LLM para extração de dados estruturados de documentos utilizando Langchain, OpenAI GPT e FastAPI
 Victor Nascimento
Victor Nascimento
Introdução
No desenvolvimento de soluções empresariais com inteligência artificial, especialmente usando tecnologias complexas como IA generativa, é fundamental que a equipe tenha acesso a ferramentas acessíveis e colaborativas. Neste post, exploramos como construir uma API usando FastAPI e LangChain, ambas ferramentas open-source, para extrair dados estruturados de faturas de energia elétrica em formato pdf. O objetivo é encapsular a complexidade da IA generativa, tornando-a acessível para toda a equipe e permitindo que outros desenvolvedores utilizem a api facilmente, sem a necessidade de um conhecimento profundo em IA. Com uma abordagem baseada em tecnologias open-source , vamos criar uma api simples, colaborativa e de alto valor, otimizando o trabalho em equipe e promovendo inovação com um custo acessível!
Neste post, exploraremos cada etapa da criação de uma solução com IA generativa para transformar a análise faturas de energia elétrica, em dados estruturados, usando uma stack de ferramentas open-source. Essa abordagem permitirá que informações úteis sejam extraídas automaticamente, simplificando o acesso aos dados e facilitando a integração com outras aplicações. Abaixo, uma visão geral do que será abordado:
Análise do PDF da Fatura de Energia
Vamos começar explorando o documento PDF de uma fatura de energia elétrica, compreendendo sua estrutura e identificando os dados críticos, como valores, datas, e demais itens que possam interessar um consumidor da nossa futura API. Esse mapeamento é fundamental para planejar uma extração de dados eficiente.Extraindo o texto do documento
Em seguida, converteremos o documento PDF em um objeto python comatível com langchain.Prompt Engineering para Extrair Dados Específicos
Para garantir que a IA extraia apenas as informações relevantes, utilizaremos técnicas de prompt engineering. Essa etapa orientará a IA a focar nos dados desejados, como datas e valores, melhorando a precisão e a eficiência. Além de fornecermos a estrutura de dados em json com a qual o modelo deve responder.Modelo LLM
O langchain torna nossa aplicação agnóstica ao fornecedor do LLM, com isso podemos utilizar modelos open source como llama3.2 , gemma2, bart.E modelos privados como o GPT-4o ou Claude 3.5 Sonnet.
Question-Answering Chain (Chain QA)
Implementaremos um chain QA para responder perguntas específicas sobre a fatura. Essa cadeia permite que o modelo de linguagem compreenda e extraia respostas detalhadas de documentos complexos, organizando as informações automaticamente e de maneira eficiente.Construindo uma API FastAPI
Por fim, vamos reunir tudo em uma API baseada em FastAPI, que servirá como um ponto de acesso fácil de usar para os dados extraídos.
Código fonte: Github
Análise do PDF da Fatura de Energia
Utilizaremos como exemplo 2 companhias de distribuição de energia elétrica: ENEL e LIGHT S.A. . Utilizaremos como fonte a documento destinado ao consumidor para realizar o pagamento do consumo de energia elétrica referente ao mês anterior da data de vencimento da fatura.
Para esta empreitadas temos interesse em extrair os seguintes dados:
Periodo de referêrencia ( no formato MM/YYYY) .
Próxima leitura ( Quando será realizada a próxima aferição à partir da data da fatura atual ).
Data de vencimento.
Bandeira tarifária ( Amarela, Verde ou Vermelha).
Nome da distribuidora ( Nesse caso ENEL ou LIGHT).
Codigo do cliente ( Identificação única do cliente na distribuidora)
Tipo de Fornecimento ( Monofásico, Bifásico ou Trifásico).
Valor total
Consumo em KWh
Nome do cliente.
Exemplo de uma conta de energia elétrica da Enel:

** Alguns dados privados foram editados
Extraindo o texto do documento
O LangChain é um framework que ajuda desenvolvedores a criarem aplicações com modelos de linguagem avançados (como chatbots e assistentes virtuais). Ele organiza diferentes partes do processo, como envio de perguntas e uso de dados, facilitando a construção de fluxos de conversa e análise de texto complexos. Em resumo, o LangChain permite integrar IA de forma prática, conectando dados e modelos em uma única aplicação.
Primeiro inicie um novo projeto python utilizando o poetry:
poetry init
Instale as seguintes dependencias:
poetry add langchain pypdf langchain_community fastapi python-multipart pymupdf langchain-openai python-dotenv
Daqui em diante podemos criar um arquivo main.py para escrever o código ( ou um jupyter notebook se preferir).
Importe as seguintes dependencias no topo do arquivo:
from langchain_community.document_loaders import PyPDFLoader
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplate
from langchain.chains.question_answering import load_qa_chain
from pydantic import BaseModel,Field
from typing import Literal
from dotenv import load_dotenv
Primeiro precisamos transformar o nosso arquivo PDF em texto, de forma à ser tratável pelo nosso LLM. Para isso utilizaremos uma ferramenta do ecossistema Langchain chamada DocumentLoader.
Um DocumentLoader é uma ferramenta do LangChain usada para carregar e estruturar dados de diversas fontes para que possam ser usados por modelos de linguagem. Ele extrai e organiza o conteúdo de documentos em um formato padronizado, facilitando o processamento e análise.
O PyPDFLoader é um tipo de DocumentLoader projetado especificamente para arquivos PDF. Ele interpreta o conteúdo do arquivo, extrai o texto e o transforma em documentos prontos para análise, permitindo que o LangChain os use diretamente em aplicações com IA generativa, como em perguntas e respostas ou resumo de textos.
Vamos assumir que o nosso arquivo PDF esteja na pasta './files/enel1.pdf’ quando analisado à partir do nosso arquivo main.py, para utilizar o nosso PyPDFLoader basta criarmos uma nova instância do objeto utilizando no construtor o caminho do arquivo. Para extrair uma lista de objetos do tipo Document, utilizamos o método .load().
file_path = "./files/enel1.pdf"
loader = PyPDFLoader(file_path)
documents =loader.load()
Nossa variável documents possui uma lista de Document, com cada Document representando uma página do arquivo pdf.
Prompt Engineering para Extrair Dados Específicos
Prompt engineering é o processo de criar e ajustar instruções específicas (ou "prompts") para guiar um modelo de linguagem (LLM) a gerar respostas úteis e precisas. No contexto de LangChain, em que LLMs são usados com DocumentLoaders para processar e entender documentos, prompt engineering ajuda a definir perguntas e tarefas de forma clara para extrair as informações corretas dos dados carregados.
No caso de extrair dados de uma conta de energia, o prompt pode ser detalhado de forma a estimular o LLM a identificar e estruturar informações importantes. Por exemplo, um prompt como "Leia a conta de energia e extraia a data de vencimento, o consumo total em kWh, e o valor total. Se houver tarifas adicionais, liste também" orienta o modelo a não apenas localizar os dados, mas também a organizá-los e inferir relações, como valores totais e adicionais.
Essa técnica ajuda a maximizar o potencial do LLM, que pode “raciocinar” para encontrar dados que não estejam explicitamente definidos e para interpretar documentos de maneira contextualizada, elevando a precisão e qualidade dos resultados.
O nosso objetivo é, além de extrair as informações, conseguir as informações de forma estruturada de modo fornece-las como um objeto JSON em uma API, para isso utilizaremos o JsonOutputParser junto à nosso prompt para guiar o modelo para a resposta adequada.
class EnergyCompanyResponse(BaseModel):
periodo_referencia: str = Field(description="Periodo de referência da fatura no formato MM/YYYY")
proxima_leitura: str = Field(description="Data da próxima leitura no formato DD/MM/YYYY")
vencimento: str = Field(description="Data de vencimento da fatura no formato")
bandeira_tarifaria: Literal['Vermelha','Amarela','Verde'] = Field(description="Bandeira tarifária da fatura")
nome_distribuidora: str = Field(description="Nome da companhia distribuidora de energia")
codigo_cliente: str = Field(description="Código do cliente na distribuidora")
codigo_instalacao: str = Field(description="Código da instalação na distribuidora")
tipo_fornecimento: Literal['Monofásico','Bifásico','Trifásico'] = Field(description="Tipo de fornecimento de energia")
valor_total: float = Field(description="Valor total da fatura")
consumo_kwh: float = Field(description="Consumo em kWh")
client_nome: str = Field(description="Nome do cliente")
output_parser = JsonOutputParser(pydantic_object=EnergyCompanyResponse)
prompt = PromptTemplate(
template="""
A resposta deve conter exclusivamente a informação em JSON, sem nenhum texto adicional.
A resposta deve ser no formato e somente com os campos abaixo: \n
{format_instructions}
O texto da fatura é o seguinte: \n
{context}
""",
input_variables=["context"],
partial_variables={
"format_instructions": output_parser.get_format_instructions()
}
)
Cada detalhe da classe EnergyCompanyResponse é importante para o modelo entender quais os dados e em que formatos eles devolvidos como resposta. O LLM irá interpretar a propriedade descriptiondos campos para preenche-los adequadamente com os valores interpretados do documento
Modelo LLM
Neste post abriremos duas possibilidade de modelo (Você pode escolher basicamente qualquer LLM, o langchain fornece suporte à quase todas). Utilizando o GPT-TURBO-3.5 a execução total desse experimento dificilmente ultrapassará o valor de R$0,01.
Caso você tenha acesso à uma máquina com capacidade computacional suficiente, poderá experimentar o modelo LLAMA3.2 na versão 3b. Adianto que dificilmente a versão do LLAMA3.2 inferior à 70b trará resultados satisfatórios para o nosso experimento.
GPT-TURBO-3.5
Utilize o painel da OpenAI para gerar uma nova api-key e a adicione ao arquivo .env na raiz do diretório, junto ao main.py
OPENAI_API_KEY=[SUA-CHAVE]
Para criarmos criarmos uma instância do modelo podemos utilizar o python-dotenv para adicione a chave como variavel de ambiente ao projeto e instancia a classe do ChatGPT
load_dotenv()
llm = ChatOpenAI(model="gpt-3.5-turbo")
LLama3.2:
Também podemos utilizar o modelo LLama, que é gratuito. Porém como não temos recurso computacionar o suficiente para executar o llama3.2 em sua forma de maior performance em um computador pessoal, não obteremos resultados tão satisfatórios quanto aos do GPT-4o.
Utilize o ollama para realizar o pull do modelo LLAMA 3.2 3b.
ollama pull llama3.2
Com isso podemos instancia o modelo da seguinte forma:
from langchain_ollama.llms import ChatOllama
llm = ChatOllama(model="llama3.2")
Para o resto desse artigo, seguiremos com o modelo ChatGpt 3.5-turbo
Question-Answering Chain (Chain QA)
No código a seguir, mostramos um exemplo prático de como configurar uma cadeia Q&A para extrair informações de faturas de energia. A função load_qa_chain carrega a cadeia com o modelo de linguagem desejado, especificando o tipo de cadeia como "stuff", que trata todos os documentos como um único bloco de texto. A question é definida para guiar o modelo na tarefa de extração, e o output_parser assegura que a resposta gerada seja formatada da maneira que definimos com o JsonOutputParser.
qa_chain = load_qa_chain(llm=llm,chain_type="stuff",prompt=prompt,verbose=False)
response = qa_chain.run(input_documents=documents,question="Extraia as informações requisitadas da fatura de energia",output_parser=output_parser)
parsed_response = output_parser.parse(response)
Construindo uma API com FASTAPI
Por fim, podemos utilizar o FASTAPI para disponibilizar o nosso modelo.
from fastapi import FastAPI, UploadFile
from langchain.schema import Document
from langchain_core.output_parsers import JsonOutputParser
from langchain.chains.question_answering import load_qa_chain
from langchain.schema import Document
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import JsonOutputParser
from langchain_openai import ChatOpenAI
from pydantic import BaseModel,Field
from typing import Literal
from dotenv import load_dotenv
load_dotenv()
import fitz
app = FastAPI(
title="Energy Bill Data",
summary="API para leitura de dados de conta de energia",
version="1.0.0",
contact={
"github":"https://github.com/vanascimento"
}
)
@app.post("/",description="Arquivo PDF da conta de energia",tags=["Energy Bill Data"])
async def analyze_document_data(file: UploadFile):
file_content = await file.read()
document = build_langchain_documents_from_bytes(file_content)
output_parser = JsonOutputParser(pydantic_object=EnergyCompanyResponse)
prompt = get_prompt(parser=output_parser)
llm = ChatOpenAI(model="gpt-3.5-turbo")
qa_chain = load_qa_chain(llm=llm,chain_type="stuff",prompt=prompt,verbose=False)
response = qa_chain.run(input_documents=[document])
json_response = output_parser.parse(response)
return json_response
def build_langchain_documents_from_bytes(file:bytes):
text = ""
with fitz.open(stream=file, filetype="pdf") as doc:
for page_num in range(doc.page_count):
page = doc[page_num]
text += page.get_text()
document = Document(page_content=text)
return document
def get_prompt(parser:JsonOutputParser):
prompt = PromptTemplate(
template="""
A resposta deve conter exclusivamente a informação em JSON, sem nenhum texto adicional.
A resposta deve ser no formato: \n
{format_instructions}
O texto da fatura é o seguinte: \n
{context}
""",
input_variables=["context"],
partial_variables={
"format_instructions": parser.get_format_instructions()
}
)
return prompt
class EnergyCompanyResponse(BaseModel):
periodo_referencia: str = Field(description="Periodo de referência da fatura no formato MM/YYYY")
proxima_leitura: str = Field(description="Data da próxima leitura no formato DD/MM/YYYY")
vencimento: str = Field(description="Data de vencimento da fatura no formato")
bandeira_tarifaria: Literal['Vermelha','Amarela','Verde'] = Field(description="Bandeira tarifária da fatura")
nome_distribuidora: str = Field(description="Nome da companhia distribuidora de energia")
codigo_cliente: str = Field(description="Código do cliente na distribuidora")
codigo_instalacao: str = Field(description="Código da instalação na distribuidora")
tipo_fornecimento: Literal['Monofásico','Bifásico','Trifásico'] = Field(description="Tipo de fornecimento de energia")
valor_total: float = Field(description="Valor total da fatura")
Para executarmos o projeto, utilize o comando:
fastapi dev main.py
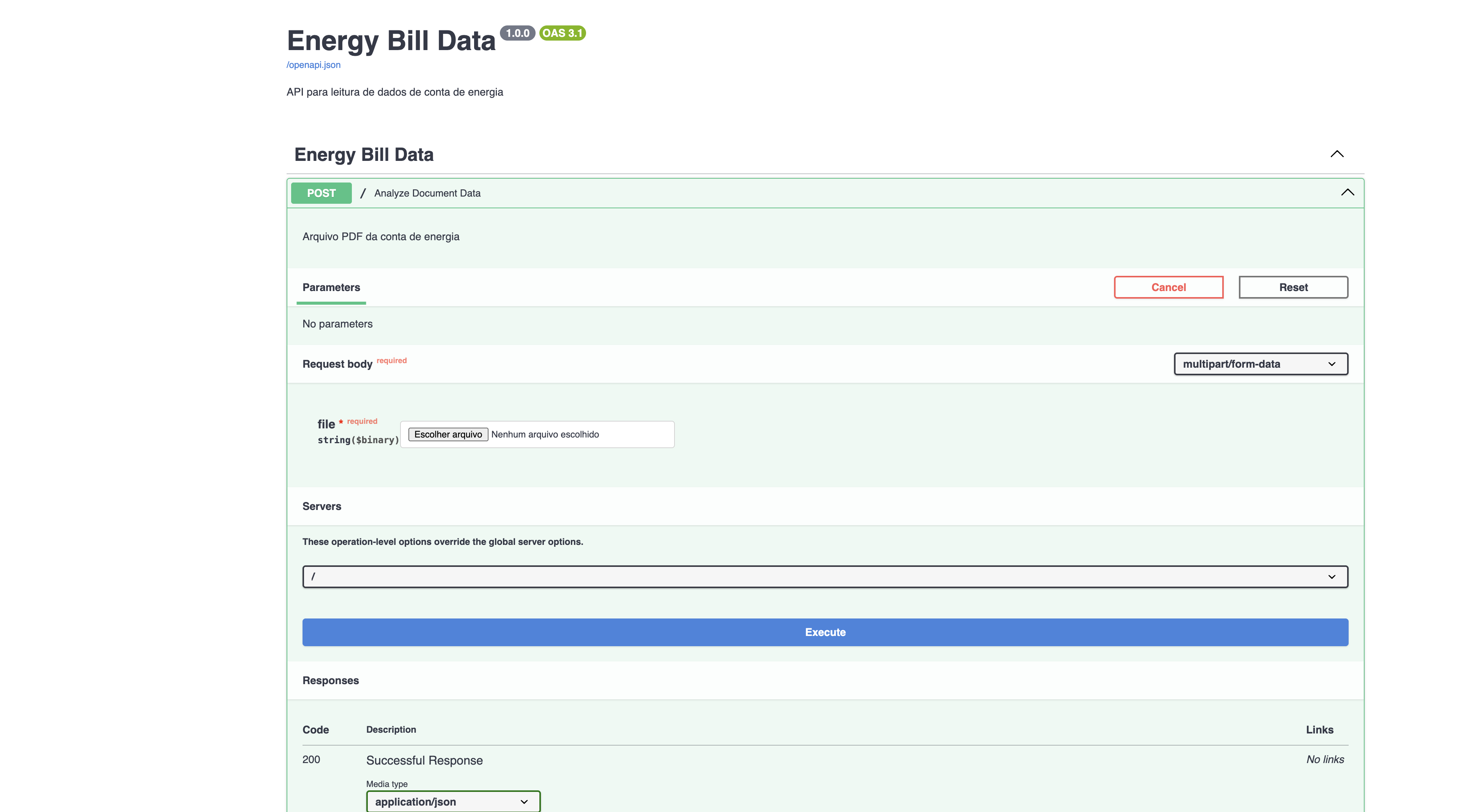
A aplicação será executada no endereço http://localhost:8000/docs, utlize a interface do swagger para enviar a sua conta de energia em pdf:
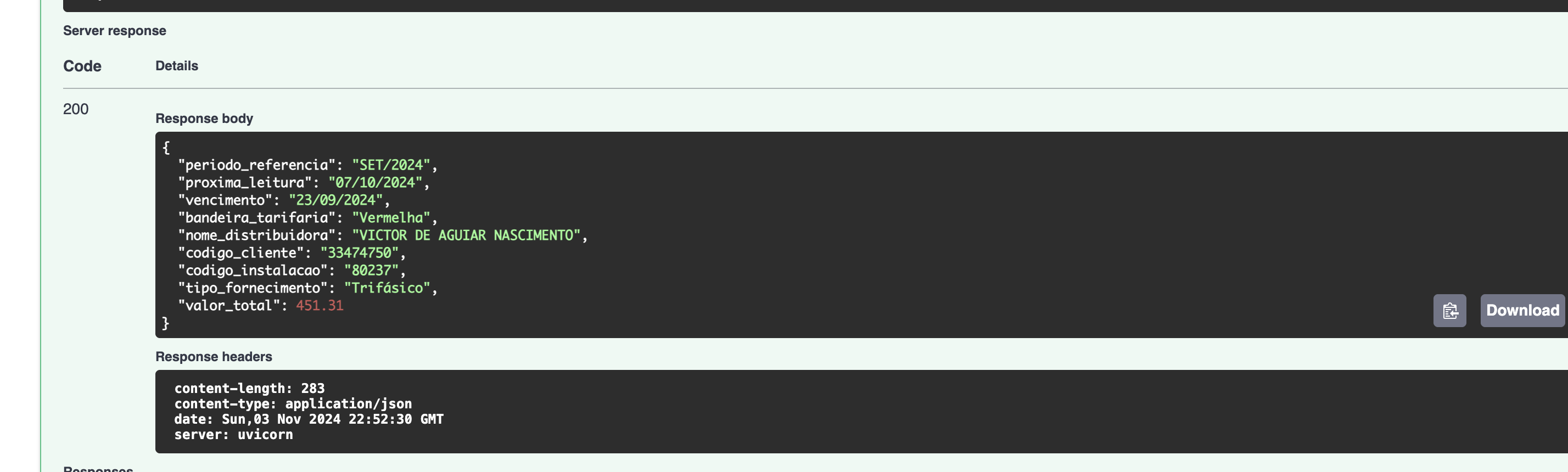
E assim obteremos a nossa resposta de forma estruturada.
Código fonte: Github
Alguns tópicos que serão abordados em artigos futuros:
Como podemos reduzir a quantidade de tokens e enviar somente a seção do documento com maior probabilidade de responder a pergunta.
Como usar ferramentas externas junto ao modelo.
Como criar uma solução com multiplos
chains.
Subscribe to my newsletter
Read articles from Victor Nascimento directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Victor Nascimento
Victor Nascimento
Electrical Engineering by Universidade Federal Fluminense 🌱 Learning Large Language Models for processing automation and how to utilize blockchain (Ethereum) on enterprise environment Working as Software Engineering @ BTG Pactual Several certifications on AWS platform and Brazilian Financial Markets