằng để tạo một pod bạn cần thông tin chi tiết về pod trong tệp định nghĩa pod.
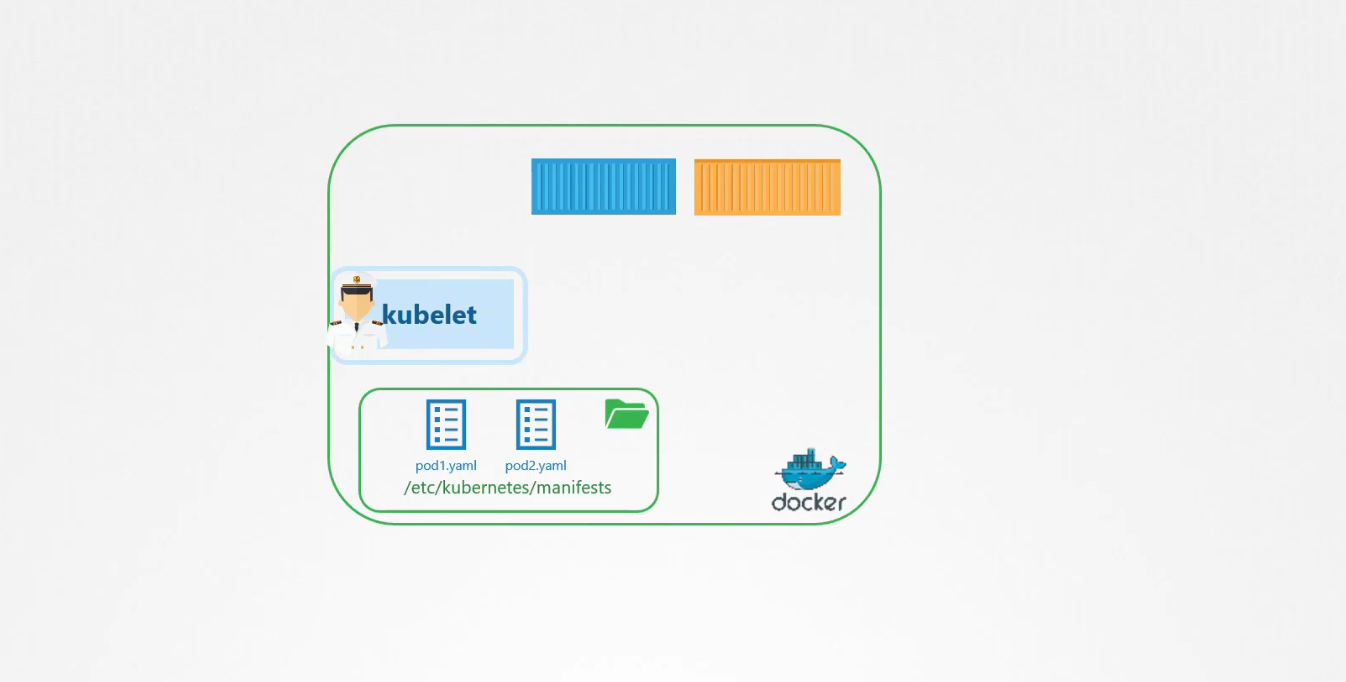
Bạn có thể cấu hình kubelet để độc các tệp định nghĩa pod từ một thư mục trên máy chủ được chỉ định để lưu trữ thông tin về pod. Đặt các tệp định nghĩa pod trong thư mục này, kubelet định kỳ kiểm tra thư mục này để tìm các file, đọc các tệp file này và tạo các pod trên máy chủ.
Nó không chỉ tạo ra pod mà đảm bảo rằng pod luôn tồn tại, nếu ứng dụng gặp sự cố kubelet sẽ cố gắng khởi động lại nó. Nếu bạn thực hiện thay đổi đối với bất kỳ file nào trong thư mục này, kubelet sẽ tạo lại pod để những thay đổi đó có hiệu lực. Nếu bạn xóa một tệp khỏi thư mục này, pod sẽ tự động bị xóa.
Vì vậy những pod này được kubelet tự tạo ra không có sự can thiệp của api-server hoặc các thành phần khác trong cluster được gọi là Static PODS.
Bạn không thể tạo replicaSet hoặc deployment hoặc service theo cách này bằng cách đặt một file vào thư mục được chỉ định. Kubelet hoạt động ở cấp độ pod và chỉ có thể hiểu pod nên nó có thể tạo static pod theo cách này.
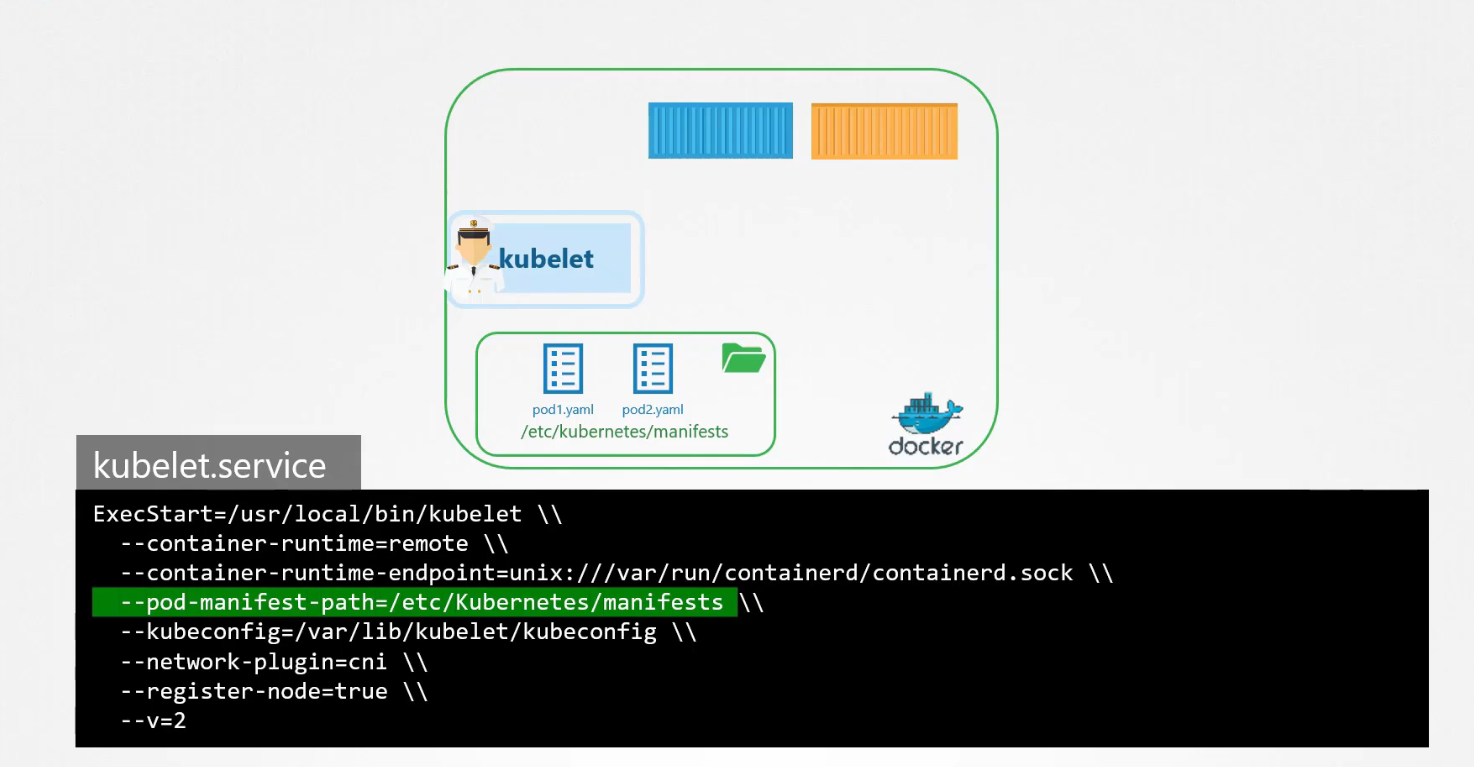
Nó có thể là bất kỳ thư mục nào trên máy chủ và vị trí của thư mục đó được chuyển vào kubelet dưới dạng tùy chọn trong khi chạy dịch vụ. Tùy chọn này có tên là pod-manifest-path ở đây nó được đặt thành thư mục /etc/Kubernetes/manifests.

Còn một cách khác để cấu hình, thay vì chỉ định trực tiếp đến thư mục trong kubelet.service bạn có thể cung cấp đường dẫn trong tệp cấu hình khác, sử dụng tùy chọn config và xác định đường dẫn thư mục là staticPodPath trong tệp đó.
Khi các static pod được tạo, bạn có thể xem chúng bằng các chạy lệnh nerdctl ps
Khi có kube-apiserver yêu cầu kubelet tạo pod thì kubelet có thể tạo cả hai loại pod cùng một lúc không?
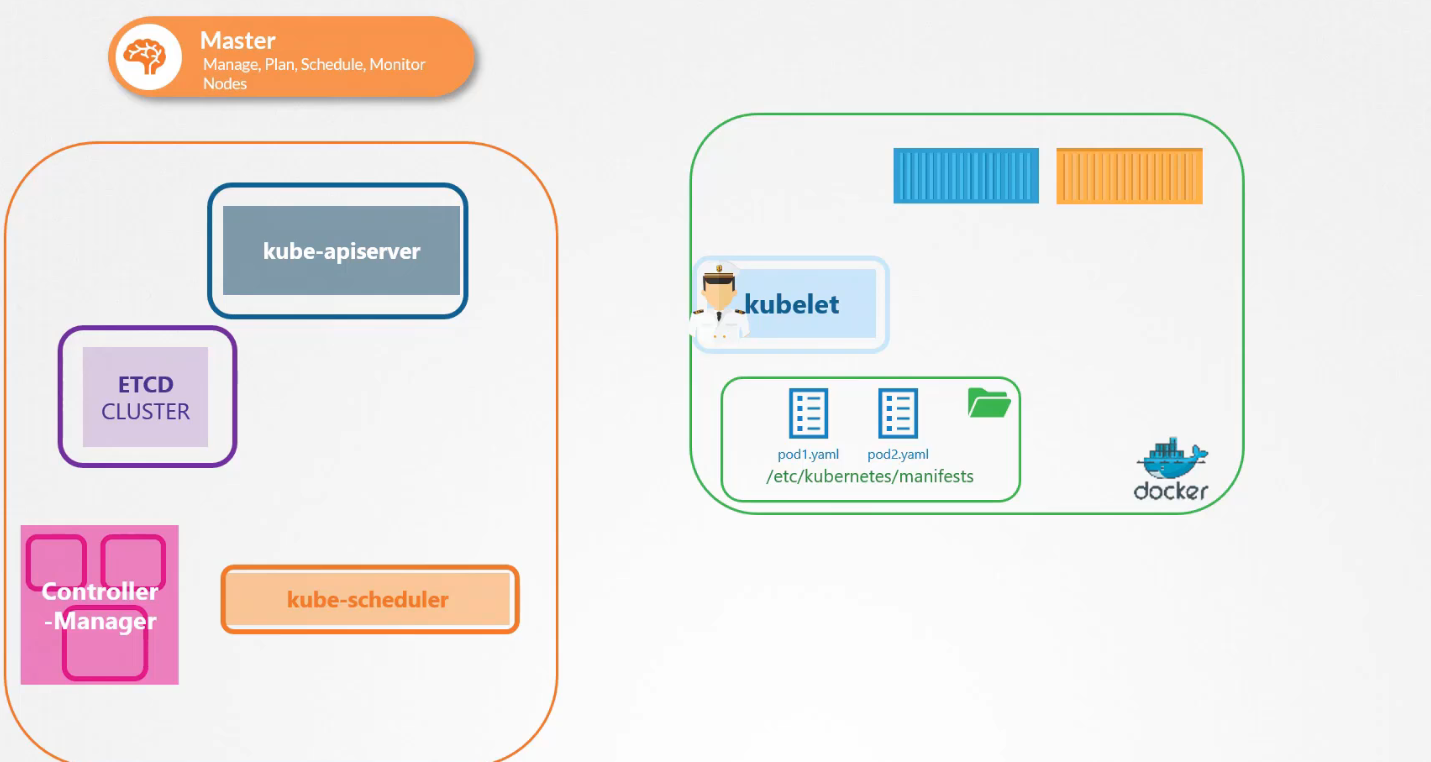
Cách hoạt động của kubelet là có thể nhận yêu cầu để tạo pod từ các đầu khác nhau:
Thông qua file định nghĩa pod từ thư mục static pod
Thông qua APIServer, đây là cách kube-apiserver cấp đàu vào cho kubelet
Kubelet có thể tạo cả static pod và các pod từ kube-apiserver cùng một lúc.
Nếu bạn chạy lệnh kubectl get pod trên master node, các static pod cũng sẽ được liệt kê như bất kỳ pod khác. Khi kubelet tạo static pod nếu node đó là một phần của cluster, nó cũng sẽ tạo một đối tượng nhân bản trong kube-apiserver. Những gì bạn thấy từ kube-apiserver là một bản sao chỉ đọc được của pod, bạn không thể chỉnh sửa hoặc xóa nó đi.
Vì nếu bất kỳ static pod nào gặp sự cố nó sẽ tự động được khởi động lại bởi kubelet.
Multiple Schedulers
Chúng ta đã thấy scheduler default hoạt động như thế nào, nó có thuật toán để phân phối các pod trên các node một cách đồng đều cũng như xem xét các điều kiện khac nhau thông qua taints & tolerations, node affinity,v.v.
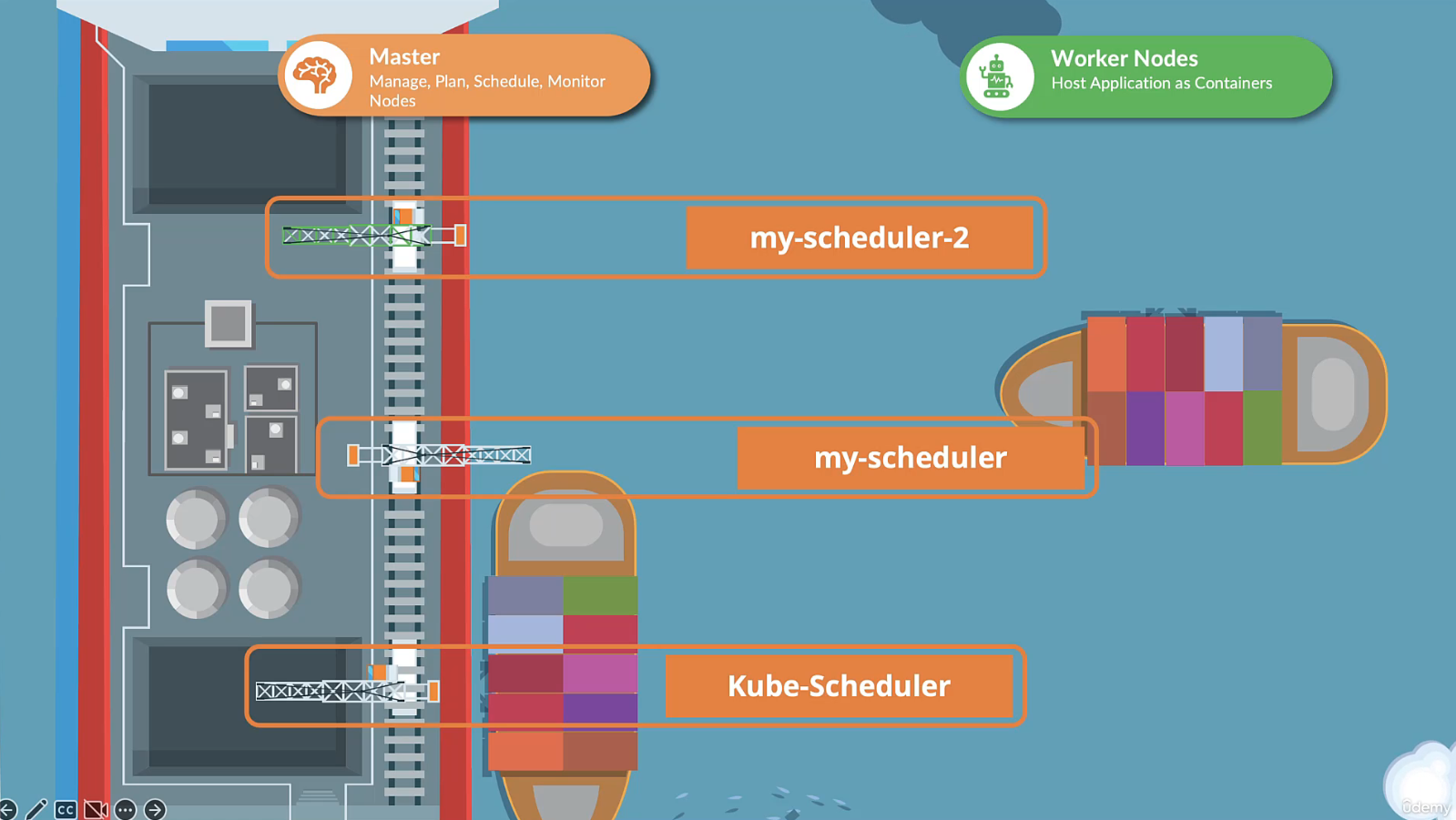
Vì vậy bạn quyết định lập thuật toán scheduler cho riêng mình để đặt pod trên các node để bạn có thể thêm các điều kiện khác. Kubernetes có khả năng mở rộng cao, bạn có thể viết chương trình scheduler của riêng mình, đóng gói nó và triển khai làm scheduler default. Vì vậy, cluster của bạn có thể có nhiều scheduler cùng một lúc.
Khi tạo pod hoặc deployment bạn có thể hướng dẫn kubernetes để nhóm được lên lịch bởi scheduler cụ thể.

Khi có nhiều scheduler thì phải có tên khác nhau để xác định chúng là những scheduler riêng biệt. Vì vậy scheduler default được đặt tên là default-scheduler và tên của nó được cấu hình trong tệp kube-scheduler.yaml như này:
apiVersion: kubecheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: default-scheduler
Đối với các scheduler khác, bạn có thể tạo một tệp cấu hình riêng và đặt tên schduler cho nó:
apiVersion: kubecheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: my-scheduler
Định nghĩa một file pod và chỉ định thuộc tính kubeconfig thành đường dẫn đến tệp scheduler.conf , có thông tin xác thực để kết nối tới API server. Sau đó chuyển vào tệp cấu hình my-scheduler-config.yaml vào thuộc tính config:
apiVersion: v1
kind: Pod
metadata:
name: my-custom-scheduler
namespace: kube-system
spec:
containers:
- command:
- kube-scheduler
- --address=127.0.0.1
- --kubeconfig=/etc/kubernetes/scheduler.conf
- --config=/etc/kubernetes/my-scheduler-config.yaml
image: k8s.gcr.io/kube-scheduler-amd64:v1.11.3
name: kube-scheduler
Bây giờ có một lựa chọn quan trong khác để xem ở đây là leaderElection và điều này sẽ đi vào cấu hình của kube-scheduler:
apiVersion: kubecheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: my-scheduler
leaderElection:
leaderElect: true
resourceNamespace: kube-system
resourceName: lock-object-my-scheduler
Tuỳ chọn này được sử dụng khi bạn có nhiều scheduler đang chạy trên các master node. Nếu có nhiều scheduler đang chạy trên các node khác nhau, mỗi lần chỉ có một scheduler hoạt động và đó là nơi mà leaderElect sẽ giúp ích trong việc lựa chọn leader.
Khi tạo một pod hoặc deployment làm thế nào để sử dụng scheduler mới này?
Ở đây, có một tệp định nghĩa pod và những gì cần làm là thêm một trường schedulerName và chỉ định tên của scheduler:
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx
schedulerName: my-custom-scheduler
Bằng các này khi pod được tạo, scheduler phù hợp sẽ được chọn và quá trình lập lịch này hoạt động.
Subscribe to my newsletter
Read articles from Phan Văn Hoàng directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by