Day 4 : Hands-On Data Preprocessing | Generative AI
 Manav Paul
Manav Paul
👋🏻 Welcome back to my blog! If you're new here, I recommend starting with Day 1 : Introduction to GenAI to get a solid foundation in generative AI.
On Day 2 and 3, we cover all the steps to make an end to end generative ai pipeline. Today, we'll get our hands dirty on the practical aspects of data preprocessing techniques.
Full Playlist : ▶ Master GenAI Series
😊 Hello World, I'm Manav Paul, a 24-year-young spiritual developer on a mission to understand and leverage the power of generative AI. This blog serves as a roadmap, guiding you through my 30-day journey of discovering the fascinating world of generative AI. Let's continue our exploration together!
Here we will be learning how to clean up the data using the data preprocessing techniques.
Let’s get our hands dirty on some code.

First, we need a dataset to work on. So let’s log in to Kaggle and download our IMDB dataset having 50K movie reviews for natural language processing or Text analytics.
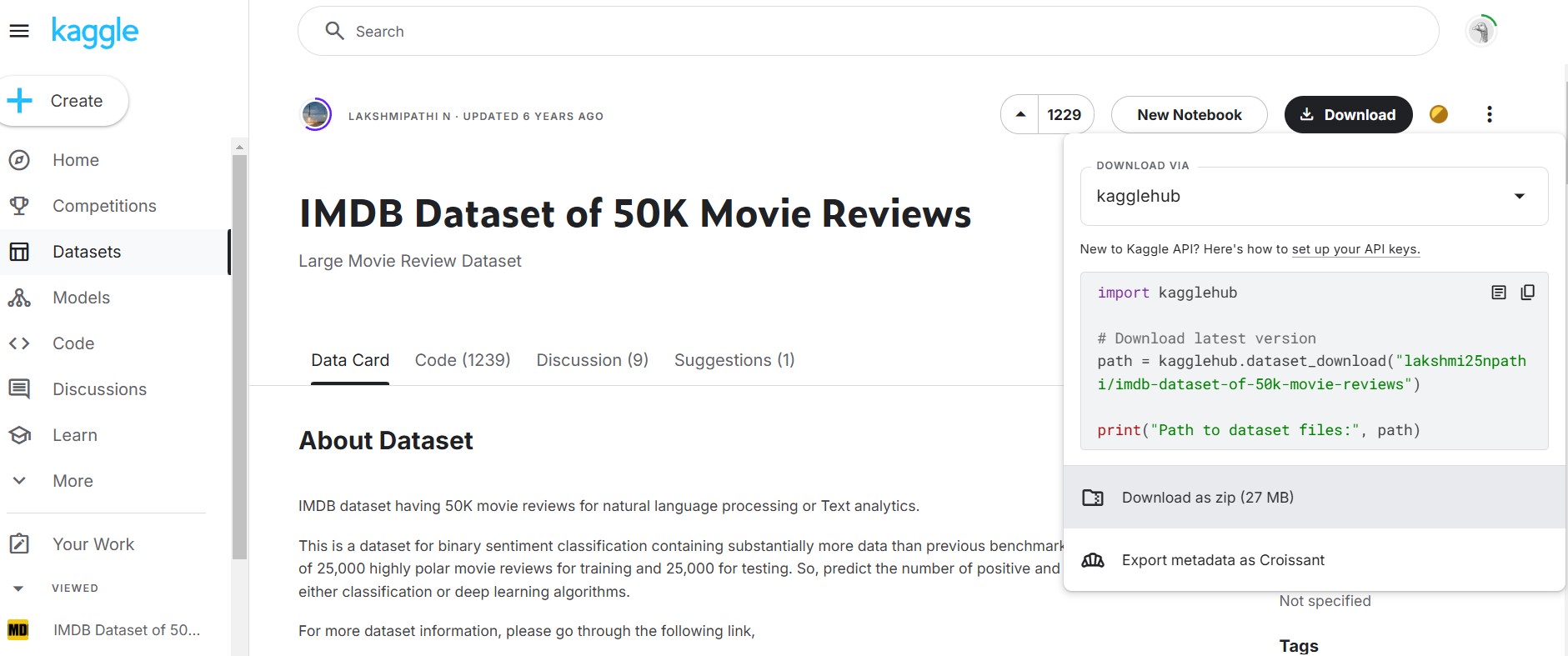
After downloading and extracting the zip file, lets head to Google Collab and create a notebook. Though I will be providing a notebook for easy understanding but I’ll recommend one must try it own their on for better hands on approach.
Below I have created a notebook “data_preprocessing.ipynb”. Upload your dataset “IMDB dataset.csv” to the notebook by right clicking inside Files folder option in navbar on the left.
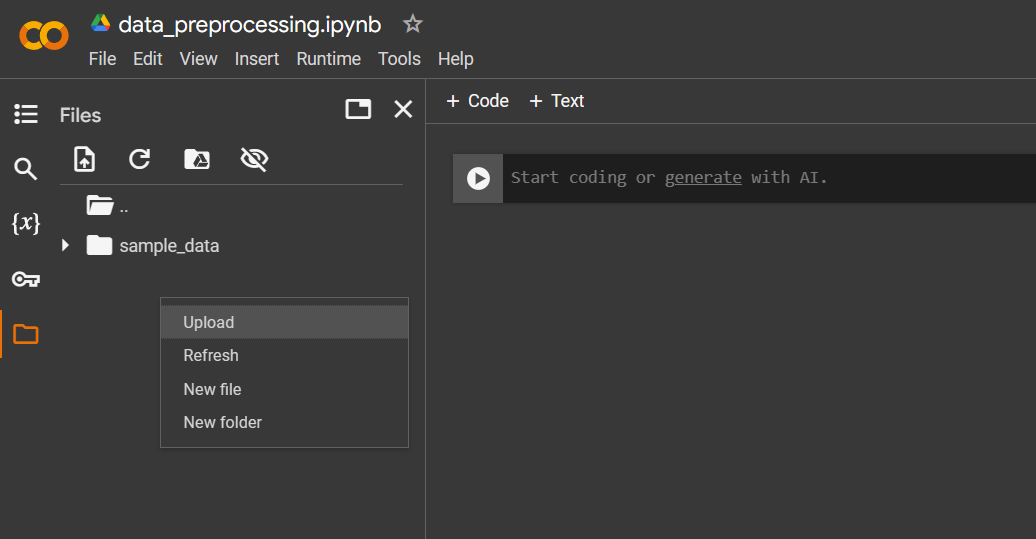
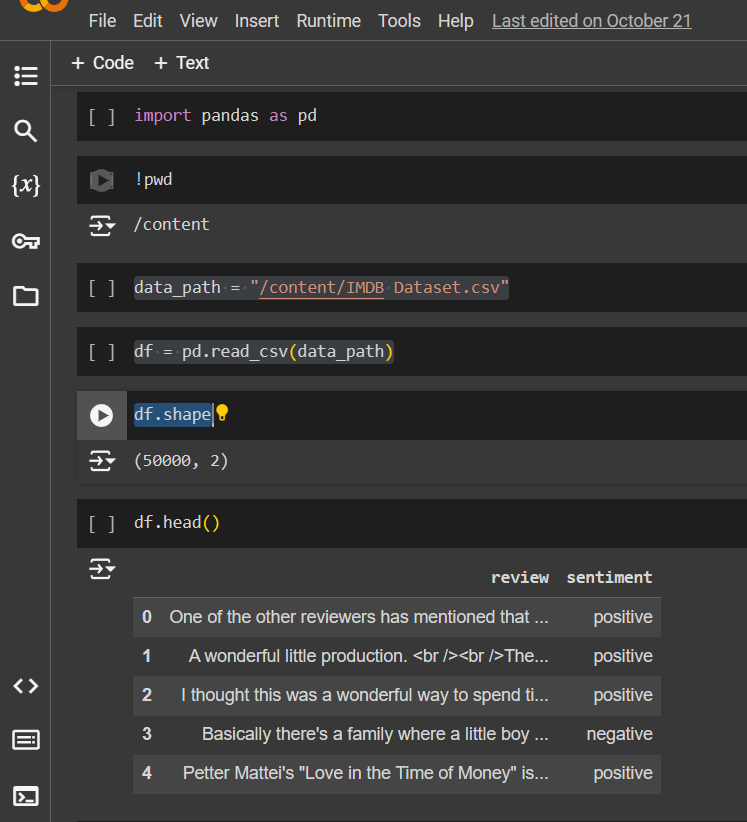
Execute the following commands in notebook to load the dataset and show.
# Pandas help load CSV file
import pandas as pd
# Check your present working directory
!pwd
# set your file path to the current working directory
data_path = "/content/IMDB Dataset.csv"
# Load the data ⬇
df = pd.read_csv(data_path)
# Shape of the data -> 50k reviews with 2 columns - reviews ,sentiment
df.shape
# Show the data
df.head()
Everything is set up and now you are ready to begin with. Let’s Go!
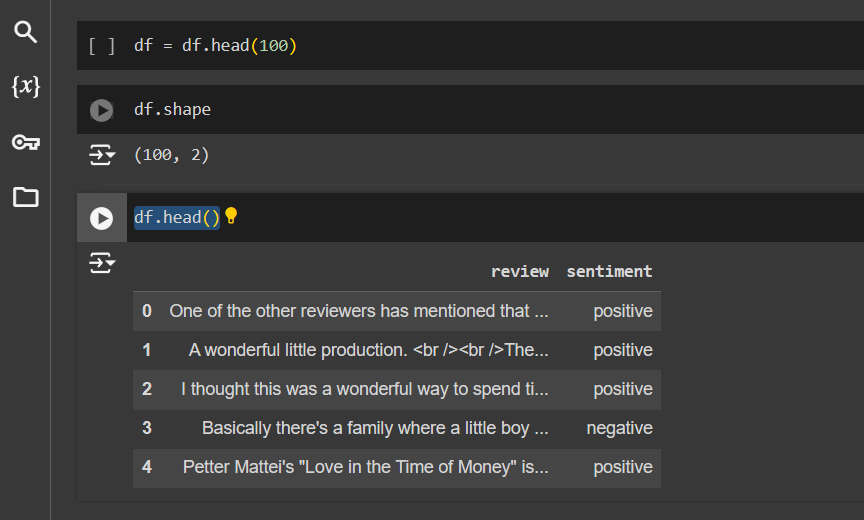
Since making operation on 50k reviews will consume a lot of time and memory, we will operate on first 100 reviews only.
# Load first 100 Examples
df = df.head(100)
# Shape will be (100,2)
df.shape
# Show the data
df.head()
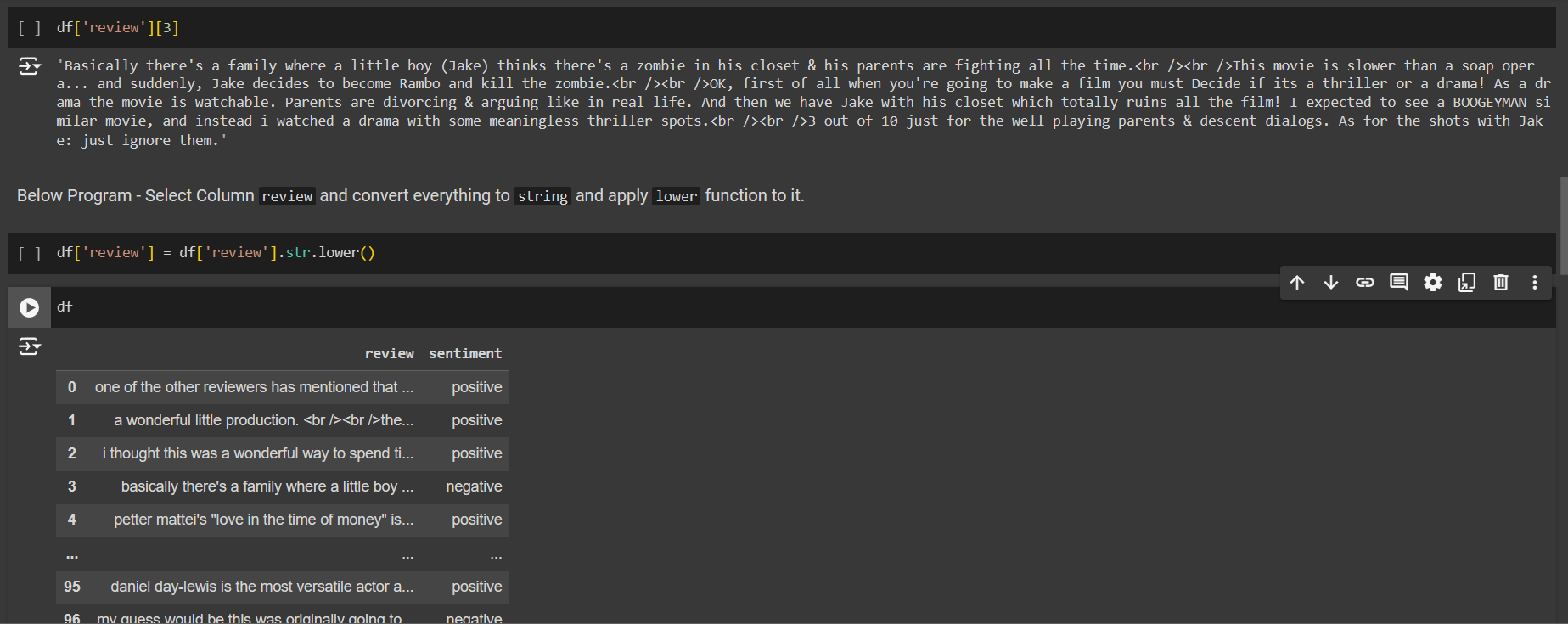
Lowercase Data
On day 2, we did Data preprocessing technique in which we learned about lowercasing which is to convert all text to lowercase to standardize the data.
# Take row 3 in review column, Notice some uppercase characters.
df['review'][3]
# convert everything to string then lower() operation on review column
df['review'] = df['review'].str.lower()
# show all the data
df
# show our new Row 3 with all lowercase
df['review'][3]

Remove <HTML> tags
Now, we will practice how to remove the html tags in data preprocessing.
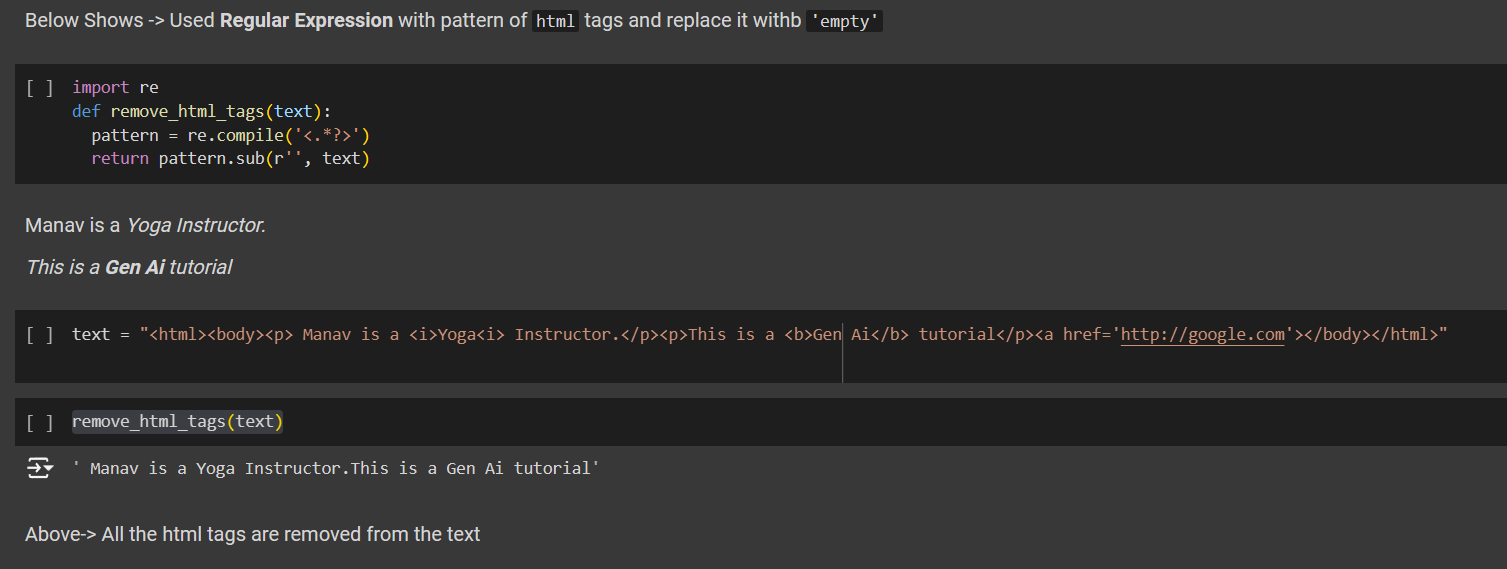
Let’s create a function named remove_html_tags.
Used Regular Expression with pattern of html tags and replace it with 'empty'
import re
def remove_html_tags(text):
pattern = re.compile('<.*?>')
return pattern.sub(r'', text)
Example:
Manav is a Yoga Instructor.
This is a Gen Ai tutorial
text = "<html><body><p> Manav is a <i>Yoga<i> Instructor.</p><p>This is a <b>Gen Ai</b> tutorial</p><a href='http://google.com'></body></html>"
Now, remove the html tags using
remove_html_tags(text)
# Output
# Manav is a Yoga Instructor.This is a Gen Ai tutorial
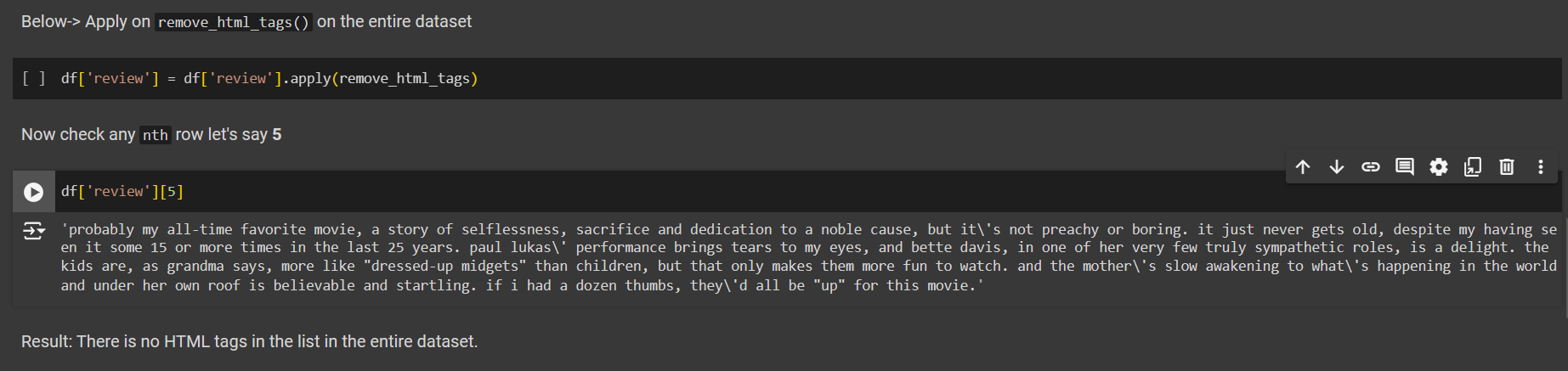
Similarly, we can apply the same function to our dataset
df['review'] = df['review'].apply(remove_html_tags)
This will remove all the html tags in our dataset. Let’s check row number 5.
df['review'][5]
# Output
# probably my all-time favorite movie,....they\'d all be "up" for this movie.
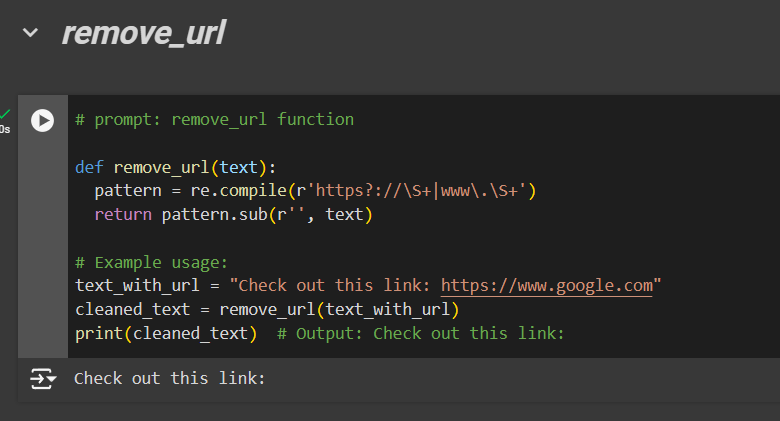
Remove URLs
Similarly, we’ll create a function named remove_url
# prompt: remove_url function
def remove_url(text):
pattern = re.compile(r'https?://\S+|www\.\S+')
return pattern.sub(r'', text)
# Example usage:
text_with_url = "Check out this link: https://www.google.com"
cleaned_text = remove_url(text_with_url)
print(cleaned_text)
# Output: Check out this link:
Punctuation handling
Now let us understand how to remove the punctuations.
import string,time
# to see all types of punctuations
string.punctuation
# that is
# !"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
# all the string punctuations inside the exclude variable
exclude = string.punctuation
exclude
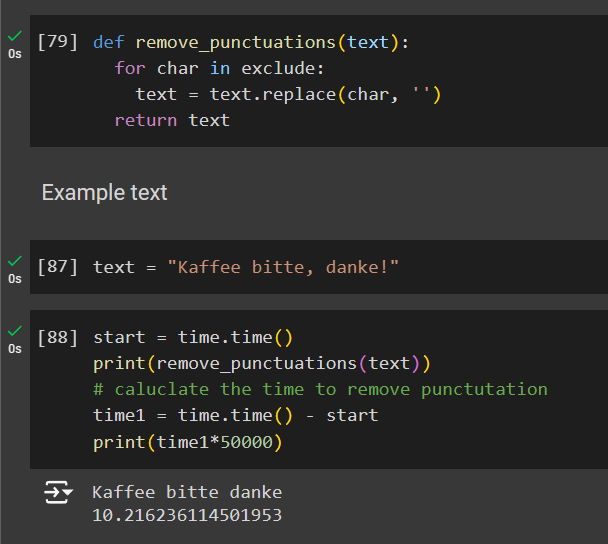
Create a function named remove_punctuations
def remove_punctuations(text):
for char in exclude:
text = text.replace(char, '')
return text
text = 'Kaffee bitte, danke!'
# We will check how much time does it take.
start = time.time()
print(remove_punctuations(text))
# caluclate the time to remove punctutation
time1 = time.time() - start
print(time1*50000)
# output:
# Kaffee bitte danke
# 10.216236114501953
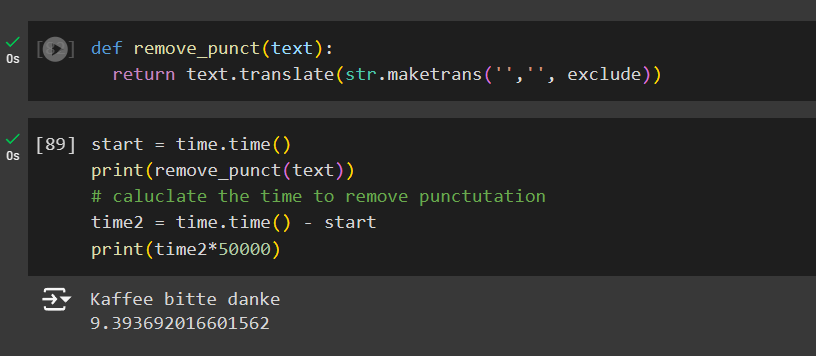
It can also be done using another method with less time as in the function remove_punctuations for loop is used thus resulting in linear time.
Create another function named remove_punct
def remove_punct(text):
return text.translate(str.maketrans('','', exclude))
start = time.time()
print(remove_punct(text))
# caluclate the time to remove punctutation
time2 = time.time() - start
print(time2*50000)
# Kaffee bitte danke
# 9.393692016601562
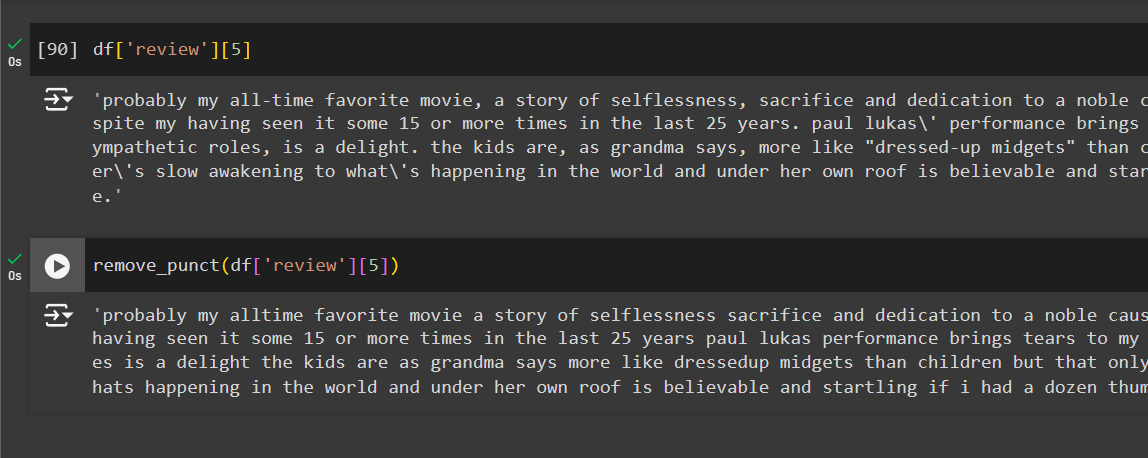
Great, now apply the same function on the dataset and check the result.
df['review'][5] # row number 5
remove_punct(df['review'][5]) # removing punctuations from row 5
# remove_punct(df['review']) # Pass the entire dataset
Chat Conversion Handle
Now, it time to handle the chat conversion written in short. Like the example below is the dictionary of such words
chat_words = {
'AFAIK':'As Far As I Know',
'AFK':'Away From Keyboard',
'ASAP':'As Soon As Possible',
'ATK':'At The Keyboard',
'CUL8R': 'See You Later',
'ATM':'At The Moment'
}
{ # Some other example to make in dictionary
"FYI: For Your Information",
"ASAP: As Soon As Possible",
"BRB: Be Right Back",
"FAQ: Frequently Asked Questions",
"IMBD: Internet Movie Database",
"LOL: Laugh Out Loud",
"BTW: By The Way",
"CU: See You",
"CUL8R: See You Later",
"CYA: See You Again",
"TTYL: Talk to Youb later"
}
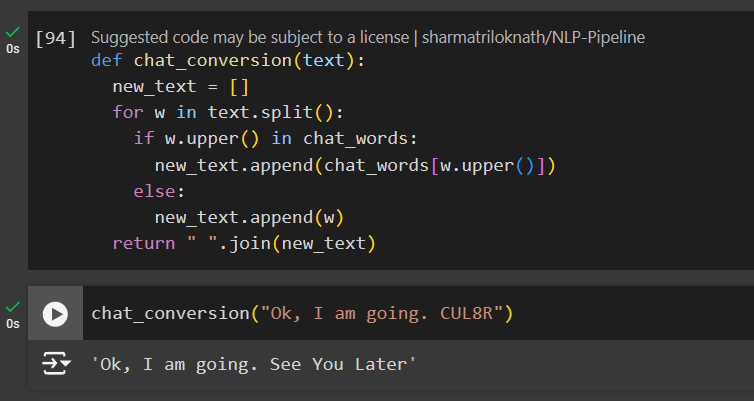
Create a function named chat_conversion and check if the chat words are there in our dictionary.
def chat_conversion(text):
new_text = []
for w in text.split():
if w.upper() in chat_words:
new_text.append(chat_words[w.upper()])
else:
new_text.append(w)
return " ".join(new_text)
Let’s test this function
chat_conversion("Ok, I am going. CUL8R")
Incorrect Text Handling
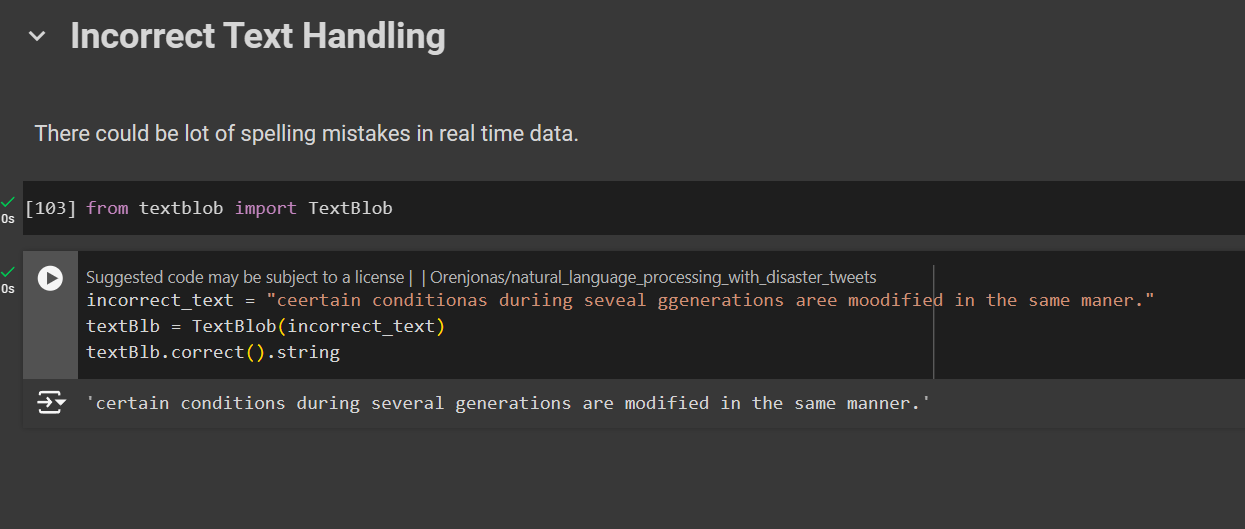
Sometime there could be mistakes during a real time conversations, so to handle these we will use TextBlob
from textblob import TextBlob
# Incorrect Text
incorrect_text = "ceertain conditionas duriing seveal ggenerations aree moodified in the same maner."
textBlb = TextBlob(incorrect_text)
textBlb.correct().string
Stopwords
You should remove these tokens only if they don't add any new information for your problem.
from nltk.corpus import stopwords
import nltk
nltk.download('stopwords')
# List down all the stopwords in English
stopwords.words('english')
len(stopwords.words("english")) # 179 total
So how does it really works?
Example :
Sentence: I practice Yoga almost everyday. I love Yoga.
We can understand the sentiment of the sentence by the words
practice, yoga, everyday, loveRest of the words are the stopwords which when removed the sentiment of the text remains the same. Hence reducing dimensionality.
Let’s test this function
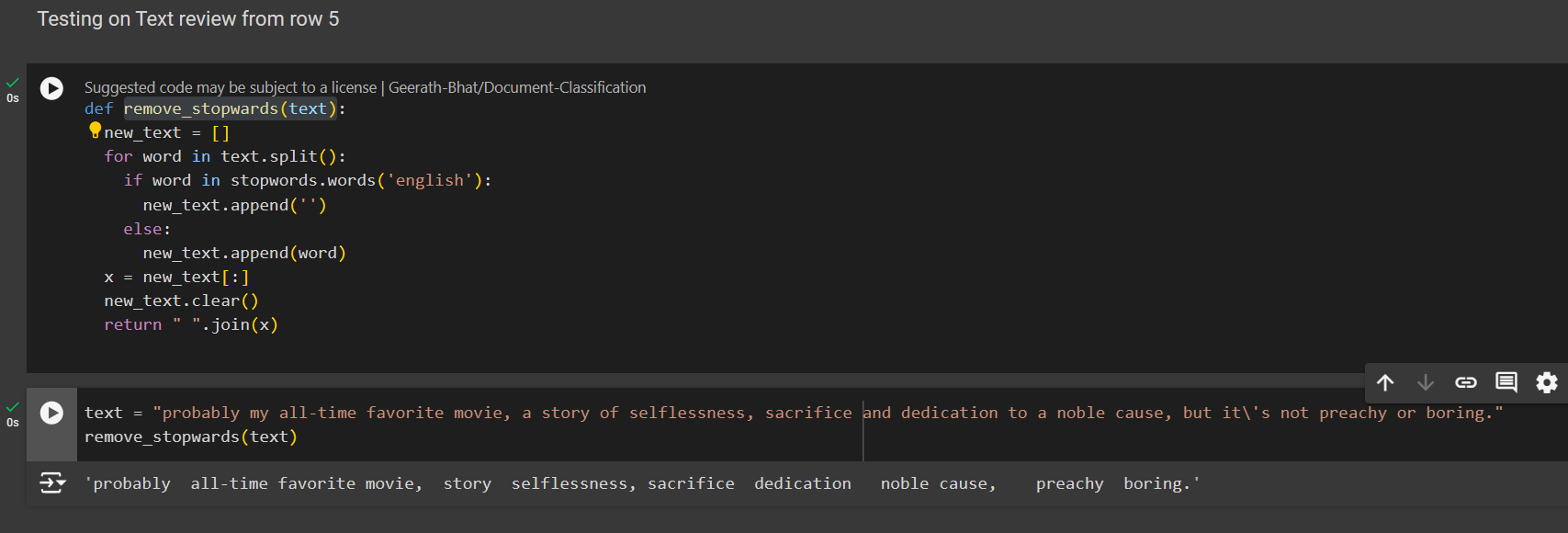
def remove_stopwards(text):
new_text = []
for word in text.split():
if word in stopwords.words('english'):
new_text.append('')
else:
new_text.append(word)
x = new_text[:]
new_text.clear()
return " ".join(x)
Test it on any row or the entire dataset you want like I did on Row number 5.
# To apply on the entire dataset (demo)
df["review"].apply(remove_stopwords)
# To permanent apply on the dataset
df["review"] = df["review"].apply(remove_stopwords)
Emoji Handling
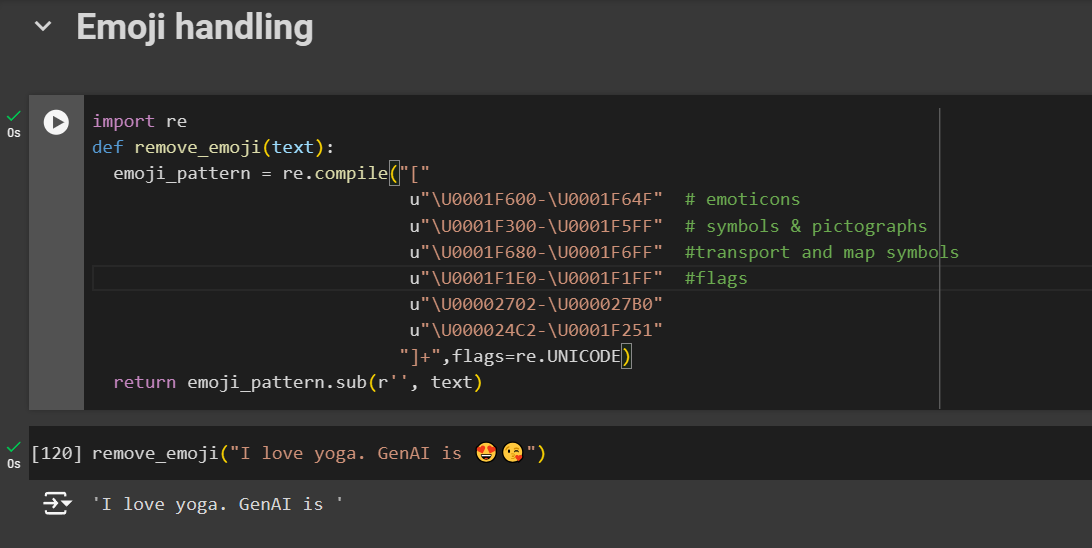
Emojis are uni-code characters.
import re
def remove_emoji(text):
emoji_pattern = re.compile("["
u"\U0001F600-\U0001F64F" # emoticons
u"\U0001F300-\U0001F5FF" # symbols & pictographs
u"\U0001F680-\U0001F6FF" #transport and map symbols
u"\U0001F1E0-\U0001F1FF" #flags
u"\U00002702-\U000027B0"
u"\U000024C2-\U0001F251"
"]+",flags=re.UNICODE)
return emoji_pattern.sub(r'', text)
remove_emoji("I love yoga. GenAI is 😍😘")
# Output : I love yoga. GenAI is
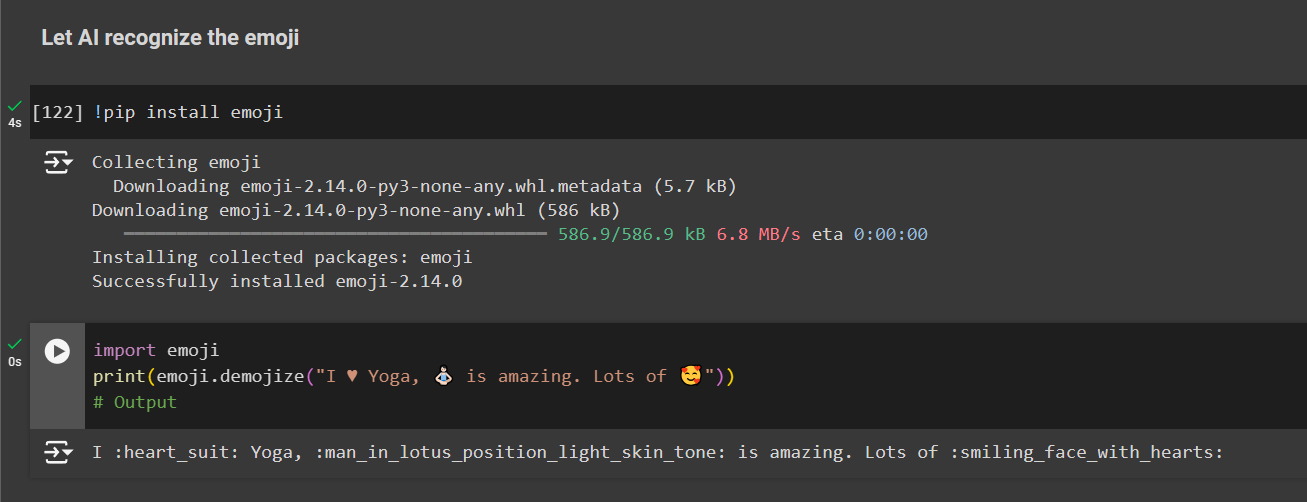
But what if emojis are required. Like when you type an emoji in Chatgpt or Gemini they tend to know the meaning of it. How can we achieve that?
!pip install emoji
demojize : extract the meaning of emojis
import emoji
print(emoji.demojize("I ♥ Yoga, 🧘🏻♂️ is amazing. Lots of 🥰"))
Tokenization
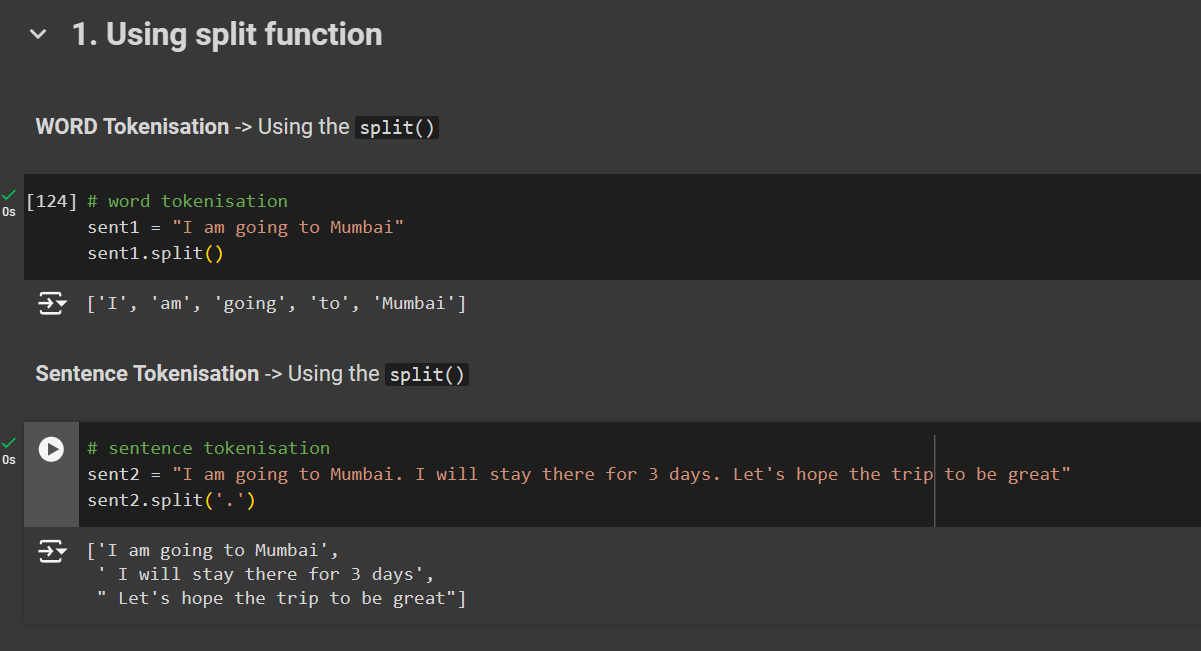
1. Using split( ) function
- Word Tokenization
# word tokenisation
sent1 = "I am going to Mumbai"
sent1.split()
- Sentence Tokenization
# sentence tokenisation
sent2 = "I am going to Mumbai. I will stay there for 3 days. Let's hope the trip to be great"
sent2.split('.')
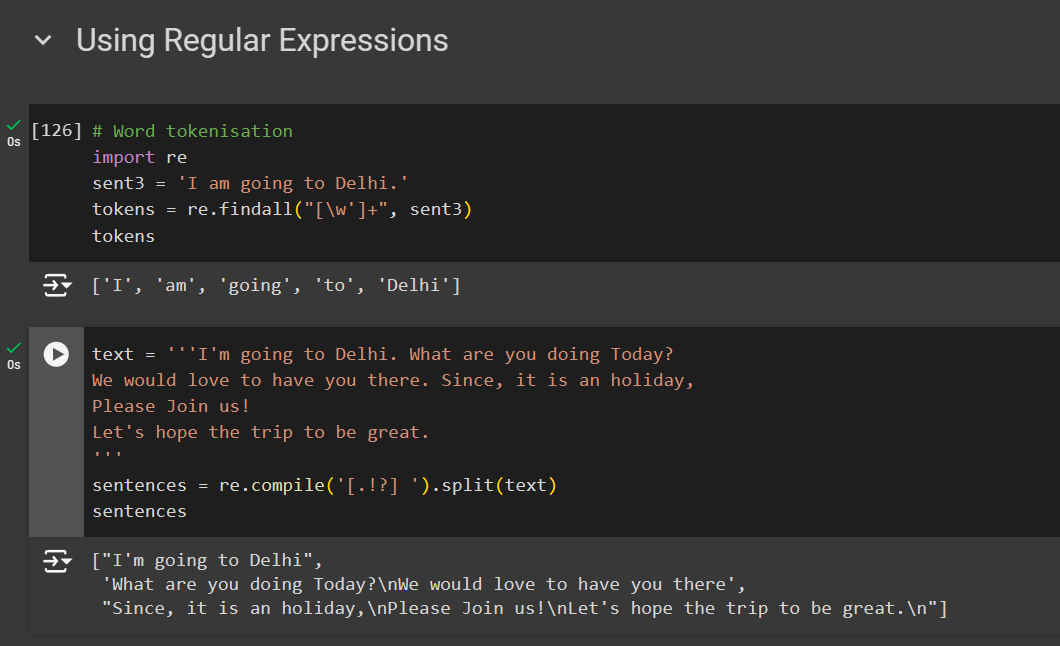
2. Using Regular Expression
- Word Tokenization
# Word tokenisation
import re
sent3 = 'I am going to Delhi.'
tokens = re.findall("[\w']+", sent3)
tokens
- Sentence Tokenization
# sentence tokennisation
text = '''I'm going to Delhi. What are you doing Today?
We would love to have you there. Since, it is an holiday,
Please Join us!
Let's hope the trip to be great.
'''
sentences = re.compile('[.!?] ').split(text)
sentences
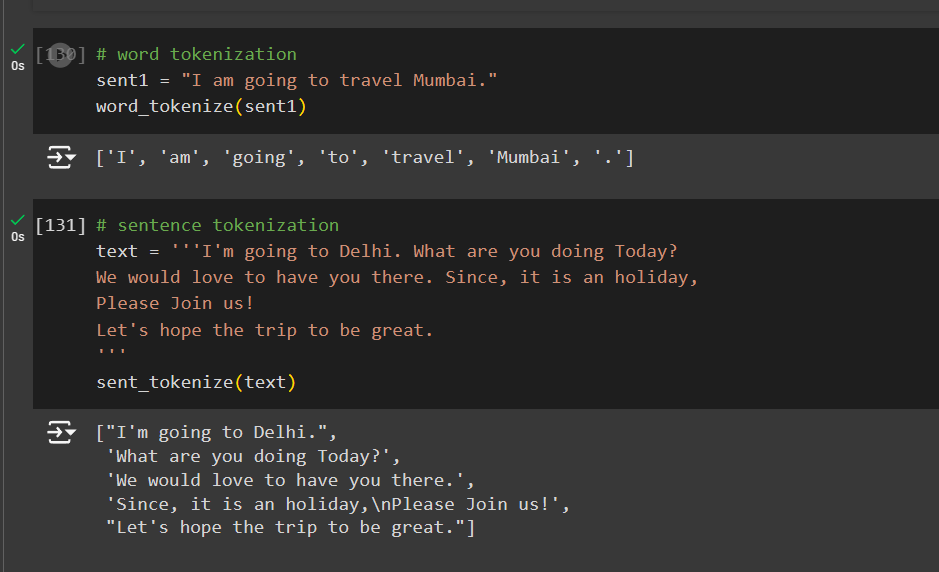
3. Using NLTK
from nltk.tokenize import word_tokenize, sent_tokenize
import nltk
nltk.download('punkt')
# word tokenize
sent1 = "I am going to travel Mumbai.
word_tokenize(sent1)
# sentence tokenize
text = '''I'm going to Delhi. What are you doing Today?
We would love to have you there. Since, it is an holiday,
Please Join us!
Let's hope the trip to be great.
'''
sent_tokenize(text)
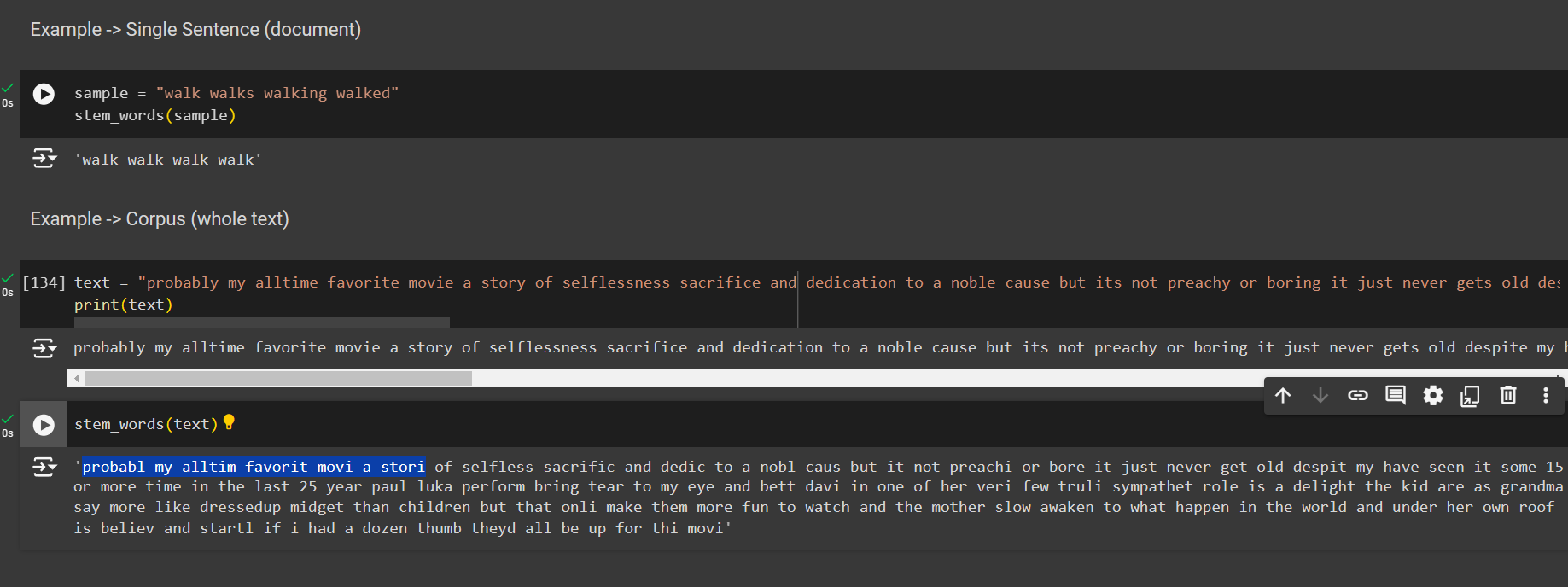
Stemming
It is faster, thus sometimes produce compromising results.
from nltk.stem.porter import PorterStemmer
ps = PorterStemmer()
def stem_words(text):
return " ".join([ps.stem(word) for word in text.split()])
sample = "walk walks walking walked"
stem_words(sample)
# output
# walk walk walk walk
Here you will notice that not all the words makes sentence when using stemming data preprocessing technique.
text = "probably my alltime favorite movie a story of selflessness sacrifice and dedication to a noble cause but its not preachy or boring it just never gets old despite my having seen it some 15 or more times in the last 25 years paul lukas performance brings tears to my eyes and bette davis in one of her very few truly sympathetic roles is a delight the kids are as grandma says more like dressedup midgets than children but that only makes them more fun to watch and the mothers slow awakening to whats happening in the world and under her own roof is believable and startling if i had a dozen thumbs theyd all be up for this movie"
print(text)
# Ouput
# probabl my alltim favourit....
So we need something that converts the text into their root words and also makes sense. Thus, we came with the concept of lemmatization.
Lemmatization
It is slower than stemmering but the results are way better.
import nltk
from nltk.stem import WordNetLemmatizer
import nltk
nltk.download('wordnet')
nltk.download('omw-1.4')
wordnet_lemmatizer = WordNetLemmatizer()
#------------------------------------------
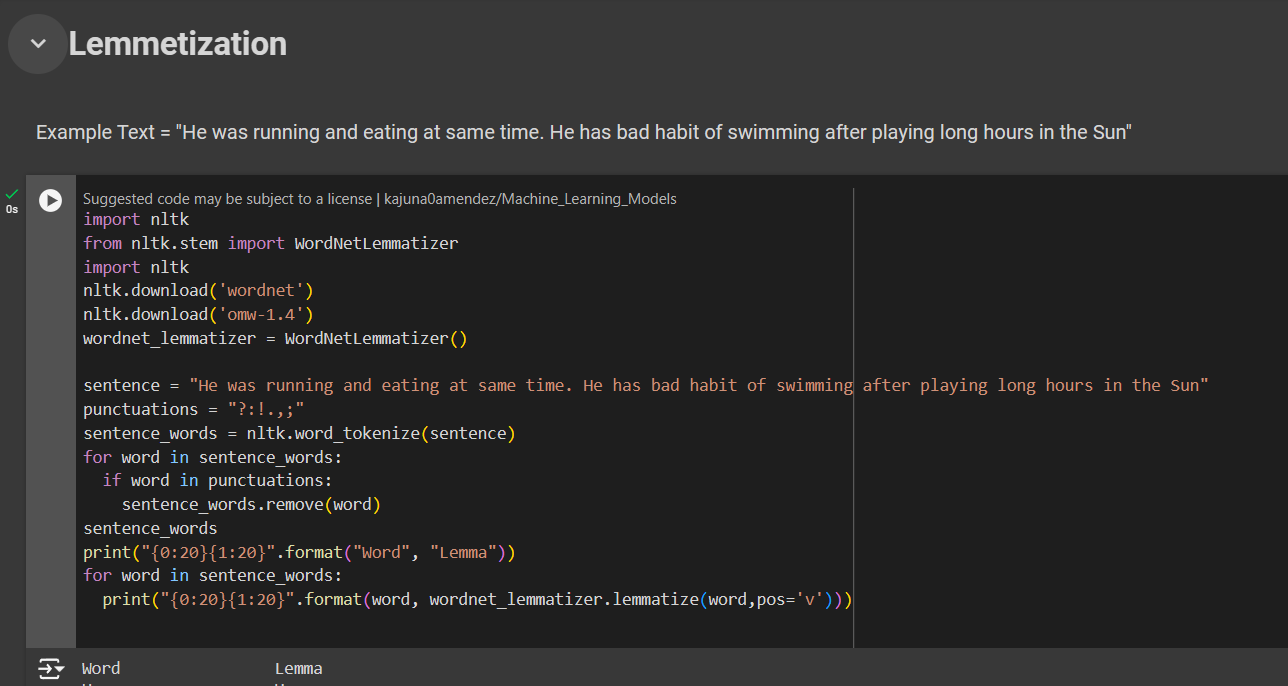
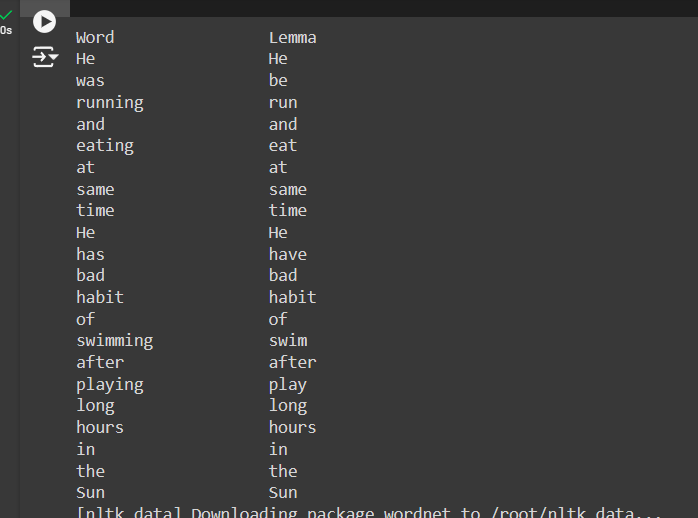
sentence = "He was running and eating at same time. He has bad habit of swimming after playing long hours in the Sun"
punctuations = "?:!.,;"
sentence_words = nltk.word_tokenize(sentence)
for word in sentence_words:
if word in punctuations:
sentence_words.remove(word)
sentence_words
#------------------------------------------
print("{0:20}{1:20}".format("Word", "Lemma"))
for word in sentence_words:
print("{0:20}{1:20}".format(word, wordnet_lemmatizer.lemmatize(word,pos='v')))
🎉That's a wrap for Day 4!
Practice these and let me know if you have any doubts.
In our next post, we'll learn data representation techniques. Stay tuned for more insights and exciting experiments!
▶ Next → Day 5 : Build a Full Stack Web Apps in Minutes.
▶ Full Playlist : Master GenAI Series
⭐Github Repo : Journey Roadmap
Subscribe to my newsletter
Read articles from Manav Paul directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Manav Paul
Manav Paul
24, Documenting my journey of DevOps | GenAI | Blockchain | NFTs