Implement Medallion architecture with SCD Type 2 in Microsoft Fabric - Part 1
 Sachin Nandanwar
Sachin Nandanwar
This article is part one of a two-part series on implementing Medallion architecture in Microsoft Fabric.
In the first part, we will see how to push data from its raw format to a Bronze layer and the fundamental steps involved in this initial transformation process and cleansing and moving this data to the Silver layer.
In the second part we will see how to move data across to the Gold layer where most of the complex transformations and aggregations occurs to prepare the data for end user analysis.
At the end of this article, I have included a YouTube video where I demonstrate the end-to-end testing of the entire process.
Please note that in this article I wont go into details highlighting the underlying concepts of the Medallion architecture. You can refer to the following link to get an understanding.
https://learn.microsoft.com/en-us/azure/databricks/lakehouse/medallion
Below is a schematic representation of a typical Medallion architecture.
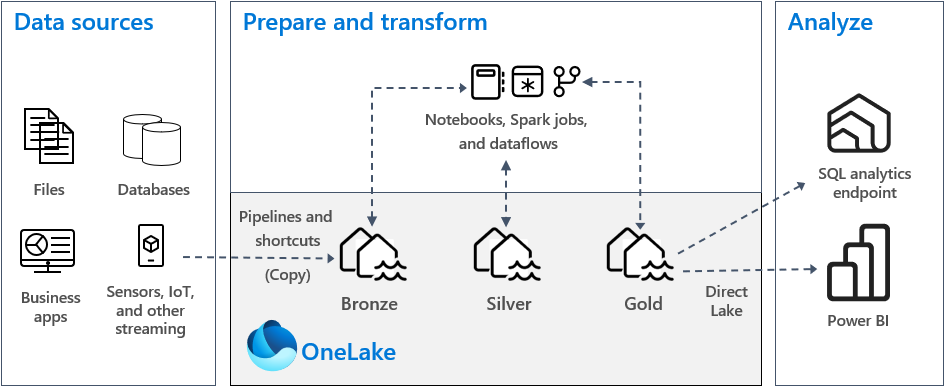
Image credit Microsoft
An important point that I would like to highlight is that most people think that the concept of Medallion architecture is relatively new but that is not the case. The idea of a Bronze layer (loading layer),Silver Layer(staging layer),Gold Layer(analytics or presentation layer) has always existed for decades. For example when you take the traditional data warehouses implementation say using MSBI suite, there always existed a loading layer(often on server drives or an RDBMS like SQL Server),staging layer(SSIS layer) and the analytics layer(SSAS cubes).
In this article we will cover few scenarios:
Data Ingestion: Loading raw data from csv file into the bronze layer.
Data Cleansing: Removing duplicates and validating the formats to ensure data consistency.
SCD implementation: Setting SCD Type 2 implementation in the data lake.
Dimension Modelling: Setting up base data for dimension model for the Gold layer.
I personally am a strong proponent of implementing Data warehouse instead of a Data lake at the Gold layer . This is because the purpose of the Gold layer is to provide highly structured, refined, and reliable data and often is quite easy to implement Data governance and controlled access to the refined data through Object and Row level security and Kimball dimensional design to serve BI workloads compared to Data lake.
Use Case
I will use a use case from a few years ago when I worked on an MSBI project.
The client’s system provided data through a CSV files sent over an SFTP. The client was adamant that he would not segregate the data into master and transactional data at his end so the data that was sent across consisted a mix of both. This needed a creation of a flow to identify and appropriately segregate the master and transactional data. The solution was implemented using the MSBI suite, with SSIS for the ETL layer, SSAS cubes for the analytical layer, and Power BI for reporting. The data warehouse was built in SQL Server 2016, utilizing a star schema with Type 2 Slowly Changing Dimensions (SCD2).
I will use a more simplified version of the use case though it was much more complex and involved numerous business logic checks and balances. I will use a small subset of the data. The data had the following columns
SalesOrder,CustomerName,CustomerEmail,CustomerRegion,ProductName,Category,Supplier,Date,Quantity,UnitPrice,TotalSales
Looking at the those attributes we can estimate that there could supposedly be four entities that could be identified as master(dimensional)data and one entity as a transactional(fact)data.
Let’s Start
To get started implement the following steps :
Create a new workspace
Create the two Fabric Lake houses (Bronze and Silver)
Move the raw data into the bronze layer through an automated process
Deduplicate, Transform and Segregate the data in the silver layer though Fabric Notebook using Pyspark.
In the first step we have to upload the raw data to the Bronze layer. This could be done manually or can be automated. I created a small C# and a PowerShell script to automate the process .You can chose either of them based on your preference. But before that you would have to first register on entra.microsoft.com and get the tenantId .The step by step process can be found here .
I will be using the existing Fabric MSAL Service Principal from my Entra.
Also ensure that you have granted at least the Contributor access to the underlying workspace
To use the PowerShell script install the following dependencies
Install-Module -Name Az -AllowClobber -Force
Install-Module -Name Az.Resources -AllowClobber -Force
Install-Module -Name Az.Storage -AllowClobber -Force
Then use the following script to automate the file upload process
$tenantId = 'Service Principal Tenant Id'
$workspaceGUID = 'Your Medallion Workspace GUID'
$lakehouseGUID = 'Bronze Layer GUID'
$localFolderPath = 'local directory path of the source csv file'
$localFiles = @('medallion_data.csv') #local file to be uploaded to the Bronze Layer
$uploadFolderPath = '/Files/' #files on the broze layer lakehouse
Connect-AzAccount -TenantId $tenantId | out-null
$ctx = New-AzStorageContext -StorageAccountName 'onelake' -UseConnectedAccount -endpoint 'fabric.microsoft.com'
$Files = Get-ChildItem -Path $localFolderPath
foreach ($f in $Files)
{
$uploadPath = $lakehouseGUID + $uploadFolderPath + $f
$localPath = $localFolderPath + $f
New-AzDataLakeGen2Item -Context $ctx -FileSystem $workspaceGUID -Path $uploadPath -Source $localPath -Force | out-null
$TextOutput = "Uploaded file " + $f + " successfully"
Write-Output $TextOutput
}
If you prefer C# application then you could use the following code. More detailed workings of the code is available on one of my other article. Ensure you have all the necessary Nuget packages referenced in the code.
using Azure.Identity;
using Azure.Storage.Files.DataLake;
using Azure.Storage.Files.DataLake.Models;
namespace UploadFileToFabric
{
internal class Program
{
private static string clientId = "Application (client) ID"
private static string tenantId = "Directory (tenant) ID";
private static string clientSecret = "Client Secret";
private static string workspaceName = "Medallion Architecture";
private static string lakeHouse = "Bronze_Layer";
private static ClientSecretCredential credential;
private static string endpoint = $"https://onelake.dfs.fabric.microsoft.com";
private static DataLakeServiceClient datalake_Service_Client;
private static DataLakeFileSystemClient dataLake_FileSystem_Client;
static async Task Main(string[] args)
{
ReturnCredentials(endpoint);
datalake_Service_Client = new DataLakeServiceClient(new Uri(endpoint), credential);
dataLake_FileSystem_Client = datalake_Service_Client.GetFileSystemClient(workspaceName);
await UploadFiles(endpoint, "E:\\Medallion_Data");
}
static async Task ReturnCredentials(string baseUrl)
{
credential = new ClientSecretCredential(tenantId, clientId, clientSecret);
}
public static async Task UploadFiles(string endpoint, string uploadfrom)
{
DirectoryInfo d = new DirectoryInfo(uploadfrom);
DataLakeDirectoryClient dataLake_DirClient = dataLake_FileSystem_Client.GetDirectoryClient($"{lakeHouse}.Lakehouse/Files");
foreach (FileInfo file in d.GetFiles())
{
DataLakeFileClient fileToUploadClient = dataLake_DirClient.CreateFile(file.Name);
FileStream fileStream = System.IO.File.OpenRead(file.FullName);
await fileToUploadClient.AppendAsync(fileStream, offset: 0);
await fileToUploadClient.FlushAsync(position: fileStream.Length);
}
await foreach (PathItem pathItem in dataLake_DirClient.GetPathsAsync(recursive: true))
{
System.Console.WriteLine($"Uploaded file: {pathItem.Name}");
}
}
}
}
The Code
Now that we have all set we first create a new notebook under the Bronze Layer. Add the following dependencies and code in the NoteBook.
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
from delta.tables import DeltaTable
## Start a new Spark session
spark = SparkSession.builder \
.appName("Fabric Medallion Architecture") \
.getOrCreate()
Define a schema based on the incoming attributes of your source data
schema = StructType([
StructField("OrderNumber", IntegerType(), True),
StructField("CustomerName", StringType(), True),
StructField("CustomerEmail", StringType(), True),
StructField("CustomerRegion", StringType(), True),
StructField("ProductName", StringType(), True),
StructField("Category", StringType(), True),
StructField("Supplier", StringType(), True),
StructField("Date", IntegerType(), True),
StructField("Quantity", IntegerType(), True),
StructField("UnitPrice", DecimalType(), True),
StructField("TotalSales", IntegerType(), True)])
Load the csv file data from the Bronze layer into a data frame .The data frame in this case is df_sales
df_sales = spark.read.load(
"abfss://Your bronze layer file location@onelake.dfs.fabric.microsoft.com/xxxxx-xxxxx-xxxx-xxx-b13cf9aaxxxx/Files/yourfile.csv",
format="csv",
options={"header": "true", "inferSchema": "true"},
schema=schema
)
Deduplicate the incoming data
##Identify and discard the duplicates from the initial load dataframe
duplicates_df = df_sales.groupBy("OrderNumber","CustomerName", "CustomerEmail","CustomerRegion",\
"ProductName", "Category", "Supplier", "Date", "Quantity", "UnitPrice", "TotalSales").count().filter("count > 1")
## Move duplicate rows to a new delta lake table "Duplicates" in the Silver layer for further analysis
duplicates_df.write.mode("append").format("delta").save("Tables/Duplicates")
## Drop the duplicates from the original sales dataframe
df_sales = df_sales.dropDuplicates()
Validate the email formats of column CustomerEmail and push the invalid rows to another delta lake table called ErrorRecords marking them with the custom error message Invalid Email Format under the ErrorRecords delta lake table
def validate_email(df_sales):
email_regex=r'^[\w\.-]+@[\w\.-]+\.\w+$'
df_invalid_emails = df_sales.filter(~col("CustomerEmail").rlike(email_regex))
df_sales_final = df_sales.exceptAll(df_invalid_emails)
df_invalid_emails = df_invalid_emails.withColumn("Error", lit('Invalid Email Format'))
df_invalid_emails.write.mode("append").format("delta").save("Tables/ErrorRecords")
return df_sales_final
You could implement additional business rules to validate the incoming data, such as checking the numeric columns. If any invalid rows are found, you can move them to the ErrorRecords delta table along with a relevant custom error message under the Error coulmn.
Next, we create a function that performs a bunch of miscellaneous data transformations on the original data frame df_sales. In this case it renames the incoming column ProductName to Product and inserts a new column OperationDate to track the data insertion/updation across the rows.
def miscellaneous_function(df_sales_final):
df_sales_final = df_sales_final.withColumnRenamed("ProductName", "Product")
df_sales_final = df_sales_final.withColumn("OperationDate", current_timestamp())
df_sales_final=df_sales_final.filter(df_sales_final.Category != "Category")
return df_sales_final
Call to the above two functions
df_sales_final = validate_email(df_sales)
df_sales_final = miscellaneous_function(df_sales_final)
Next we have to determine if the data load to the delta table is first or an incremental load. To identify that, we set a Boolean variable to check if the delta table exist. If not then it would mean that the data load is the first load.
## We set the path of the Sales table in the Silver layer to a variable sales_table_path
sales_table_path = "Tables/Sales"
if spark.catalog.tableExists("Sales"):
FirstLoad = False
else:
FirstLoad = True
Now that we can identify the type of load , we perform the underlying operation.
For example if the load type is a first load then we create the delta table sales and if not then we perform upsert operation. Incase of updates we move the original data to an archive table prior to performing the update. This way we satisfy the SCD Type 2 criteria. We could implement SCD Type 2 in the Gold layer but I personally would prefer that the Gold layer consists only of operational data. But again that’s just my personal opinion.
##Check if its a first load and create the delta table
if FirstLoad == True:
df_sales_final.write.mode("overwrite").format("delta").save(sales_table_path)
sales_table = DeltaTable.forPath(spark, sales_table_path)
else :
sales_table = DeltaTable.forPath(spark, sales_table_path)
sales_table_df = sales_table.toDF()
## as it is an incremental load first identify the rows that would be affected
## and move them to Archive table to satisfy SCD type 2
changes_df = df_sales_final.alias("sales_new_data") \
.join(
sales_table_df.alias("sales_existing_data"),
on="OrderNumber",
how="inner"
).filter(
(col("sales_new_data.CustomerName") != col("sales_existing_data.CustomerName")) |
(col("sales_new_data.CustomerEmail") != col("sales_existing_data.CustomerEmail")) |
(col("sales_new_data.CustomerRegion") != col("sales_existing_data.CustomerRegion")) |
(col("sales_new_data.Product") != col("sales_existing_data.Product")) |
(col("sales_new_data.Category") != col("sales_existing_data.Category")) |
(col("sales_new_data.Supplier") != col("sales_existing_data.Supplier")) |
(col("sales_new_data.Date") != col("sales_existing_data.Date")) |
(col("sales_new_data.Quantity") != col("sales_existing_data.Quantity")) |
(col("sales_new_data.UnitPrice") != col("sales_existing_data.UnitPrice")) |
(col("sales_new_data.TotalSales") != col("sales_existing_data.TotalSales"))
).select("sales_existing_data.*")
changes_df.write.mode("append").format("delta").save("Tables/Archive")
##Perform the upsert operation.
sales_table.alias("sales_existing_data").merge(
source = df_sales_final.alias("sales_new_data"),
condition = "sales_existing_data.OrderNumber = sales_new_data.OrderNumber"
)\
.whenMatchedUpdate( condition= "sales_existing_data.CustomerName!= sales_new_data.CustomerName OR "
"sales_existing_data.CustomerEmail != sales_new_data.CustomerEmail OR "
"sales_existing_data.CustomerRegion != sales_new_data.CustomerRegion OR "
"sales_existing_data.Product != sales_new_data.Product OR "
"sales_existing_data.Category != sales_new_data.Category OR "
"sales_existing_data.Supplier != sales_new_data.Supplier OR "
"sales_existing_data.Date != sales_new_data.Date OR "
"sales_existing_data.Quantity != sales_new_data.Quantity OR "
"sales_existing_data.UnitPrice != sales_new_data.UnitPrice OR "
"sales_existing_data.TotalSales != sales_new_data.TotalSales OR ",
set =
{
"sales_existing_data.CustomerName": "sales_new_data.CustomerName",
"sales_existing_data.CustomerEmail": "sales_new_data.CustomerEmail",
"sales_existing_data.CustomerRegion": "sales_new_data.CustomerRegion",
"sales_existing_data.Product": "sales_new_data.Product",
"sales_existing_data.Category": "sales_new_data.Category",
"sales_existing_data.Supplier": "sales_new_data.Supplier",
"sales_existing_data.Date": "sales_new_data.Date",
"sales_existing_data.Quantity": "sales_new_data.Quantity",
"sales_existing_data.UnitPrice": "sales_new_data.UnitPrice",
"sales_existing_data.TotalSales": "sales_new_data.TotalSales",
"sales_existing_data.OperationDate": current_timestamp()
}
)\
.whenNotMatchedInsertAll().execute()
A quick double check to ensure that if the header column from the source file is inserted as a row into the delta table, then delete that row.
sales_table.delete(condition = col("Category") == "Category")
Now that we have the cleansed data with SCD Type 2 implemented we can move ahead to create the master/dimension staging data in the Silver layer. The basic goal to this approach is to separate the dimension data so that it serves as the base source for dimensional entities in the Gold layer.
We are reloading the entire data across these entities as there aren’t any identifiable attributes to perform upserts on this type of data.
##Create Customer table
def createcustomer_table():
schema = StructType([StructField("CustomerName", StringType(), True),
StructField("CustomerEmail", StringType(), True),
StructField("CustomerRegion", StringType(), True)])
customer_df = spark.createDataFrame([], schema)
customer_df=spark.read.load(sales_table_path).select("CustomerName","CustomerEmail","CustomerRegion").distinct()\
.withColumn("DateTimeInserted",current_timestamp())
customer_table_path = "Tables/Customer"
customer_df.write.mode("overwrite").format("delta").save(customer_table_path)
##Create Category table
def createcategory_table():
schema = StructType([StructField("Category", StringType(), True),
StructField("DateTimeInserted", TimestampType(), True)])
category_df = spark.createDataFrame([], schema)
category_df=spark.read.load(sales_table_path).select("category").distinct()\
.withColumn("DateTimeInserted",current_timestamp())
category_table_path = "Tables/Category"
category_df.write.mode("overwrite").format("delta").save(category_table_path)
#Create Product table
def createproduct_table():
schema = StructType([StructField("Product", StringType(), True),
StructField("DateTimeInserted", TimestampType(), True)])
product_df = spark.createDataFrame([], schema)
product_df=spark.read.load(sales_table_path).select("product").distinct()\
.withColumn("DateTimeInserted",current_timestamp())
product_table_path = "Tables/Product"
product_df.write.mode("overwrite").format("delta").save(product_table_path)
#Create Supplier table
def createsupplier_table():
schema = StructType([StructField("Supplier", StringType(), True),
StructField("DateTimeInserted", TimestampType(), True)])
supplier_df = spark.createDataFrame([], schema)
supplier_df=spark.read.load(sales_table_path).select("supplier").distinct()\
.withColumn("DateTimeInserted",current_timestamp())
supplier_table_path = "Tables/Supplier"
supplier_df.write.mode("overwrite").format("delta").save(supplier_table_path)
Call to the above functions
createcustomer_table()
createcategory_table()
createproduct_table()
createsupplier_table()
Complete Source code of the NoteBook
# Welcome to your new notebook
# Type here in the cell editor to add code!
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
from delta.tables import DeltaTable
# Start Spark session
spark = SparkSession.builder \
.appName("Fabric Medallion Architecture") \
.getOrCreate()
schema = StructType([
StructField("OrderNumber", IntegerType(), True),
StructField("CustomerName", StringType(), True),
StructField("CustomerEmail", StringType(), True),
StructField("CustomerRegion", StringType(), True),
StructField("ProductName", StringType(), True),
StructField("Category", StringType(), True),
StructField("Supplier", StringType(), True),
StructField("Date", IntegerType(), True),
StructField("Quantity", IntegerType(), True),
StructField("UnitPrice", DecimalType(), True),
StructField("TotalSales", IntegerType(), True)
])
df_sales = spark.read.load(
"abfss://Your bronze layer file location@onelake.dfs.fabric.microsoft.com/xxxxx-xxxxx-xxxx-xxx-b13cf9aaxxxx/Files/yourfile.csv",
format="csv",
options={"header": "true", "inferSchema": "true"},
schema=schema
)
duplicates_df = df_sales.groupBy("OrderNumber","CustomerName", "CustomerEmail","CustomerRegion",\
"ProductName", "Category", "Supplier", "Date", "Quantity", "UnitPrice", "TotalSales").count().filter("count > 1")
duplicates_df.write.mode("append").format("delta").save("Tables/Duplicates")
df_sales = df_sales.dropDuplicates()
def validate_email(df_sales):
email_regex=r'^[\w\.-]+@[\w\.-]+\.\w+$'
df_invalid_emails = df_sales.filter(~col("CustomerEmail").rlike(email_regex))
df_sales_final = df_sales.exceptAll(df_invalid_emails)
df_invalid_emails = df_invalid_emails.withColumn("Error", lit('Invalid Email Format'))
df_invalid_emails.write.mode("append").format("delta").save("Tables/ErrorRecords")
return df_sales_final
def miscellaneous_function(df_sales_final):
df_sales_final = df_sales_final.withColumnRenamed("ProductName", "Product")
df_sales_final = df_sales_final.withColumn("OperationDate", current_timestamp())
df_sales_final=df_sales_final.filter(df_sales_final.Category != "Category")
return df_sales_final
df_sales_final = validate_email(df_sales)
df_sales_final = miscellaneous_function(df_sales_final)
sales_table_path = "Tables/Sales"
if spark.catalog.tableExists("Sales"):
FirstLoad = False
else:
FirstLoad = True
if FirstLoad == True:
df_sales_final.write.mode("overwrite").format("delta").save(sales_table_path)
sales_table = DeltaTable.forPath(spark, sales_table_path)
else :
sales_table = DeltaTable.forPath(spark, sales_table_path)
sales_table_df = sales_table.toDF()
changes_df = df_sales_final.alias("sales_new_data") \
.join(
sales_table_df.alias("sales_existing_data"),
on="OrderNumber",
how="inner"
).filter(
(col("sales_new_data.CustomerName") != col("sales_existing_data.CustomerName")) |
(col("sales_new_data.CustomerEmail") != col("sales_existing_data.CustomerEmail")) |
(col("sales_new_data.CustomerRegion") != col("sales_existing_data.CustomerRegion")) |
(col("sales_new_data.Product") != col("sales_existing_data.Product")) |
(col("sales_new_data.Category") != col("sales_existing_data.Category")) |
(col("sales_new_data.Supplier") != col("sales_existing_data.Supplier")) |
(col("sales_new_data.Date") != col("sales_existing_data.Date")) |
(col("sales_new_data.Quantity") != col("sales_existing_data.Quantity")) |
(col("sales_new_data.UnitPrice") != col("sales_existing_data.UnitPrice")) |
(col("sales_new_data.TotalSales") != col("sales_existing_data.TotalSales"))
).select("sales_existing_data.*")
changes_df.write.mode("append").format("delta").save("Tables/Archive")
sales_table.alias("sales_existing_data").merge(
source = df_sales_final.alias("sales_new_data"),
condition = "sales_existing_data.OrderNumber = sales_new_data.OrderNumber"
)\
.whenMatchedUpdate( condition= "sales_existing_data.CustomerName!= sales_new_data.CustomerName OR "
"sales_existing_data.CustomerEmail != sales_new_data.CustomerEmail OR "
"sales_existing_data.CustomerRegion != sales_new_data.CustomerRegion OR "
"sales_existing_data.Product != sales_new_data.Product OR "
"sales_existing_data.Category != sales_new_data.Category OR "
"sales_existing_data.Supplier != sales_new_data.Supplier OR "
"sales_existing_data.Date != sales_new_data.Date OR "
"sales_existing_data.Quantity != sales_new_data.Quantity OR "
"sales_existing_data.UnitPrice != sales_new_data.UnitPrice OR "
"sales_existing_data.TotalSales != sales_new_data.TotalSales OR ",
set =
{
"sales_existing_data.CustomerName": "sales_new_data.CustomerName",
"sales_existing_data.CustomerEmail": "sales_new_data.CustomerEmail",
"sales_existing_data.CustomerRegion": "sales_new_data.CustomerRegion",
"sales_existing_data.Product": "sales_new_data.Product",
"sales_existing_data.Category": "sales_new_data.Category",
"sales_existing_data.Supplier": "sales_new_data.Supplier",
"sales_existing_data.Date": "sales_new_data.Date",
"sales_existing_data.Quantity": "sales_new_data.Quantity",
"sales_existing_data.UnitPrice": "sales_new_data.UnitPrice",
"sales_existing_data.TotalSales": "sales_new_data.TotalSales",
"sales_existing_data.OperationDate": current_timestamp()
}
)\
.whenNotMatchedInsertAll().execute()
sales_table.delete(condition = col("Category") == "Category")
def createcustomer_table():
schema = StructType([StructField("CustomerName", StringType(), True),
StructField("CustomerEmail", StringType(), True),
StructField("CustomerRegion", StringType(), True)])
customer_df = spark.createDataFrame([], schema)
customer_df=spark.read.load(sales_table_path).select("CustomerName","CustomerEmail","CustomerRegion").distinct()\
.withColumn("DateTimeInserted",current_timestamp())
customer_table_path = "Tables/Customer"
customer_df.write.mode("overwrite").format("delta").save(customer_table_path)
def createcategory_table():
schema = StructType([StructField("Category", StringType(), True),
StructField("DateTimeInserted", TimestampType(), True)])
category_df = spark.createDataFrame([], schema)
category_df=spark.read.load(sales_table_path).select("category").distinct()\
.withColumn("DateTimeInserted",current_timestamp())
category_table_path = "Tables/Category"
category_df.write.mode("overwrite").format("delta").save(category_table_path)
def createproduct_table():
schema = StructType([StructField("Product", StringType(), True),
StructField("DateTimeInserted", TimestampType(), True)])
product_df = spark.createDataFrame([], schema)
product_df=spark.read.load(sales_table_path).select("product").distinct()\
.withColumn("DateTimeInserted",current_timestamp())
product_table_path = "Tables/Product"
product_df.write.mode("overwrite").format("delta").save(product_table_path)
def createsupplier_table():
schema = StructType([StructField("Supplier", StringType(), True),
StructField("DateTimeInserted", TimestampType(), True)])
supplier_df = spark.createDataFrame([], schema)
supplier_df=spark.read.load(sales_table_path).select("supplier").distinct()\
.withColumn("DateTimeInserted",current_timestamp())
supplier_table_path = "Tables/Supplier"
supplier_df.write.mode("overwrite").format("delta").save(supplier_table_path)
createcustomer_table()
createcategory_table()
createproduct_table()
createsupplier_table()
Kindly go through the below YouTube video I created to test the overall process.
A correction in the above video @4:30:
We got 202 rows in the sales table from the total of 206 rows in the source is because of two rows having incorrect email format, one row being duplicate and one row which is an header but was identified to be a row and process validated that row as having an incorrect email format and eventually discarding it. This way out of total of 206 rows 202 rows were loaded into the Sales delta table.
Conclusion
As mentioned earlier, Medallion architecture isnt really a new concept per se. Its just a new nomenclature defined specifically for delta lakes but conceptually they are similar to the equivalent traditional end to end data analytics implementation.
In the next article we would look into the process of moving data into a data warehouse in the Gold layer using Fabric data pipeline and create a star schema dimensional model that serves as a source to the semantic model.
So stay tuned !!!
Subscribe to my newsletter
Read articles from Sachin Nandanwar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by