What is Unsupervised Learning? Key Concepts Explained
 HowAiWorks
HowAiWorks
From Recommendation Systems in Streaming Services to Anomaly Detection in Cybersecurity, unsupervised learning—a subbranch of machine learning—covers it all! This article is here to give you a comprehensive overview of unsupervised learning, how it differs from supervised learning, and some common applications where it shines.
Unsupervised- versus Supervised Learning
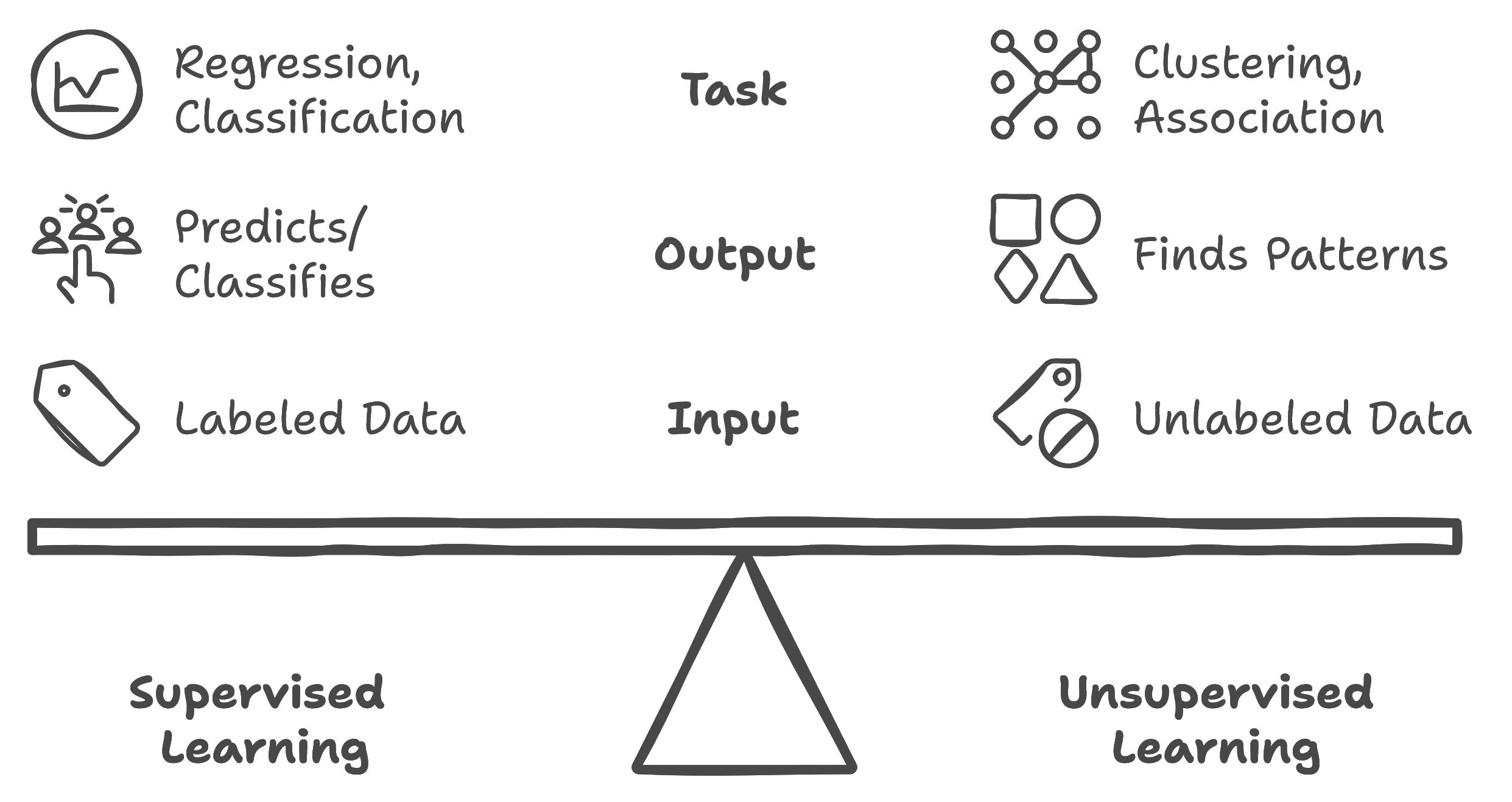
Machine learning algorithms depend heavily on data to perform tasks like prediction, classification, and pattern recognition. The data they use generally falls into two main categories: labeled and unlabeled.
Labeled data includes a specific "answer" or category label for each data point, which guides the algorithm during training. Algorithms trained on labeled data use supervised learning, where the labels provide a reference for learning.
In contrast, unlabeled data comes without category labels or predefined answers. Algorithms trained on this type of data employ unsupervised learning, identifying patterns and structures within the data independently, without needing predefined categories. Instead, it searches for structure within the data itself. For example, a music-streaming service may not label songs with a user’s specific taste preferences. Instead, it can use unsupervised learning to cluster songs into genres or moods based on acoustic properties and usage patterns, offering a customized playlist for each user.
Common tasks in unsupervised learning include:
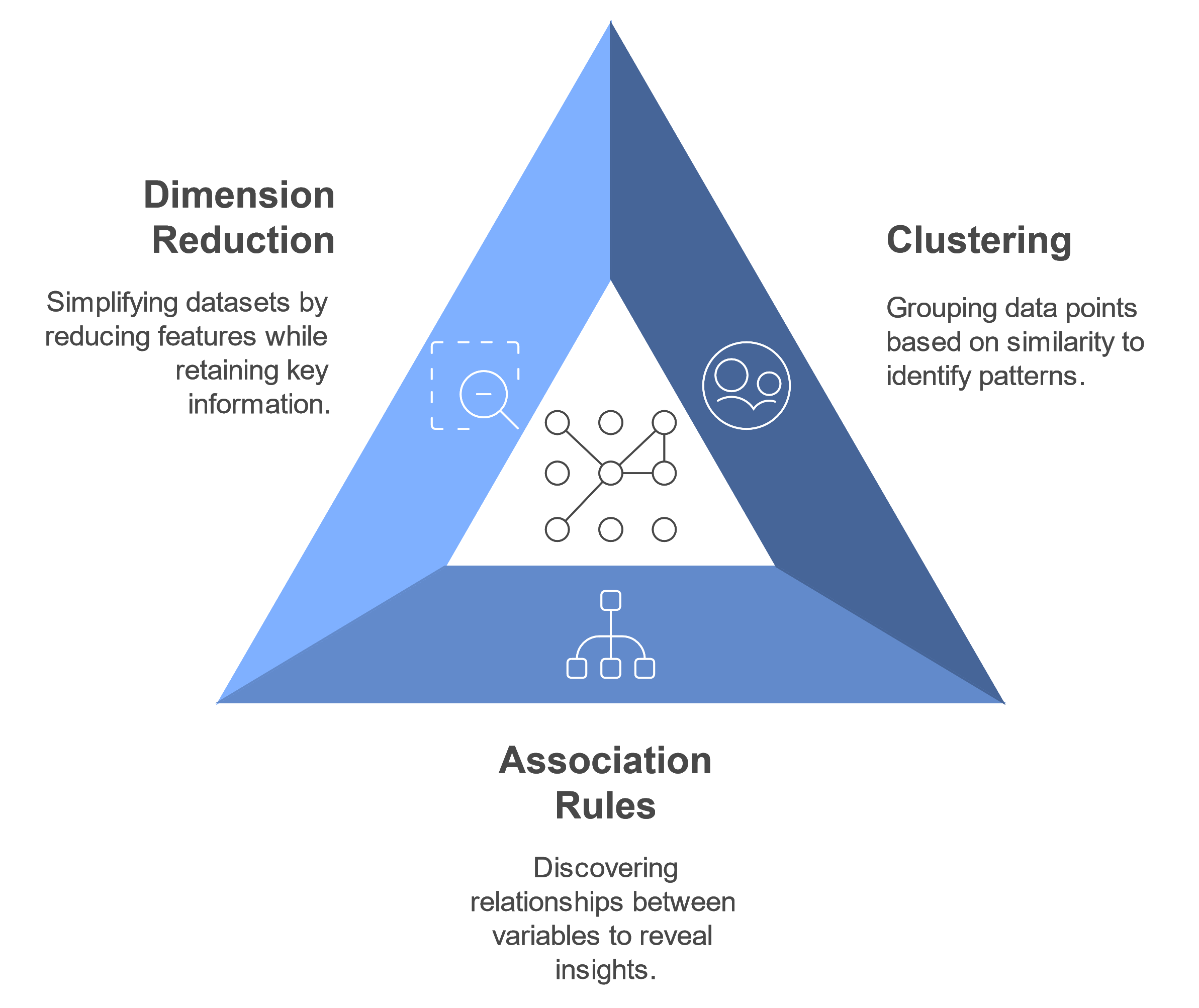
Examples:
Clustering: Clustering customers based on purchase behavior to identify marketing segments.
Association Rules: Finding frequent item combinations in a grocery store to improve product placement.
Dimensional Reduction: Simplifying complex datasets for better analysis and visualization.
Comparison of Supervised and Unsupervised Learning
To choose one approach or the other, you need to consider the conditions.
What is your goal? A classification/regression prediction or data discovery?
What data is available? labelled or unlabelled data? Below is a comparison between the two approaches that may help you decide.
| Supervised Learning | Unsupervised Learning | |
| Accuracy | Can be directly measured against labels | Difficult to measure directly, often evaluated by quality of patterns |
| Algorithms | Linear Regression, Decision Trees, Neural Networks | K-Means, Apriori, Principal Component Analysis (PCA) |
| Applications | Fraud detection, medical diagnosis | Market basket analysis, personalized recommendations |
Types of Unsupervised Learning
Unsupervised learning focuses on finding structure and hidden patterns within data. Three prominent types are clustering, association rules, and dimensional reduction.
Clustering
Clustering organizes data points into groups based on their similarity. This approach is often used in exploratory data analysis, where it helps uncover hidden patterns or groups within the data. For instance, clustering can segment customers based on purchasing behavior, helping companies tailor their marketing strategies.
There are several types of clustering algorithms, each with a specific approach:
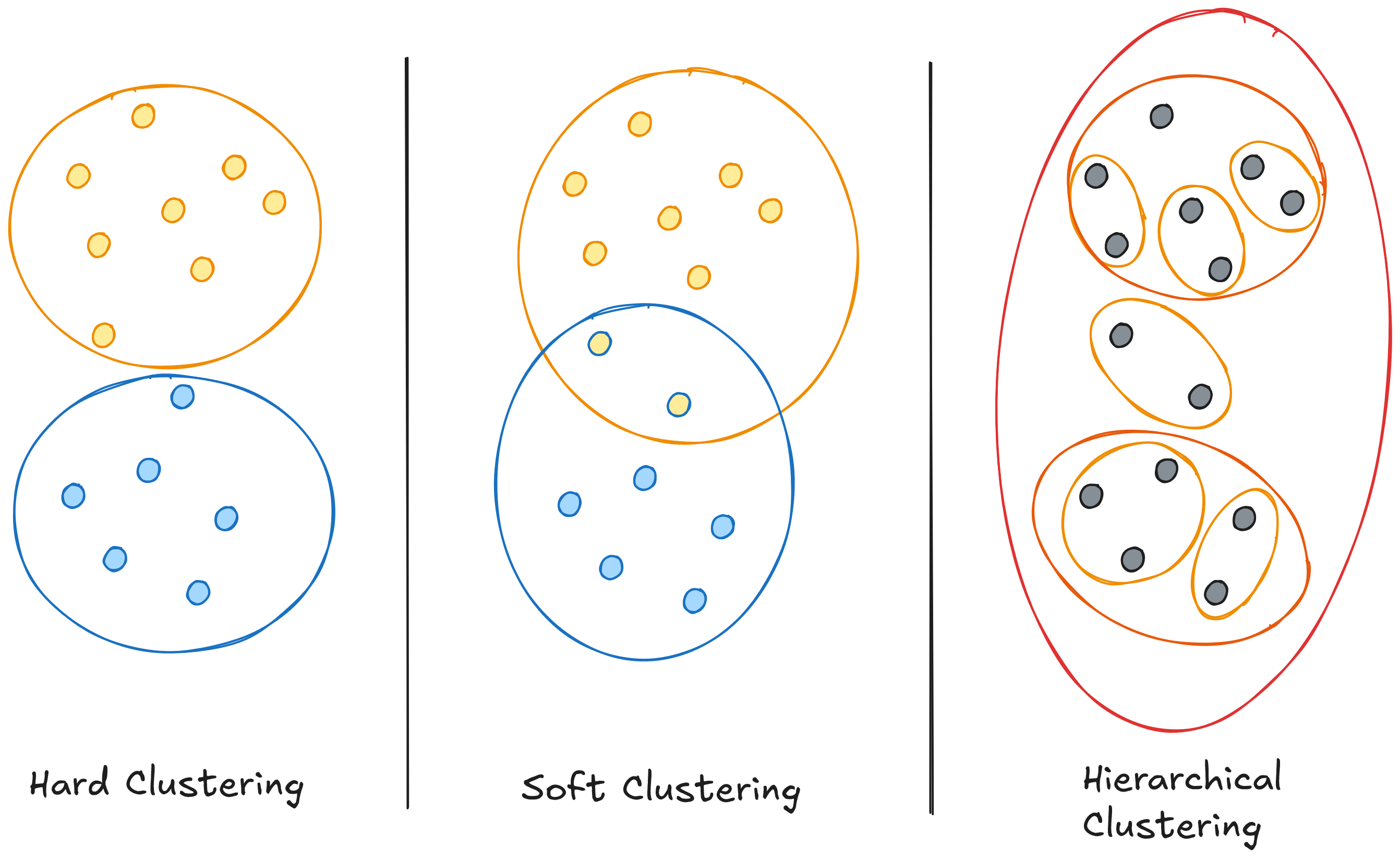
| Type of Clustering | Definition | Common Algorithms |
| Hard Clustering | Each data point belongs to only one cluster | K-Means, K-Medoids |
| Soft Clustering | Data points can belong to multiple clusters with varying probabilities | Gaussian Mixture Models (GMM) |
| Hierarchical Clustering | Builds a hierarchy of clusters, forming a tree-like structure | Agglomerative, Divisive Clustering |
K-Means Clustering
K-Means is one of the most popular clustering algorithms, often used in applications such as customer segmentation, document categorization, and image compression. K-Means groups data by iteratively assigning points to clusters and adjusting cluster centroids until the clusters are optimized. For example, e-commerce companies use K-Means to segment customers based on purchasing patterns, helping them create targeted marketing campaigns.
Association Rules
Association rules uncover relationships between items within large datasets, making them ideal for applications like market basket analysis. For instance, if a supermarket finds that “bread” and “butter” are frequently bought together, it may display these items closer to each other to boost sales.
The Apriori algorithm is widely used for generating association rules. It operates by scanning datasets for frequent itemsets and creating rules from them. Apriori is especially popular in retail for tasks like cross-selling and upselling. For example, Amazon might use Apriori to suggest products frequently bought together, like “people who bought this phone case also bought a screen protector.”
Apriori Algorithm in Depth
The Apriori algorithm works in two main steps:
Frequent Itemset Generation: It scans the dataset to identify items or item combinations that frequently appear together.
Rule Generation: It creates “if-then” rules from these frequent itemsets. For example, if “X” and “Y” are bought together frequently, the rule would state: if “X” is bought, then “Y” is likely to be bought too.
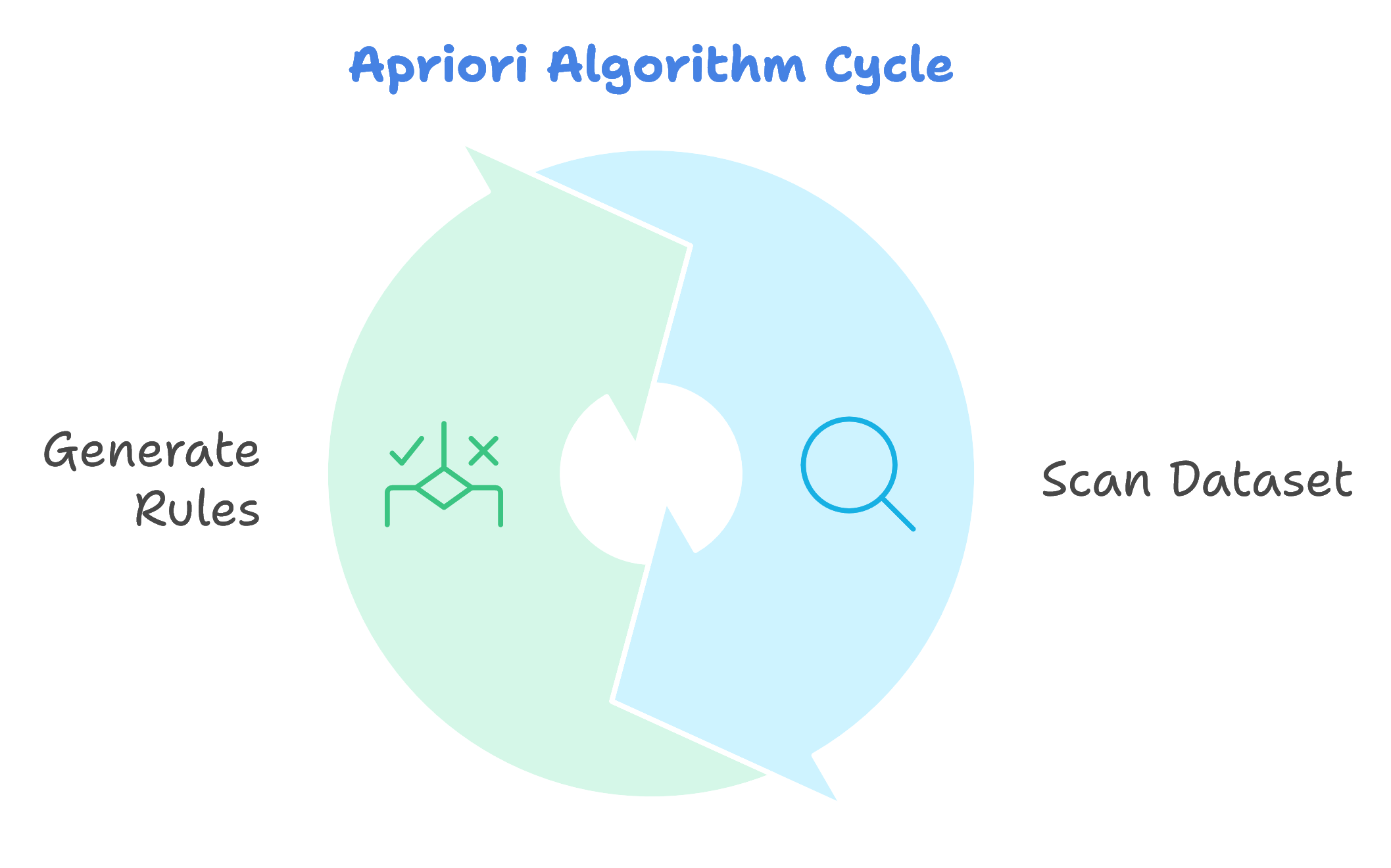
This algorithm is highly effective in discovering purchase patterns, making it a staple in recommendation engines and retail analytics.
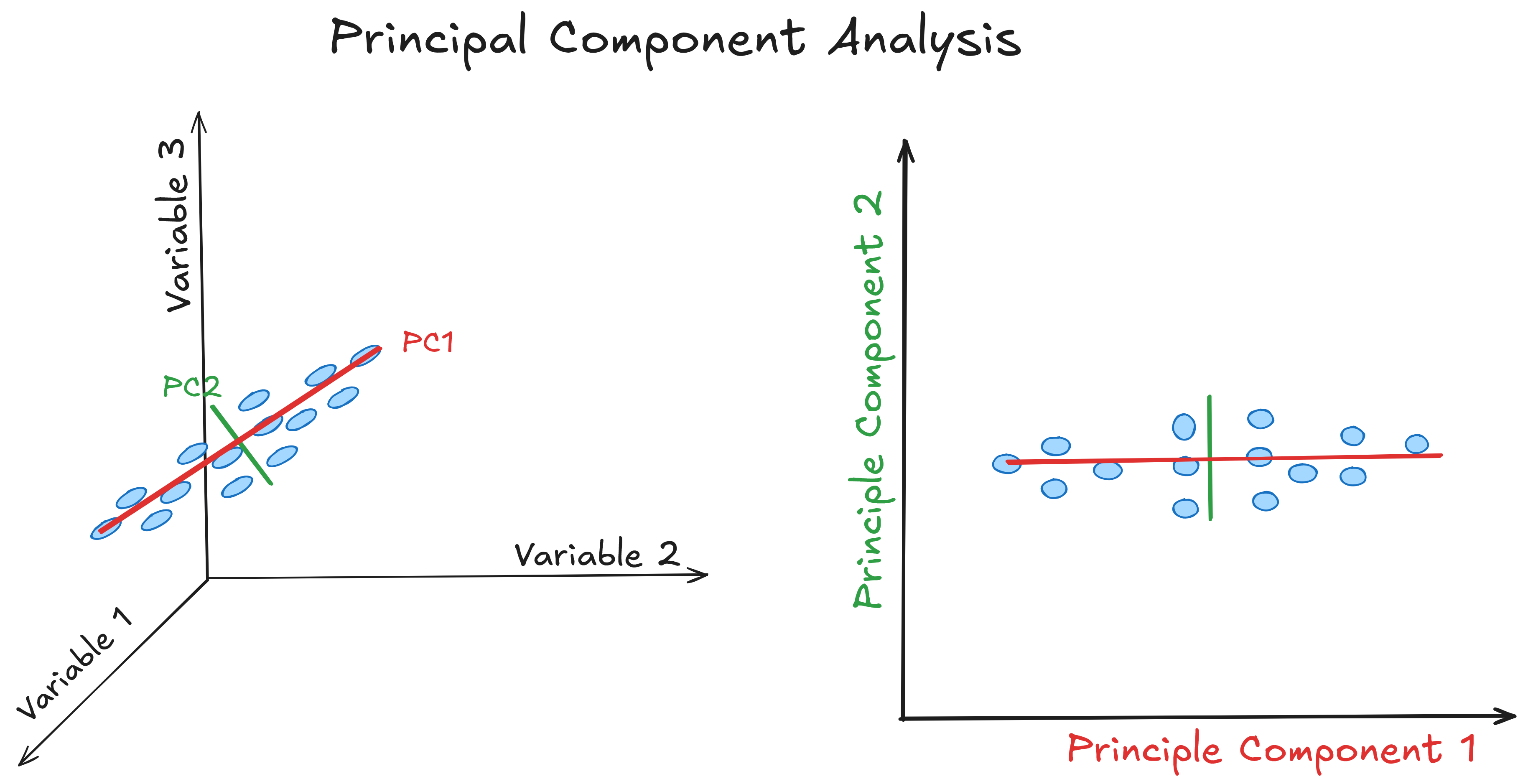
Dimensional Reduction
Dimensional reduction techniques help simplify high-dimensional datasets by reducing the number of features while preserving essential information. This approach is crucial in fields like image processing and text analysis, where the data has many attributes.
Applications: Used for image recognition, text mining, and large dataset visualization, helping to make complex data easier to interpret.
Common Algorithms: The most widely used dimensional reduction algorithms are Principal Component Analysis (PCA) and t-Distributed Stochastic Neighbor Embedding (t-SNE). PCA transforms data into a smaller number of uncorrelated variables called principal components. t-SNE is often used for visualizing high-dimensional data in two or three dimensions, especially useful in gene expression analysis and image classification.
Unsupervised Learning in Advanced AI
Unsupervised learning can enhance various AI domains, including computer vision, and natural language processing (NLP).
Unsupervised Learning in Computer Vision
In computer vision, unsupervised learning aids in image segmentation, dividing an image into meaningful segments. Image segmentation is particularly useful in medical imaging, where it helps identify specific areas of interest, such as tumors in MRI scans. By analyzing unlabeled images, segmentation algorithms can automatically detect and outline abnormalities.
Unsupervised Learning in NLP
Unsupervised learning also plays a critical role in natural language processing (NLP), specifically in tasks like speech recognition. In speech recognition, clustering techniques can help group phonemes—distinct units of sound—allowing the system to recognize spoken words without requiring extensive labeled datasets. This capability is integral to developing robust NLP systems that can process multiple languages and dialects.
Applications of Unsupervised Learning
Unsupervised learning techniques are used across various industries, helping organizations discover patterns and make data-driven decisions. Here are some of the key fields where unsupervised learning excels:
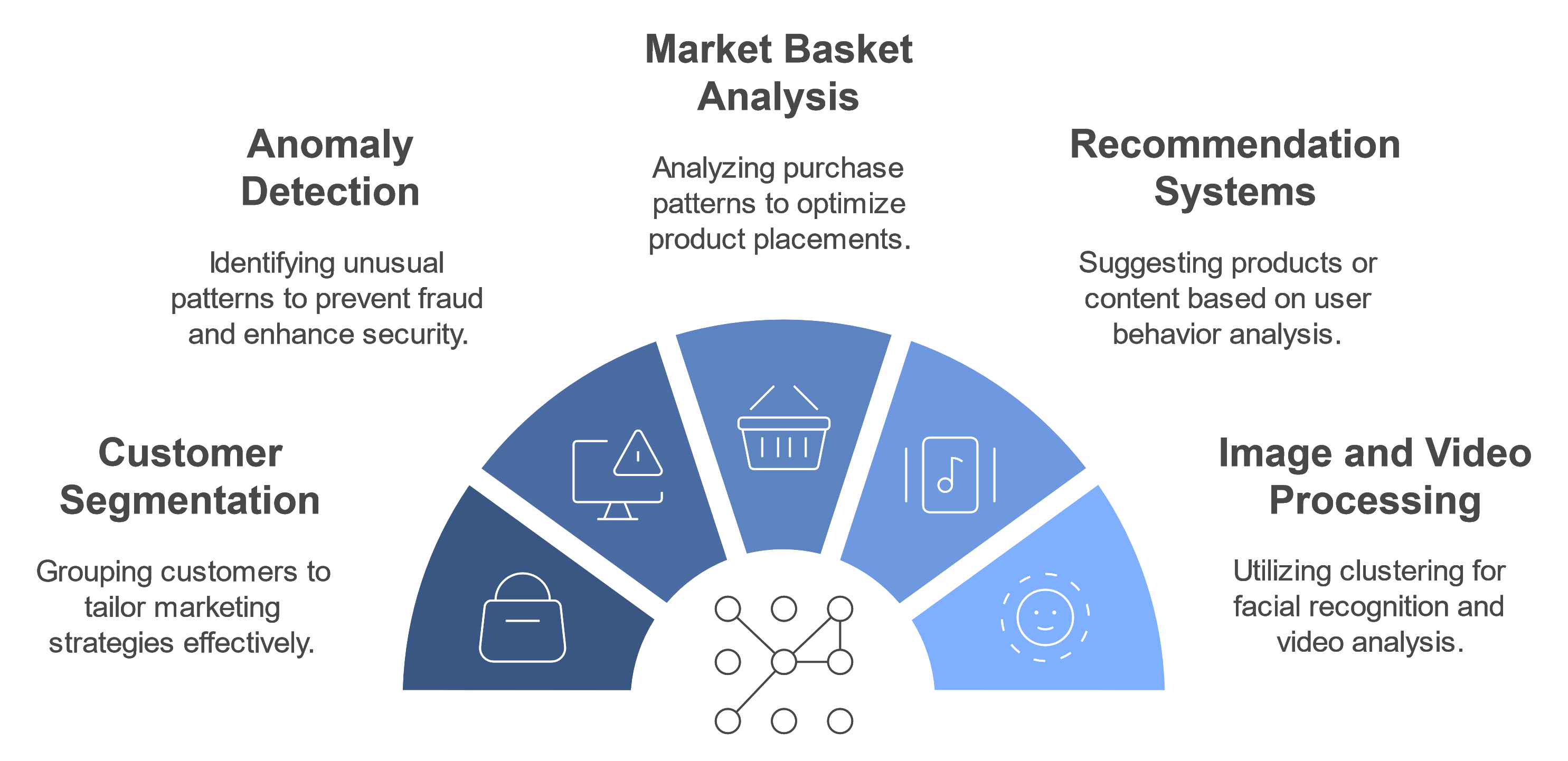
Customer Segmentation: Grouping customers based on purchasing behavior, demographics, or engagement levels. Retailers use this to tailor marketing campaigns for different customer segments.
Anomaly Detection: Identifying unusual patterns or outliers in data, a common task in cybersecurity and fraud prevention. For example, banks use anomaly detection algorithms to flag unusual transactions that may indicate fraud.
Market Basket Analysis: Used to find associations between items, such as frequently bought products. Retailers leverage this to optimize product placements and enhance cross-selling strategies.
Recommendation Systems: Recommending products or content to users based on unsupervised learning of user behaviors and preferences. Streaming services, for example, use clustering to recommend similar movies or shows based on past viewing habits.
Image and Video Processing: Used in applications like facial recognition and video surveillance, where clustering and segmentation algorithms help analyze and categorize visual data.
Unsupervised learning's ability to find hidden patterns makes it a powerful tool in today’s data-driven world, unlocking insights across finance, healthcare, retail, and beyond.
Curious to learn more about artificial intelligence? Check out these blogs:
Subscribe to my newsletter
Read articles from HowAiWorks directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by